Hai difficoltà con SQL UNION? Succede se i risultati che hai combinato mettono in stallo il tuo SQL Server. Oppure un rapporto che ha funzionato prima fa apparire una casella con un'icona X rossa. Si verifica un errore "Clash tipo operando" che punta a una riga con UNION. Inizia il “fuoco”. Ti suona familiare?
Sia che tu stia utilizzando SQL UNION per un po' di tempo o che tu abbia appena iniziato, un cheat sheet o una serie concisa di note non farà male. Questo è ciò che otterrai oggi in questo post. Questo elenco offre 10 suggerimenti utili sia per i principianti che per i veterani. Inoltre, ci saranno esempi e alcune discussioni avanzate.

[sendpulse-form id=”11900″]
Ma prima di entrare nel primo punto, chiariamo i termini.
UNION è uno degli operatori di insiemi in SQL che combina 2 o più insiemi di risultati. Può tornare utile quando devi combinare nomi, statistiche mensili e altro da diverse fonti. E se utilizzi SQL Server, MySQL o Oracle, lo scopo, il comportamento e la sintassi saranno molto simili. Ma come funziona?
1. Usa SQL UNION per combinare Unico Record
L'utilizzo di UNION per combinare i set di risultati rimuove i duplicati.
Perché è importante?
Il più delle volte, non vuoi risultati con duplicati. Un rapporto con righe duplicate spreca inchiostro e carta nelle copie cartacee. E questo farà arrabbiare i tuoi utenti.
Come usarlo
Combina i risultati delle istruzioni SELECT con UNION in mezzo.
Prima di iniziare con l'esempio, prepariamo i nostri dati di esempio.
USE AdventureWorks
GO
IF OBJECT_ID ('dbo.Customer1', 'U') IS NOT NULL
DROP TABLE dbo.Customer1;
GO
IF OBJECT_ID ('dbo.Customer2', 'U') IS NOT NULL
DROP TABLE dbo.Customer2;
GO
IF OBJECT_ID ('dbo.Customer3', 'U') IS NOT NULL
DROP TABLE dbo.Customer3;
GO
-- Get 3 customer names with Andersen lastname
SELECT TOP 3
p.LastName
, p.FirstName
, c.AccountNumber
INTO dbo.Customer1
FROM Person.Person AS p
INNER JOIN Sales.Customer c
ON c.PersonID = p.BusinessEntityID
WHERE p.LastName = 'Andersen';
-- Make sure we have a duplicate in another table
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer2
FROM Customer1 c
-- Seems it's not enough. Let's have a 3rd copy
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer3
FROM Customer1 c
Utilizzeremo i dati generati dal codice sopra fino al terzo suggerimento. Ora che siamo pronti, ecco l'esempio:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
Abbiamo 3 copie degli stessi nomi dei clienti e prevediamo che i record univoci scompaiano. Guarda i risultati:
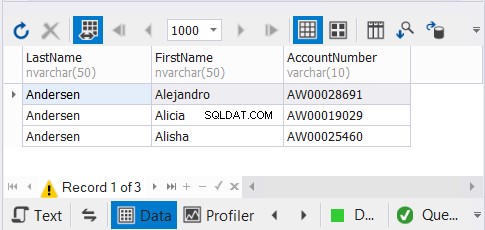
La soluzione dbForge Studio per SQL Server che utilizziamo per i nostri esempi mostra solo 3 record. Avrebbero potuto essere 9. Applicando UNION, abbiamo rimosso i duplicati.
Come funziona?
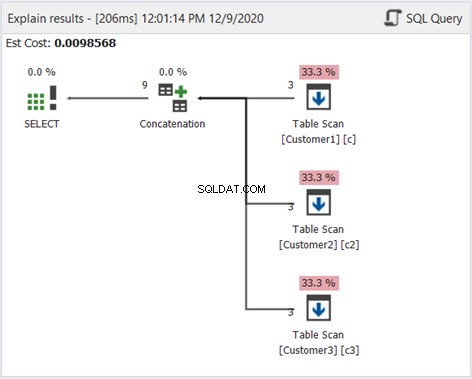
Il diagramma Plan in dbForge Studio mostra come SQL Server produce il risultato mostrato nella Figura 1. Dai un'occhiata:
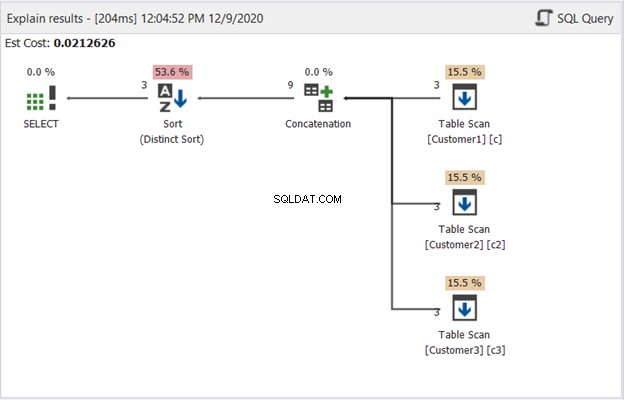
Per interpretare la Figura 2, inizia da destra a sinistra:
- Abbiamo recuperato 3 record da ciascun operatore Table Scan. Queste sono le 3 istruzioni SELECT dell'esempio sopra. Ogni riga che esce mostra "3" che significa 3 record ciascuno.
- L'operatore di concatenazione esegue la combinazione dei risultati. La riga che esce mostra "9", un output di 9 record dalla combinazione dei risultati.
- L'operatore Distinct Sort garantisce che i record univoci siano l'output finale. La riga che ne esce mostra "3", che è coerente con il numero di record nella Figura 1.
Il diagramma precedente mostra come UNION viene elaborato da SQL Server. Il numero e il tipo di operatori utilizzati possono variare a seconda della query e dell'origine dati sottostante. Ma in sintesi, un'UNIONE funziona come segue:
- Recupera i risultati di ogni istruzione SELECT.
- Combina i risultati con un operatore di concatenazione.
- Se i risultati combinati non sono univoci, SQL Server filtrerà i duplicati.
Tutti gli esempi di successo con UNION seguono questi passaggi di base.
2. Usa SQL UNION ALL per combinare record con duplicati
L'utilizzo di UNION ALL combina i set di risultati con i duplicati inclusi.
Perché è importante?
Potresti voler combinare i set di risultati e quindi ottenere i record con i duplicati per l'elaborazione in un secondo momento. Questa attività è utile per ripulire i tuoi dati.
Come usarlo
Combina i risultati delle istruzioni SELECT con UNION ALL in mezzo. Dai un'occhiata all'esempio:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION ALL
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
Il codice sopra emette 9 record come mostrato nella Figura 3:
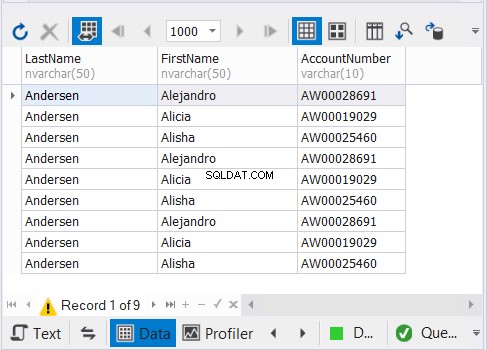
Come funziona?
Come prima, utilizziamo il diagramma Plan per sapere come funziona:
Fatta eccezione per l'ordinamento distinto nella figura 2, il diagramma sopra è lo stesso. È appropriato perché non vogliamo filtrare i duplicati.
Il diagramma sopra mostra come funziona UNION ALL. In sintesi, questi sono i passaggi che seguirà SQL Server:
- Recupera i risultati di ogni istruzione SELECT.
- Quindi, combina i risultati con un operatore di concatenazione.
Gli esempi di successo con UNION ALL seguono questo schema.
3. Puoi mescolare SQL UNION e UNION ALL ma raggrupparli con parentesi
Puoi combinare l'uso di UNION e UNION ALL in almeno tre istruzioni SELECT.
Come usarlo?
Combina i risultati delle istruzioni SELECT con UNION o UNION ALL in mezzo. Le parentesi raggruppano i risultati che si uniscono. Usiamo gli stessi dati per il prossimo esempio:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
(
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
)
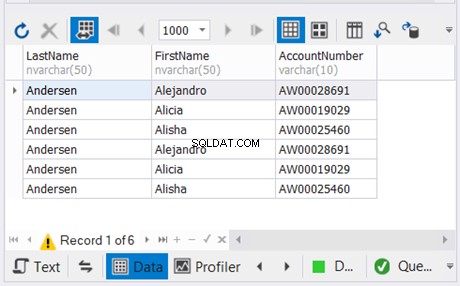
L'esempio precedente combina i risultati delle ultime due istruzioni SELECT senza duplicati. Quindi, lo combina con il risultato della prima istruzione SELECT. Il risultato è nella Figura 5 di seguito:
4. Le colonne di ciascuna istruzione SELECT dovrebbero avere tipi di dati compatibili
Le colonne in ogni istruzione SELECT che utilizza UNION possono avere tipi di dati diversi. È accettabile purché siano compatibili e consentano la conversione implicita su di essi. Il tipo di dati finale dei risultati combinati utilizzerà il tipo di dati con la precedenza più alta. Inoltre, la base della dimensione finale dei dati sono i dati con la dimensione maggiore. Nel caso di stringhe utilizzerà i dati con il maggior numero di caratteri.
Perché è importante?
Se è necessario inserire il risultato di UNION in una tabella, il tipo e la dimensione dei dati finali determineranno se si adatta o meno alla colonna della tabella di destinazione. In caso contrario, si verificherà un errore. Ad esempio, una delle colonne in UNION ha un tipo finale di NVARCHAR(50). Se la colonna della tabella di destinazione è VARCHAR(50), non puoi inserirla nella tabella.
Come funziona?
Non c'è modo migliore per spiegarlo di un esempio:
SELECT N'김지수' AS FullName
UNION
SELECT N'김제니' AS KoreanName
UNION
SELECT N'박채영' AS KoreanName
UNION
SELECT N'ลลิษา มโนบาล' AS ThaiName
UNION
SELECT 'Kim Ji-soo' AS EnglishName
UNION
SELECT 'Jennie Kim' AS EnglishName
UNION
SELECT 'Roseanne Park' AS EnglishName
UNION
SELECT 'Lalisa Manoban' AS EnglishName
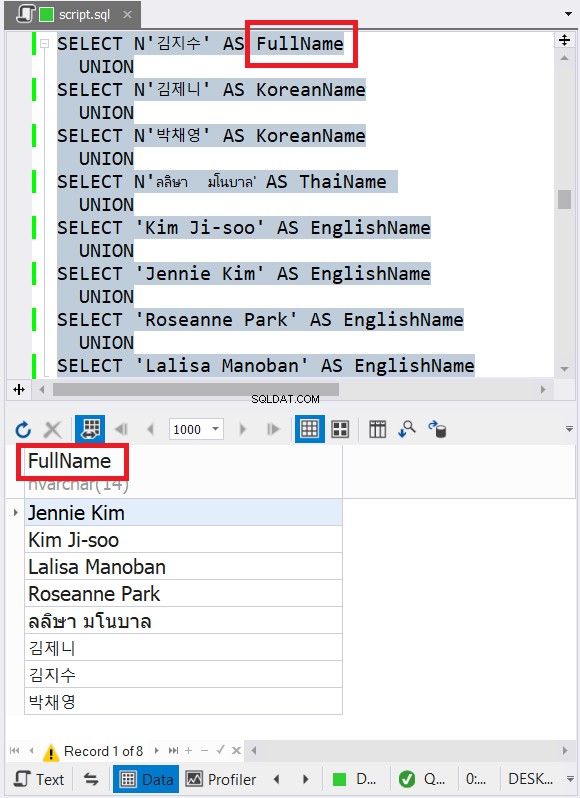
L'esempio sopra contiene dati con nomi di caratteri inglesi, coreani e tailandesi. Thai e coreano sono caratteri Unicode. I caratteri inglesi non lo sono. Quindi, quale pensi che saranno il tipo e la dimensione dei dati finali? dbForge Studio lo mostra nel set di risultati:
Hai notato il tipo di dati finale nella figura 6? Non può essere VARCHAR a causa dei caratteri Unicode. Quindi, deve essere NVARCHAR. Nel frattempo, la dimensione non può essere inferiore a 14 perché i dati con il maggior numero di caratteri hanno 14 caratteri. Vedi le didascalie in rosso nella Figura 6. È utile includere il tipo e la dimensione dei dati nell'intestazione della colonna in dbForge Studio.
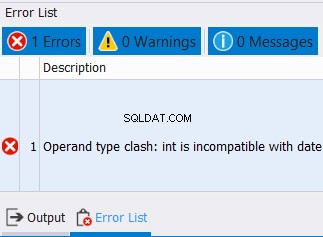
Non vale solo per i tipi di dati stringa. Vale anche per numeri e date. Nel frattempo, se si tenta di combinare dati con tipi di dati incompatibili, si verificherà un errore. Vedi l'esempio seguente:
SELECT CAST('12/25/2020' AS DATE) AS col1
UNION
SELECT CAST('10' AS INT) AS col1
Non possiamo combinare date e numeri interi in una colonna. Quindi, aspettati un errore come quello qui sotto:
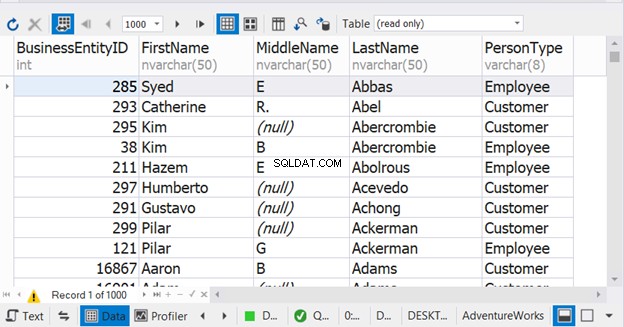
5. I nomi delle colonne dei risultati combinati utilizzeranno i nomi delle colonne della prima istruzione SELECT
Questo problema si riferisce al suggerimento precedente. Nota i nomi delle colonne nel codice nel suggerimento n. 4. Ci sono diversi nomi di colonna in ogni istruzione SELECT. Tuttavia, abbiamo visto il nome della colonna finale nel risultato combinato nella Figura 6 in precedenza. Pertanto, la base è il nome della colonna della prima istruzione SELECT.
Perché è importante?
Questo può essere utile quando è necessario scaricare il risultato di UNION in una tabella temporanea. Se è necessario fare riferimento ai nomi delle colonne nelle istruzioni successive, è necessario essere certi dei nomi. A meno che tu non stia utilizzando un editor di codice avanzato con IntelliSense, sei pronto per un altro errore nel tuo codice T-SQL.
Come funziona?
Vedere la Figura 8 per risultati più chiari sull'utilizzo di dbForge Studio:
6. Aggiungi ORDER BY nell'ultima istruzione SELECT con SQL UNION per ordinare i risultati
È necessario ordinare i risultati combinati. In una serie di istruzioni SELECT con UNION in mezzo, puoi farlo con la clausola ORDER BY nell'ultima istruzione SELECT.
Perché è importante?
Gli utenti desiderano ordinare i dati nel modo che preferiscono in app, pagine Web, report, fogli di lavoro e altro ancora.
Come usarlo
Utilizzare ORDER BY nell'ultima istruzione SELECT. Ecco un esempio:
SELECT
e.BusinessEntityID
,p.FirstName
,p.MiddleName
,p.LastName
,'Employee' AS PersonType
FROM HumanResources.Employee e
INNER JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityID
UNION
SELECT
c.PersonID
,p.FirstName
,p.MiddleName
,p.LastName
,'Customer' AS PersonType
FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
ORDER BY p.LastName, p.FirstName
L'esempio sopra fa sembrare che l'ordinamento avvenga solo nell'ultima istruzione SELECT. Ma non lo è. Funzionerà per il risultato combinato. Sarai nei guai se lo inserisci in ogni istruzione SELECT. Guarda il risultato:
Senza ORDER BY, il set di risultati conterrà tutti i dipendenti PersonType prima seguito da tutti i clienti PersonType . Tuttavia, la Figura 9 dimostra che i nomi diventano l'ordinamento del risultato combinato.
Se provi a inserire ORDER BY in ciascuna istruzione SELECT per ordinare, ecco cosa accadrà:
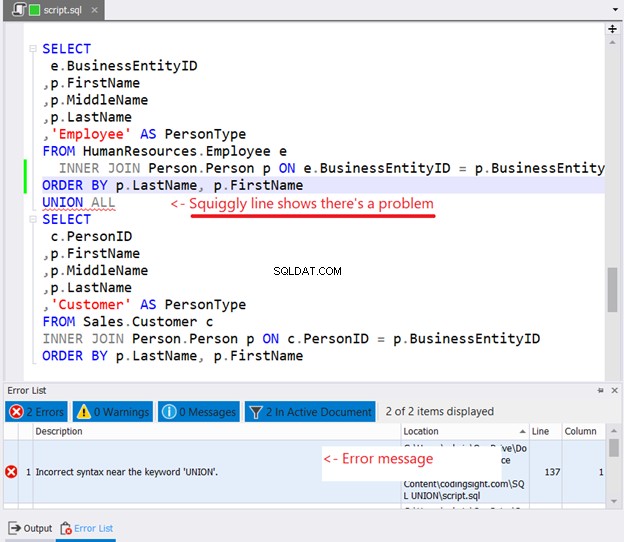
Hai visto la linea ondulata nella Figura 10? È un avvertimento. Se non te ne sei accorto e sei andato avanti, apparirà un errore nella finestra Elenco errori di dbForge Studio.
7. Le clausole WHERE e GROUP BY possono essere utilizzate in ogni istruzione SELECT con SQL UNION
La clausola ORDER BY non funziona in ogni istruzione SELECT con UNION nel mezzo. Tuttavia, le clausole WHERE e GROUP BY funzionano.
Perché è importante?
Potresti voler combinare i risultati di diverse query che filtrano, contano o riepilogano i dati. Ad esempio, puoi farlo per ottenere il totale degli ordini cliente per gennaio 2012 e confrontarlo con gennaio 2013, gennaio 2014 e così via.
Come usarlo
Inserire le clausole WHERE e/o GROUP BY in ciascuna istruzione SELECT. Dai un'occhiata all'esempio seguente:
USE AdventureWorks
GO
-- Get the number of orders for January 2012, 2013, 2014 for comparison
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
Il codice sopra combina il numero di ordini di gennaio per tre anni consecutivi. Ora controlla l'output:
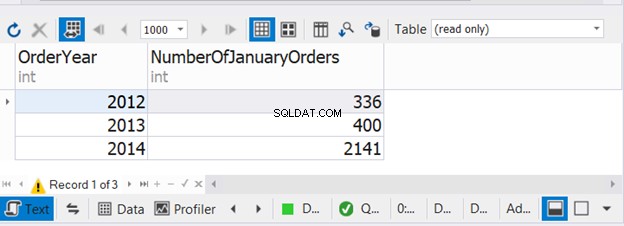
Questo esempio mostra che è possibile utilizzare WHERE e GROUP BY in ciascuna delle tre istruzioni SELECT con UNION.
8. SELECT INTO Funziona con SQL UNION
Quando devi inserire i risultati di una query con SQL UNION in una tabella, puoi farlo utilizzando SELECT INTO.
Perché è importante?
Ci saranno momenti in cui dovrai inserire i risultati di una query con UNION in una tabella per un'ulteriore elaborazione.
Come usarlo
Inserire la clausola INTO nella prima istruzione SELECT. Ecco un esempio:
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
INTO JanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
Ricorda di inserire solo una clausola INTO nella prima istruzione SELECT.
Come funziona
SQL Server segue il modello di elaborazione di UNION. Quindi, inserisce il risultato nella tabella specificata nella clausola INTO.
9. Differenzia SQL UNION da SQL JOIN
Sia SQL UNION che SQL JOIN combinano i dati della tabella, ma la differenza nella sintassi e nei risultati è come la notte e il giorno.
Perché è importante?
Se il tuo report o qualsiasi requisito necessita di un JOIN ma hai fatto un UNION, l'output sarà errato.
Come vengono utilizzati SQL UNION e SQL JOIN
È SQL UNION vs. JOIN. Questa è una delle query di ricerca e delle domande correlate che un principiante fa in Google quando impara a conoscere SQL UNION. Ecco la tabella delle differenze:
| SQL UNION | join SQL | |
| Cosa è combinato | Righe | Colonne (usando una chiave) |
| Numero di colonne per tabella | Lo stesso per tutte le tabelle | Variabile (Zero su tutte le colonne/tabella) |
In tutti i progetti con cui sono stato, SQL JOIN si applica la maggior parte del tempo. Ho avuto solo pochi casi che utilizzavano SQL UNION. Ma come hai visto finora, SQL UNION è tutt'altro che inutile.
10. SQL UNION ALL è più veloce di UNION
I diagrammi del piano nella Figura 2 e nella Figura 4 precedenti suggeriscono che UNION richiede un operatore aggiuntivo per garantire risultati unici. Ecco perché UNION ALL è più veloce.
Perché è importante?
Tu, i tuoi utenti, i tuoi clienti, il tuo capo, tutti vogliono risultati rapidi. Sapere che UNION ALL è più veloce di UNION ti fa chiedere cosa fare se hai bisogno di risultati combinati unici. C'è una soluzione, come vedrai più avanti.
Prestazioni di SQL UNION ALL e prestazioni di UNION
La Figura 2 e la Figura 4 ti hanno già dato un'idea di quale sia più veloce. Ma gli esempi di codice utilizzati sono semplici con un piccolo set di risultati. Aggiungiamo altri confronti utilizzando milioni di record per renderlo avvincente.
Per cominciare, prepariamo i dati:
SELECT TOP (2000000)
val = ROW_NUMBER() OVER (ORDER BY sod.SalesOrderDetailID)
INTO dbo.TestNumbers
FROM AdventureWorks.Sales.SalesOrderDetail sod
CROSS JOIN AdventureWorks.Sales.SalesOrderDetail sod2
Sono 2 milioni di record. Spero che sia abbastanza convincente. Ora, abbiamo i prossimi due esempi di query di seguito.
-- Using UNION ALL
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
-- Using UNION
SELECT
val
FROM TestNumbers tn
UNION
SELECT
val
FROM TestNumbers tn
Esaminiamo i processi coinvolti in queste query iniziando da quello più veloce.
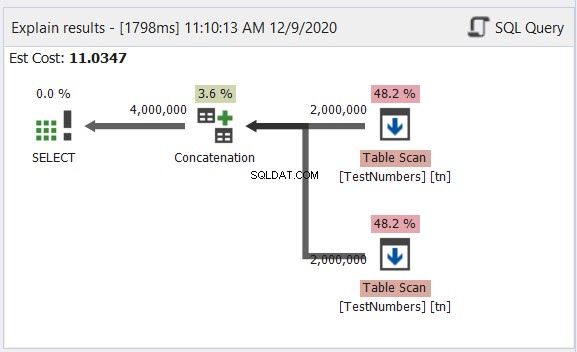
Analisi del diagramma del piano
Il diagramma in Figura 12 sembra tipico di un processo UNION ALL. Tuttavia, il risultato è di 4 milioni di risultati combinati. Vedere la freccia che esce dall'operatore di concatenazione. Tuttavia, in genere è perché non gestisce i duplicati.
Ora, abbiamo il diagramma della query UNION nella Figura 13:
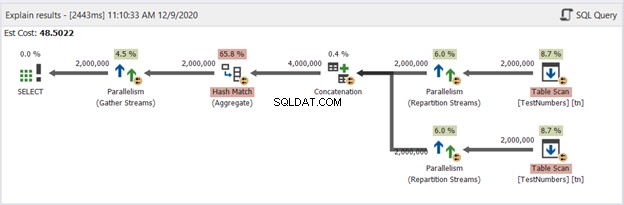
Questo non è più tipico. Il piano diventa un piano di query parallelo per gestire la rimozione dei duplicati in quattro milioni di righe. Il piano di query parallele significa che SQL Server deve dividere il processo per il numero di core del processore disponibili.
Interpretiamolo, partendo dagli operatori di destra andando verso sinistra:
- Dato che stiamo combinando una tabella su se stessa, SQL Server deve recuperarla due volte. Guarda le due scansioni tabella con due milioni di record ciascuna.
- Gli operatori di Repartition Stream controlleranno la distribuzione di ogni riga al successivo thread disponibile.
- La concatenazione raddoppia il risultato a quattro milioni. Questo sta ancora considerando il numero di core del processore.
- Si applica una corrispondenza hash per rimuovere i duplicati. Questo è un processo costoso con un costo dell'operatore del 65,8%. Di conseguenza, due milioni di record sono stati scartati.
- Gather Streams ricombina i risultati ottenuti in ciascun core del processore o thread in uno.
È troppo lavoro anche se il processo è diviso in più thread. Pertanto, concluderai che funzionerà più lentamente. Ma cosa succede se esiste una soluzione per ottenere record univoci con UNION ALL ma più velocemente di così?
Risultati unici ma correzione più rapida con UNION ALL – Come?
Non ti farò aspettare. Ecco il codice:
SELECT DISTINCT
val
FROM
(
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
) AS uniqtn
Questa può essere una soluzione scadente. Ma controlla il suo diagramma del piano nella Figura 14:
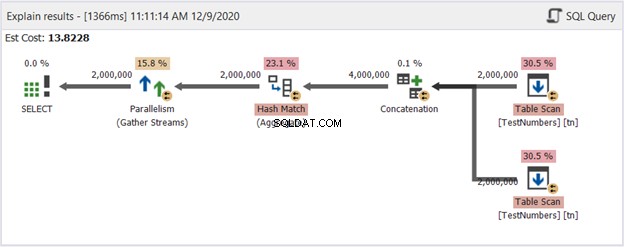
Quindi, cosa lo ha reso migliore? Se lo confronti con la Figura 13, vedrai che gli operatori di Repartition Stream sono spariti. Tuttavia, utilizza ancora più thread per portare a termine il lavoro. D'altra parte, implica che Query Optimizer ritenga questo processo più semplice da eseguire rispetto alla query che utilizza UNION.
Possiamo concludere con sicurezza che dovremmo evitare di usare UNION e utilizzare invece questo approccio? Affatto! Controlla sempre il diagramma del piano di esecuzione! Dipende sempre da cosa vuoi che SQL Server ti dia. Questo mostra solo che se ti imbatti in un muro delle prestazioni, devi cambiare il tuo approccio alla query.
Che ne dici delle statistiche I/O?
Non possiamo ignorare la quantità di risorse necessarie a SQL Server per elaborare i nostri esempi di query. Ecco perché dobbiamo anche esaminare le loro STATISTICHE IO. Confrontando le tre query precedenti, otteniamo le letture logiche seguenti:
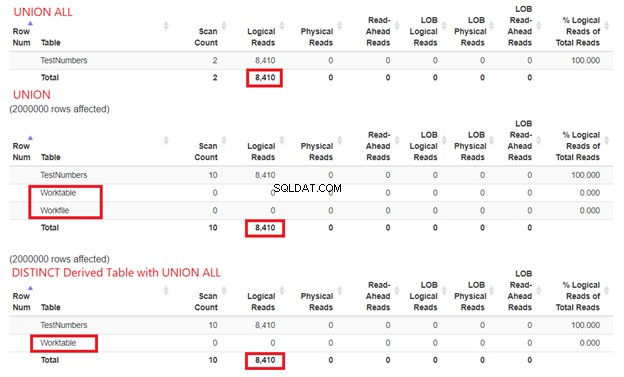
Dalla Figura 15, possiamo ancora concludere che UNION ALL è più veloce di UNION sebbene le letture logiche siano le stesse. La presenza di Worktable e File di lavoro mostra utilizzando tempdb per portare a termine il lavoro. Nel frattempo, quando utilizziamo SELECT DISTINCT da una tabella derivata con UNION ALL, il tempdb l'utilizzo è inferiore rispetto a UNION. Ciò riconferma ulteriormente che la nostra analisi dai diagrammi del piano precedenti è corretta.
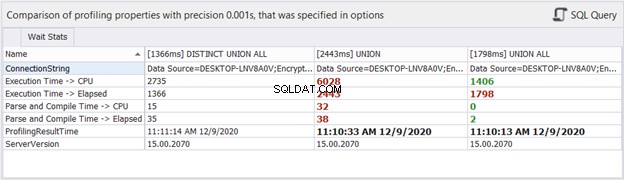
Che ne dici delle statistiche temporali?
Sebbene il tempo trascorso possa cambiare in ogni esecuzione che facciamo alle stesse query, può darci un'idea e aggiungere ulteriori prove alla nostra analisi. dbForge Studio mostra le differenze di orario delle tre query precedenti. Questo confronto è coerente con l'analisi precedente che abbiamo fatto.
Conclusione
Abbiamo coperto molte informazioni di base per fornire ciò di cui hai bisogno per utilizzare SQL UNION e UNION ALL. Potresti non ricordare tutto dopo aver letto questo post, quindi assicurati di aggiungere questa pagina ai preferiti.
Se ti piace il post, sentiti libero di condividerlo sui social media.