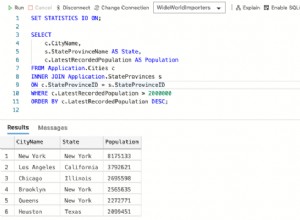
Nel mio blog precedente, abbiamo discusso di vari modi per selezionare o scansionare i dati da una singola tabella. Ma in pratica, il recupero dei dati da una singola tabella non è sufficiente. Richiede la selezione dei dati da più tabelle e la correlazione tra di loro. La correlazione di questi dati tra tabelle è chiamata unione di tabelle e può essere eseguita in vari modi. Poiché l'unione di tabelle richiede dati di input (ad es. dalla scansione della tabella), non può mai essere un nodo foglia nel piano generato.
Es. considera un semplice esempio di query come SELECT * FROM TBL1, TBL2 dove TBL1.ID> TBL2.ID; e supponiamo che il piano generato sia il seguente:
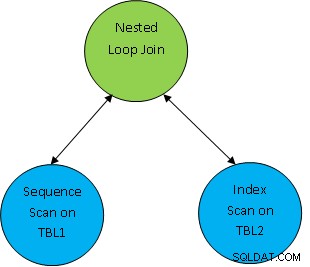
Quindi qui vengono prima scansionate entrambe le tabelle e poi unite insieme come per la condizione di correlazione come TBL.ID> TBL2.ID
Oltre al metodo di unione, anche l'ordine di unione è molto importante. Considera l'esempio seguente:
SELEZIONARE * DA TBL1, TBL2, TBL3 DOVE TBL1.ID=TBL2.ID E TBL2.ID=TBL3.ID;
Si consideri che TBL1, TBL2 E TBL3 hanno rispettivamente 10, 100 e 1000 record.
La condizione TBL1.ID=TBL2.ID restituisce solo 5 record, mentre TBL2.ID=TBL3.ID restituisce 100 record, quindi è meglio unire prima TBL1 e TBL2 in modo da ottenere un numero minore di record unito a TBL3. Il piano sarà come mostrato di seguito:
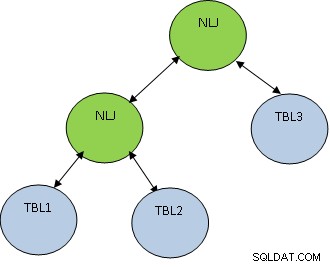
PostgreSQL supporta il tipo di join seguente:
- Unisciti al loop nidificato
- Unisciti all'hash
- Unisci Unisciti
Ciascuno di questi metodi di join è ugualmente utile a seconda della query e di altri parametri, ad es. query, dati di tabella, clausola di join, selettività, memoria ecc. Questi metodi di join sono implementati dalla maggior parte dei database relazionali.
Creiamo una tabella di pre-configurazione e popolarla con alcuni dati, che verranno usati frequentemente per spiegare meglio questi metodi di scansione.
postgres=# create table blogtable1(id1 int, id2 int);
CREATE TABLE
postgres=# create table blogtable2(id1 int, id2 int);
CREATE TABLE
postgres=# insert into blogtable1 values(generate_series(1,10000),3);
INSERT 0 10000
postgres=# insert into blogtable2 values(generate_series(1,1000),3);
INSERT 0 1000
postgres=# analyze;
ANALYZEIn tutti i nostri esempi successivi, consideriamo il parametro di configurazione predefinito se non diversamente specificato.
Unisciti al loop nidificato
Nested Loop Join (NLJ) è l'algoritmo di join più semplice in cui ogni record di relazione esterna è abbinato a ciascun record di relazione interna. Il Join tra la relazione A e B con la condizione A.ID Nested Loop Join (NLJ) è il metodo di unione più comune e può essere utilizzato su quasi tutti i set di dati con qualsiasi tipo di clausola di unione. Poiché questo algoritmo esegue la scansione di tutte le tuple di relazione interna ed esterna, è considerata l'operazione di join più costosa. In base alla tabella e ai dati precedenti, la seguente query risulterà in un Nested Loop Join come mostrato di seguito: Dato che la clausola di join è "<", l'unico metodo di join possibile qui è Nested Loop Join. Nota qui un nuovo tipo di nodo come Materialise; questo nodo funge da cache dei risultati intermedi, ovvero invece di recuperare più volte tutte le tuple di una relazione, la prima volta che il risultato recuperato viene archiviato in memoria e alla successiva richiesta di ottenere la tupla verrà servito dalla memoria invece di recuperare nuovamente dalle pagine delle relazioni . Nel caso in cui tutte le tuple non possano essere inserite in memoria, le tuple di spillover vanno a un file temporaneo. È utile principalmente in caso di Nested Loop Join e in una certa misura in caso di Merge Join poiché si basano su una nuova scansione della relazione interna. Materialise Node non si limita solo alla memorizzazione nella cache dei risultati della relazione, ma può memorizzare nella cache i risultati di qualsiasi nodo sottostante nell'albero del piano. SUGGERIMENTO:nel caso in cui la clausola join sia "=" e il join del ciclo nidificato sia scelto tra una relazione, è davvero importante indagare se è possibile scegliere un metodo di join più efficiente come hash o merge join configurazione di ottimizzazione (ad es. work_mem ma non limitato a ) o aggiungendo un indice, ecc. Alcune delle query potrebbero non avere una clausola di join, in tal caso anche l'unica scelta per partecipare è Nested Loop Join. Per esempio. considera le seguenti query in base ai dati di preimpostazione: Il join nell'esempio sopra è solo un prodotto cartesiano di entrambe le tabelle. Questo algoritmo funziona in due fasi: Il join tra la relazione A e B con condizione A.ID =B.ID può essere rappresentato come segue: In base alla tabella e ai dati di preimpostazione sopra, la seguente query risulterà in un hash join come mostrato di seguito: Qui la tabella hash viene creata sulla tabella blogtable2 perché è la tabella più piccola, quindi la memoria minima richiesta per la tabella hash e l'intera tabella hash può stare in memoria. Merge Join è un algoritmo in cui ogni record di relazione esterna viene confrontato con ogni record di relazione interna finché non esiste la possibilità di corrispondenza della clausola di join. Questo algoritmo di join viene utilizzato solo se entrambe le relazioni sono ordinate e l'operatore della clausola di join è "=". Il join tra la relazione A e B con condizione A.ID =B.ID può essere rappresentato come segue: La query di esempio che ha prodotto un hash join, come mostrato sopra, può risultare in un Merge Join se l'indice viene creato su entrambe le tabelle. Questo perché i dati della tabella possono essere recuperati in ordine a causa dell'indice, che è uno dei criteri principali per il metodo Merge Join: Quindi, come vediamo, entrambe le tabelle utilizzano la scansione dell'indice invece della scansione sequenziale, a causa della quale entrambe le tabelle emetteranno record ordinati. PostgreSQL supporta varie configurazioni relative al pianificatore, che possono essere utilizzate per suggerire a Query Optimizer di non selezionare un particolare tipo di metodo di unione. Se il metodo di unione scelto dall'ottimizzatore non è ottimale, è possibile disattivare questi parametri di configurazione per forzare Query Optimizer a scegliere un tipo diverso di metodi di unione. Tutti questi parametri di configurazione sono "on" per impostazione predefinita. Di seguito sono riportati i parametri di configurazione del pianificatore specifici per i metodi di unione. Ci sono molti parametri di configurazione relativi al piano utilizzati per vari scopi. In questo blog, mantenendolo limitato ai soli metodi di adesione. Questi parametri possono essere modificati da una particolare sessione. Quindi, nel caso in cui desideriamo sperimentare il piano da una sessione particolare, questi parametri di configurazione possono essere manipolati e le altre sessioni continueranno a funzionare così com'è. Ora, considera gli esempi precedenti di merge join e hash join. Senza un indice, Query Optimizer ha selezionato un hash join per la query seguente, come mostrato di seguito, ma dopo aver utilizzato la configurazione, passa all'unione di join anche senza indice: Inizialmente viene scelto Hash Join perché i dati delle tabelle non sono ordinati. Per scegliere il Merge Join Plan, è necessario prima ordinare tutti i record recuperati da entrambe le tabelle e quindi applicare il merge join. Quindi, il costo dello smistamento sarà aggiuntivo e quindi il costo complessivo aumenterà. Quindi forse, in questo caso, il costo totale (compreso l'aumento) è maggiore del costo totale di Hash Join, quindi viene scelto Hash Join. Una volta che il parametro di configurazione enable_hashjoin viene modificato in "off", ciò significa che Query Optimizer assegna direttamente un costo per l'hash join come costo di disattivazione (=1.0e10 ovvero 10000000000.00). Il costo di ogni possibile adesione sarà inferiore a questo. Quindi, la stessa query risulta in Merge Join dopo che enable_hashjoin è stato modificato in "off" poiché anche includendo il costo di ordinamento, il costo totale dell'unione join è inferiore al costo di disabilitazione. Ora considera l'esempio seguente: Come possiamo vedere sopra, anche se il parametro di configurazione relativo al join del ciclo nidificato è stato modificato in "off", comunque sceglie il join del ciclo nidificato poiché non vi è alcuna possibilità alternativa di alcun altro tipo di metodo di unione da ottenere selezionato. In termini più semplici, poiché Nested Loop Join è l'unico possibile join, qualunque sia il costo sarà sempre il vincitore (come ero il vincitore nella gara dei 100 metri se correvo da solo... :-)). Inoltre, nota la differenza di costo nel primo e nel secondo piano. Il primo piano mostra il costo effettivo di Nested Loop Join ma il secondo mostra il costo di disattivazione dello stesso. Tutti i tipi di metodi di join PostgreSQL sono utili e vengono selezionati in base alla natura della query, dei dati, della clausola di join, ecc. Nel caso in cui la query non funzioni come previsto, ad es. i metodi di join non lo sono selezionato come previsto, l'utente può giocare con i diversi parametri di configurazione del piano disponibili e vedere se manca qualcosa.For each tuple r in A
For each tuple s in B
If (r.ID < s.ID)
Emit output tuple (r,s)postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 < bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (bt1.id1 < bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# explain select * from blogtable1, blogtable2;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..125162.50 rows=10000000 width=16)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(4 rows)Partecipa hash
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (bt1.id1 = bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows) Unisci Unisciti
For each tuple r in A
For each tuple s in B
If (r.ID = s.ID)
Emit output tuple (r,s)
Break;
If (r.ID > s.ID)
Continue;
Else
Break;postgres=# create index idx1 on blogtable1(id1);
CREATE INDEX
postgres=# create index idx2 on blogtable2(id1);
CREATE INDEX
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
---------------------------------------------------------------------------------------
Merge Join (cost=0.56..90.36 rows=1000 width=16)
Merge Cond: (bt1.id1 = bt2.id1)
-> Index Scan using idx1 on blogtable1 bt1 (cost=0.29..318.29 rows=10000 width=8)
-> Index Scan using idx2 on blogtable2 bt2 (cost=0.28..43.27 rows=1000 width=8)
(4 rows)Configurazione
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (blogtable1.id1 = blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_hashjoin to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
----------------------------------------------------------------------------
Merge Join (cost=874.21..894.21 rows=1000 width=16)
Merge Cond: (blogtable1.id1 = blogtable2.id1)
-> Sort (cost=809.39..834.39 rows=10000 width=8)
Sort Key: blogtable1.id1
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: blogtable2.id1
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(8 rows)postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_nestloop to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=10000000000.00..10000150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)Conclusione