L'anno scorso ho pubblicato un suggerimento chiamato Migliora l'efficienza di SQL Server passando a INSTEAD OF Triggers.
Il motivo principale per cui tendo a favorire un trigger INVECE DI, in particolare nei casi in cui mi aspetto molte violazioni della logica aziendale, è che sembra intuitivo che sarebbe più economico prevenire del tutto un'azione, piuttosto che andare avanti ed eseguirla (e log it!), solo per utilizzare un trigger AFTER per eliminare le righe incriminate (o ripristinare l'intera operazione). I risultati mostrati in quel suggerimento hanno dimostrato che questo era, in effetti, il caso - e sospetto che sarebbero ancora più pronunciati con indici più non raggruppati interessati dall'operazione.
Tuttavia, era su un disco lento e su uno dei primi CTP di SQL Server 2014. Nel preparare una diapositiva per una nuova presentazione che farò quest'anno sui trigger, ho scoperto che su una build più recente di SQL Server 2014:combinato con l'hardware aggiornato, è stato un po' più complicato dimostrare lo stesso delta nelle prestazioni tra un trigger AFTER e INSTEAD OF. Quindi ho deciso di scoprire il motivo, anche se ho subito capito che sarebbe stato più lavoro di quanto avessi mai fatto per una singola diapositiva.
Una cosa che voglio menzionare è che i trigger possono usare tempdb in modi diversi, e questo potrebbe spiegare alcune di queste differenze. Un trigger AFTER utilizza l'archivio versioni per le pseudo-tabelle inserite ed eliminate, mentre un trigger INSTEAD OF esegue una copia di questi dati in una tabella di lavoro interna. La differenza è sottile, ma vale la pena sottolineare.
Le variabili
Testerò vari scenari, tra cui:
- Tre diversi trigger:
- Un trigger AFTER che elimina righe specifiche che non riescono
- Un trigger AFTER che esegue il rollback dell'intera transazione se una riga non riesce
- Un trigger INSTEAD OF che inserisce solo le righe che passano
- Diversi modelli di ripristino e impostazioni di isolamento degli snapshot:
- COMPLETO con SNAPSHOT abilitato
- FULL con SNAPSHOT disabilitato
- SEMPLICE con SNAPSHOT abilitato
- SEMPLICE con SNAPSHOT disabilitato
- Diversi layout del disco*:
- Dati su SSD, accedi a HDD da 7200 RPM
- Dati su SSD, accedi a SSD
- Dati su HDD da 7200 RPM, accesso su SSD
- Dati su HDD da 7200 RPM, accesso su HDD da 7200 RPM
- Diversi tassi di errore:
- Tasso di errore del 10%, 25% e 50% su:
- Inserimento batch singolo di 20.000 righe
- 10 batch da 2.000 righe
- 100 batch di 200 righe
- 1.000 lotti di 20 righe
- 20.000 inserti singleton
*
tempdbè un singolo file di dati su un disco lento da 7200 RPM. Questo è intenzionale e ha lo scopo di amplificare eventuali colli di bottiglia causati dai vari usi ditempdb. Ho intenzione di rivisitare questo test ad un certo punto quandotempdbè su un SSD più veloce. - Tasso di errore del 10%, 25% e 50% su:
Ok, già TL;DR!
Se vuoi solo conoscere i risultati, salta giù. Tutto nel mezzo è solo uno sfondo e una spiegazione di come ho impostato ed eseguito i test. Non ho il cuore spezzato dal fatto che non tutti saranno interessati a tutte le minuzie.
Lo scenario
Per questo particolare insieme di test, lo scenario reale è quello in cui un utente sceglie un nome visualizzato e il trigger è progettato per rilevare i casi in cui il nome scelto viola alcune regole. Ad esempio, non può essere una variazione di "ninny-muggins" (puoi sicuramente usare la tua immaginazione qui).
Ho creato una tabella con 20.000 nomi utente univoci:
USE model; GO -- 20,000 distinct, good Names ;WITH distinct_Names AS ( SELECT Name FROM sys.all_columns UNION SELECT Name FROM sys.all_objects ) SELECT TOP (20000) Name INTO dbo.GoodNamesSource FROM ( SELECT Name FROM distinct_Names UNION SELECT Name + 'x' FROM distinct_Names UNION SELECT Name + 'y' FROM distinct_Names UNION SELECT Name + 'z' FROM distinct_Names ) AS x; CREATE UNIQUE CLUSTERED INDEX x ON dbo.GoodNamesSource(Name);
Quindi ho creato una tabella che sarebbe stata la fonte per i miei "nomi cattivi" da confrontare. In questo caso è solo ninny-muggins-00001 tramite ninny-muggins-10000 :
USE model;
GO
CREATE TABLE dbo.NaughtyUserNames
(
Name NVARCHAR(255) PRIMARY KEY
);
GO
-- 10,000 "bad" names
INSERT dbo.NaughtyUserNames(Name)
SELECT N'ninny-muggins-' + RIGHT(N'0000' + RTRIM(n),5)
FROM
(
SELECT TOP (10000) n = ROW_NUMBER() OVER (ORDER BY Name)
FROM dbo.GoodNamesSource
) AS x;
Ho creato queste tabelle nel model database in modo che ogni volta che creo un database, esista localmente e ho intenzione di creare molti database per testare la matrice dello scenario sopra elencata (piuttosto che modificare semplicemente le impostazioni del database, cancellare il registro, ecc.). Tieni presente che se crei oggetti nel modello a scopo di test, assicurati di eliminarli quando hai finito.
Per inciso, lascerò intenzionalmente violazioni chiave e altri errori nella gestione di questo, supponendo ingenuamente che il nome scelto venga verificato per l'unicità molto prima che venga tentato l'inserimento, ma all'interno della stessa transazione (proprio come il il controllo contro la tabella dei nomi cattivi potrebbe essere stato fatto in anticipo).
Per supportare questo, ho anche creato le seguenti tre tabelle quasi identiche in model , ai fini dell'isolamento del test:
USE model; GO -- AFTER (rollback) CREATE TABLE dbo.UserNames_After_Rollback ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Rollback(DateCreated) INCLUDE(Name); -- AFTER (delete) CREATE TABLE dbo.UserNames_After_Delete ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Delete(DateCreated) INCLUDE(Name); -- INSTEAD CREATE TABLE dbo.UserNames_Instead ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_Instead(DateCreated) INCLUDE(Name); GO
E i seguenti tre trigger, uno per ogni tabella:
USE model;
GO
-- AFTER (rollback)
CREATE TRIGGER dbo.trUserNames_After_Rollback
ON dbo.UserNames_After_Rollback
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
IF EXISTS
(
SELECT 1 FROM inserted AS i
WHERE EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
)
)
BEGIN
ROLLBACK TRANSACTION;
END
END
GO
-- AFTER (delete)
CREATE TRIGGER dbo.trUserNames_After_Delete
ON dbo.UserNames_After_Delete
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
DELETE d
FROM inserted AS i
INNER JOIN dbo.NaughtyUserNames AS n
ON i.Name = n.Name
INNER JOIN dbo.UserNames_After_Delete AS d
ON i.UserID = d.UserID;
END
GO
-- INSTEAD
CREATE TRIGGER dbo.trUserNames_Instead
ON dbo.UserNames_Instead
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserNames_Instead(Name)
SELECT i.Name
FROM inserted AS i
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
);
END
GO Probabilmente vorresti prendere in considerazione una gestione aggiuntiva per notificare all'utente che la sua scelta è stata annullata o ignorata, ma anche questo è omesso per semplicità.
La configurazione del test
Ho creato dati di esempio che rappresentano i tre tassi di errore che volevo testare, cambiando il 10 percento in 25 e poi 50 e aggiungendo anche queste tabelle a model :
USE model;
GO
DECLARE @pct INT = 10, @cap INT = 20000;
-- change this ----^^ to 25 and 50
DECLARE @good INT = @cap - (@cap*(@pct/100.0));
SELECT Name, rn = ROW_NUMBER() OVER (ORDER BY NEWID())
INTO dbo.Source10Percent FROM
-- change this ^^ to 25 and 50
(
SELECT Name FROM
(
SELECT TOP (@good) Name FROM dbo.GoodNamesSource ORDER BY NEWID()
) AS g
UNION ALL
SELECT Name FROM
(
SELECT TOP (@cap-@good) Name FROM dbo.NaughtyUserNames ORDER BY NEWID()
) AS b
) AS x;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.Source10Percent(rn);
-- and here as well -------------------------^^ Ogni tabella ha 20.000 righe, con una diversa combinazione di nomi che passeranno e non avranno esito negativo, e la colonna del numero di riga semplifica la suddivisione dei dati in batch di diverse dimensioni per test diversi, ma con tassi di errore ripetibili per tutti i test.
Ovviamente abbiamo bisogno di un posto dove catturare i risultati. Ho scelto di utilizzare un database separato per questo, eseguendo ogni test più volte, catturando semplicemente la durata.
CREATE DATABASE ControlDB; GO USE ControlDB; GO CREATE TABLE dbo.Tests ( TestID INT, DiskLayout VARCHAR(15), RecoveryModel VARCHAR(6), TriggerType VARCHAR(14), [snapshot] VARCHAR(3), FailureRate INT, [sql] NVARCHAR(MAX) ); CREATE TABLE dbo.TestResults ( TestID INT, BatchDescription VARCHAR(15), Duration INT );
Ho compilato dbo.Tests tabella con il seguente script, in modo da poter eseguire porzioni diverse per impostare i quattro database in modo che corrispondano ai parametri di test correnti. Nota che D:\ è un SSD, mentre G:\ è un disco da 7200 RPM:
TRUNCATE TABLE dbo.Tests;
TRUNCATE TABLE dbo.TestResults;
;WITH d AS
(
SELECT DiskLayout FROM (VALUES
('DataSSD_LogHDD'),
('DataSSD_LogSSD'),
('DataHDD_LogHDD'),
('DataHDD_LogSSD')) AS d(DiskLayout)
),
t AS
(
SELECT TriggerType FROM (VALUES
('After_Delete'),
('After_Rollback'),
('Instead')) AS t(TriggerType)
),
m AS
(
SELECT RecoveryModel = 'FULL'
UNION ALL SELECT 'SIMPLE'
),
s AS
(
SELECT IsSnapshot = 0
UNION ALL SELECT 1
),
p AS
(
SELECT FailureRate = 10
UNION ALL SELECT 25
UNION ALL SELECT 50
)
INSERT ControlDB.dbo.Tests
(
TestID,
DiskLayout,
RecoveryModel,
TriggerType,
IsSnapshot,
FailureRate,
Command
)
SELECT
TestID = ROW_NUMBER() OVER
(
ORDER BY d.DiskLayout, t.TriggerType, m.RecoveryModel, s.IsSnapshot, p.FailureRate
),
d.DiskLayout,
m.RecoveryModel,
t.TriggerType,
s.IsSnapshot,
p.FailureRate,
[sql]= N'SET NOCOUNT ON;
CREATE DATABASE ' + QUOTENAME(d.DiskLayout)
+ N' ON (name = N''data'', filename = N''' + CASE d.DiskLayout
WHEN 'DataSSD_LogHDD' THEN N'D:\data\data1.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data1.ldf'');'
WHEN 'DataSSD_LogSSD' THEN N'D:\data\data2.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data2.ldf'');'
WHEN 'DataHDD_LogHDD' THEN N'G:\data\data3.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data3.ldf'');'
WHEN 'DataHDD_LogSSD' THEN N'G:\data\data4.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data4.ldf'');' END
+ '
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET RECOVERY ' + m.RecoveryModel + ';'';'
+ CASE WHEN s.IsSnapshot = 1 THEN
'
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET ALLOW_SNAPSHOT_ISOLATION ON;'';
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET READ_COMMITTED_SNAPSHOT ON;'';'
ELSE '' END
+ '
DECLARE @d DATETIME2(7), @i INT, @LoopID INT, @loops INT, @perloop INT;
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT LoopID, loops, perloop FROM dbo.Loops;
OPEN c;
FETCH c INTO @LoopID, @loops, @perloop;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC sp_executesql N''TRUNCATE TABLE '
+ QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + ';'';
SELECT @d = SYSDATETIME(), @i = 1;
WHILE @i <= @loops
BEGIN
BEGIN TRY
INSERT ' + QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + '(Name)
SELECT Name FROM ' + QUOTENAME(d.DiskLayout) + '.dbo.Source' + RTRIM(p.FailureRate) + 'Percent
WHERE rn > (@i-1)*@perloop AND rn <= @i*@perloop;
END TRY
BEGIN CATCH
SET @TestID = @TestID;
END CATCH
SET @i += 1;
END
INSERT ControlDB.dbo.TestResults(TestID, LoopID, Duration)
SELECT @TestID, @LoopID, DATEDIFF(MILLISECOND, @d, SYSDATETIME());
FETCH c INTO @LoopID, @loops, @perloop;
END
CLOSE c;
DEALLOCATE c;
DROP DATABASE ' + QUOTENAME(d.DiskLayout) + ';'
FROM d, t, m, s, p; -- implicit CROSS JOIN! Do as I say, not as I do! :-) Quindi è stato semplice eseguire tutti i test più volte:
USE ControlDB;
GO
SET NOCOUNT ON;
DECLARE @TestID INT, @Command NVARCHAR(MAX), @msg VARCHAR(32);
DECLARE d CURSOR LOCAL FAST_FORWARD FOR
SELECT TestID, Command
FROM ControlDB.dbo.Tests ORDER BY TestID;
OPEN d;
FETCH d INTO @TestID, @Command;
WHILE @@FETCH_STATUS <> -1
BEGIN
SET @msg = 'Starting ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
EXEC sp_executesql @Command, N'@TestID INT', @TestID;
SET @msg = 'Finished ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
FETCH d INTO @TestID, @Command;
END
CLOSE d;
DEALLOCATE d;
GO 10
Sul mio sistema ci sono volute quasi 6 ore, quindi preparati a lasciare che questo segua il suo corso ininterrottamente. Inoltre, assicurati di non avere connessioni attive o finestre di query aperte rispetto al model database, altrimenti potresti ricevere questo errore quando lo script tenta di creare un database:
Impossibile ottenere il blocco esclusivo sul "modello" del database. Riprova l'operazione più tardi.
Risultati
Ci sono molti punti dati da esaminare (e tutte le query utilizzate per derivare i dati sono referenziate nell'Appendice). Tieni presente che ogni durata media indicata qui supera i 10 test e inserisce un totale di 100.000 righe nella tabella di destinazione.
Grafico 1 – Aggregati complessivi
Il primo grafico mostra gli aggregati complessivi (durata media) per le diverse variabili in isolamento (quindi *tutti* i test utilizzano un trigger AFTER che elimina, *tutti* i test utilizzano un trigger AFTER che esegue il rollback, ecc.).
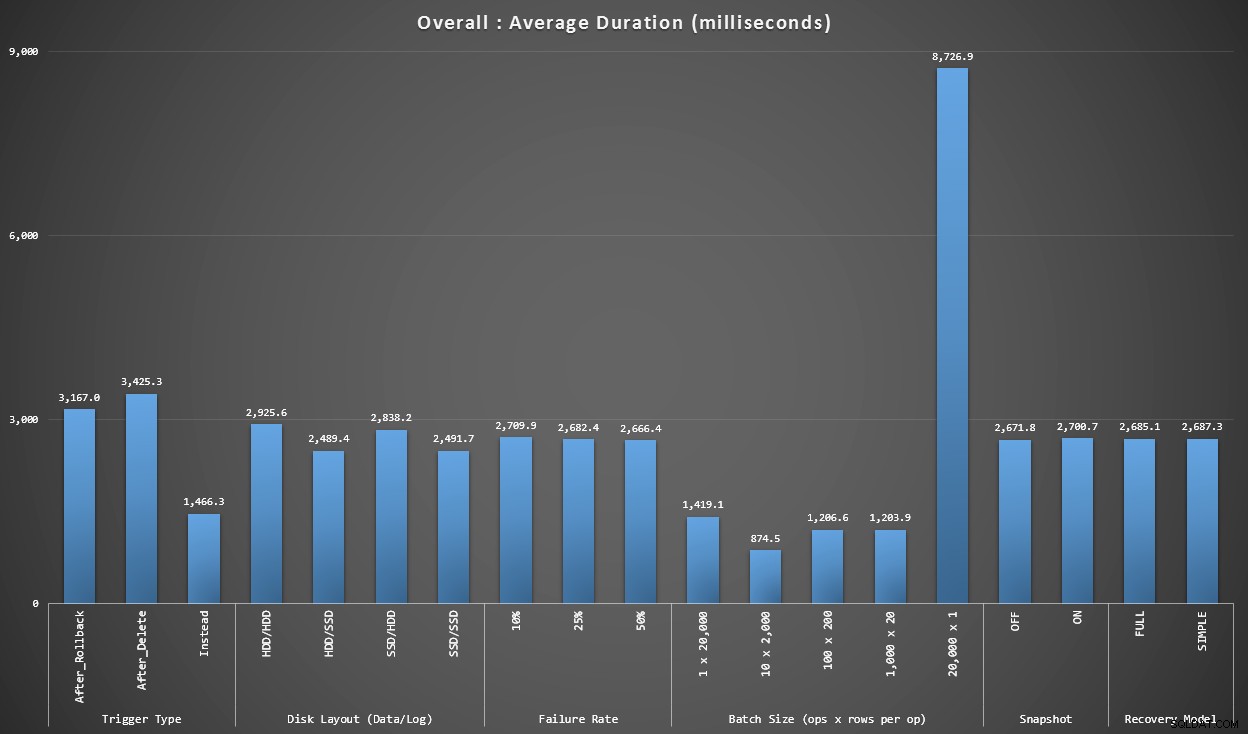
Durata media, in millisecondi, per ogni variabile isolata em>
Alcune cose ci saltano subito all'occhio:
- Il trigger INSTEAD OF qui è due volte più veloce di entrambi i trigger AFTER.
- Avere il registro delle transazioni su SSD ha fatto un po' la differenza. Posizione del file di dati molto meno.
- Il batch di 20.000 inserti singleton era 7-8 volte più lento di qualsiasi altra distribuzione batch.
- L'inserimento in batch singolo di 20.000 righe è stato più lento di qualsiasi distribuzione non singleton.
- Il tasso di errore, l'isolamento degli snapshot e il modello di ripristino hanno avuto un impatto minimo o nullo sulle prestazioni.
Grafico 2 – I migliori 10 in assoluto
Questo grafico mostra i 10 risultati più veloci quando viene considerata ogni variabile. Questi sono tutti INVECE DI trigger in cui la percentuale più alta di righe non riesce (50%). Sorprendentemente, il più veloce (anche se non di molto) aveva sia i dati che l'accesso sullo stesso HDD (non SSD). C'è un mix di layout del disco e modelli di ripristino qui, ma tutti e 10 avevano l'isolamento degli snapshot abilitato e i primi 7 risultati riguardavano tutti la dimensione del batch di 10 x 2.000 righe.
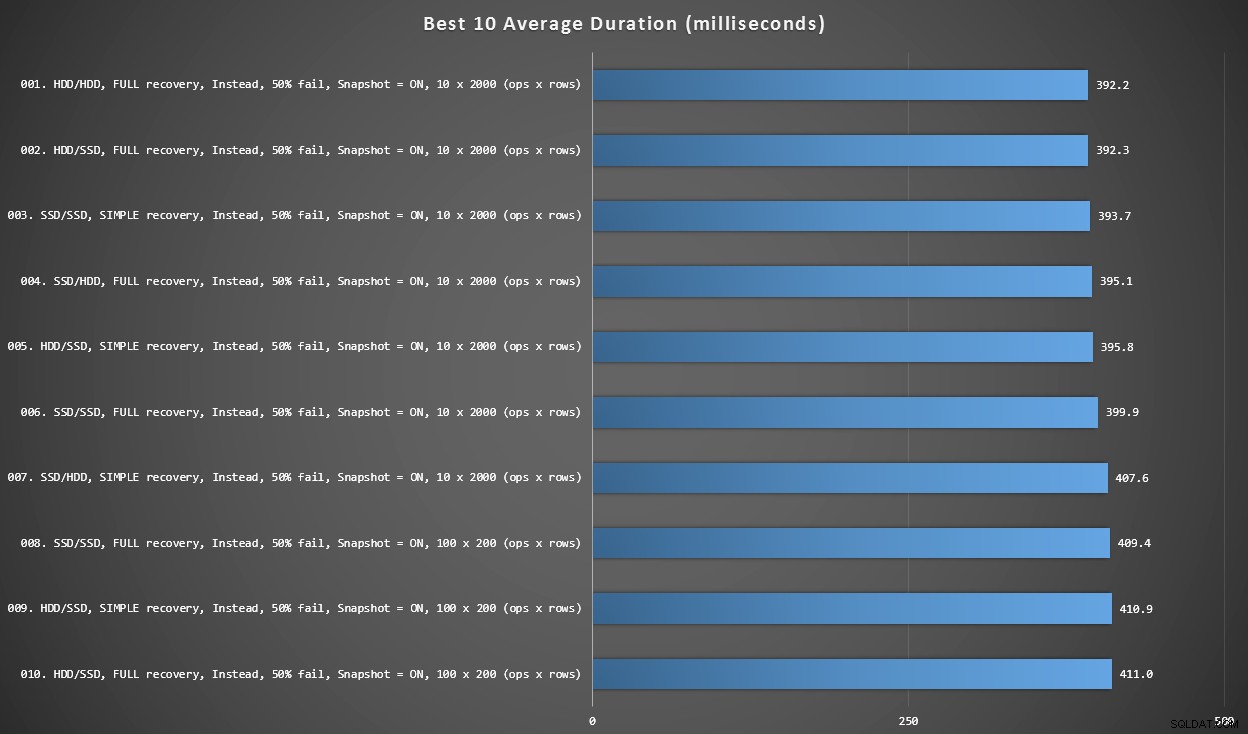
Le migliori 10 durate, in millisecondi, considerando ogni variabile
Il trigger AFTER più veloce, una variante ROLLBACK con un tasso di errore del 10% nella dimensione batch di 100 x 200 righe, è arrivato alla posizione n. 144 (806 ms).
Grafico 3 – I peggiori 10 in assoluto
Questo grafico mostra i 10 risultati più lenti quando si considera ogni variabile; tutti sono varianti AFTER, tutti coinvolgono i 20.000 inserti singleton e tutti hanno dati e accedono allo stesso HDD lento.
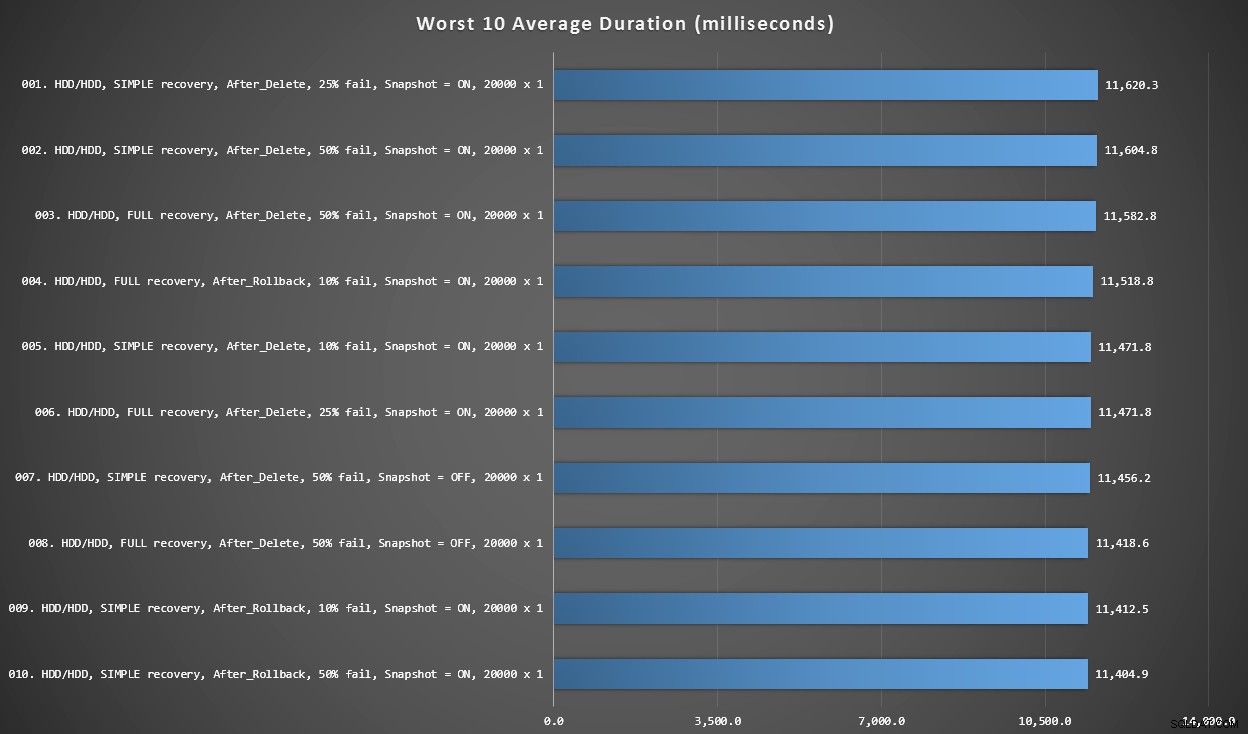
Le 10 durate peggiori, in millisecondi, considerando ogni variabile
Il test INSTEAD OF più lento era nella posizione n. 97, a 5.680 ms, un test di inserimento di 20.000 singleton in cui il 10% fallisce. È interessante anche osservare che nessun singolo trigger AFTER che utilizzava la dimensione del batch di 20.000 inserti singleton è andato meglio – infatti il 96° peggior risultato è stato un test AFTER (cancellazione) che è arrivato a 10.219 ms – quasi il doppio del successivo risultato più lento.
Grafico 4 – Tipo di disco di registro, inserimenti singleton
I grafici sopra ci danno un'idea approssimativa dei maggiori punti dolenti, ma sono troppo ingranditi o non abbastanza ingranditi. Questo grafico filtra i dati in base alla realtà:nella maggior parte dei casi questo tipo di operazione sarà un inserto singleton. Ho pensato di suddividerlo in base alla frequenza di errore e al tipo di disco su cui si trova il registro, ma guardare solo le righe in cui il batch è composto da 20.000 singoli inserti.
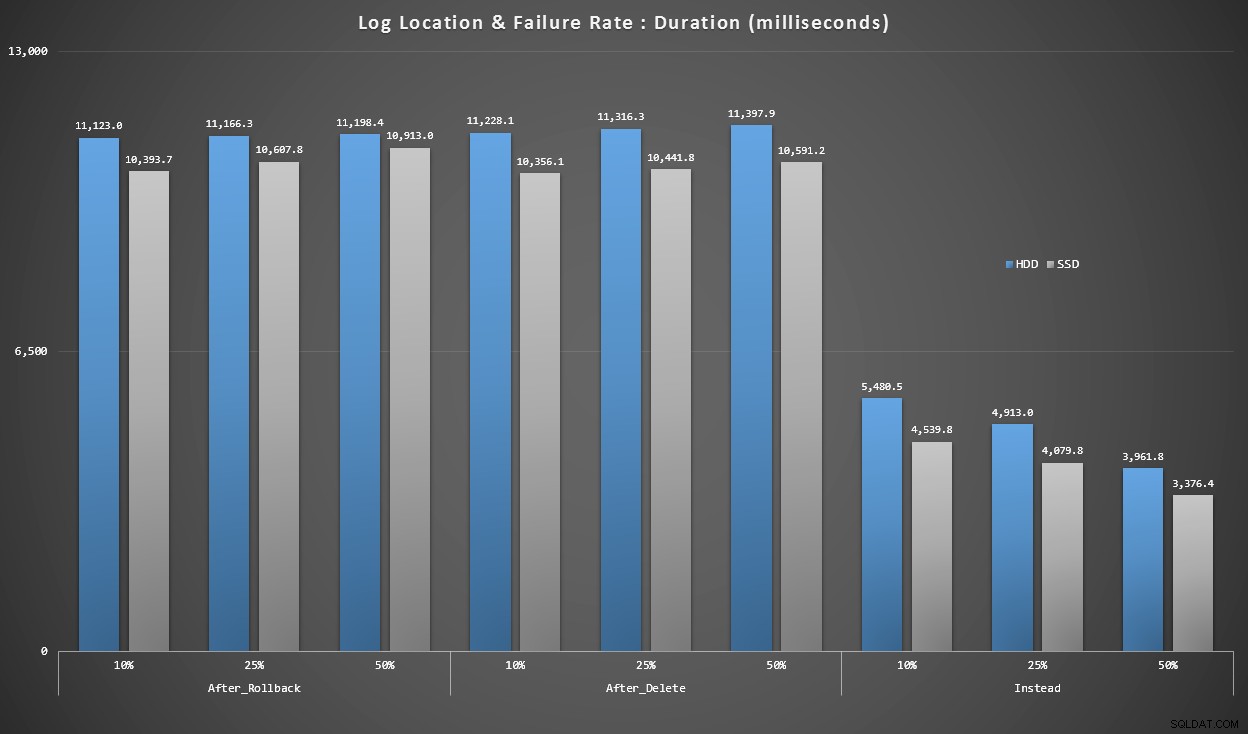
Durata, in millisecondi, raggruppata per tasso di errore e posizione del registro, per 20.000 singoli inserti
Qui vediamo che tutti i trigger AFTER hanno una media nell'intervallo di 10-11 secondi (a seconda della posizione del registro), mentre tutti i trigger INSTEAD OF sono ben al di sotto dei 6 secondi.
Conclusione
Finora, mi sembra chiaro che il trigger INSTEAD OF è vincente nella maggior parte dei casi, in alcuni casi più di altri (ad esempio, poiché il tasso di errore aumenta). Altri fattori, come il modello di recupero, sembrano avere un impatto molto minore sulle prestazioni complessive.
Se hai altre idee su come scomporre i dati o desideri una copia dei dati per eseguire le tue affettature e cubetti, faccelo sapere. Se desideri aiuto per configurare questo ambiente in modo da poter eseguire i tuoi test, posso aiutarti anche con quello.
Sebbene questo test dimostri che INSTEAD OF trigger vale sicuramente la pena considerare, non è l'intera storia. Ho letteralmente messo insieme questi trigger usando la logica che pensavo avesse più senso per ogni scenario, ma il codice trigger, come qualsiasi istruzione T-SQL, può essere ottimizzato per piani ottimali. In un post successivo, darò un'occhiata a una potenziale ottimizzazione che potrebbe rendere più competitivo il trigger AFTER.
Appendice
Query utilizzate per la sezione Risultati:
Grafico 1 – Aggregati complessivi
SELECT RTRIM(l.loops) + ' x ' + RTRIM(l.perloop), AVG(r.Duration*1.0) FROM dbo.TestResults AS r INNER JOIN dbo.Loops AS l ON r.LoopID = l.LoopID GROUP BY RTRIM(l.loops) + ' x ' + RTRIM(l.perloop); SELECT t.IsSnapshot, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.IsSnapshot; SELECT t.RecoveryModel, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.RecoveryModel; SELECT t.DiskLayout, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.DiskLayout; SELECT t.TriggerType, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.TriggerType; SELECT t.FailureRate, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.FailureRate;
Grafico 2 e 3:i migliori e i peggiori 10
;WITH src AS
(
SELECT DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
Batch = RTRIM(l.loops) + ' x ' + RTRIM(l.perloop),
Duration = AVG(Duration*1.0)
FROM dbo.Tests AS t
INNER JOIN dbo.TestResults AS tr
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON tr.LoopID = l.LoopID
GROUP BY DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
RTRIM(l.loops) + ' x ' + RTRIM(l.perloop)
),
agg AS
(
SELECT label = REPLACE(REPLACE(DiskLayout,'Data',''),'_Log','/')
+ ', ' + RecoveryModel + ' recovery, ' + TriggerType
+ ', ' + RTRIM(FailureRate) + '% fail'
+ ', Snapshot = ' + CASE IsSnapshot WHEN 1 THEN 'ON' ELSE 'OFF' END
+ ', ' + Batch + ' (ops x rows)',
best10 = ROW_NUMBER() OVER (ORDER BY Duration),
worst10 = ROW_NUMBER() OVER (ORDER BY Duration DESC),
Duration
FROM src
)
SELECT grp, label, Duration FROM
(
SELECT TOP (20) grp = 'best', label = RIGHT('0' + RTRIM(best10),2) + '. ' + label, Duration
FROM agg WHERE best10 <= 10
ORDER BY best10 DESC
UNION ALL
SELECT TOP (20) grp = 'worst', label = RIGHT('0' + RTRIM(worst10),2) + '. ' + label, Duration
FROM agg WHERE worst10 <= 10
ORDER BY worst10 DESC
) AS b
ORDER BY grp; Grafico 4 – Tipo di disco di registro, inserimenti singleton
;WITH x AS
(
SELECT
TriggerType,FailureRate,
LogLocation = RIGHT(DiskLayout,3),
Duration = AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON l.LoopID = tr.LoopID
WHERE l.loops = 20000
GROUP BY RIGHT(DiskLayout,3), FailureRate, TriggerType
)
SELECT TriggerType, FailureRate,
HDDDuration = MAX(CASE WHEN LogLocation = 'HDD' THEN Duration END),
SSDDuration = MAX(CASE WHEN LogLocation = 'SSD' THEN Duration END)
FROM x
GROUP BY TriggerType, FailureRate
ORDER BY TriggerType, FailureRate;