SQL DISTINCT è buono (o cattivo) quando devi rimuovere i duplicati nei risultati?
Alcuni dicono che è buono e aggiungono DISTINCT quando compaiono i duplicati. Alcuni dicono che non va bene e suggeriscono di utilizzare GROUP BY senza una funzione di aggregazione. Altri affermano che DISTINCT e GROUP BY sono gli stessi quando devi rimuovere i duplicati.
Questo post analizzerà i dettagli per ottenere risposte corrette. Quindi, alla fine, utilizzerai la parola chiave migliore in base alla necessità. Cominciamo.
Un breve promemoria sulle basi dell'istruzione SQL SELECT DISTINCT
Prima di approfondire, ricordiamo cos'è l'istruzione SQL SELECT DISTINCT. Una tabella di database può includere valori duplicati per molte ragioni, ma potremmo voler ottenere solo i valori univoci. In questo caso, SELECT DISTINCT torna utile. Questa clausola DISTINCT fa in modo che l'istruzione SELECT recuperi solo record univoci.
La sintassi dell'istruzione è semplice:
SELECT DISTINCT column
FROM table_name
WHERE [condition];Qui, la condizione WHERE è facoltativa.
L'istruzione si applica sia a una singola colonna che a più colonne. La sintassi di questa istruzione applicata a più colonne è la seguente:
SELECT DISTINCT
column_name1,
column_name2,
column_nameN.
FROM
table_name;Tieni presente che lo scenario di query su più colonne suggerirà di utilizzare la combinazione di valori in tutte le colonne definite dall'istruzione per determinare l'unicità.
E ora, esploriamo l'uso pratico e i trucchi dell'applicazione dell'istruzione SELECT DISTINCT.
Come funziona SQL DISTINCT per rimuovere i duplicati
Ottenere risposte non è così difficile da trovare. SQL Server ci ha fornito piani di esecuzione per vedere come verrà elaborata una query per fornirci i risultati necessari.
La sezione seguente si concentra sul piano di esecuzione quando si utilizza DISTINCT. Devi premere Ctrl-M in SQL Server Management Studio prima di eseguire le query seguenti. Oppure, fai clic su Includi piano di esecuzione effettivo dalla barra degli strumenti.
Piani di query in SQL DISTINCT
Iniziamo confrontando 2 query. La prima non utilizzerà DISTINCT e la seconda query lo farà.
USE AdventureWorks
GO
-- Without DISTINCT. Duplicates included
SELECT Lastname FROM Person.Person;
-- With DISTINCT. Duplicates removed
SELECT DISTINCT Lastname FROM Person.Person;
Ecco il piano di esecuzione:
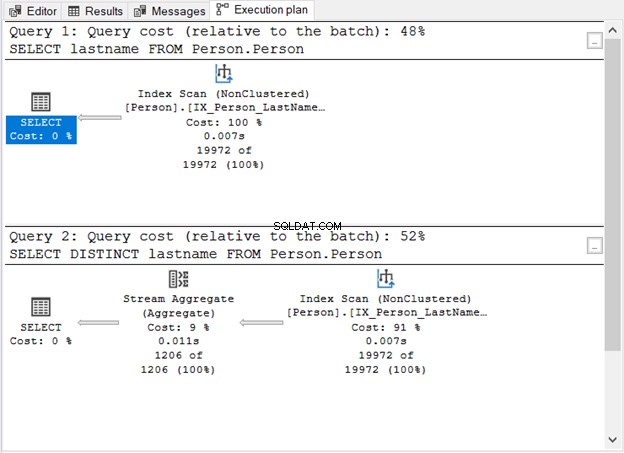
Cosa ci ha mostrato la Figura 1?
- Senza la parola chiave DISTINCT, la query è semplice.
- Appare un passaggio aggiuntivo dopo aver aggiunto DISTINCT.
- Il costo della query per l'utilizzo di DISTINCT è maggiore rispetto a quello senza.
- Entrambi hanno operatori di scansione dell'indice. Questo è comprensibile perché non c'è una clausola WHERE specifica nelle nostre domande.
- Il passaggio aggiuntivo, l'operatore Stream Aggregate, viene utilizzato per rimuovere i duplicati.
Il numero di letture logiche è lo stesso (107) se si controlla STATISTICS IO. Tuttavia, il numero di record è molto diverso. La prima query restituisce 19.972 righe. Nel frattempo, la seconda query restituisce 1.206 righe.
Quindi, non puoi aggiungere DISTINCT ogni volta che vuoi. Ma se hai bisogno di valori univoci, questo è un sovraccarico necessario.
Ci sono operatori utilizzati per generare valori univoci. Esaminiamone alcuni.
STREAM AGGREGATO
Questo è l'operatore che hai visto nella Figura 1. Accetta un singolo input e restituisce un risultato aggregato. Nella Figura 1, l'input proviene dall'operatore Index Scan. Tuttavia, Stream Aggregate ha bisogno di un input ordinato.
Come puoi vedere nella Figura 1, utilizza IX_Person_LastName_FirstName_MiddleName , un indice non univoco sui nomi. Poiché l'indice ordina già i record per nome, Stream Aggregate accetta l'input. Senza l'indice, Query Optimizer può scegliere di utilizzare un operatore di ordinamento aggiuntivo nel piano. E questo sarà più costoso. Oppure può utilizzare una corrispondenza hash.
HASH MATCH (AGGREGATO)
Un altro operatore utilizzato da DISTINCT è Hash Match. Questo operatore viene utilizzato per join e aggregazioni.
Quando si utilizza DISTINCT, Hash Match aggrega i risultati per produrre valori univoci. Ecco un esempio.
USE AdventureWorks
GO
-- Get unique first names
SELECT DISTINCT Firstname FROM Person.Person;
Ed ecco il piano di esecuzione:
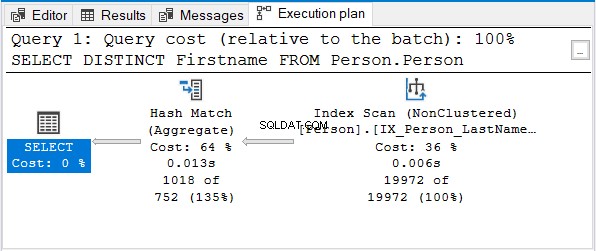
Ma perché non Stream Aggregate?
Si noti che viene utilizzato lo stesso indice del nome. Quell'indice si ordina con Cognome primo. Quindi, un Nome solo la query verrà annullata.
Hash Match (aggregato) è la prossima scelta logica per rimuovere i duplicati.
HASH MATCH (FLOW DISTINCT)
L'Hash Match (Aggregate) è un operatore di blocco. Pertanto, non produrrà l'output che ha elaborato l'intero flusso di input. Se limitiamo il numero di righe (come usando TOP con DISTINCT), produrrà un output univoco non appena quelle righe saranno disponibili. Ecco di cosa tratta Hash Match (Flow Distinct).
USE AdventureWorks
GO
SELECT DISTINCT TOP 100
sod.ProductID
,soh.OrderDate
,soh.ShipDate
FROM Sales.SalesOrderDetail sod
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID;
La query utilizza TOP 100 insieme a DISTINCT. Ecco il piano di esecuzione:
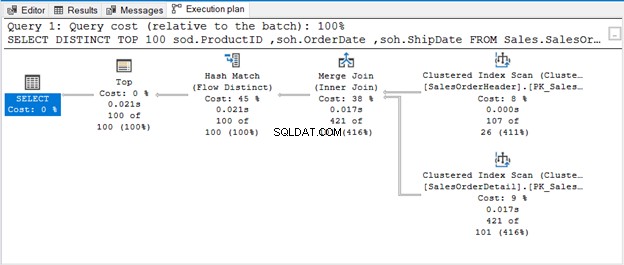
QUANDO NON C'È ALCUN OPERATORE PER RIMUOVERE I DUPLICATI
Sì. Questo può succedere. Considera l'esempio seguente.
USE AdventureWorks
GO
SELECT DISTINCT
BusinessEntityID
FROM Person.Person;
Quindi, controlla il piano di esecuzione:
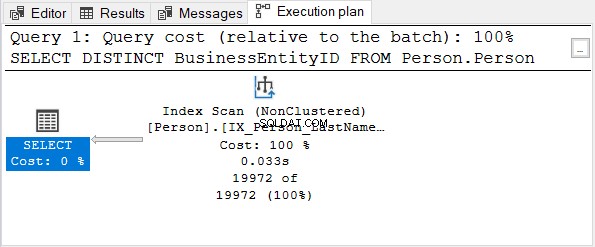
L'BusinessEntityID colonna è la chiave primaria. Poiché quella colonna è già univoca, non serve applicare DISTINCT. Prova a rimuovere DISTINCT dall'istruzione SELECT:il piano di esecuzione è lo stesso della Figura 4.
Lo stesso vale quando si utilizza DISTINCT su colonne con un indice univoco.
SQL DISTINCT funziona su TUTTE le colonne nell'elenco SELECT
Finora, abbiamo utilizzato solo 1 colonna nei nostri esempi. Tuttavia, DISTINCT funziona su TUTTE le colonne specificate nell'elenco SELECT.
Ecco un esempio. Questa query assicurerà che i valori di tutte e 3 le colonne siano univoci.
USE AdventureWorks
GO
SELECT DISTINCT
Lastname
,FirstName
,MiddleName
FROM Person.Person;
Notare le prime righe del set di risultati nella Figura 5.
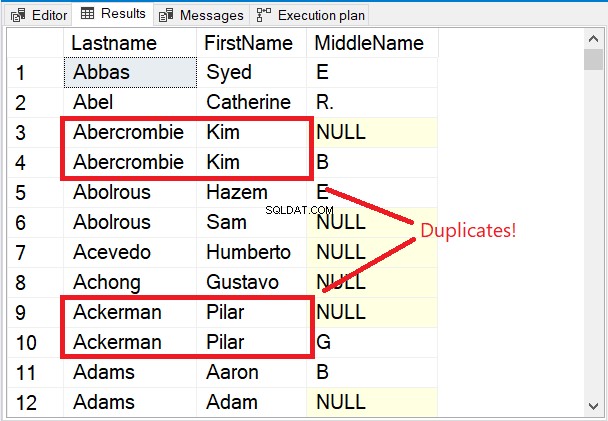
Le prime righe sono tutte uniche. La parola chiave DISTINCT ha assicurato che il secondo nome viene considerata anche la colonna. Notare i 2 nomi riquadrati in rosso. Considerando il Cognome e Nome solo li renderà duplicati. Ma aggiungendo secondo nome al mix ha cambiato tutto.
Cosa succede se desideri ottenere nomi e cognomi univoci ma includere il secondo nome nel risultato?
Hai 2 opzioni:
- Aggiungi una clausola WHERE per rimuovere i secondi nomi NULL. Questo rimuoverà tutti i nomi con un secondo nome NULL.
- Oppure, aggiungi una clausola GROUP BY su Cognome e Nome colonne. Quindi, usa la funzione di aggregazione MIN su Middlename colonna. Questo otterrà 1 secondo nome con lo stesso cognome e nome.
SQL DISTINCT vs. GROUP BY
Quando si utilizza GROUP BY senza una funzione di aggregazione, si comporta come DISTINCT. Come lo sappiamo? Un modo per scoprirlo è usare un esempio.
USE AdventureWorks
GO
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID;
-- using GROUP BY
SELECT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY
soh.TerritoryID
,st.Name;
Eseguili e controlla il piano di esecuzione. È come lo screenshot qui sotto?
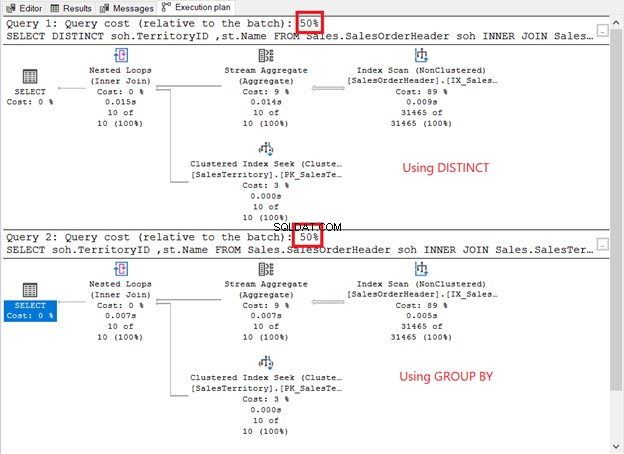
Come si confrontano?
- Hanno gli stessi operatori del piano e la stessa sequenza.
- Il costo dell'operatore di ciascuno e il costo della query sono gli stessi.
Se controlli QueryPlanHash proprietà dei 2 operatori SELECT, sono le stesse. Pertanto, Query Optimizer ha utilizzato lo stesso processo per restituire gli stessi risultati.
Alla fine, non possiamo dire che l'utilizzo di GROUP BY sia migliore di DISTINCT nella restituzione di valori univoci. Puoi dimostrarlo utilizzando gli esempi precedenti per sostituire DISTINCT con GROUP BY.
Ora è una questione di preferenza quale utilizzerai. Preferisco DISTINTO. Indica esplicitamente l'intento nella query:produrre risultati univoci. E per me, GROUP BY è per raggruppare i risultati utilizzando una funzione di aggregazione. Tale intento è anche chiaro e coerente con la parola chiave stessa. Non so se qualcun altro manterrà le mie domande un giorno. Quindi, il codice dovrebbe essere chiaro.
Ma questa non è la fine della storia.
Quando SQL DISTINCT non è uguale a GROUP BY
Ho appena espresso la mia opinione, e poi questa?
È vero. Non saranno sempre gli stessi. Considera questo esempio.
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh;
-- using GROUP BY
SELECT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh
GROUP BY
soh.TerritoryID;
Sebbene il set di risultati non sia ordinato, le righe sono le stesse dell'esempio precedente. L'unica differenza è l'uso di una sottoquery:
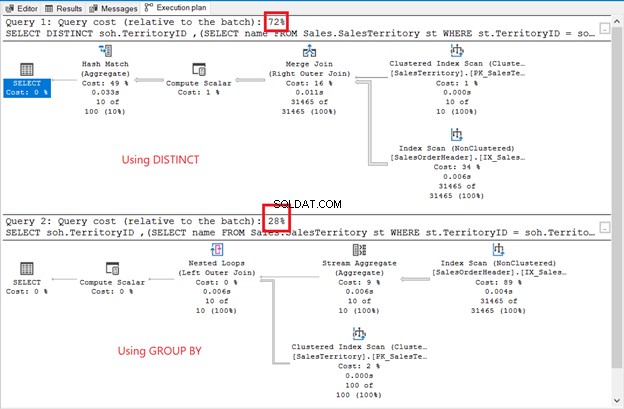
Le differenze sono evidenti:operatori, costo della query, piano generale. Questa volta, GROUP BY vince con solo il 28% del costo della query. Ma ecco il punto.
L'obiettivo è mostrarti che possono essere diversi. È tutto. Questa non è affatto una raccomandazione. L'uso di un join ha un piano di esecuzione migliore (vedi di nuovo la Figura 6).
Il risultato finale
Ecco cosa abbiamo imparato finora:
- DISTINCT aggiunge un operatore del piano per rimuovere i duplicati.
- DISTINCT e GROUP BY senza una funzione aggregata danno come risultato lo stesso piano. In breve, sono gli stessi per la maggior parte del tempo.
- A volte DISTINCT e GROUP BY possono avere piani diversi quando una sottoquery è coinvolta nell'elenco SELECT.
Quindi, SQL DISTINCT è buono o cattivo nel rimuovere i duplicati nei risultati?
I risultati dicono che è buono. Non è né meglio né peggio di GROUP BY perché i piani sono gli stessi. Ma è buona abitudine controllare il piano di esecuzione. Pensa all'ottimizzazione fin dall'inizio. In questo modo, se ti imbatti in differenze tra DISTINCT e GROUP BY, le individuerai.
Inoltre, gli strumenti moderni rendono questo compito molto più semplice. Ad esempio, un popolare prodotto dbForge SQL Complete di Devart ha una funzione specifica che calcola i valori nelle funzioni aggregate nel set di risultati pronti della griglia dei risultati SSMS. I valori DISTINCT sono presenti anche lì.
Ti piace il post? Quindi, per favore, spargi la voce condividendolo sulle tue piattaforme di social media preferite.
Articoli correlati per ulteriori informazioni
- SQL GROUP BY:3 semplici consigli per raggruppare i risultati come un professionista
- SQL INSERT INTO SELECT:5 semplici modi per gestire i duplicati
- Cosa sono le funzioni di aggregazione SQL? (Suggerimenti facili per i principianti)
- Ottimizzazione delle query SQL:5 fatti fondamentali per potenziare le query



