Galera Cluster viene fornito con molte caratteristiche degne di nota che non sono disponibili nella replica standard di MySQL (o nella replica di gruppo); provisioning automatico dei nodi, vero multi-master con risoluzione dei conflitti e failover automatico. Esistono anche una serie di limitazioni che potrebbero potenzialmente influire sulle prestazioni del cluster. Fortunatamente, se non ne sei a conoscenza, ci sono soluzioni alternative. E se lo fai bene, puoi ridurre al minimo l'impatto di queste limitazioni e migliorare le prestazioni complessive.
In precedenza abbiamo trattato molti suggerimenti e trucchi relativi a Galera Cluster, inclusa l'esecuzione di Galera su AWS Cloud. Questo post del blog si tuffa chiaramente negli aspetti delle prestazioni, con esempi su come ottenere il massimo da Galera.
Carico utile di replica
Un po' di introduzione - Galera replica i set di scritture durante la fase di commit, trasferendo i set di scritture dal nodo di origine ai nodi di ricezione in modo sincrono tramite il plug-in di replica wsrep. Questo plugin certificherà anche i set di scritture sui nodi riceventi. Se il processo di certificazione ha esito positivo, restituisce OK al client sul nodo di origine e verrà applicato sui nodi riceventi in un secondo momento in modo asincrono. In caso contrario, verrà eseguito il rollback della transazione sul nodo di origine (restituendo un errore al client) e i set di scritture che sono stati trasferiti ai nodi di ricezione verranno eliminati.
Un writeset consiste in operazioni di scrittura all'interno di una transazione che modifica lo stato del database. In Galera Cluster, autocommit il valore predefinito è 1 (abilitato). Letteralmente, qualsiasi istruzione SQL eseguita in Galera Cluster verrà racchiusa come transazione, a meno che non si inizi esplicitamente con BEGIN, START TRANSACTION o SET autocommit=0. Il diagramma seguente illustra l'incapsulamento di una singola istruzione DML in un writeset:
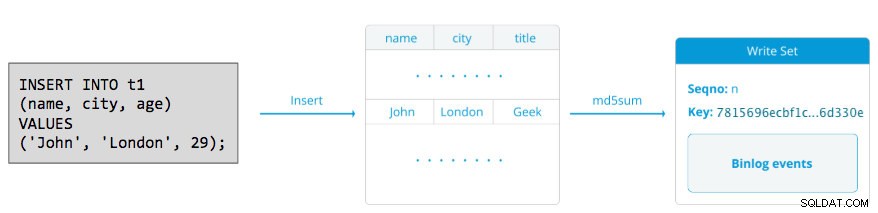
Per DML (INSERT, UPDATE, DELETE..), il payload del writeset è costituito dagli eventi di log binari per una particolare transazione mentre per i DDL (ALTER, GRANT, CREATE..), il payload del writeset è l'istruzione DDL stessa. Per i DML, il writeset dovrà essere certificato contro i conflitti sul nodo ricevente mentre per i DDL (a seconda di wsrep_osu_method , predefinito su TOI), il cluster del cluster esegue l'istruzione DDL su tutti i nodi nella stessa sequenza di ordini totali, impedendo ad altre transazioni di eseguire il commit mentre il DDL è in corso (vedere anche RSU). In parole semplici, Galera Cluster gestisce la replica DDL e DML in modo diverso.
Tempo di andata e ritorno
In generale, i seguenti fattori determinano la velocità con cui Galera può replicare un writeset da un nodo di origine a tutti i nodi di ricezione:
- Tempo di andata e ritorno (RTT) al nodo più lontano del cluster dal nodo di origine.
- La dimensione di un writeset da trasferire e da certificare per il conflitto sul nodo ricevente.
Ad esempio, se abbiamo un cluster Galera a tre nodi e uno dei nodi si trova a 10 millisecondi di distanza (0,01 secondi), è molto improbabile che tu possa scrivere più di 100 volte al secondo sulla stessa riga senza creare conflitti. C'è una citazione popolare di Mark Callaghan che descrive abbastanza bene questo comportamento:
"[In un cluster Galera] una determinata riga non può essere modificata più di una volta per RTT"
Per misurare il valore RTT, esegui semplicemente il ping sul nodo di origine fino al nodo più lontano nel cluster:
$ ping 192.168.55.173 # the farthest nodeAttendere un paio di secondi (o minuti) e terminare il comando. L'ultima riga della sezione statistica ping è ciò che stiamo cercando:
--- 192.168.55.172 ping statistics ---
65 packets transmitted, 65 received, 0% packet loss, time 64019ms
rtt min/avg/max/mdev = 0.111/0.431/1.340/0.240 msIl massimo il valore è 1,340 ms (0,00134s) e dovremmo prendere questo valore quando stimiamo il minimo transazioni al secondo (tps) per questo cluster. La media il valore è 0,431 ms (0,000431 s) e possiamo utilizzare per stimare la media tps mentre min il valore è 0,111 ms (0,000111 s) che possiamo utilizzare per stimare il massimo tps. Il mdev indica come sono stati distribuiti i campioni RTT dalla media. Un valore più basso significa RTT più stabile.
Pertanto, le transazioni al secondo possono essere stimate dividendo RTT (in secondi) in 1 secondo:

Risultato,
- Tps minimo:1 / 0,00134 (RTT massimo) =746,26 ~ 746 tps
- Tps medi:1 / 0,000431 (RTT medio) =2320,19 ~ 2320 tps
- Tps massimi:1 / 0,000111 (RTT min) =9009,01 ~ 9009 tps
Si noti che questa è solo una stima per anticipare le prestazioni di replica. Non c'è molto che possiamo fare per migliorare questo lato del database, una volta che tutto è distribuito e funzionante. Tranne se si spostano o migrano i server di database più vicini l'uno all'altro per migliorare l'RTT tra i nodi o se si aggiornano le periferiche di rete o l'infrastruttura. Ciò richiederebbe una finestra di manutenzione e una pianificazione adeguata.
Fai grandi transazioni
Un altro fattore è la dimensione della transazione. Dopo che il writeset è stato trasferito, ci sarà un processo di certificazione. La certificazione è un processo per determinare se il nodo può applicare o meno il writeset. Galera genera pseudo chiavi di checksum MD5 da ogni riga completa. Il costo della certificazione dipende dalla dimensione del writeset, che si traduce in una serie di ricerche di chiavi univoche nell'indice di certificazione (una tabella hash). Se aggiorni 500.000 righe in una singola transazione, ad esempio:
# a 500,000 rows table
mysql> UPDATE mydb.settings SET success = 1;Quanto sopra genererà un singolo writeset con 500.000 eventi di log binari al suo interno. Questo enorme set di scrittura non supera wsrep_max_ws_size (predefinito a 2 GB), quindi verrà trasferito dal plug-in di replica Galera a tutti i nodi del cluster, certificando queste 500.000 righe sui nodi riceventi per eventuali transazioni in conflitto che sono ancora nella coda slave. Infine, lo stato della certificazione viene restituito al plug-in di replica di gruppo. Maggiore è la dimensione della transazione, maggiore è il rischio che sia in conflitto con altre transazioni che provengono da un altro master. Transazioni in conflitto sprecano risorse del server, oltre a causare un enorme rollback al nodo di origine. Nota che un'operazione di rollback in MySQL è molto più lenta e meno ottimizzata dell'operazione di commit.
L'istruzione SQL di cui sopra può essere riscritta in un'istruzione più compatibile con Galera con l'aiuto di un semplice ciclo, come nell'esempio seguente:
(bash)$ for i in {1..500}; do \
mysql -uuser -ppassword -e "UPDATE mydb.settings SET success = 1 WHERE success != 1 LIMIT 1000"; \
sleep 2; \
doneIl comando della shell sopra aggiornerebbe 1000 righe per transazione per 500 volte e attenderà 2 secondi tra le esecuzioni. È inoltre possibile utilizzare una procedura memorizzata o altri mezzi per ottenere un risultato simile. Se non è possibile riscrivere la query SQL, è sufficiente indicare all'applicazione di eseguire la transazione di grandi dimensioni durante una finestra di manutenzione per ridurre il rischio di conflitti.
Per enormi eliminazioni, prendi in considerazione l'utilizzo di pt-archiver da Percona Toolkit, un lavoro a basso impatto e solo in avanti per sgranocchiare i vecchi dati dalla tabella senza influire molto sulle query OLTP.
Fili slave paralleli
In Galera, l'applicatore è un processo multithread. Applicatore è un thread in esecuzione all'interno di Galera per applicare i set di scrittura in arrivo da un altro nodo. Ciò significa che è possibile per tutti i ricevitori eseguire più operazioni DML che provengono direttamente dal nodo di origine (master) contemporaneamente. La replica parallela di Galera viene applicata alle transazioni solo quando è sicuro farlo. Migliora la probabilità che il nodo si sincronizzi con il nodo di origine. Tuttavia, la velocità di replica è ancora limitata a RTT e alle dimensioni del set di scrittura.
Per ottenere il meglio da questo, dobbiamo sapere due cose:
- Il numero di core del server.
- Il valore di wsrep_cert_deps_distance stato.
Lo stato wsrep_cert_deps_distance ci dice il potenziale grado di parallelizzazione. È il valore della distanza media tra i valori seqno più alti e quelli più bassi che possono essere eventualmente applicati in parallelo. Puoi usare wsrep_cert_deps_distance status variabile per determinare il numero massimo di thread slave possibili. Tieni presente che questo è un valore medio nel tempo. Quindi, per ottenere un buon valore, devi colpire il cluster con operazioni di scrittura tramite carico di lavoro di test o benchmark finché non vedi un valore stabile in uscita.
Per ottenere il numero di core, puoi semplicemente usare il seguente comando:
$ grep -c processor /proc/cpuinfo
4Idealmente, 2, 3 o 4 thread di applicatore slave per core della CPU sono un buon inizio. Pertanto, il valore minimo per i thread slave dovrebbe essere 4 volte il numero di core della CPU e non deve superare il wsrep_cert_deps_distance valore:
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cert_deps_distance';
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| wsrep_cert_deps_distance | 48.16667 |
+--------------------------+----------+Puoi controllare il numero di thread dell'applicatore slave utilizzando wsrep_slave_thread variabile. Anche se questa è una variabile dinamica, solo l'aumento del numero avrebbe un effetto immediato. Se riduci il valore in modo dinamico, ci vorrà del tempo prima che il thread dell'applicatore esca al termine dell'applicazione. Un valore consigliato è compreso tra 16 e 48:
mysql> SET GLOBAL wsrep_slave_threads = 48;Tieni presente che affinché i thread slave paralleli funzionino, è necessario impostare quanto segue (che di solito è preconfigurato per Galera Cluster):
innodb_autoinc_lock_mode=2Galera Cache (gcache)
Galera utilizza un file preallocato con una dimensione specifica chiamata gcache, in cui un nodo Galera conserva una copia dei set di scrittura in stile buffer circolare. Per impostazione predefinita, la sua dimensione è 128 MB, che è piuttosto piccola. Incremental State Transfer (IST) è un metodo per preparare un joiner inviando solo i writeset mancanti disponibili nella gcache del donatore. IST è più veloce del trasferimento di snapshot di stato (SST), non è bloccante e non ha un impatto significativo sulle prestazioni del donatore. Dovrebbe essere l'opzione preferita quando possibile.
L'IST può essere raggiunto solo se tutte le modifiche perse dal joiner sono ancora nel file gcache del donatore. L'impostazione consigliata per questo deve essere grande quanto l'intero set di dati MySQL. Se lo spazio su disco è limitato o costoso, determinare la giusta dimensione della dimensione di gcache è fondamentale, poiché può influenzare le prestazioni di sincronizzazione dei dati tra i nodi Galera.
La dichiarazione seguente ci darà un'idea della quantità di dati replicati da Galera. Eseguire la seguente istruzione su uno dei nodi Galera durante le ore di punta (testato su MariaDB>10.0 e PXC>5.6, galera>3.x):
mysql> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;
+--------+---------+-----------------+-----------------------+
| MB/min | MB/hour | gcache Size(MB) | Time to full(minutes) |
+--------+---------+-----------------+-----------------------+
| 7.95 | 477.00 | 128 | 16.10 |
+--------+---------+-----------------+-----------------------+
Possiamo stimare che il nodo Galera possa avere circa 16 minuti di inattività, senza richiedere l'adesione a SST (a meno che Galera non possa determinare lo stato del joiner). Se è troppo breve e hai spazio su disco sufficiente sui tuoi nodi, puoi modificare wsrep_provider_options="gcache.size=
Si consiglia inoltre di utilizzare gcache.recover=yes in wsrep_provider_options (Galera>3.19), dove Galera tenterà di ripristinare il file gcache in uno stato utilizzabile all'avvio anziché eliminarlo, preservando così la possibilità di avere IST ed evitando il più possibile SST. Codership e Percona ne hanno parlato in dettaglio nei loro blog. IST è sempre il metodo migliore per eseguire la sincronizzazione dopo che un nodo si è unito nuovamente al cluster. È il 50% più veloce di xtrabackup o mariabackup e 5 volte più veloce di mysqldump.
Slave asincrono
I nodi Galera sono strettamente accoppiati, in cui le prestazioni di replica sono veloci quanto il nodo più lento. Galera utilizza un meccanismo di controllo del flusso, per controllare il flusso di replica tra i membri ed eliminare qualsiasi ritardo dello slave. La replica può essere tutta veloce o tutta lenta su ogni nodo e viene regolata automaticamente da Galera. Se vuoi conoscere il controllo del flusso, leggi questo post sul blog di Jay Janssen di Percona.
Nella maggior parte dei casi, sono spesso inevitabili operazioni pesanti come analisi di lunga durata (ad alta intensità di lettura) e backup (ad alta intensità di lettura, blocco), che potrebbero potenzialmente degradare le prestazioni del cluster. Il modo migliore per eseguire questo tipo di query è inviarle a un server di replica ad accoppiamento libero, ad esempio uno slave asincrono.
Uno slave asincrono si replica da un nodo Galera utilizzando il protocollo di replica asincrono MySQL standard. Non c'è limite al numero di slave che possono essere collegati a un nodo Galera, ed è anche possibile concatenarlo con un master intermedio. Le operazioni MySQL eseguite su questo server non influiranno sulle prestazioni del cluster, a parte la fase di sincronizzazione iniziale in cui è necessario eseguire un backup completo sul nodo Galera per mettere in scena lo slave prima di stabilire il collegamento di replica (sebbene ClusterControl consenta di creare il slave da un backup esistente prima di connetterlo al cluster).
GTID (Global Transaction Identifier) fornisce una migliore mappatura delle transazioni tra i nodi ed è supportato in MySQL 5.6 e MariaDB 10.0. Con GTID, l'operazione di failover su uno slave su un altro master (un altro nodo Galera) è semplificata, senza la necessità di capire esattamente il file di registro e la posizione. Galera include anche la propria implementazione GTID, ma questi due sono indipendenti l'uno dall'altro.
Il ridimensionamento di uno slave asincrono è a portata di clic se si utilizza ClusterControl -> Aggiungi la funzione Slave di replica:
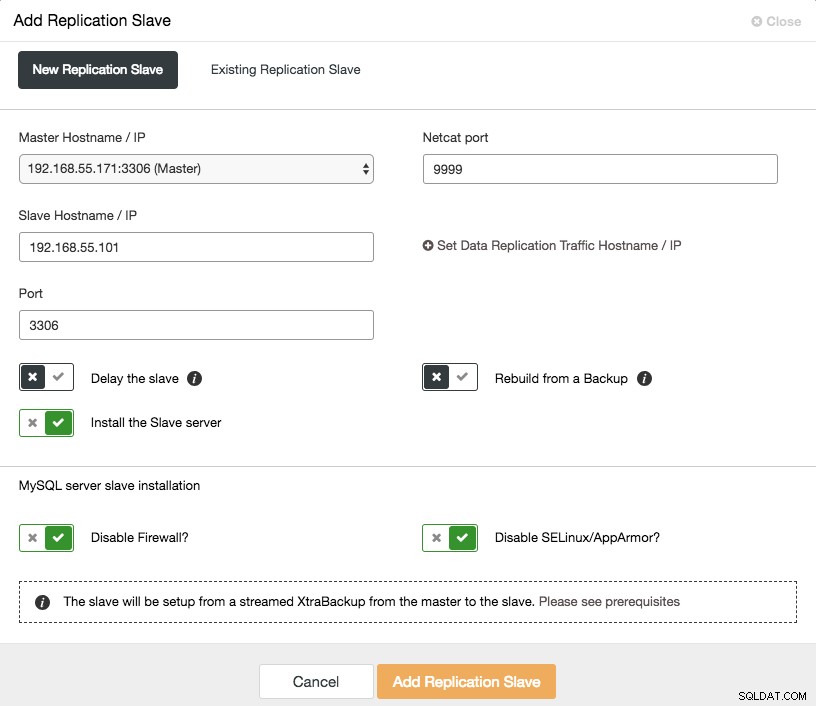
Tieni presente che i log binari devono essere abilitati sul master (il nodo Galera scelto) prima di poter procedere con questa configurazione. Abbiamo anche trattato il modo manuale in questo post precedente.
Lo screenshot seguente di ClusterControl mostra la topologia del cluster, illustra la nostra architettura Galera Cluster con uno slave asincrono:
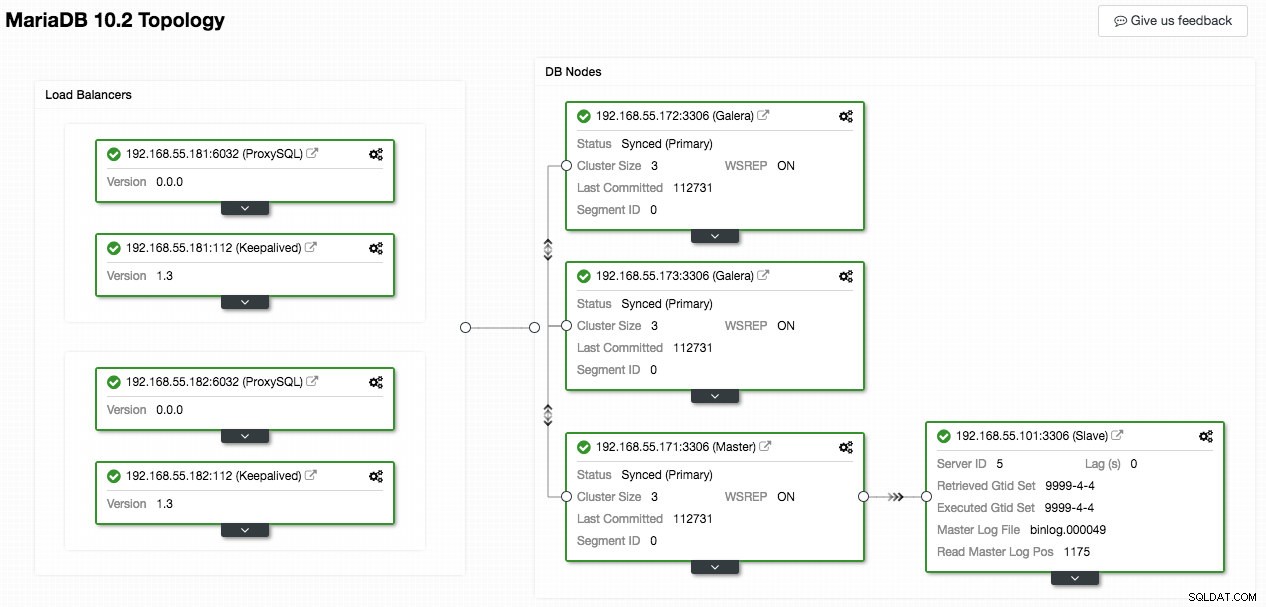
ClusterControl rileva automaticamente la topologia e genera il diagramma super cool come sopra. Puoi anche eseguire attività di amministrazione direttamente da questa pagina facendo clic sull'icona a forma di ingranaggio in alto a destra di ciascuna casella.
Proxy inverso compatibile con SQL
ProxySQL e MariaDB MaxScale sono proxy inversi intelligenti che comprendono il protocollo MySQL ed è in grado di agire come gateway, router, bilanciatore del carico e firewall davanti ai tuoi nodi Galera. Con l'aiuto del provider di indirizzi IP virtuali come LVS o Keepalived e combinandolo con la tecnologia di replica multi-master Galera, possiamo avere un servizio di database altamente disponibile, eliminando tutti i possibili single-point-of-failures (SPOF) dal punto di applicazione -di vista. Ciò migliorerà sicuramente la disponibilità e l'affidabilità dell'architettura nel suo insieme.
Un altro vantaggio di questo approccio è che avrai la possibilità di monitorare, riscrivere o reindirizzare le query SQL in entrata in base a una serie di regole prima che raggiungano il server del database effettivo, riducendo al minimo le modifiche sull'applicazione o sul lato client e instradando le query a un nodo più adatto per prestazioni ottimali. Le query rischiose per Galera come LOCK TABLES e FLUSH TABLES WITH READ LOCK possono essere prevenute molto prima che causino il caos nel sistema, mentre query con impatto come le query "hotspot" (una riga a cui diverse query desiderano accedere contemporaneamente) possono essere riscritto o reindirizzato a un singolo nodo Galera per ridurre il rischio di conflitti di transazione. Per query di sola lettura pesanti come OLAP o backup, puoi indirizzarle a uno slave asincrono, se disponibile.
Il proxy inverso monitora anche lo stato del database, le query e le variabili per comprendere le modifiche alla topologia e produrre una decisione di instradamento accurata verso i server back-end. Indirettamente, centralizza il monitoraggio dei nodi e la panoramica del cluster senza la necessità di controllare regolarmente ogni singolo nodo Galera. La schermata seguente mostra il dashboard di monitoraggio ProxySQL in ClusterControl:
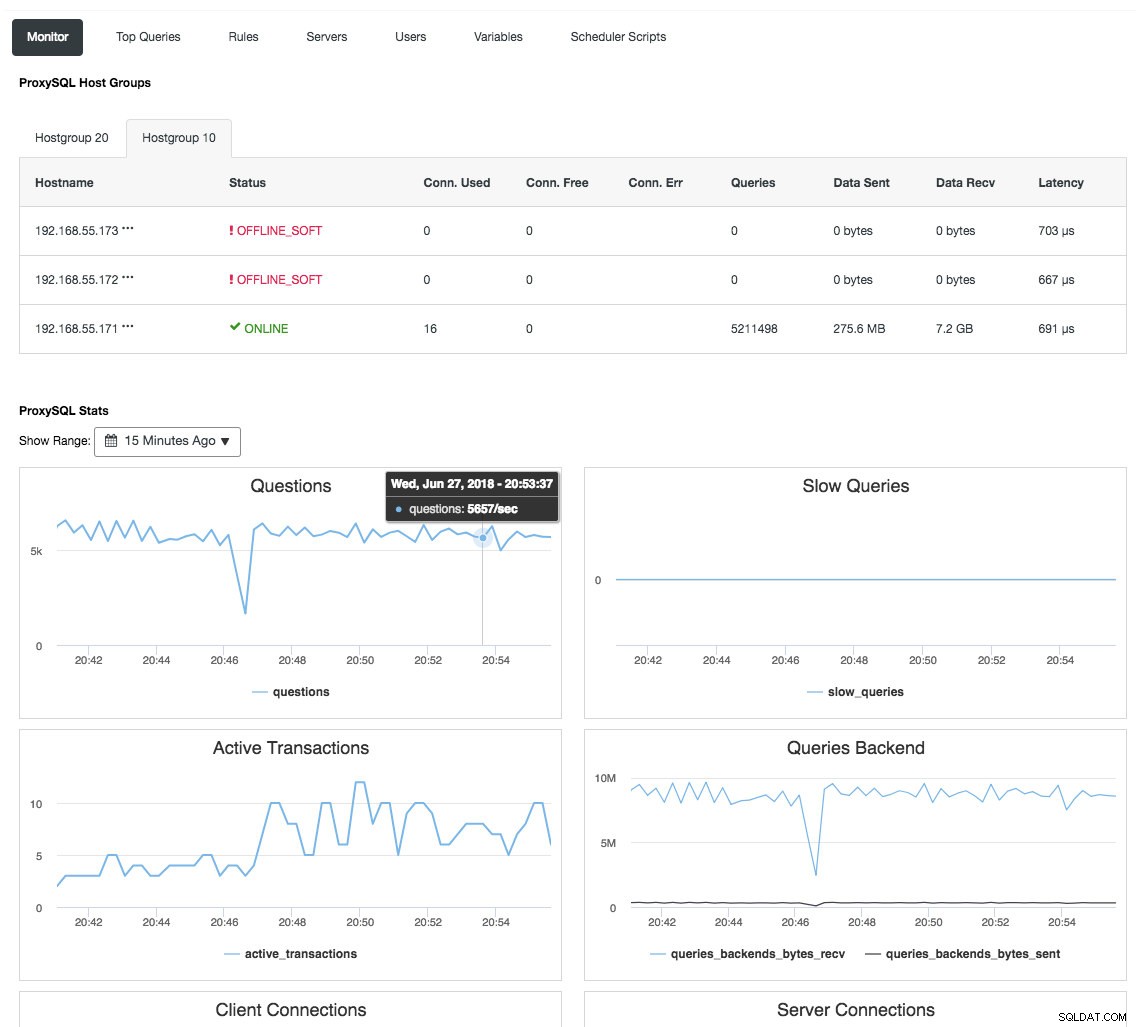
Ci sono anche molti altri vantaggi che un sistema di bilanciamento del carico può apportare per migliorare significativamente il cluster Galera, come spiegato in dettaglio in questo post del blog, Diventa un DBA ClusterControl:rendere i tuoi componenti DB HA tramite Load Balancer.
Pensieri finali
Con una buona comprensione del funzionamento interno di Galera Cluster, possiamo aggirare alcune delle limitazioni e migliorare il servizio di database. Buon raggruppamento!