Il serializzabile il livello di isolamento fornisce una protezione completa da effetti di concorrenza che possono minacciare l'integrità dei dati e portare a risultati di query errati. L'uso dell'isolamento serializzabile significa che se una transazione che può essere mostrata per produrre risultati corretti senza attività simultanee, continuerà a funzionare correttamente quando compete con qualsiasi combinazione di transazioni simultanee.
Questa è una garanzia potente e uno che probabilmente corrisponde alle aspettative intuitive di isolamento delle transazioni di molti programmatori T-SQL (sebbene in verità, relativamente pochi di questi utilizzeranno regolarmente l'isolamento serializzabile in produzione).
Lo standard SQL definisce tre livelli di isolamento aggiuntivi che offrono un ACID molto più debole garanzie di isolamento rispetto al serializzabile, in cambio di una concorrenza potenzialmente maggiore e meno potenziali effetti collaterali come blocco, deadlock e interruzioni del tempo di commit.
A differenza dell'isolamento serializzabile, gli altri livelli di isolamento sono definiti esclusivamente in termini di determinati fenomeni di concorrenza che potrebbero essere osservati. Il successivo più forte dei livelli di isolamento standard dopo serializzabile è denominato lettura ripetibile . Lo standard SQL specifica che le transazioni a questo livello consentono un singolo fenomeno di concorrenza noto come fantasma .
Proprio come abbiamo visto in precedenza importanti differenze tra il significato intuitivo comune delle proprietà delle transazioni ACID e la realtà, il fenomeno fantasma comprende una gamma di comportamenti più ampia di quanto spesso si pensi.
Questo post della serie esamina le effettive garanzie fornite dalla lettura ripetibile livello di isolamento e mostra alcuni dei comportamenti fantasma che si possono incontrare. Per illustrare alcuni punti, faremo riferimento alla seguente semplice query di esempio, in cui il semplice compito è contare il numero totale di righe in una tabella:
SELECT COUNT_BIG(*) FROM dbo.SomeTable;
Lettura ripetibile
Una cosa strana del livello di isolamento in lettura ripetibile è che non garantisce effettivamente che le letture siano ripetibili , almeno in un senso comunemente inteso. Questo è un altro esempio in cui il significato intuitivo da solo può essere fuorviante. L'esecuzione della stessa query due volte all'interno della stessa transazione di lettura ripetibile può effettivamente restituire risultati diversi.
In aggiunta a ciò, l'implementazione di SQL Server della lettura ripetibile significa che una singola lettura di un insieme di dati potrebbe perdere alcune righe che logicamente dovrebbe essere considerato nel risultato della query. Sebbene innegabilmente specifico dell'implementazione, questo comportamento è pienamente in linea con la definizione di lettura ripetibile contenuta nello standard SQL.
L'ultima cosa che voglio notare rapidamente prima di approfondire i dettagli è che la lettura ripetibile in SQL Server non fornire una vista puntuale dei dati.
Letture non ripetibili
Il livello di isolamento in lettura ripetibile garantisce che i dati non cambieranno per tutta la durata della transazione una volta letta per la prima volta.
Ci sono un paio di sottigliezze contenute in quella definizione. Innanzitutto, consente ai dati di cambiare dopo la transazione inizia ma prima che i dati siano primi acceduto. In secondo luogo, non vi è alcuna garanzia che la transazione incontrerà effettivamente tutti i dati che si qualificano logicamente. Vedremo esempi di entrambi a breve.
C'è un altro preliminare che dobbiamo toglierci di mezzo rapidamente, che ha a che fare con la query di esempio che useremo. In tutta onestà, la semantica di questa query è un po' confusa. A rischio di sembrare leggermente filosofico, cosa significa contare il numero di righe nella tabella? Il risultato dovrebbe riflettere lo stato della tabella com'era in un determinato momento? Questo momento dovrebbe essere l'inizio o la fine della transazione o qualcos'altro?
Potrebbe sembrare un po' schizzinoso, ma la domanda è valida in qualsiasi database che supporti letture e modifiche simultanee di dati. L'esecuzione della nostra query di esempio potrebbe richiedere un periodo di tempo arbitrariamente lungo (data una tabella sufficientemente grande o vincoli di risorse, ad esempio), quindi le modifiche simultanee non solo sono possibili, ma potrebbero essere inevitabili .
La questione fondamentale qui è il potenziale del fenomeno della concorrenza denominato fantasma nello standard SQL. Durante il conteggio delle righe nella tabella, un'altra transazione simultanea potrebbe inserire nuove righe in un punto che abbiamo già controllato, oppure cambia una riga che non abbiamo ancora controllato in modo tale che si sposti in un punto che abbiamo già cercato. Le persone spesso pensano ai fantasmi come a righe che potrebbero apparire magicamente se lette per la seconda volta, in una dichiarazione separata, ma gli effetti possono essere molto più sottili di così.
Esempio di inserimento simultaneo
Questo primo esempio mostra come gli inserimenti simultanei possono produrre un non ripetibile leggere e/o far saltare le righe. Immagina che la nostra tabella di test contenga inizialmente cinque righe con i valori riportati di seguito:

Ora impostiamo il livello di isolamento su lettura ripetibile, avviamo una transazione ed eseguiamo la nostra query di conteggio. Come ti aspetteresti, il risultato è cinque . Nessun grande mistero finora.
È ancora in esecuzione all'interno della stessa transazione di lettura ripetibile , eseguiamo nuovamente la query di conteggio, ma questa volta mentre una seconda transazione simultanea inserisce nuove righe nella stessa tabella. Il diagramma seguente mostra la sequenza degli eventi, con la seconda transazione che aggiunge righe con i valori 2 e 6 (potreste aver notato che questi valori erano evidenti per la loro assenza appena sopra):
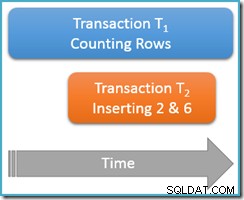
Se la nostra query di conteggio fosse in esecuzione su serializzabile livello di isolamento, sarebbe garantito il conteggio di cinque o sette righe (vedi l'articolo precedente di questa serie se hai bisogno di un aggiornamento sul perché è così). Come funziona correre al meno isolato il livello di lettura ripetibile influisce sulle cose?
Bene, lettura ripetibile l'isolamento garantisce che la seconda esecuzione della query di conteggio vedrà tutte le righe lette in precedenza e saranno nello stesso stato di prima. Il problema è che l'isolamento di lettura ripetibile non dice nulla su come la transazione dovrebbe trattare le nuove righe (i fantasmi).
Immagina che la nostra transazione di conteggio delle righe (T1 ) ha una strategia di esecuzione fisica in cui le righe vengono cercate in ordine crescente di indice. Questo è un caso comune, ad esempio quando il motore di esecuzione utilizza una scansione dell'indice b-tree con ordine in avanti. Ora, subito dopo la transazione T1 conta le righe 1 e 3 in ordine crescente, transazione T2 potrebbe intrufolarsi, inserire nuove righe 2 e 6 e quindi eseguire il commit della transazione.
Sebbene a questo punto stiamo principalmente pensando a comportamenti logici, dovrei menzionare che non c'è nulla nell'implementazione del blocco di SQL Server della lettura ripetibile per prevenire transazione T2 dal fare questo. Lock condivisi presi dalla transazione T1 sulle righe lette in precedenza impediscono la modifica di tali righe, ma non impediscono le nuove righe dall'essere inserito nell'intervallo di valori testato dalla nostra query di conteggio (a differenza dei blocchi dell'intervallo di chiavi con blocco dell'isolamento serializzabile).
Ad ogni modo, con le due nuove righe impegnate, transazione T1 continua la sua ricerca in ordine crescente, incontrando infine le righe 4, 5, 6 e 7. Nota che T1 vede una nuova riga 6 in questo scenario, ma non nuova riga 2 (a causa della ricerca ordinata e della sua posizione al momento dell'inserimento).
Il risultato è che la lettura ripetibile conteggio dei rapporti di query che la tabella contiene sei righe (valori 1, 3, 4, 5, 6 e 7). Questo risultato non è coerente con il risultato precedente di cinque righe ottenuto all'interno della stessa transazione . La seconda lettura ha contato la riga fantasma 6 ma ha mancato la riga fantasma 2. Questo per quanto riguarda il significato intuitivo di una lettura ripetibile!
Esempio di aggiornamento simultaneo
Una situazione simile può verificarsi con un aggiornamento simultaneo invece di un inserto. Immagina che la nostra tabella di test sia reimpostata per contenere le stesse cinque righe di prima:

Questa volta, eseguiremo la nostra query di conteggio solo una volta alla lettura ripetibile livello di isolamento, mentre una seconda transazione simultanea aggiorna la riga con il valore 5 in modo che abbia un valore di 2:
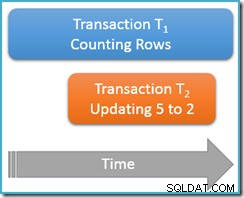
Transazione T1 ricomincia a contare le righe, (in ordine crescente) incontrando prima le righe 1 e 3. Ora, la transazione T2 entra, cambia il valore della riga 5 in 2 e si impegna:

Ho mostrato la riga aggiornata nella stessa posizione di prima per rendere chiara la modifica, ma l'indice b-tree che stiamo scansionando mantiene i dati in ordine logico, quindi l'immagine reale è più simile a questa:

Il punto è che la transazione T1 sta scansionando contemporaneamente questa stessa struttura in ordine in avanti, essendo attualmente posizionato appena dopo la voce per il valore 3. La query di conteggio continua la scansione in avanti da quel punto, trovando le righe 4 e 7 (ma non la riga 5 ovviamente).
Per riassumere, la query di conteggio ha visto le righe 1, 3, 4 e 7 in questo scenario. Segnala un conteggio di quattro righe – il che è strano, perché la tabella sembra contenere cinque righe tutto!
Una seconda esecuzione della query di conteggio all'interno della stessa transazione di lettura ripetibile riporterebbe cinque righe, per ragioni simili a prima. Come nota finale, nel caso te lo stia chiedendo, le eliminazioni simultanee non offrono l'opportunità di un'anomalia basata su fantasmi sotto isolamento di lettura ripetibile.
Pensieri finali
Gli esempi precedenti utilizzavano entrambi scansioni in ordine crescente di una struttura di indice per presentare una vista semplice del tipo di effetti che i fantasmi possono avere su una lettura ripetibile interrogazione. È importante capire che queste illustrazioni non si basano in alcun modo importante sulla direzione di scansione o sul fatto che è stato utilizzato un indice b-tree. Per favore, non dal punto di vista che le scansioni ordinate sono in qualche modo responsabili e quindi da evitare!
Gli stessi effetti di concorrenza possono essere osservati con una scansione in ordine decrescente di una struttura di indice o in una varietà di altri scenari di accesso ai dati fisici. Il punto principale è che i fenomeni fantasma sono specificamente consentiti (sebbene non richiesti) dallo standard SQL per le transazioni al livello di isolamento di lettura ripetibile.
Non tutte le transazioni richiedono la garanzia di isolamento completo fornita dall'isolamento serializzabile e non molti sistemi potrebbero tollerare gli effetti collaterali se lo facessero. Tuttavia, vale la pena avere una buona comprensione di quali garanzie offrono i vari livelli di isolamento.
La prossima volta
La parte successiva di questa serie esamina le garanzie di isolamento ancora più deboli offerte dal livello di isolamento predefinito di SQL Server, read commit .
[Vedi l'indice per l'intera serie]


