Questo articolo è il terzo di una serie sulle soglie di ottimizzazione per il raggruppamento e l'aggregazione dei dati. Nella parte 1 ho trattato l'algoritmo Stream Aggregate preordinato. Nella parte 2 ho trattato l'algoritmo Sort + Stream Aggregate non preordinato. In questa parte tratterò l'algoritmo Hash Match (Aggregate), che chiamerò semplicemente Hash Aggregate. Fornisco anche un riepilogo e un confronto tra gli algoritmi che tratterò nella Parte 1, Parte 2 e Parte 3.
Userò lo stesso database di esempio chiamato PerformanceV3, che ho usato nei precedenti articoli della serie. Assicurati solo che prima di eseguire gli esempi nell'articolo, esegui prima il codice seguente per eliminare un paio di indici non necessari:
DROP INDEX idx_nc_sid_od_cid SU dbo.Orders;DROP INDEX idx_unc_od_oid_i_cid_eid SU dbo.Orders;
Gli unici due indici che dovrebbero essere lasciati in questa tabella sono idx_cl_od (raggruppato con orderdate come chiave) e PK_Orders (non raggruppato con orderid come chiave).
Aggregato hash
L'algoritmo Hash Aggregate organizza i gruppi in una tabella hash basata su una funzione hash scelta internamente. A differenza dell'algoritmo Stream Aggregate, non è necessario utilizzare le righe in ordine di gruppo. Considera la seguente query (la chiameremo Query 1) come esempio (forzando un aggregato hash e un piano seriale):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1);
La figura 1 mostra il piano per la query 1.
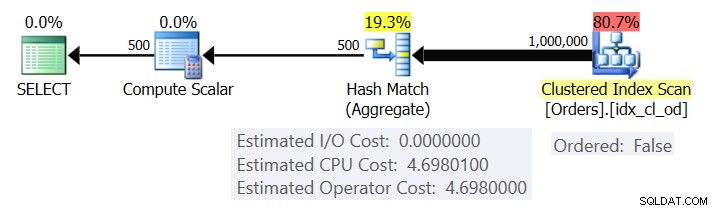
Figura 1:piano per la query 1
Il piano esegue la scansione delle righe dall'indice cluster utilizzando una proprietà Ordered:False (la scansione non è necessaria per recapitare le righe ordinate dalla chiave dell'indice). In genere, l'ottimizzatore preferirà eseguire la scansione dell'indice di copertura più stretto, che nel nostro caso risulta essere l'indice cluster. Il piano crea una tabella hash con le colonne raggruppate e gli aggregati. La nostra query richiede un aggregato COUNT di tipo INT. Il piano in realtà lo calcola come un valore tipizzato BIGINT, da cui l'operatore Calcola scalare, applicando la conversione implicita a INT.
Microsoft non condivide pubblicamente gli algoritmi hash che utilizzano. Questa è una tecnologia molto proprietaria. Tuttavia, per illustrare il concetto, supponiamo che SQL Server utilizzi la funzione hash % 250 (modulo 250) per la nostra query precedente. Prima di elaborare qualsiasi riga, la nostra tabella hash ha 250 bucket che rappresentano i 250 possibili risultati della funzione hash (da 0 a 249). Poiché SQL Server elabora ogni riga, applica la funzione hash
orderid empid ------- ----- 320 330 5660 253820 3850 11000 255700 31240 253350 4400 255
La figura 2 mostra tre stati della tabella hash:prima dell'elaborazione di qualsiasi riga, dopo l'elaborazione delle prime 5 righe e dopo l'elaborazione delle prime 10 righe. Ciascun elemento nell'elenco collegato contiene la tupla (empid, COUNT(*)).
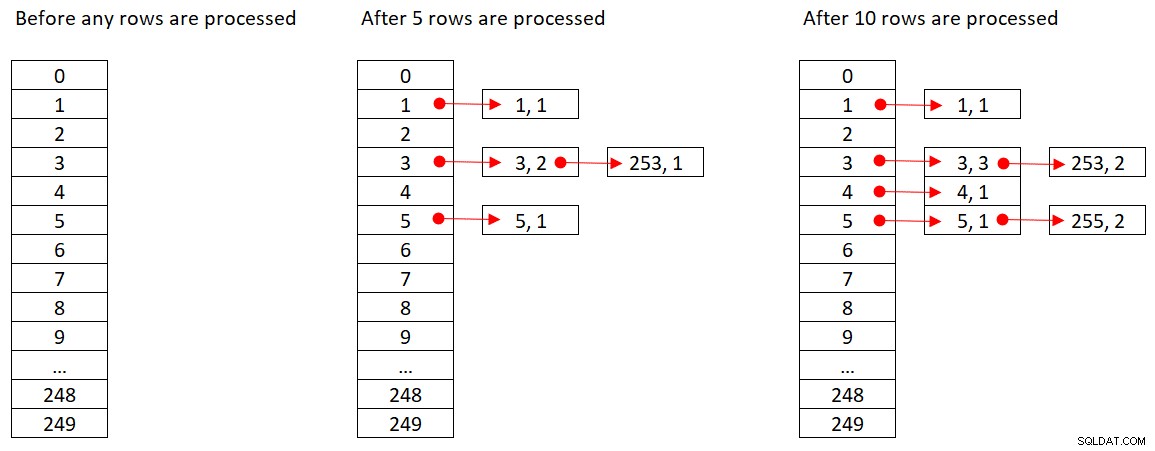
Figura 2:Stati della tabella hash
Una volta che l'operatore Hash Aggregate ha terminato di consumare tutte le righe di input, la tabella hash ha tutti i gruppi con lo stato finale dell'aggregato.
Come l'operatore Sort, l'operatore Hash Aggregate richiede una concessione di memoria e, se esaurisce la memoria, deve essere trasferito su tempdb; tuttavia, mentre l'ordinamento richiede una concessione di memoria proporzionale al numero di righe da ordinare, l'hashing richiede una concessione di memoria proporzionale al numero di gruppi. Quindi, specialmente quando il set di raggruppamento ha un'alta densità (numero ridotto di gruppi), questo algoritmo richiede molta meno memoria rispetto a quando è richiesto l'ordinamento esplicito.
Considera le seguenti due query (chiamale Query 1 e Query 2):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1); SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (ORDER GROUP, MAXDOP 1);
La figura 3 confronta le concessioni di memoria per queste query.

Figura 3:Piani per Query 1 e Query 2
Nota la grande differenza tra le concessioni di memoria nei due casi.
Per quanto riguarda il costo dell'operatore Hash Aggregate, tornando alla Figura 1, si noti che non c'è alcun costo di I/O, ma solo un costo della CPU. Quindi, prova a decodificare la formula dei costi della CPU utilizzando tecniche simili a quelle che ho trattato nelle parti precedenti della serie. I fattori che possono potenzialmente influenzare il costo dell'operatore sono il numero di righe di input, il numero di gruppi di output, la funzione di aggregazione utilizzata e il raggruppamento per (cardinalità del gruppo di raggruppamento, tipi di dati utilizzati).
Ti aspetteresti che questo operatore abbia un costo di avvio in preparazione per la creazione della tabella hash. Ti aspetteresti anche che si ridimensioni in modo lineare rispetto al numero di righe e gruppi. Questo è davvero quello che ho trovato. Tuttavia, mentre i costi degli operatori Stream Aggregate e Sort non sono influenzati da ciò che si raggruppa, sembra che il costo dell'operatore Hash Aggregate lo sia, sia in termini di cardinalità del set di raggruppamento che di tipi di dati utilizzati.
Per osservare che la cardinalità del raggruppamento incide sul costo dell'operatore, controlla i costi della CPU degli operatori Hash Aggregate nei piani per le seguenti query (chiamatele Query 3 e Query 4):
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 50 AS grp1, orderid % 20 AS grp2, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 50, orderid % 20 OPTION(HASH GROUP, MAXDOP 1 );
Ovviamente, vuoi assicurarti che il numero stimato di righe di input e gruppi di output sia lo stesso in entrambi i casi. I piani stimati per queste query sono mostrati nella Figura 4.
Figura 4:Piani per Query 3 e Query 4
Come puoi vedere, il costo della CPU dell'operatore Hash Aggregate è 0,16903 quando si raggruppa per una colonna intera e 0,174016 quando si raggruppa per due colonne intere, con tutto il resto uguale. Ciò significa che la cardinalità dell'insieme di raggruppamento incide effettivamente sul costo.
Per quanto riguarda se il tipo di dati dell'elemento raggruppato influisce sul costo, ho utilizzato le seguenti query per verificarlo (chiamatele Query 5, Query 6 e Query 7):
SELECT CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT) AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY CAST(orderid AS SMALLINT) % OPZIONE CAST(1000 AS SMALLINT)(GRUPPO HASH, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT) AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT) OPZIONE (GRUPPO HASH, MAXDOP 1);
I piani per tutte e tre le query hanno lo stesso numero stimato di righe di input e gruppi di output, ma ottengono tutti costi CPU stimati diversi (0,121766, 0,16903 e 0,171716), quindi il tipo di dati utilizzato influisce sui costi.
Anche il tipo di funzione aggregata sembra avere un impatto sul costo. Ad esempio, considera le seguenti due query (chiamale Query 8 e Query 9):
SELECT orderid % 1000 AS grp, COUNT(*) AS numorders FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1);
Il costo stimato della CPU per l'Hash Aggregate nel piano per la query 8 è 0,166344 e nella query 9 è 0,16903.
Potrebbe essere un esercizio interessante per cercare di capire esattamente in che modo la cardinalità dell'insieme di raggruppamento, i tipi di dati e la funzione di aggregazione utilizzati influiscono sul costo; Semplicemente non ho perseguito questo aspetto dei costi. Quindi, dopo aver scelto il gruppo di raggruppamento e la funzione di aggregazione per la tua query, puoi decodificare la formula dei costi. Ad esempio, eseguiamo il reverse engineering della formula dei costi della CPU per l'operatore Hash Aggregate quando si raggruppa per una singola colonna intera e si restituisce l'aggregato MAX(data ordine). La formula dovrebbe essere:
Costo CPU operatore =Utilizzando le tecniche che ho dimostrato nei precedenti articoli della serie, ho ottenuto la seguente formula di reverse engineering:
Costo CPU operatore =0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087Puoi verificare l'accuratezza della formula utilizzando le seguenti query:
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 2000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 2000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 3000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 3000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 6000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 6000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 5000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 5000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(HASH GROUP, MAXDOP 1);
Ottengo i seguenti risultati:
numrows numgroups Forecastedcost Costo stimato----------- ----------- ------------- ------- ------- 100000 1000 0.703315 0.703316100000 2000 0.721023 0.721024200000 3000 1.40659 1.40659200000 6000 1.45972 1.45972500000 5000 3.44558 3.445500000 10000 3.53412 3.53412La formula sembra essere azzeccata.
Riepilogo e confronto costi
Ora abbiamo le formule di costo per le tre strategie disponibili:Stream Aggregate preordinato, Sort + Stream Aggregate e Hash Aggregate. La tabella seguente riassume e confronta le caratteristiche di costo dei tre algoritmi:
| Aggregato di streaming preordinato | Ordina + aggrega Stream | Aggregato hash | |
| Formula | @numrows * 0.0000006 + @numgroups * 0.0000005 | 0,0112613 + Numero ridotto di righe: 9.99127891201865E-05 + @numrows * LOG(@numrows) * 2.25061348918698E-06 Numero elevato di righe: 1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06 + @numrows * 0.0000006 + @numgroups * 0.0000005 | 0.017749 + @numrows * 0.00000667857 + @numgroups * 0.0000177087
* Raggruppamento per singola colonna intera, restituendo MAX( |
| Ridimensionamento | lineare | n log n | lineare |
| Costo di I/O di avvio | nessuno | 0,0112613 | nessuno |
| Costo CPU di avvio | nessuno | ~ 0,0001 | 0,017749 |
Secondo queste formule, la Figura 5 mostra il modo in cui ciascuna delle strategie viene ridimensionata per un numero diverso di righe di input, utilizzando come esempio un numero fisso di gruppi di 500.
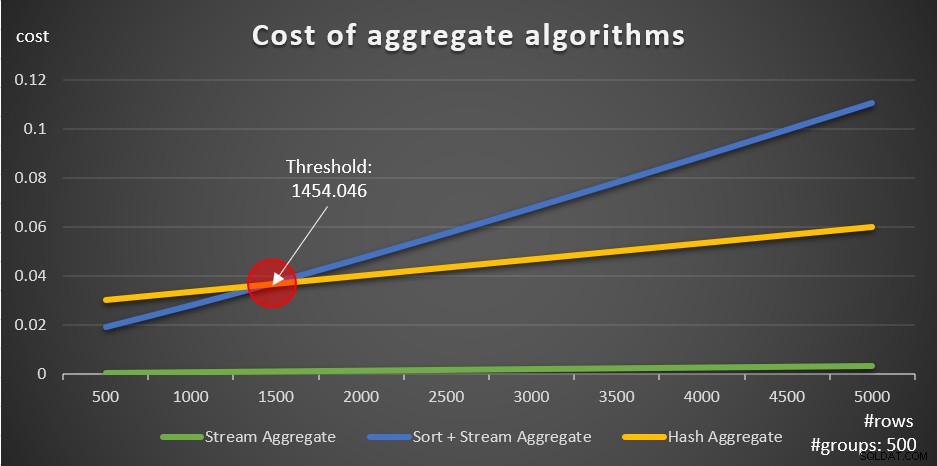
Figura 5:costo degli algoritmi aggregati
Puoi vedere chiaramente che se i dati sono preordinati, ad esempio in un indice di copertura, la strategia Stream Aggregate preordinata è l'opzione migliore, indipendentemente dal numero di righe coinvolte. Si supponga, ad esempio, di dover interrogare la tabella Ordini e calcolare la data massima dell'ordine per ciascun dipendente. Crei il seguente indice di copertura:
CREA INDEX idx_eid_od SU dbo.Orders(empid, orderdate);
Ecco cinque query che emulano una tabella Ordini con diversi numeri di righe (10.000, 20.000, 30.000, 40.000 e 50.000):
SELECT empid, MAX(data ordine) AS maxod FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (30000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (40000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (50000) * FROM dbo.Orders) AS D GROUP BY empid;
La figura 6 mostra i piani per queste query.
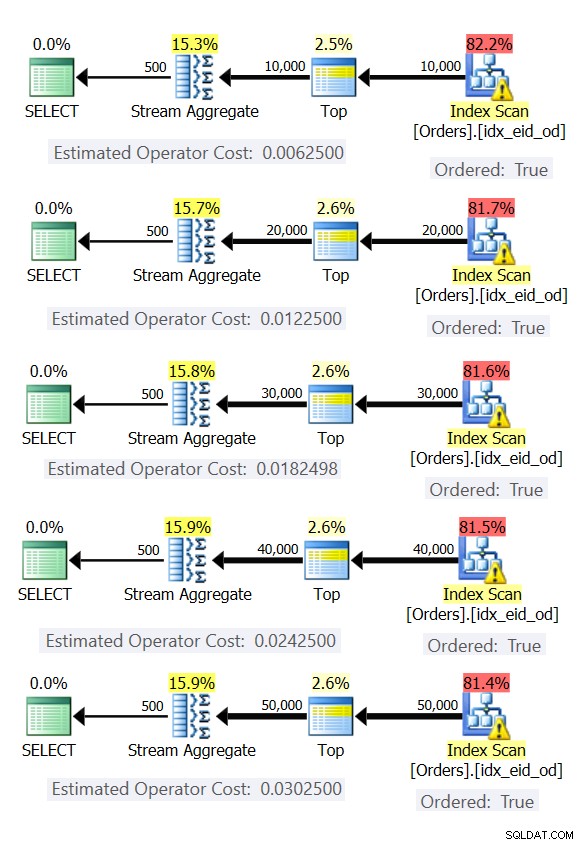
Figura 6:piani con strategia Stream Aggregate preordinata
In tutti i casi, i piani eseguono una scansione ordinata dell'indice di copertura e applicano l'operatore Stream Aggregate senza la necessità di un ordinamento esplicito.
Usa il codice seguente per eliminare l'indice che hai creato per questo esempio:
DROP INDEX idx_eid_od SU dbo.Orders;
L'altra cosa importante da notare sui grafici nella Figura 5 è cosa succede quando i dati non sono preordinati. Ciò accade quando non è presente alcun indice di copertura, nonché quando si raggruppano per espressioni manipolate anziché per colonne di base. Esiste una soglia di ottimizzazione, nel nostro caso a 1454.046 righe, al di sotto della quale la strategia Sort + Stream Aggregate ha un costo inferiore e al di sopra o al di sopra della quale la strategia Hash Aggregate ha un costo inferiore. Ciò ha a che fare con il fatto che il primo ha un costo di avvio inferiore, ma si ridimensiona in modo n log n, mentre il secondo ha un costo di avvio più elevato ma si ridimensiona in modo lineare. Ciò rende il primo preferito con un numero ridotto di righe di input. Se le nostre formule di reverse engineering sono accurate, le seguenti due query (chiamatele Query 10 e Query 11) dovrebbero avere piani diversi:
SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1454) * FROM dbo.Orders) AS D GROUP BY orderid % 500; SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1455) * FROM dbo.Orders) AS D GROUP BY orderid % 500;
I piani per queste query sono mostrati nella Figura 7.
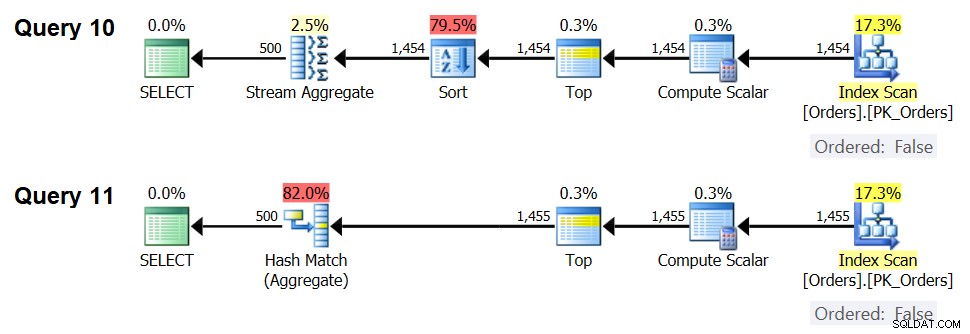
Figura 7:Piani per Query 10 e Query 11
Infatti, con 1.454 righe di input (al di sotto della soglia di ottimizzazione), l'ottimizzatore preferisce naturalmente l'algoritmo Sort + Stream Aggregate per la Query 10 e con 1.455 righe di input (al di sopra della soglia di ottimizzazione), l'ottimizzatore preferisce naturalmente l'algoritmo Hash Aggregate per la Query 11 .
Potenziale per operatore Adaptive Aggregate
Uno degli aspetti complicati delle soglie di ottimizzazione sono i problemi di sniffing dei parametri quando si utilizzano query sensibili ai parametri nelle stored procedure. Si consideri la seguente procedura memorizzata come esempio:
CREATE O ALTER PROC dbo.EmpOrders @initialorderid AS INTAS SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid>=@initialorderid GROUP BY empid;GO
Creare il seguente indice ottimale per supportare la query della stored procedure:
CREA INDEX idx_oid_i_eid SU dbo.Orders(orderid) INCLUDE(empid);
Hai creato l'indice con orderid come chiave per supportare il filtro dell'intervallo della query e hai incluso empid per la copertura. Questa è una situazione in cui non puoi davvero creare un indice che supporterà sia il filtro dell'intervallo che le righe filtrate preordinate dal set di raggruppamento. Ciò significa che l'ottimizzatore dovrà scegliere tra gli algoritmi Sort + stream Aggregate e Hash Aggregate. In base alle nostre formule di determinazione dei costi, la soglia di ottimizzazione è compresa tra 937 e 938 righe di input (ad esempio 937,5 righe).
Si supponga di eseguire la procedura memorizzata la prima volta con un ID ordine iniziale di input che fornisce un numero ridotto di corrispondenze (al di sotto della soglia):
EXEC dbo.EmpOrders @initialorderid =999991;
SQL Server produce un piano che usa l'algoritmo Sort + Stream Aggregate e memorizza il piano nella cache. Le esecuzioni successive riutilizzano il piano memorizzato nella cache, indipendentemente dal numero di righe coinvolte. Ad esempio, la seguente esecuzione ha un numero di corrispondenze superiore alla soglia di ottimizzazione:
EXEC dbo.EmpOrders @initialorderid =990001;
Tuttavia, riutilizza il piano memorizzato nella cache nonostante non sia ottimale per questa esecuzione. Questo è un classico problema di sniffing dei parametri.
SQL Server 2017 introduce funzionalità di elaborazione delle query adattive, progettate per far fronte a tali situazioni determinando durante l'esecuzione della query quale strategia utilizzare. Tra questi miglioramenti c'è un operatore Adaptive Join che durante l'esecuzione determina se attivare un algoritmo Loop o Hash basato su una soglia di ottimizzazione calcolata. La nostra storia aggregata richiede un operatore Adaptive Aggregate simile, che durante l'esecuzione sceglierebbe tra una strategia Sort + Stream Aggregate e una strategia Hash Aggregate, sulla base di una soglia di ottimizzazione calcolata. La figura 8 illustra uno pseudo piano basato su questa idea.
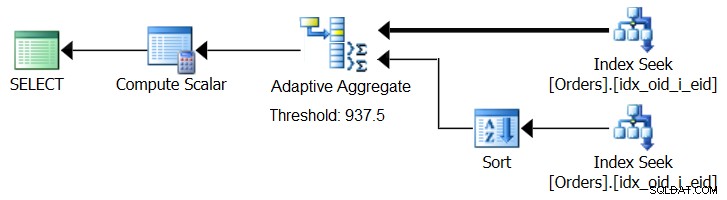
Figura 8:Pseudo piano con operatore Adaptive Aggregate
Per ora, per ottenere un piano del genere è necessario utilizzare Microsoft Paint. Ma poiché il concetto di elaborazione adattiva delle query è così intelligente e funziona così bene, è ragionevole aspettarsi di vedere ulteriori miglioramenti in quest'area in futuro.
Esegui il codice seguente per eliminare l'indice che hai creato per questo esempio:
DROP INDEX idx_oid_i_eid SU dbo.Orders;
Conclusione
In questo articolo ho trattato i costi e il ridimensionamento dell'algoritmo Hash Aggregate e lo ho confrontato con le strategie Stream Aggregate e Sort + Stream Aggregate. Ho descritto la soglia di ottimizzazione esistente tra le strategie Sort + Stream Aggregate e Hash Aggregate. Con un numero ridotto di righe di input si preferisce il primo e con un numero elevato il secondo. Ho anche descritto la possibilità di aggiungere un operatore Adaptive Aggregate, simile all'operatore Adaptive Join già implementato, per aiutare a gestire i problemi di sniffing dei parametri quando si utilizzano query sensibili ai parametri. Il mese prossimo continuerò la discussione trattando considerazioni sul parallelismo e casi che richiedono la riscrittura delle query.