Questo articolo è il secondo di una serie sulle soglie di ottimizzazione relative al raggruppamento e all'aggregazione dei dati. Nella parte 1, ho fornito la formula di reverse engineering per il costo dell'operatore Stream Aggregate. Ho spiegato che questo operatore deve consumare le righe ordinate dall'insieme di raggruppamento (qualsiasi ordine dei suoi membri) e che quando i dati vengono ottenuti preordinati da un indice, si ottiene un ridimensionamento lineare rispetto al numero di righe e al numero di gruppi. Inoltre, in questo caso non è necessaria alcuna concessione di memoria.
In questo articolo, mi concentrerò sulla determinazione dei costi e sulla scalabilità di un'operazione basata sull'aggregazione del flusso quando i dati non vengono ottenuti preordinati da un indice, ma devono essere prima ordinati.
Nei miei esempi, userò il database di esempio PerformanceV3, come nella Parte 1. Puoi scaricare lo script che crea e popola questo database da qui. Prima di eseguire gli esempi di questo articolo, assicurati di eseguire prima il codice seguente per eliminare un paio di indici non necessari:
DROP INDEX idx_nc_sid_od_cid SU dbo.Orders;DROP INDEX idx_unc_od_oid_i_cid_eid SU dbo.Orders;
Gli unici due indici che dovrebbero essere lasciati in questa tabella sono idx_cl_od (raggruppato con orderdate come chiave) e PK_Orders (non cluster con orderid come chiave).
Ordina + aggrega Stream
L'obiettivo di questo articolo è provare a capire in che modo un'operazione di aggregazione del flusso viene ridimensionata quando i dati non sono preordinati dal set di raggruppamento. Poiché l'operatore Stream Aggregate deve elaborare le righe ordinate, se non sono preordinate in un indice, il piano deve includere un operatore di ordinamento esplicito. Quindi il costo dell'operazione aggregata che dovresti prendere in considerazione è la somma dei costi degli operatori Sort + Stream Aggregate.
Userò la seguente query (la chiameremo Query 1) per dimostrare un piano che prevede tale ottimizzazione:
SELECT shipperid, MAX(data ordine) AS maxod FROM (SELECT TOP (100) * FROM dbo.Orders) AS D GROUP BY shipperid;
Il piano per questa query è mostrato nella Figura 1.

Figura 1:piano per la query 1
Il motivo per cui utilizzo un'espressione di tabella con un filtro TOP è controllare il numero esatto di righe (stimate) coinvolte nel raggruppamento e nell'aggregazione. L'applicazione di modifiche controllate semplifica il tentativo di decodificare le formule di determinazione dei costi.
Se ti stai chiedendo perché filtrare un numero così piccolo di righe in questo esempio, ha a che fare con le soglie di ottimizzazione che rendono questa strategia preferita all'algoritmo Hash Aggregate. Nella parte 3 descriverò i costi e il ridimensionamento dell'alternativa hash. Nei casi in cui l'ottimizzatore non scelga da solo un'operazione di aggregazione del flusso, ad esempio quando sono coinvolti un numero elevato di righe, è sempre possibile forzarlo con l'hint OPTION(ORDER GROUP) durante il processo di ricerca. Quando ti concentri sul costo dei piani seriali, puoi ovviamente aggiungere un suggerimento MAXDOP 1 per eliminare il parallelismo.
Come accennato, per valutare il costo e il ridimensionamento di un algoritmo di aggregazione di flussi non preordinati, è necessario tenere conto della somma degli operatori Sort + Stream Aggregate. Conosci già la formula dei costi per l'operatore Stream Aggregate dalla Parte 1:
@numrows * 0.0000006 + @numgroups * 0.0000005Nella nostra query abbiamo 100 righe di input stimate e 5 gruppi di output stimati (5 ID mittente distinti stimati in base alle informazioni sulla densità). Quindi il costo dell'operatore Stream Aggregate nel nostro piano è:
100 * 0,0000006 + 5 * 0,0000005 =0,0000625Proviamo a capire la formula di costo per l'operatore di ordinamento. Ricorda, il nostro obiettivo è il costo stimato e la scalabilità perché il nostro obiettivo finale è quello di individuare le soglie di ottimizzazione in cui l'ottimizzatore cambia le sue scelte da una strategia all'altra.
La stima del costo di I/O sembra essere fissa:0,0112613. Ottengo lo stesso costo di I/O indipendentemente da fattori come il numero di righe, il numero di colonne di ordinamento, il tipo di dati e così via. Questo è probabilmente per spiegare un lavoro di I/O previsto.
Per quanto riguarda il costo della CPU, purtroppo, Microsoft non espone pubblicamente gli algoritmi esatti che usano per l'ordinamento. Tuttavia, tra gli algoritmi comuni utilizzati per l'ordinamento dai motori di database in generale ci sono diverse implementazioni di merge sort e quicksort. Grazie agli sforzi fatti da Paul White, che ama guardare le tracce dello stack del debugger di Windows (non tutti noi abbiamo lo stomaco per questo), abbiamo un po' più di comprensione dell'argomento, pubblicato nella sua serie "Internals of the Seven SQL Server Ordina.» Secondo i risultati di Paul, la classe di ordinamento generale (usata nel piano sopra) utilizza l'ordinamento di unione (prima interno, quindi passa a esterno). In media, questo algoritmo richiede n log n confronti per ordinare n elementi. Con questo in mente, è probabilmente una scommessa sicura come punto di partenza presumere che la parte CPU del costo dell'operatore sia basata su una formula come:
Costo CPU operatore =Naturalmente, questa potrebbe essere una semplificazione eccessiva della formula di determinazione dei costi utilizzata da Microsoft, ma in assenza di documentazione in merito, questa è una prima ipotesi migliore.
Successivamente, puoi ottenere l'ordinamento dei costi della CPU da due piani di query prodotti per ordinare diversi numeri di righe, ad esempio 1000 e 2000, e in base a quelli e alla formula precedente, eseguire il reverse engineering del costo di confronto e del costo di avvio. A tale scopo, non è necessario utilizzare una query raggruppata; è sufficiente fare solo un ORDINE di base. Userò le seguenti due query (le chiameremo Query 2 e Query 3):
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid;
Il punto nell'ordinare in base al risultato di un calcolo è forzare l'uso di un operatore di ordinamento nel piano.
La figura 2 mostra le parti rilevanti dei due piani:
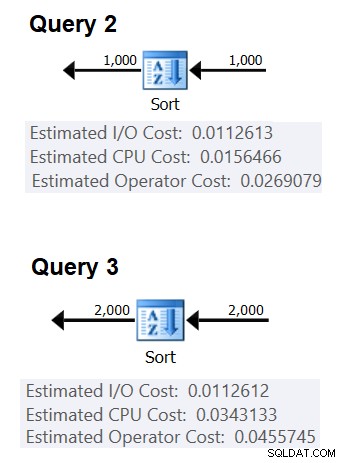
Figura 2:Piani per Query 2 e Query 3
Per provare a dedurre il costo di un confronto, dovresti utilizzare la seguente formula:
costo di confronto =
((
/ (
(0,0343133 – 0,0156466) / (2000*LOG(2000) – 1000*LOG(1000)) =2.25061348918698E-06
Per quanto riguarda il costo di avvio, puoi dedurlo in base a entrambi i piani, ad esempio in base al piano che ordina 2000 righe:
costo di avvio =0,0343133 – 2000*LOG(2000) * 2,25061348918698E-06 =9,99127891201865E-05
E così la nostra formula Ordina costo CPU diventa:
Costo CPU operatore di ordinamento =9,99127891201865E-05 + @numrows * LOG(@numrows) * 2,25061348918698E-06Utilizzando tecniche simili, scoprirai che fattori come la dimensione media delle righe, il numero di colonne di ordinamento e i relativi tipi di dati non influiscono sul costo stimato della CPU di ordinamento. L'unico fattore che sembra essere rilevante è il numero stimato di righe. Si noti che l'ordinamento richiederà una concessione di memoria e la concessione è proporzionale al numero di righe (non di gruppi) e alla dimensione media delle righe. Ma attualmente il nostro obiettivo è il costo stimato dell'operatore e sembra che questa stima sia influenzata solo dal numero stimato di righe.
Questa formula sembra prevedere bene il costo della CPU fino a una soglia di circa 5.000 righe. Provalo con i seguenti numeri:100, 200, 300, 400, 500, 1000, 2000, 3000, 4000, 5000:
SELECT numrows, 9.99127891201865E-05 + numrows * LOG(numrows) * 2.25061348918698E-06 AS costo previsto DA (VALUES(100), (200), (300), (400), (500), (1000) , (2000), (3000), (4000), (5000)) AS D(numri);
Confronta ciò che la formula prevede e i costi della CPU stimati mostrati dai piani per le seguenti query:
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (100) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (200) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (300) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (400) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (500) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (3000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (4000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (5000) * FROM dbo.Orders) AS D ORDER BY myorderid;
Ho ottenuto i seguenti risultati:
numrows rapporto costo stimato costo previsto ----------- --------------- -------------- --- ---- 100 0.0011363 0.0011365 1.00018 200 0.0024848 0.0024849 1.00004 300 0.0039510 0.0039511 1.00003 400 0.0054937 0.0054938 1.00002 500 0.0070933 0.0070933 1.00000 1000 0.0156466 0.0156466 1.00000 2000 0.0343133 0.0343133 1.00000 3000 0.0541576 0.0541576 1.00000 4000 0.0747667 0.0747665 1.00000 5000 0.0959445 0.0959442 1.00000
La colonna costo previsto mostra la previsione basata sulla nostra formula di reverse engineering, la colonna costo stimato mostra il costo stimato che appare nel piano e il rapporto colonna mostra il rapporto tra quest'ultimo e il primo.
La predicazione sembra abbastanza accurata fino a 5.000 righe. Tuttavia, con numeri superiori a 5.000, la nostra formula di reverse engineering smette di funzionare bene. La query seguente fornisce le predicazioni per righe 6K, 7K, 10K, 20K, 100K e 200K:
SELECT numrows, 9.99127891201865E-05 + numrows * LOG(numrows) * 2.25061348918698E-06 AS costo previsto DA (VALUES(6000), (7000), (10000), (20000), (100000), (200000) ) AS D(numrighe);
Utilizza le seguenti query per ottenere i costi della CPU stimati dai piani (nota il suggerimento per forzare un piano seriale poiché con un numero maggiore di righe è più probabile che otterrai un piano parallelo in cui le formule di costo sono regolate per il parallelismo):
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (6000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (7000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1);
Ho ottenuto i seguenti risultati:
numrows rapporto costo stimato costo previsto ----------- --------------- -------------- --- --- 6000 0.117575 0.160970 1.3691 7000 0.139583 0.244848 1.7541 10000 0.207389 0.603420 2.9096 20000 0.445878 1.311710 2.9419 100000 100000 100000 2.9422222222222222220.163016578 1.311710 2.9419 100000 100000 100000 100000 2.9423 Come puoi vedere, oltre le 5.000 righe la nostra formula diventa sempre meno precisa, ma curiosamente, il rapporto di precisione si stabilizza su circa 2,94 a circa 20.000 righe. Ciò implica che con numeri grandi la nostra formula si applica ancora, solo con un costo di confronto più elevato, e che all'incirca tra 5.000 e 20.000 righe, si passa gradualmente dal costo di confronto inferiore a quello più alto. Ma cosa potrebbe spiegare la differenza tra la piccola scala e la grande scala? La buona notizia è che la risposta non è così complessa come conciliare la meccanica quantistica e la relatività generale con la teoria delle stringhe. È solo che su scala ridotta Microsoft ha voluto tenere conto del fatto che è probabile che venga utilizzata la cache della CPU e, a fini di costo, presuppone una dimensione della cache fissa.Quindi, per calcolare il costo di confronto su larga scala, si desidera utilizzare l'ordinamento dei costi della CPU da due piani per numeri superiori a 20.000. Userò 100.000 e 200.000 righe (ultime due righe nella tabella sopra). Ecco la formula per dedurre il costo di confronto:
costo di confronto =
(16.1657 – 7.62392) / (200000*LOG(200000) – 100000*LOG(100000)) =6.62193536908588E-06Quindi, ecco la formula per dedurre il costo di avvio in base al piano per 200.000 righe:
costo di avvio =
16.1657 – 200000*LOG(200000) * 6.62193536908588E-06 =1.35166186417734E-04Potrebbe benissimo essere che il costo di avvio per le piccole e grandi scale sia lo stesso e che la differenza che abbiamo ottenuto sia dovuta a errori di arrotondamento. Ad ogni modo, con un numero elevato di righe, il costo di avvio diventa trascurabile rispetto al costo dei confronti.
In sintesi, ecco la formula per il costo della CPU dell'operatore di ordinamento per numeri grandi (>=20000):
Costo CPU operatore =1,35166186417734E-04 + @numrows * LOG(@numrows) * 6,62193536908588E-06Testiamo l'accuratezza della formula con 500K, 1M e 10M righe. Il codice seguente fornisce le predicazioni della nostra formula:
SELECT numrows, 1.35166186417734E-04 + numrows * LOG(numrows) * 6.62193536908588E-06 AS costo previsto DA (VALUES(500000), (1000000), (10000000)) AS D(numrows);Utilizza le seguenti query per ottenere i costi della CPU stimati:
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT CHECKSUM(NEWID()) come myorderid FROM (SELECT TOP (10000000) O1.orderid FROM dbo.Orders AS O1 CROSS JOIN dbo.Orders AS O2) AS D ORDER BY myorderid OPTION(MAXDOP 1);Ho ottenuto i seguenti risultati:
numrows rapporto costo stimato costo previsto ----------- --------------- -------------- --- --- 500000 43.4479 43.448 1.0000 1000000 91.4856 91.486 1.0000 10000000 1067.3300 1067.340 1.0000Sembra che la nostra formula per i numeri grandi funzioni abbastanza bene.
Mettere tutto insieme
Il costo totale dell'applicazione di un aggregato di flussi con ordinamento esplicito per un numero ridotto di righe (<=5.000 righe) è:
+ + =
0.0112613
+ 9.99127891201865E-05 + @numrows * LOG(@ numrows) * 2.25061348918698E-06
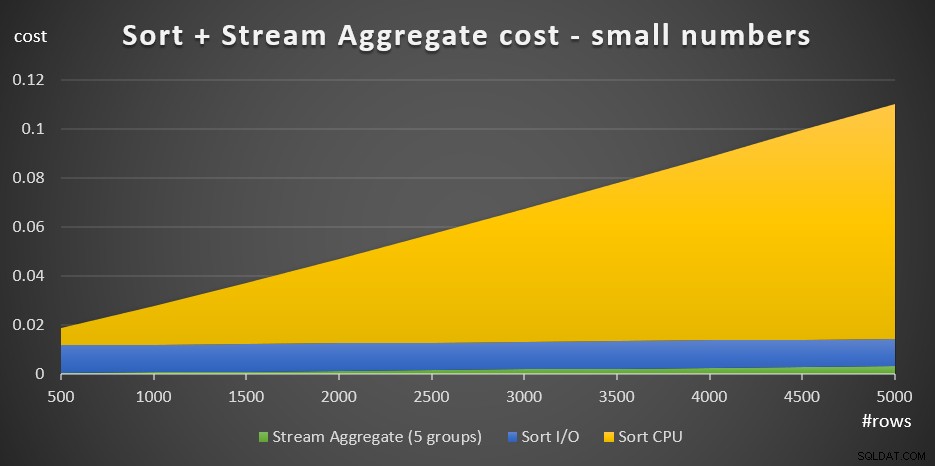
+ @numrows * 0.0000006 + @numgroups * 0.0000005La figura 3 ha un grafico ad area che mostra come questo costo si ridimensiona.
Figura 3:Costo dell'ordinamento + aggregato flusso per piccoli numeri di righeIl costo della CPU di ordinamento è la parte più sostanziale del costo aggregato totale di Sort + Stream. Tuttavia, con un numero ridotto di righe, il costo Stream Aggregate e la parte del costo Ordina I/O non sono del tutto trascurabili. In termini visivi, puoi vedere chiaramente tutte e tre le parti del grafico.
Per quanto riguarda un numero elevato di righe (>=20.000), la formula del costo è:
0.0112613
+ 1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06
+ @numrows * 0.0000006 + @numgroups * 0.0000005Non ho visto molto valore nel perseguire il modo esatto in cui i costi di confronto passano dalla piccola alla grande scala.
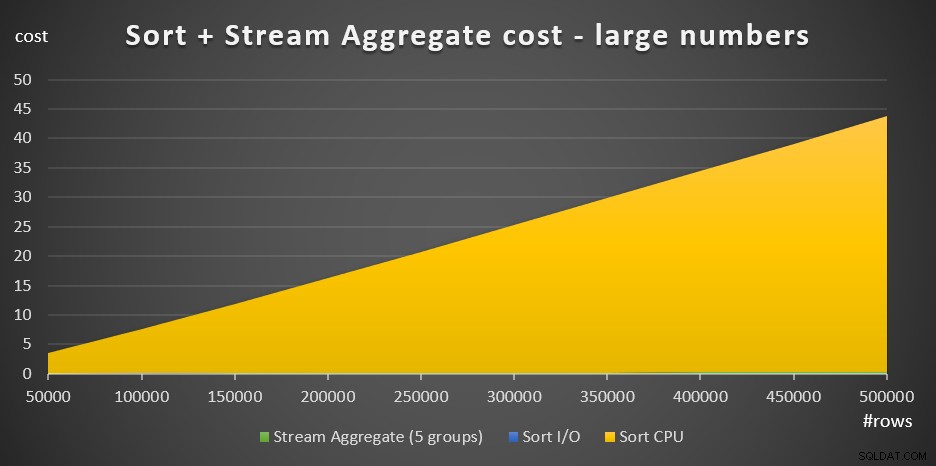
La Figura 4 ha un grafico ad area che mostra come il costo scala per grandi numeri.
Figura 4:Costo dell'ordinamento + aggregato del flusso per un numero elevato di righeCon un numero elevato di righe, il costo Stream Aggregate e Ordina I/O sono così trascurabili rispetto al costo della CPU Ordina che non sono nemmeno visibili ad occhio nudo nel grafico. Inoltre è trascurabile anche la parte del costo della CPU di Sort attribuita al lavoro di avvio. Pertanto, l'unica parte del calcolo dei costi veramente significativa è il costo totale di confronto:
@numrows * LOG(@numrows) *Ciò significa che quando è necessario valutare il ridimensionamento della strategia Sort + Stream Aggregate, è possibile semplificarla solo per questa parte dominante. Ad esempio, se devi valutare in che modo il costo scalerebbe da 100.000 righe a 100.000.000 di righe, puoi utilizzare la formula (notare che il costo di confronto è irrilevante):
(100000000 * LOG(100000000)*) / (100000 * LOG(100000)*) =1600Questo ti dice che quando il numero di righe aumenta da 100.000 di un fattore 1.000 a 100.000.000, il costo stimato aumenta di un fattore 1.600.
Il ridimensionamento da 1.000.000 a 1.000.000.000 di righe viene calcolato come:
(1000000000 * LOG(1000000000)) / (1000000 * LOG(1000000)) =1500Cioè, quando il numero di righe aumenta da 1.000.000 di un fattore 1.000, il costo stimato aumenta di un fattore 1.500.
Queste sono osservazioni interessanti sul modo in cui la strategia Sort + Stream Aggregate scala. A causa del suo costo di avvio molto basso e del ridimensionamento lineare extra, ti aspetteresti che questa strategia funzioni bene con un numero molto piccolo di righe, ma non così bene con numeri grandi. Inoltre, il fatto che l'operatore Stream Aggregate da solo rappresenti una frazione così piccola del costo rispetto a quando è necessario anche un ordinamento, ti dice che puoi ottenere prestazioni significativamente migliori se la situazione è tale da poter creare un indice di supporto .
Nella parte successiva della serie, tratterò il ridimensionamento dell'algoritmo Hash Aggregate. Se ti piace questo esercizio di cercare di capire le formule di costo, vedi se riesci a capirlo per questo algoritmo. L'importante è capire i fattori che lo influenzano, il modo in cui si ridimensiona e le condizioni in cui funziona meglio degli altri algoritmi.