All'inizio di questa settimana, ho pubblicato un seguito al mio recente post su STRING_SPLIT() in SQL Server 2016, indirizzando diversi commenti lasciati sul post e/o inviatimi direttamente:
STRING_SPLIT()in SQL Server 2016:follow-up n. 1
Dopo che quel post è stato per lo più scritto, c'è stata una domanda in ritardo da Doug Ellner:
Come si confrontano queste funzioni con i parametri con valori di tabella?
Ora, testare i TVP era già nella mia lista di progetti futuri, dopo un recente scambio su Twitter con @Nick_Craver su Stack Overflow. Ha detto che erano entusiasti di STRING_SPLIT() si sono comportati bene, perché non erano soddisfatti delle prestazioni dell'invio di circa 7.000 valori tramite un parametro con valori di tabella.
I miei test
Per questi test ho utilizzato SQL Server 2016 RC3 (13.0.1400.361) su una VM Windows 10 a 8 core, con storage PCIe e 32 GB di RAM.
Ho creato una semplice tabella che imitava ciò che stavano facendo (selezionando circa 10.000 valori da una tabella di oltre 3 milioni di post di righe), ma per i miei test ha molte meno colonne e meno indici:
CREATE TABLE dbo.Posts_Regular ( PostID int PRIMARY KEY, HitCount int NOT NULL DEFAULT 0 ); INSERT dbo.Posts_Regular(PostID) SELECT TOP (3000000) ROW_NUMBER() OVER (ORDER BY s1.[object_id]) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2;
Ho anche creato una versione In-Memory, perché ero curioso di sapere se un approccio avrebbe funzionato diversamente:
CREATE TABLE dbo.Posts_InMemory ( PostID int PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 4000000), HitCount int NOT NULL DEFAULT 0 ) WITH (MEMORY_OPTIMIZED = ON);
Ora, volevo creare un'app C# che passasse 10.000 valori univoci, sia come stringa separata da virgole (creata utilizzando un StringBuilder) o come TVP (passata da un DataTable). Il punto sarebbe recuperare o aggiornare una selezione di righe in base a una corrispondenza, a un elemento prodotto dalla divisione dell'elenco o a un valore esplicito in un TVP. Quindi il codice è stato scritto per aggiungere ogni 300° valore alla stringa o DataTable (il codice C# è in un'appendice di seguito). Ho preso le funzioni che ho creato nel post originale, le ho modificate per gestire varchar(max) , e quindi ha aggiunto due funzioni che accettavano un TVP, una delle quali ottimizzata per la memoria. Ecco i tipi di tabella (le funzioni sono nell'appendice sotto):
CREATE TYPE dbo.PostIDs_Regular AS TABLE(PostID int PRIMARY KEY); GO CREATE TYPE dbo.PostIDs_InMemory AS TABLE ( PostID int NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1000000) ) WITH (MEMORY_OPTIMIZED = ON); GO
Ho anche dovuto ingrandire la tabella di Numbers per gestire stringhe> 8K e con elementi> 8K (l'ho creato righe di 1MM). Quindi ho creato sette stored procedure:cinque di loro hanno un varchar(max) e unendosi con l'output della funzione per aggiornare la tabella di base, e poi due per accettare il TVP e unirsi direttamente a quello. Il codice C# chiama ciascuna di queste sette procedure, con l'elenco di 10.000 post da selezionare o aggiornare, 1.000 volte. Queste procedure sono anche nell'appendice sottostante. Quindi, solo per riassumere, i metodi testati sono:
- Nativo (
STRING_SPLIT()) - XML
- CLR
- Tabella dei numeri
- JSON (con
intesplicito uscita) - Parametro con valori di tabella
- Parametro con valori di tabella ottimizzato per la memoria
Verificheremo il recupero dei 10.000 valori, 1.000 volte, utilizzando un DataReader, ma non l'iterazione sul DataReader, poiché ciò renderebbe il test più lungo e richiederebbe la stessa quantità di lavoro per l'applicazione C# indipendentemente da come il database prodotto il set. Verificheremo anche l'aggiornamento delle 10.000 righe, 1.000 volte ciascuna, utilizzando ExecuteNonQuery() . E testeremo sia la versione normale che quella ottimizzata per la memoria della tabella Posts, che possiamo cambiare molto facilmente senza dover modificare nessuna delle funzioni o procedure, usando un sinonimo:
CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular; -- to test memory-optimized version: DROP SYNONYM dbo.Posts; CREATE SYNONYM dbo.Posts FOR dbo.Posts_InMemory; -- to test the disk-based version again: DROP SYNONYM dbo.Posts; CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular;
Ho avviato l'applicazione, l'ho eseguita più volte per ogni combinazione per garantire che la compilazione, la memorizzazione nella cache e altri fattori non fossero ingiusti nei confronti del batch eseguito prima, quindi ho analizzato i risultati dalla tabella di registrazione (ho anche controllato a campione sys. dm_exec_procedure_stats per assicurarsi che nessuno degli approcci avesse un sovraccarico significativo basato sull'applicazione, e invece no).
Risultati:tabelle basate su disco
A volte faccio fatica con la visualizzazione dei dati:ho davvero cercato di trovare un modo per rappresentare queste metriche su un unico grafico, ma penso che ci fossero troppi punti dati per far risaltare quelli salienti.
Puoi fare clic per ingrandire uno qualsiasi di questi in una nuova scheda/finestra, ma anche se hai una piccola finestra ho cercato di chiarire il vincitore attraverso l'uso del colore (e il vincitore era lo stesso in ogni caso). E per essere chiari, per "Durata media" intendo il tempo medio impiegato dall'applicazione per completare un ciclo di 1.000 operazioni.
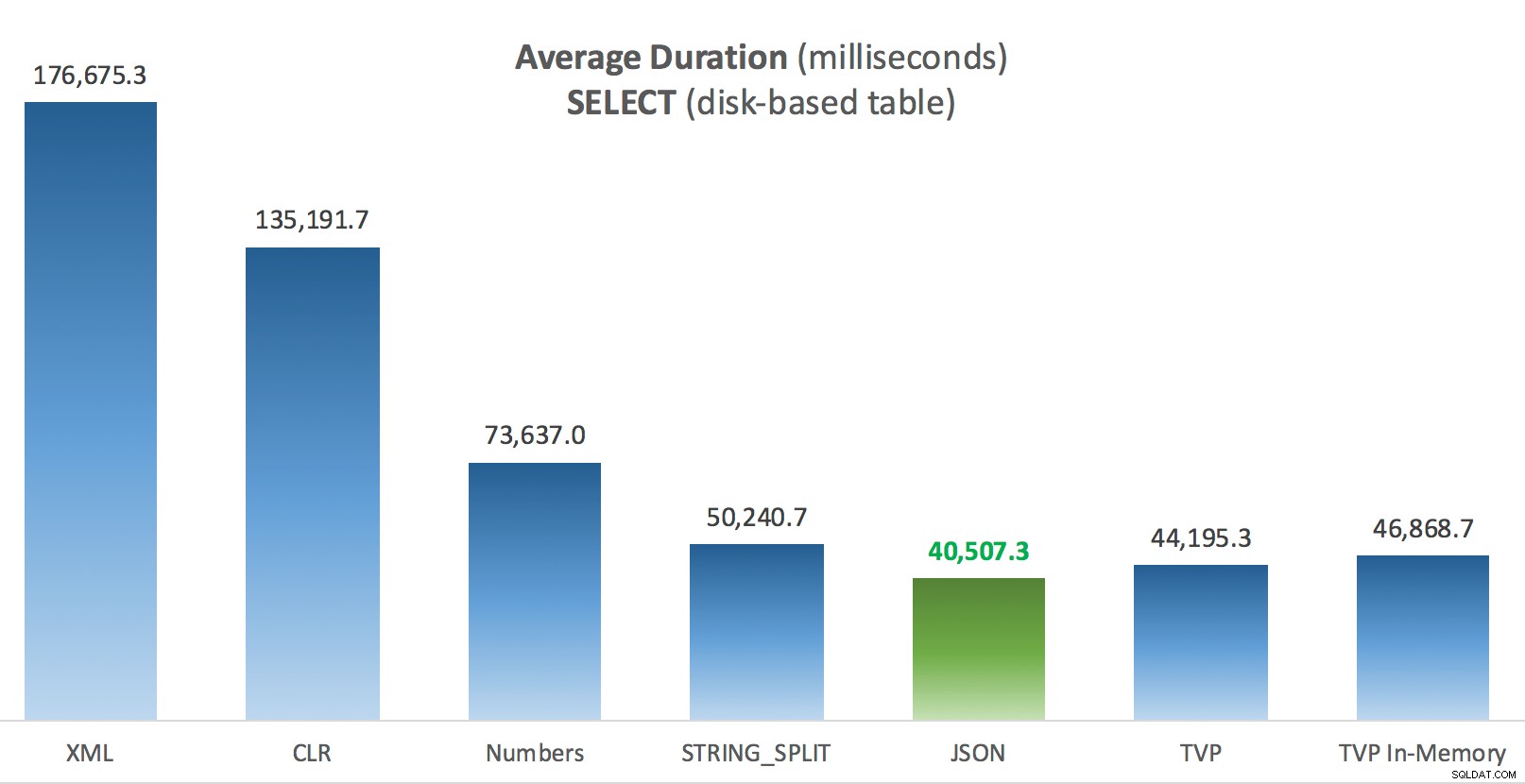 Durata media (millisecondi) per SELECT rispetto alla tabella Post basata su disco
Durata media (millisecondi) per SELECT rispetto alla tabella Post basata su disco
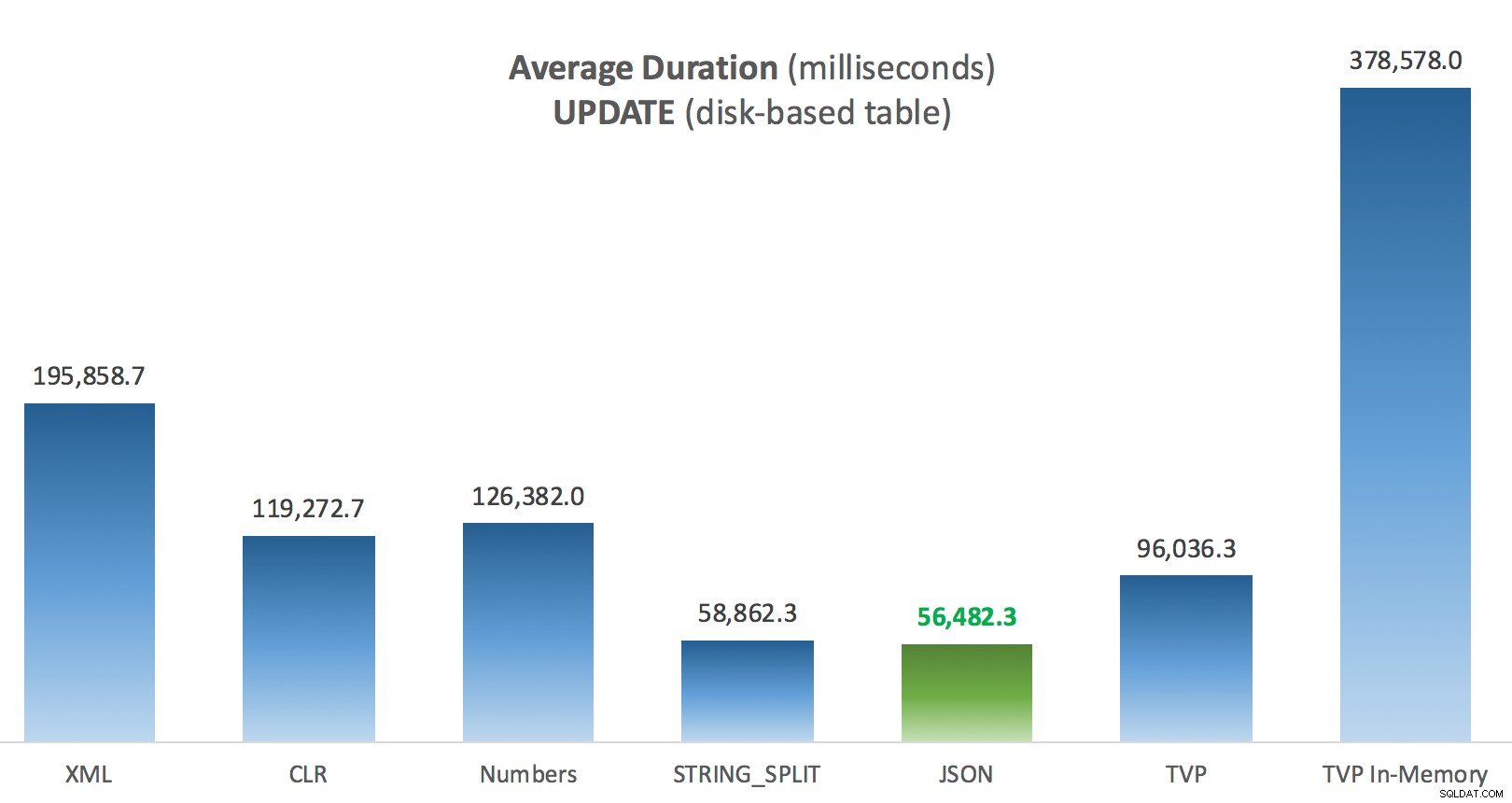 Durata media (millisecondi) per AGGIORNAMENTI rispetto alla tabella Post basata su disco
Durata media (millisecondi) per AGGIORNAMENTI rispetto alla tabella Post basata su disco
La cosa più interessante qui, per me, è quanto male ha fatto il TVP con ottimizzazione della memoria durante l'assistenza con un UPDATE . Si scopre che le scansioni parallele sono attualmente bloccate in modo troppo aggressivo quando è coinvolto DML; Microsoft ha riconosciuto questo come un divario di funzionalità e sperano di affrontarlo presto. Nota che la scansione parallela è attualmente possibile con SELECT ma è bloccato per DML in questo momento. (Non verrà risolto in SQL Server 2014, poiché queste specifiche operazioni di scansione parallela non sono disponibili per nessuna operazione.) Quando è stato risolto o quando i TVP sono più piccoli e/o il parallelismo non è comunque vantaggioso, dovresti vedere che i TVP ottimizzati per la memoria funzioneranno meglio (il modello semplicemente non funziona bene per questo particolare caso d'uso di TVP relativamente grandi).
Per questo caso specifico, ecco i piani per il SELECT (che potrei costringere ad andare in parallelo) e UPDATE (cosa che non ho potuto):
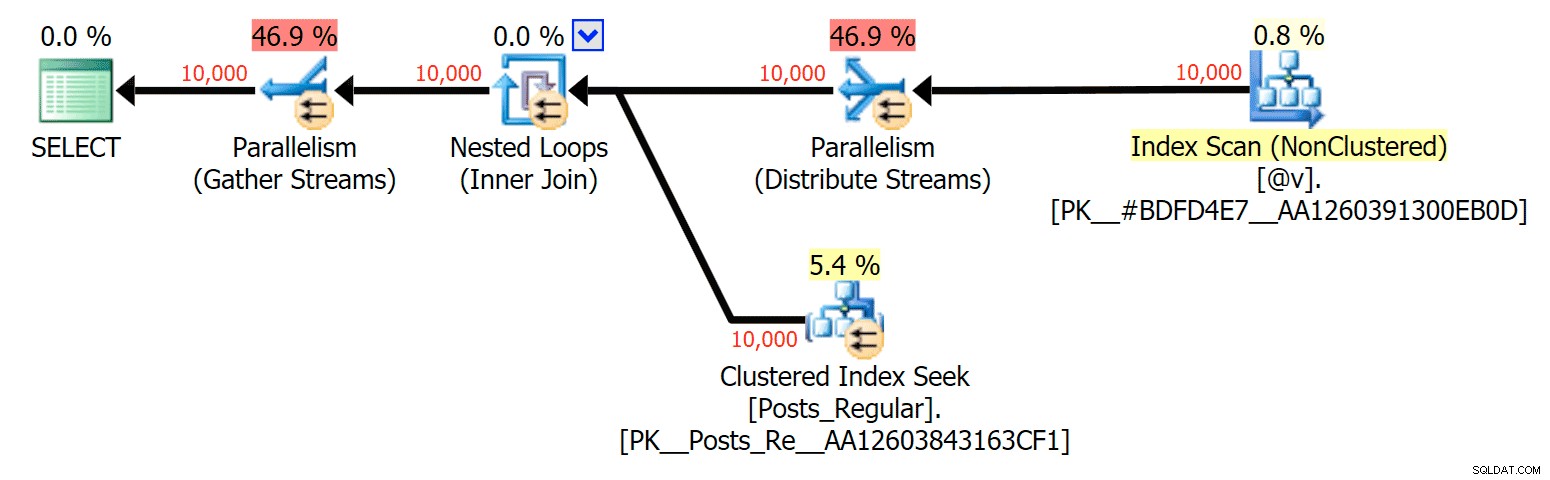 Parallelismo in un piano SELECT che unisce una tabella basata su disco a un TVP in memoria
Parallelismo in un piano SELECT che unisce una tabella basata su disco a un TVP in memoria
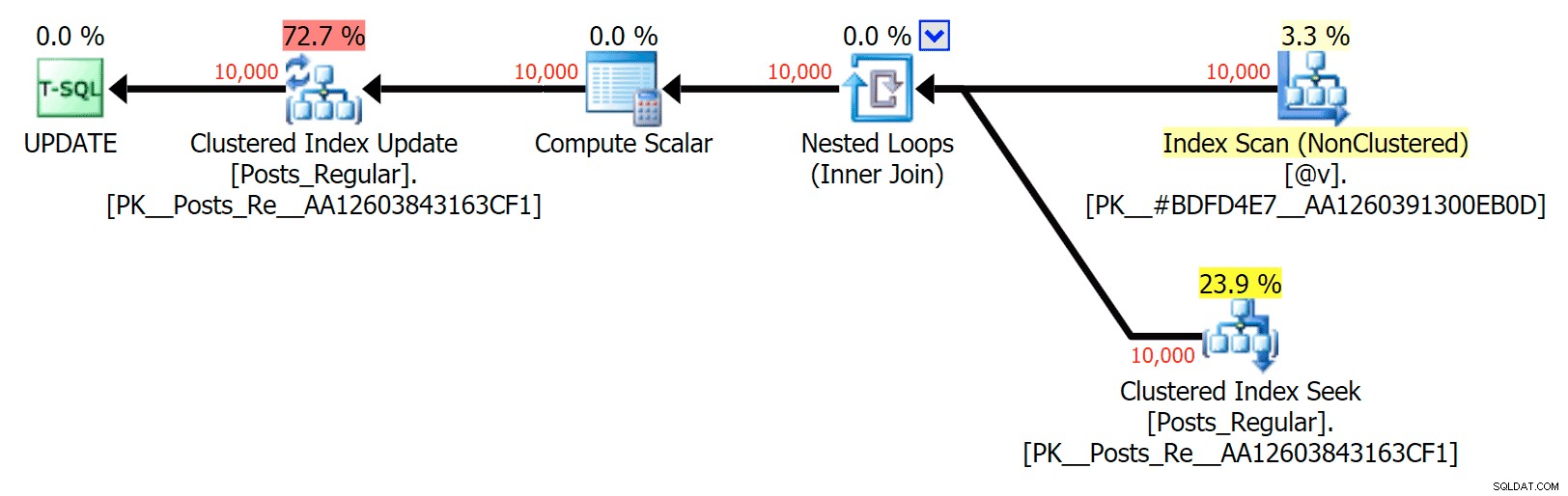 Nessun parallelismo in un piano UPDATE che unisce una tabella basata su disco a una in memoria TVP
Nessun parallelismo in un piano UPDATE che unisce una tabella basata su disco a una in memoria TVP
Risultati – Tabelle con ottimizzazione per la memoria
Un po' più di coerenza qui:i quattro metodi a destra sono relativamente uniformi, mentre i tre a sinistra sembrano molto indesiderabili per contrasto. Prestare inoltre particolare attenzione alla scalabilità assoluta rispetto alle tabelle basate su disco:per la maggior parte, utilizzando gli stessi metodi e anche senza parallelismo, si ottengono operazioni molto più rapide rispetto alle tabelle ottimizzate per la memoria, con conseguente riduzione dell'utilizzo complessivo della CPU.
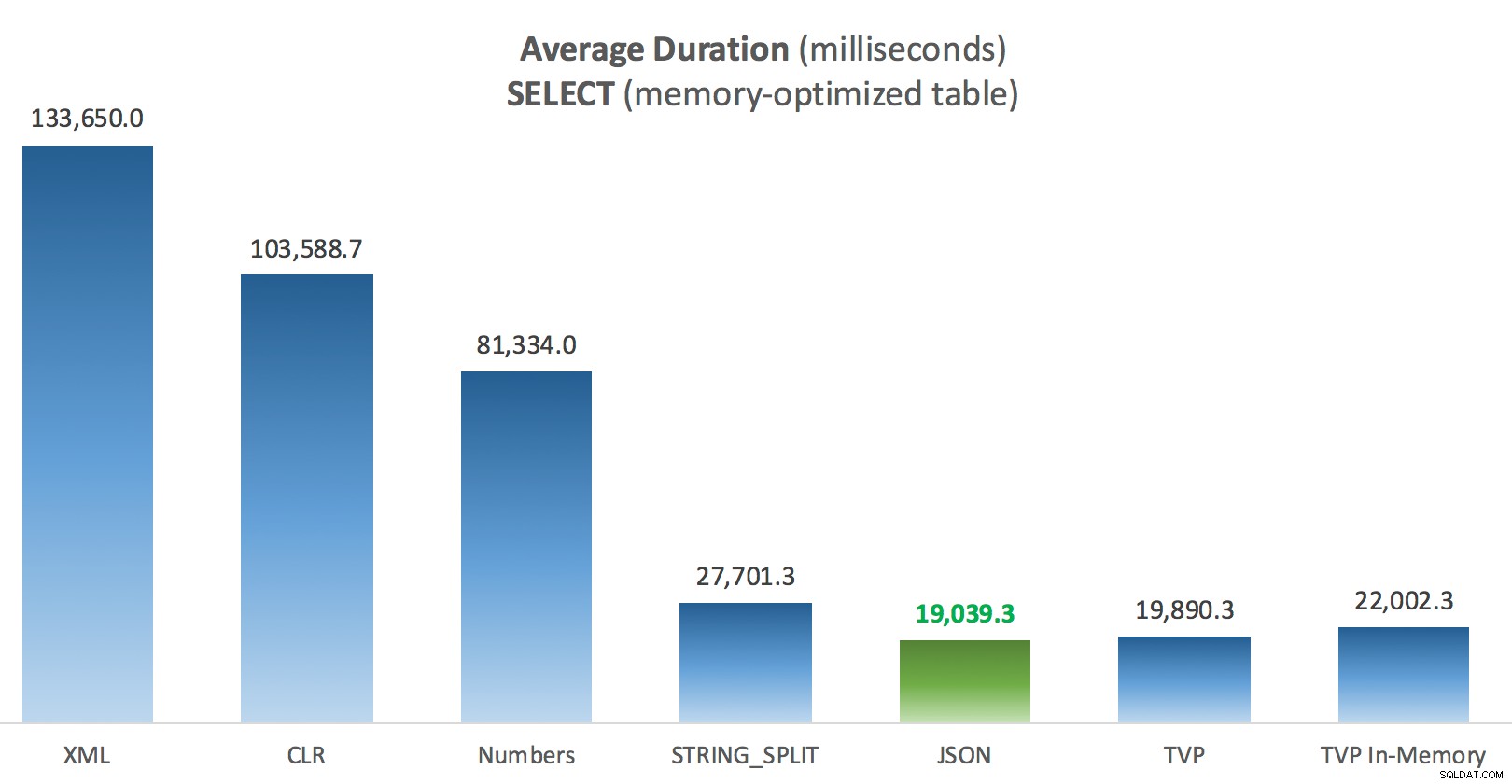 Durata media (millisecondi) per SELECT rispetto alla tabella Post ottimizzata per la memoria
Durata media (millisecondi) per SELECT rispetto alla tabella Post ottimizzata per la memoria
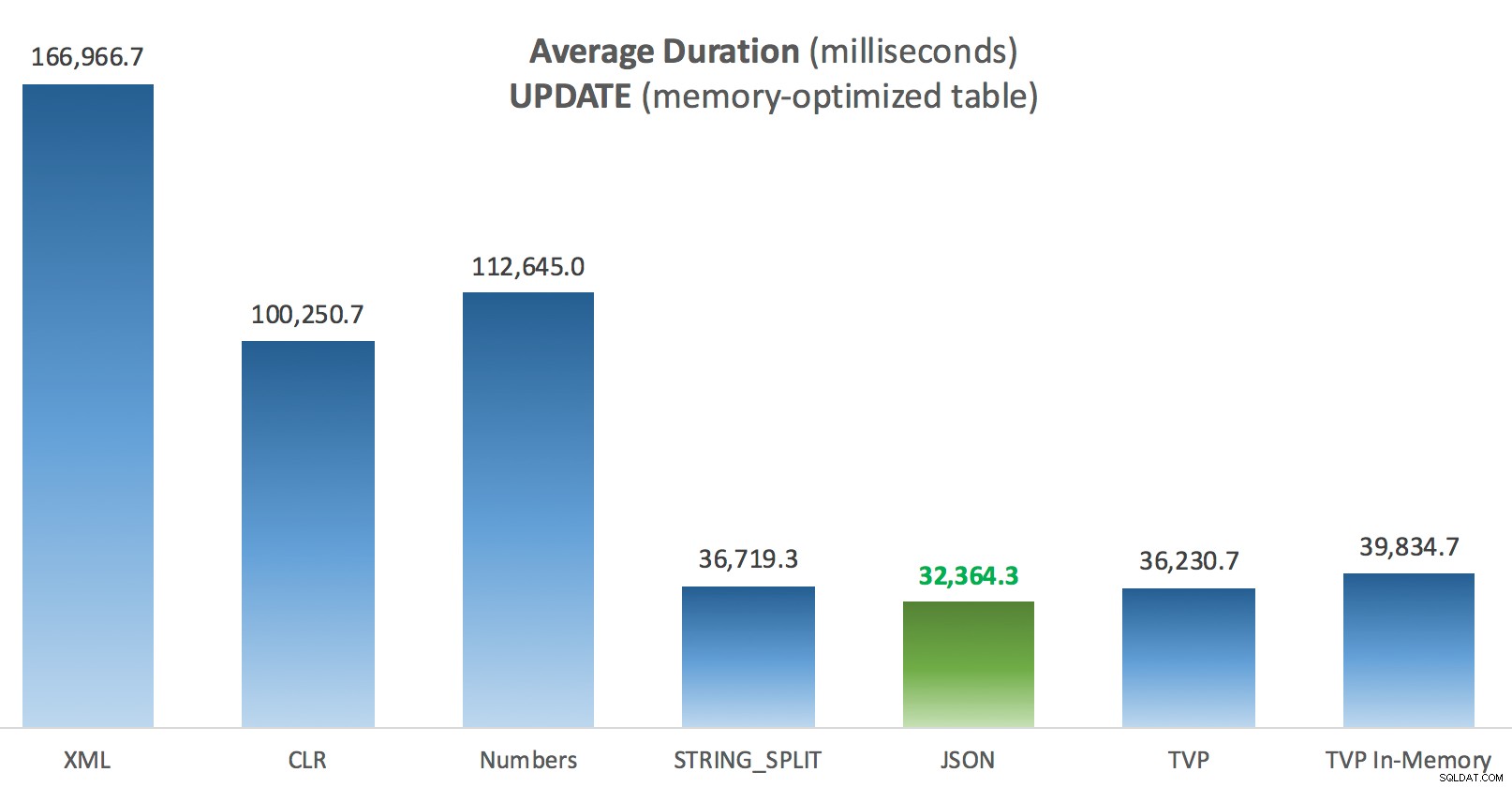 Durata media (millisecondi) per gli AGGIORNAMENTI rispetto alla tabella dei messaggi ottimizzata per la memoria
Durata media (millisecondi) per gli AGGIORNAMENTI rispetto alla tabella dei messaggi ottimizzata per la memoria
Conclusione
Per questo test specifico, con una dimensione dei dati, una distribuzione e un numero di parametri specifici e sul mio hardware particolare, JSON è stato un vincitore coerente (anche se marginalmente). Per alcuni degli altri test nei post precedenti, tuttavia, altri approcci sono andati meglio. Solo un esempio di come ciò che stai facendo e dove lo stai facendo può avere un impatto drammatico sull'efficienza relativa di varie tecniche, ecco le cose che ho testato in questa breve serie, con il mio riassunto di quale tecnica utilizzare in tal caso e quale utilizzare come seconda o terza scelta (ad esempio, se non è possibile implementare CLR a causa di criteri aziendali o perché si utilizza il database SQL di Azure oppure non è possibile usare JSON o STRING_SPLIT() perché non sei ancora su SQL Server 2016). Nota che non sono tornato indietro e non ho testato nuovamente l'assegnazione della variabile e SELECT INTO script che utilizzano TVP:questi test sono stati impostati presupponendo che si disponesse già di dati esistenti in formato CSV che avrebbero comunque dovuto essere prima suddivisi. In genere, se puoi evitarlo, non smoosh i tuoi set in stringhe separate da virgole in primo luogo, IMHO.
| Obiettivo | 1a scelta | 2a scelta (e 3a, se del caso) |
|---|---|---|
| Semplice assegnazione di variabili | STRING_SPLIT() | CLR se <2016 XML se nessun CLR e <2016 |
| SELEZIONA IN | CLR | XML se non CLR |
| SELEZIONA IN (senza spool) | CLR | Tabella dei numeri se nessun CLR |
| SELEZIONA IN (senza spool + MAXDOP 1) | STRING_SPLIT() | CLR se <2016 Tabella dei numeri se nessun CLR e <2016 |
| SELEZIONARE unendo un elenco grande (basato su disco) | JSON (int) | TVP se <2016 |
| SELEZIONARE unendo un elenco grande (ottimizzato per la memoria) | JSON (int) | TVP se <2016 |
| UPDATE unendo un elenco grande (basato su disco) | JSON (int) | TVP se <2016 |
| UPDATE unendo un elenco grande (ottimizzato per la memoria) | JSON (int) | TVP se <2016 |
Per la domanda specifica di Doug:JSON, STRING_SPLIT() e i TVP si sono comportati in modo piuttosto simile in questi test in media, abbastanza vicini che i TVP sono la scelta più ovvia se non si utilizza SQL Server 2016. Se si hanno casi d'uso diversi, questi risultati potrebbero differire. Molto bene .
Il che ci porta alla morale di questo storia:io e altri possiamo eseguire test di prestazione molto specifici, che ruotano attorno a qualsiasi caratteristica o approccio, e giungere a una conclusione su quale approccio sia più veloce. Ma ci sono così tante variabili che non avrò mai la sicurezza di dire "questo approccio è sempre il più veloce." In questo scenario, mi sono sforzato di controllare la maggior parte dei fattori che contribuiscono e, sebbene JSON abbia vinto in tutti e quattro i casi, puoi vedere come quei diversi fattori hanno influenzato i tempi di esecuzione (e in modo drastico per alcuni approcci). vale sempre la pena costruire i propri test e spero di aver contribuito a illustrare come procedo con questo genere di cose.
Appendice A:Codice dell'applicazione della console
Per favore, niente pignoli su questo codice; è stato letteralmente messo insieme come un modo molto semplice per eseguire queste stored procedure 1.000 volte con elenchi veri e DataTable assemblati in C# e per registrare il tempo impiegato da ciascun ciclo in una tabella (per essere sicuri di includere qualsiasi sovraccarico relativo all'applicazione con la gestione una stringa grande o una raccolta). Potrei aggiungere la gestione degli errori, eseguire il ciclo in modo diverso (ad es. costruire gli elenchi all'interno del ciclo invece di riutilizzare una singola unità di lavoro) e così via.
using System;
using System.Text;
using System.Configuration;
using System.Data;
using System.Data.SqlClient;
namespace SplitTesting
{
class Program
{
static void Main(string[] args)
{
string operation = "Update";
if (args[0].ToString() == "-Select") { operation = "Select"; }
var csv = new StringBuilder();
DataTable elements = new DataTable();
elements.Columns.Add("value", typeof(int));
for (int i = 1; i <= 10000; i++)
{
csv.Append((i*300).ToString());
if (i < 10000) { csv.Append(","); }
elements.Rows.Add(i*300);
}
string[] methods = { "Native", "CLR", "XML", "Numbers", "JSON", "TVP", "TVP_InMemory" };
using (SqlConnection con = new SqlConnection())
{
con.ConnectionString = ConfigurationManager.ConnectionStrings["primary"].ToString();
con.Open();
SqlParameter p;
foreach (string method in methods)
{
SqlCommand cmd = new SqlCommand("dbo." + operation + "Posts_" + method, con);
cmd.CommandType = CommandType.StoredProcedure;
if (method == "TVP" || method == "TVP_InMemory")
{
cmd.Parameters.Add("@PostList", SqlDbType.Structured).Value = elements;
}
else
{
cmd.Parameters.Add("@PostList", SqlDbType.VarChar, -1).Value = csv.ToString();
}
var timer = System.Diagnostics.Stopwatch.StartNew();
for (int x = 1; x <= 1000; x++)
{
if (operation == "Update") { cmd.ExecuteNonQuery(); }
else { SqlDataReader rdr = cmd.ExecuteReader(); rdr.Close(); }
}
timer.Stop();
long this_time = timer.ElapsedMilliseconds;
// log time - the logging procedure adds clock time and
// records memory/disk-based (determined via synonym)
SqlCommand log = new SqlCommand("dbo.LogBatchTime", con);
log.CommandType = CommandType.StoredProcedure;
log.Parameters.Add("@Operation", SqlDbType.VarChar, 32).Value = operation;
log.Parameters.Add("@Method", SqlDbType.VarChar, 32).Value = method;
log.Parameters.Add("@Timing", SqlDbType.Int).Value = this_time;
log.ExecuteNonQuery();
Console.WriteLine(method + " : " + this_time.ToString());
}
}
}
}
} Esempio di utilizzo:
SplitTesting.exe -SelezionaSplitTesting.exe -Aggiorna
Appendice B:Funzioni, procedure e tabella di registrazione
Ecco le funzioni modificate per supportare varchar(max) (la funzione CLR ha già accettato nvarchar(max) ed ero ancora riluttante a provare a cambiarlo):
CREATE FUNCTION dbo.SplitStrings_Native( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] FROM STRING_SPLIT(@List, @Delimiter));
GO
CREATE FUNCTION dbo.SplitStrings_XML( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] = y.i.value('(./text())[1]', 'varchar(max)')
FROM (SELECT x = CONVERT(XML, '<i>' + REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')) AS a CROSS APPLY x.nodes('i') AS y(i));
GO
CREATE FUNCTION dbo.SplitStrings_Numbers( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO
CREATE FUNCTION dbo.SplitStrings_JSON( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] FROM OPENJSON(CHAR(91) + @List + CHAR(93)) WITH (value int '$'));
GO E le procedure memorizzate sembravano così:
CREATE PROCEDURE dbo.UpdatePosts_Native @PostList varchar(max) AS BEGIN UPDATE p SET HitCount += 1 FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID = s.[value]; END GO CREATE PROCEDURE dbo.SelectPosts_Native @PostList varchar(max) AS BEGIN SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID = s.[value]; END GO -- repeat for the 4 other varchar(max)-based methods CREATE PROCEDURE dbo.UpdatePosts_TVP @PostList dbo.PostIDs_Regular READONLY -- switch _Regular to _InMemory AS BEGIN SET NOCOUNT ON; UPDATE p SET HitCount += 1 FROM dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID = s.PostID; END GO CREATE PROCEDURE dbo.SelectPosts_TVP @PostList dbo.PostIDs_Regular READONLY -- switch _Regular to _InMemory AS BEGIN SET NOCOUNT ON; SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID = s.PostID; END GO -- repeat for in-memory
E infine, la tabella di registrazione e la procedura:
CREATE TABLE dbo.SplitLog
(
LogID int IDENTITY(1,1) PRIMARY KEY,
ClockTime datetime NOT NULL DEFAULT GETDATE(),
OperatingTable nvarchar(513) NOT NULL, -- Posts_InMemory or Posts_Regular
Operation varchar(32) NOT NULL DEFAULT 'Update', -- or select
Method varchar(32) NOT NULL DEFAULT 'Native', -- or TVP, JSON, etc.
Timing int NOT NULL DEFAULT 0
);
GO
CREATE PROCEDURE dbo.LogBatchTime
@Operation varchar(32),
@Method varchar(32),
@Timing int
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.SplitLog(OperatingTable, Operation, Method, Timing)
SELECT base_object_name, @Operation, @Method, @Timing
FROM sys.synonyms WHERE name = N'Posts';
END
GO
-- and the query to generate the graphs:
;WITH x AS
(
SELECT OperatingTable,Operation,Method,Timing,
Recency = ROW_NUMBER() OVER
(PARTITION BY OperatingTable,Operation,Method
ORDER BY ClockTime DESC)
FROM dbo.SplitLog
)
SELECT OperatingTable,Operation,Method,AverageDuration = AVG(1.0*Timing)
FROM x WHERE Recency <= 3
GROUP BY OperatingTable,Operation,Method;