Le funzioni OVER e PARTITION BY sono entrambe funzioni utilizzate per suddividere in porzioni un set di risultati in base a criteri specificati.
Questo articolo spiega come queste due funzioni possono essere utilizzate insieme per recuperare i dati partizionati in modi molto specifici.
Preparazione di alcuni dati di esempio
Per eseguire le nostre query di esempio, creiamo prima un database chiamato "studentdb".
Esegui il seguente comando nella finestra della query:
CREATE DATABASE schooldb;
Successivamente, dobbiamo creare la tabella "student" all'interno del database "studentdb". La tabella degli studenti avrà cinque colonne:id, nome, età, sesso e punteggio_totale.
Come sempre, assicurati di aver eseguito correttamente il backup prima di sperimentare un nuovo codice. Se non sei sicuro, consulta questo articolo sul backup dei database di SQL Server.
Esegui la seguente query per creare la tabella studenti.
USE schooldb
CREATE TABLE student
(
id INT PRIMARY KEY IDENTITY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
age INT NOT NULL,
total_score INT NOT NULL,
) Infine, dobbiamo inserire alcuni dati fittizi con cui lavorare nel database.
USE schooldb
INSERT INTO student
VALUES ('Jolly', 'Female', 20, 500),
('Jon', 'Male', 22, 545),
('Sara', 'Female', 25, 600),
('Laura', 'Female', 18, 400),
('Alan', 'Male', 20, 500),
('Kate', 'Female', 22, 500),
('Joseph', 'Male', 18, 643),
('Mice', 'Male', 23, 543),
('Wise', 'Male', 21, 499),
('Elis', 'Female', 27, 400); Ora siamo pronti per lavorare su un problema e vedere chi possiamo usare Over and Partition By per risolverlo.
Problema
Abbiamo 10 record nella tabella degli studenti e vogliamo visualizzare il nome, l'ID e il sesso per tutti gli studenti, inoltre vogliamo anche visualizzare il numero totale di studenti che appartengono a ciascun genere, l'età media degli studenti studenti di ogni genere e la somma dei valori nella colonna total_score per ogni genere.
Il set di risultati che stiamo cercando è il seguente:
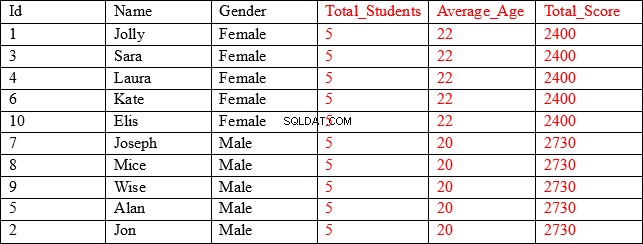
Come puoi vedere, le prime tre colonne (mostrate in nero) contengono valori individuali per ogni record, mentre le ultime tre colonne (mostrate in rosso) contengono valori aggregati raggruppati per la colonna del sesso. Ad esempio, nella colonna Average_Ege, le prime cinque righe mostrano l'età media e il punteggio totale di tutti i record in cui il sesso è Femminile.
Il nostro set di risultati contiene risultati aggregati uniti a colonne non aggregate.
Per recuperare i risultati aggregati, raggruppati per una particolare colonna, possiamo utilizzare la clausola GROUP BY come di consueto.
USE schooldb SELECT gender, count(gender) AS Total_Students, AVG(age) as Average_Age, SUM(total_score) as Total_Score FROM student GROUP BY gender
Vediamo come possiamo recuperare Total_Students, Average_Age e Total_Score degli studenti raggruppati per genere.
Vedrai i seguenti risultati:

Ora estendiamo questo e aggiungiamo "id" e "name" (le colonne non aggregate nell'istruzione SELECT) e vediamo se possiamo ottenere il risultato desiderato.
USE schooldb SELECT id, name, gender, count(gender) AS total_students, AVG(age) as Average_Age, SUM(total_score) as Total_Score FROM student GROUP BY gender
Quando esegui la query precedente, vedrai un errore:

L'errore dice che la colonna id della tabella studente non è valida all'interno dell'istruzione SELECT poiché stiamo usando la clausola GROUP BY nella query.
Ciò significa che dovremo applicare una funzione aggregata sulla colonna id o dovremo utilizzarla nella clausola GROUP BY. In breve, questo schema non risolve il nostro problema.
Soluzione che utilizza la dichiarazione JOIN
Una soluzione a questo sarebbe utilizzare l'istruzione JOIN per unire le colonne con risultati aggregati a colonne contenenti risultati non aggregati.
Per fare ciò, è necessaria una sottoquery che recuperi il genere, Total_Students, Average_Age e Total_Score degli studenti raggruppati per genere. Questi risultati possono quindi essere uniti ai risultati ottenuti dalla sottoquery con l'istruzione SELECT esterna. Questo verrà applicato alla colonna sesso della sottoquery contenente il risultato aggregato e alla colonna sesso della tabella studenti. L'istruzione SELECT esterna includerebbe colonne non aggregate, ad esempio "id" e "name", come di seguito.
USE schooldb SELECT id, name, Aggregation.gender, Aggregation.Total_students, Aggregation.Average_Age, Aggregation.Total_Score FROM student INNER JOIN (SELECT gender, count(gender) AS Total_students, AVG(age) AS Average_Age, SUM(total_score) AS Total_Score FROM student GROUP BY gender) AS Aggregation on Aggregation.gender = student.gender
La query di cui sopra ti darà il risultato desiderato ma non è la soluzione ottimale. Abbiamo dovuto usare un'istruzione JOIN e una sottoquery che aumenta la complessità dello script. Questa non è una soluzione elegante o efficiente.
Un approccio migliore consiste nell'utilizzare le clausole OVER e PARTITION BY insieme.
Soluzione che utilizza OVER e PARTITION BY
Per utilizzare le clausole OVER e PARTITION BY, è sufficiente specificare la colonna in base alla quale si desidera partizionare i risultati aggregati. Questo è meglio spiegato con l'uso di un esempio.
Diamo un'occhiata al raggiungimento del nostro risultato utilizzando OVER e PARTITION BY.
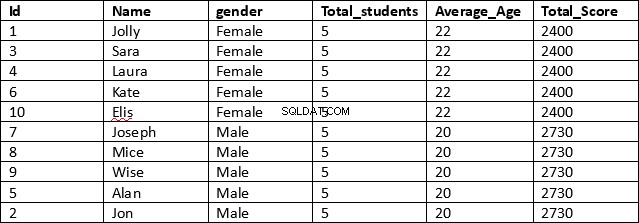
USE schooldb SELECT id, name, gender, COUNT(gender) OVER (PARTITION BY gender) AS Total_students, AVG(age) OVER (PARTITION BY gender) AS Average_Age, SUM(total_score) OVER (PARTITION BY gender) AS Total_Score FROM student
Questo è un risultato molto più efficiente. Nella prima riga dello script vengono recuperate le colonne id, name e gender. Queste colonne non contengono risultati aggregati.
Successivamente, per le colonne che contengono risultati aggregati, specifichiamo semplicemente la funzione aggregata, seguita dalla clausola OVER e poi tra parentesi specifichiamo la clausola PARTITION BY seguita dal nome della colonna che vogliamo che i nostri risultati siano partizionati come mostrato sotto.
Riferimenti
- Microsoft:comprensione della clausola OVER
- Midnight DBA – Introduzione a OVER e PARTITION BY
- StackOverflow – Differenza tra PARTITION BY e GROUP BY