In qualità di consulente che lavora con SQL Server, molte volte mi viene chiesto di guardare un server che sembra avere problemi di prestazioni. Durante l'esecuzione del triage sul server, pongo alcune domande, ad esempio:qual è il normale utilizzo della CPU, quali sono le latenze medie del disco, qual è il normale utilizzo della memoria e così via. La risposta di solito è "non lo sappiamo" o "non acquisiamo tali informazioni regolarmente". Non avere una linea di base recente rende molto difficile sapere che aspetto abbia un comportamento anomalo. Se non sai qual è il comportamento normale, come fai a sapere con certezza se le cose vanno meglio o peggio? Uso spesso le espressioni "se non lo stai monitorando, non puoi misurarlo" e "se non lo stai misurando, non puoi gestirlo".
Dal punto di vista del monitoraggio, come minimo, le organizzazioni dovrebbero monitorare i processi non riusciti come backup, manutenzione dell'indice, DBCC CHECKDB e qualsiasi altro lavoro importante. È facile impostare notifiche di errore per questi; tuttavia è necessario anche un processo in atto per assicurarsi che i lavori vengano eseguiti come previsto. Ho visto lavori che si bloccano e non vengono mai completati. Una notifica di errore non attiverebbe un allarme poiché il lavoro non riesce o non riesce mai.
Da una linea di base delle prestazioni, ci sono diverse metriche chiave che dovrebbero essere acquisite. Ho creato un processo che utilizzo con i client che acquisisce le metriche chiave su base regolare e memorizza tali valori in un database utente. Il mio processo è semplice:un database dedicato con procedure memorizzate che utilizzano script comuni che inseriscono i set di risultati nelle tabelle. Ho processi di SQL Agent per eseguire le stored procedure a intervalli regolari e uno script di pulizia per eliminare i dati più vecchi di X giorni. Le metriche che acquisisco sempre includono:
Aspettativa di vita della pagina :PLE è probabilmente uno dei modi migliori per valutare se il tuo sistema è sotto pressione della memoria interna. La maggior parte dei sistemi ha valori PLE che fluttuano durante i normali carichi di lavoro. Mi piace orientare questi valori per sapere quali sono i valori minimo, medio e massimo. Mi piace cercare di capire cosa ha causato la caduta di PLE in determinati momenti della giornata per vedere se questi processi possono essere regolati. Molte volte, qualcuno esegue una scansione della tabella e svuota il pool di buffer. Essere in grado di indicizzare correttamente tali query può aiutare. Assicurati solo di monitorare il contatore PLE corretto:vedi qui .
Utilizzo della CPU :Avere una linea di base per l'utilizzo della CPU ti consente di sapere se il tuo sistema è improvvisamente sotto pressione della CPU. Spesso quando un utente si lamenta di problemi di prestazioni, noterà che la CPU sembra alta. Ad esempio, se la CPU si aggira intorno all'80%, potrebbero trovarlo preoccupante, tuttavia se la CPU era anche all'80% nello stesso periodo delle settimane precedenti quando non sono stati segnalati problemi, la probabilità che sia la CPU il problema è molto bassa. La tendenza della CPU non serve solo a catturare quando la CPU aumenta e rimane a un valore costantemente alto. Ho numerose storie di quando sono stato portato in un ponte di una conferenza di gravità perché si è verificato un problema con un'applicazione. Essendo il DBA, indossavo il cappello di "Default Blame Acceptor". Quando il team dell'applicazione ha detto che c'era un problema con il database, spettava a me dimostrare che non lo era, il server del database era colpevole fino a prova contraria. Ricordo vividamente un incidente in cui il team dell'applicazione era sicuro che il server del database stesse riscontrando problemi perché gli utenti non potevano connettersi. Avevano letto su Internet che SQL Server potrebbe soffrire di fame di pool di thread se rifiutava le connessioni. Sono saltato sul server e ho iniziato a guardare le risorse e quali processi erano attualmente in esecuzione. Nel giro di pochi minuti ho riferito che il server in questione era molto annoiato. Sulla base delle nostre metriche di base, la CPU era in genere del 60% ed era inattiva di circa il 20%, l'aspettativa di vita della pagina era notevolmente superiore al normale e non si verificavano blocchi o blocchi, l'I/O sembrava ottimo, nessun errore nei registri e i conteggi delle sessioni erano circa 1/3 del loro conteggio normale. Ho quindi fatto il commento:"Sembra che gli utenti non stiano nemmeno raggiungendo il server del database". Ciò ha attirato l'attenzione degli utenti della rete e si sono resi conto che una modifica apportata al sistema di bilanciamento del carico non funzionava correttamente e hanno determinato che oltre il 50% delle connessioni veniva instradato in modo errato e non veniva effettuato al server del database. Se non avessi saputo quale fosse la linea di base, ci sarebbe voluto molto più tempo per raggiungere la risoluzione.
I/O su disco :L'acquisizione delle metriche del disco è molto importante. Il DMV sys.dm_io_virtual_file_stats è cumulativo dall'ultimo riavvio del server. L'acquisizione delle latenze I/O in un intervallo di tempo ti darà una linea di base di ciò che è normale durante quel periodo. Fare affidamento sul valore cumulativo può fornire dati distorti da attività successive all'orario lavorativo o lunghi periodi in cui il sistema è rimasto inattivo. Paul ne ha discusso qui .
Dimensioni dei file di database :Disporre di un inventario dei database che includa le dimensioni dei file, le dimensioni utilizzate, lo spazio libero e altro può aiutarti a prevedere la crescita del database. Spesso mi viene chiesto di prevedere la quantità di spazio di archiviazione necessaria per un server di database nel prossimo anno. Senza conoscere il trend di crescita settimanale o mensile, non ho modo di fare un calcolo intelligente. Una volta che comincio a monitorare questi valori, posso adattare correttamente questo trend. Oltre alle tendenze, potevo anche scoprire quando c'era una crescita inaspettata del database. Quando vedo una crescita inaspettata e indago, di solito scopro che qualcuno ha duplicato una tabella per eseguire alcuni test (sì, in produzione!) o ha eseguito un altro processo una tantum. Tenere traccia di questo tipo di dati ed essere in grado di rispondere quando si verificano anomalie ti aiuta a dimostrare che sei proattivo e che tieni sotto controllo i tuoi sistemi.
Statistiche di attesa :il monitoraggio delle statistiche di attesa può aiutarti a iniziare a capire la causa di determinati problemi di prestazioni. Molti nuovi DBA si preoccupano quando iniziano a ricercare le statistiche di attesa e non riescono a rendersi conto che le attese si verificano sempre e che è proprio il modo in cui funziona il sistema di pianificazione di SQL Server. Ci sono anche molte attese che possono essere considerate benigne o per lo più innocue. Paul Randal esclude queste attese per lo più innocue nel suo popolare script di statistiche di attesa. Paul ha anche creato una vasta libreria dei vari tipi di attesa e latch classi con descrizioni e altre informazioni sulla risoluzione dei problemi di attese e latch.
Ho documentato il mio processo di raccolta dei dati e puoi trovare il codice sul mio blog . A seconda della situazione e dei tipi di problemi che un cliente potrebbe riscontrare, potrei anche voler acquisire metriche aggiuntive. Glenn Berry ha scritto sul blog di un processo che ha messo insieme che acquisisce il conteggio medio delle attività, il conteggio medio delle attività eseguibili, il conteggio medio degli I/O in sospeso, l'utilizzo della CPU del processo di SQL Server e l'aspettativa di vita media della pagina in tutti i nodi NUMA. Una rapida ricerca su Internet farà emergere molti altri processi di raccolta dati condivisi dalle persone, anche SQL Server Tiger Team dispone di un processo che utilizza T-SQL e PowerShell.
L'utilizzo di un database personalizzato e la creazione del proprio pacchetto di raccolta dati è una soluzione valida per acquisire una linea di base, ma la maggior parte di noi non è impegnata nella creazione di soluzioni complete di monitoraggio di SQL Server. C'è molto altro che sarebbe utile acquisire, cose come query di lunga durata, query principali e procedure archiviate basate su memoria, I/O e CPU, deadlock, frammentazione dell'indice, transazioni al secondo e molto altro. Per questo, consiglio sempre ai clienti di acquistare uno strumento di monitoraggio di terze parti. Questi fornitori sono specializzati nell'essere sempre aggiornati sulle ultime tendenze e funzionalità di SQL Server in modo che tu possa concentrare il tuo tempo sull'assicurarti che SQL Server sia il più stabile e veloce possibile.
Soluzioni come SQL Sentry (per SQL Server) e DB Sentry (per il database SQL di Azure) acquisiscono tutte queste metriche e consentono di creare facilmente diverse linee di base. Puoi avere una linea di base normale, fine mese, fine trimestre e altro. È quindi possibile applicare la linea di base e vedere visivamente come le cose sono diverse. Ancora più importante, puoi configurare un numero qualsiasi di avvisi per varie condizioni ed essere avvisato quando le metriche superano le tue soglie.
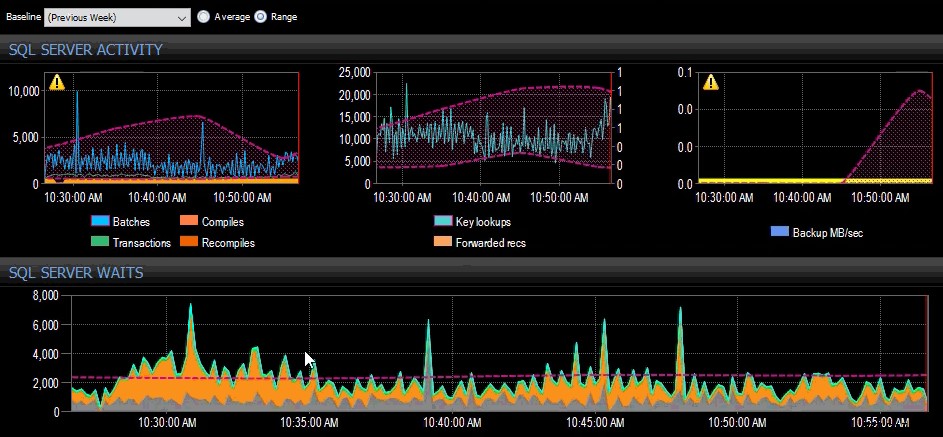 La previsione della scorsa settimana è stata applicata a diverse metriche di SQL Server nel dashboard di SQL Sentry.
La previsione della scorsa settimana è stata applicata a diverse metriche di SQL Server nel dashboard di SQL Sentry.
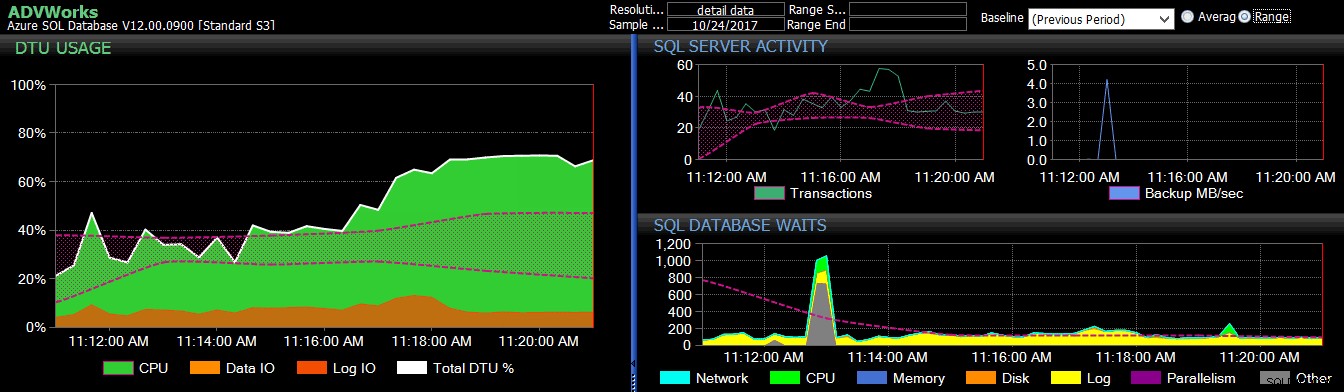 La previsione del periodo precedente è stata applicata a diverse metriche del database SQL di Azure nel dashboard di DB Sentry.
La previsione del periodo precedente è stata applicata a diverse metriche del database SQL di Azure nel dashboard di DB Sentry.
Per ulteriori informazioni sulle linee di base in SentryOne, vedere questi post sul blog del loro team o questo video del martedì di 2 minuti . Interessato a scaricare una versione di prova? Hanno coperto anche te .