Uno dei metodi più diffusi per ottenere un'elevata disponibilità per MySQL è la replica. La replica esiste da molti anni ed è diventata molto più stabile con l'introduzione dei GTID. Ma anche con questi miglioramenti, il processo di replica può interrompersi per vari motivi, ad esempio quando master e slave non sono sincronizzati perché le scritture sono state inviate direttamente allo slave. Come risolvete i problemi di replica e come li risolvete?
In questo post del blog, discuteremo alcuni dei problemi comuni con la replica e come risolverli con ClusterControl. Cominciamo con il primo.
Replica interrotta con qualche errore
La maggior parte dei DBA MySQL in genere vede questo tipo di problema almeno una volta nella propria carriera. Per vari motivi, uno slave può essere danneggiato o addirittura interrompere la sincronizzazione con il master. Quando ciò accade, la prima cosa da fare per avviare la risoluzione dei problemi è controllare la presenza di messaggi nel registro degli errori. Nella maggior parte dei casi, il messaggio di errore è facilmente rintracciabile nel registro degli errori o eseguendo la query SHOW SLAVE STATUS.
Diamo un'occhiata al seguente esempio tratto da SHOW STATUS SLAVE:
********** 0. row **********
Slave_IO_State:
Master_Host: 10.2.9.71
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000111
Read_Master_Log_Pos: 255477362
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: binlog.000111
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 255477362
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-2268440
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: optimistic
SQL_Delay: 0
SQL_Remaining_Delay:
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0Possiamo vedere chiaramente che l'errore è correlato all'errore fatale 1236 ricevuto dal master durante la lettura dei dati dal registro binario:'Impossibile trovare lo stato GTID richiesto dallo slave in nessun file binlog. Probabilmente lo stato slave è troppo vecchio e i file binlog richiesti sono stati eliminati.'. In poche parole, ciò che l'errore ci dice essenzialmente è che c'è incoerenza nei dati e i file di registro binari richiesti sono già stati eliminati.
Questo è un buon esempio in cui il processo di replica smette di funzionare. Oltre a SHOW SLAVE STATUS, puoi anche tenere traccia dello stato nella scheda "Panoramica" del cluster in ClusterControl. Quindi, come risolvere questo problema con ClusterControl? Hai due opzioni da provare:
-
Puoi provare a riavviare lo slave da "Node Action"
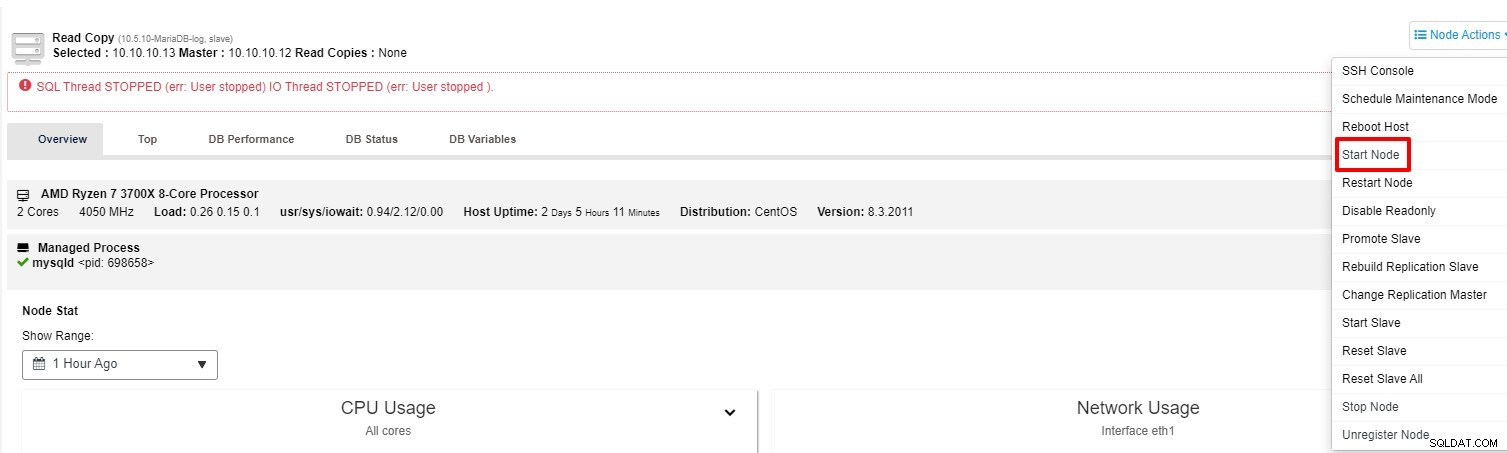
-
Se lo slave continua a non funzionare, puoi eseguire il lavoro "Rebuild Replication Slave" da "Azione nodo"
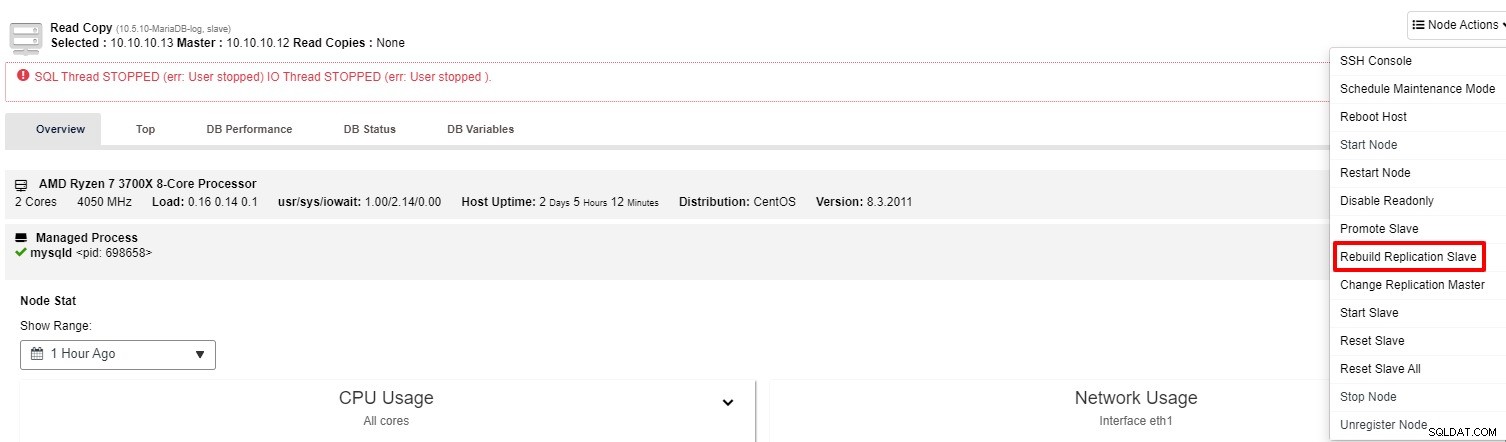
Il più delle volte, la seconda opzione risolverà il problema. ClusterControl eseguirà un backup del master e ricostruirà lo slave danneggiato ripristinando i dati. Una volta ripristinati i dati, lo slave viene collegato al master in modo che possa recuperare il ritardo.
Ci sono anche diversi modi manuali per ricostruire lo slave come elencato di seguito, puoi anche fare riferimento a questo link per maggiori dettagli:
-
Utilizzo di Mysqldump per ricostruire uno slave MySQL incoerente
-
Utilizzo di Mydumper per ricostruire uno slave MySQL incoerente
-
Utilizzo di uno snapshot per ricostruire uno slave MySQL incoerente
-
Utilizzo di Xtrabackup o Mariabackup per ricostruire uno slave MySQL incoerente
Promuove uno schiavo a diventare un maestro
Nel tempo, il sistema operativo o il database devono essere patchati o aggiornati per mantenere stabilità e sicurezza. Una delle migliori pratiche per ridurre al minimo i tempi di inattività, soprattutto per un aggiornamento importante, è promuovere uno degli slave come master dopo che l'aggiornamento è stato eseguito con successo su quel particolare nodo.
Eseguendo questa operazione, potresti indirizzare la tua applicazione al nuovo master e la replica master-slave continuerà a funzionare. Nel frattempo, potresti anche procedere con l'upgrade sul vecchio master in tutta tranquillità. Con ClusterControl questo può essere eseguito con pochi clic solo supponendo che la replica sia configurata come basata su Global Transaction ID o in breve GTID. Per evitare qualsiasi perdita di dati, vale la pena interrompere qualsiasi query dell'applicazione nel caso in cui il vecchio master funzioni correttamente. Questa non è l'unica situazione in cui potresti promuovere lo schiavo. Nel caso in cui il nodo master sia inattivo, puoi anche eseguire questa azione.
Senza ClusterControl, ci sono alcuni passaggi per promuovere lo slave. Ciascuno dei passaggi richiede anche l'esecuzione di alcune query:
-
Elimina manualmente il master
-
Seleziona lo slave più avanzato per diventare un master e preparalo
-
Riconnetti altri slave al nuovo master
-
Cambiare il vecchio padrone in schiavo
Tuttavia, i passaggi per promuovere Slave con ClusterControl sono solo pochi clic:Cluster> Nodi> scegli nodo slave> Promuovi Slave come da screenshot qui sotto:
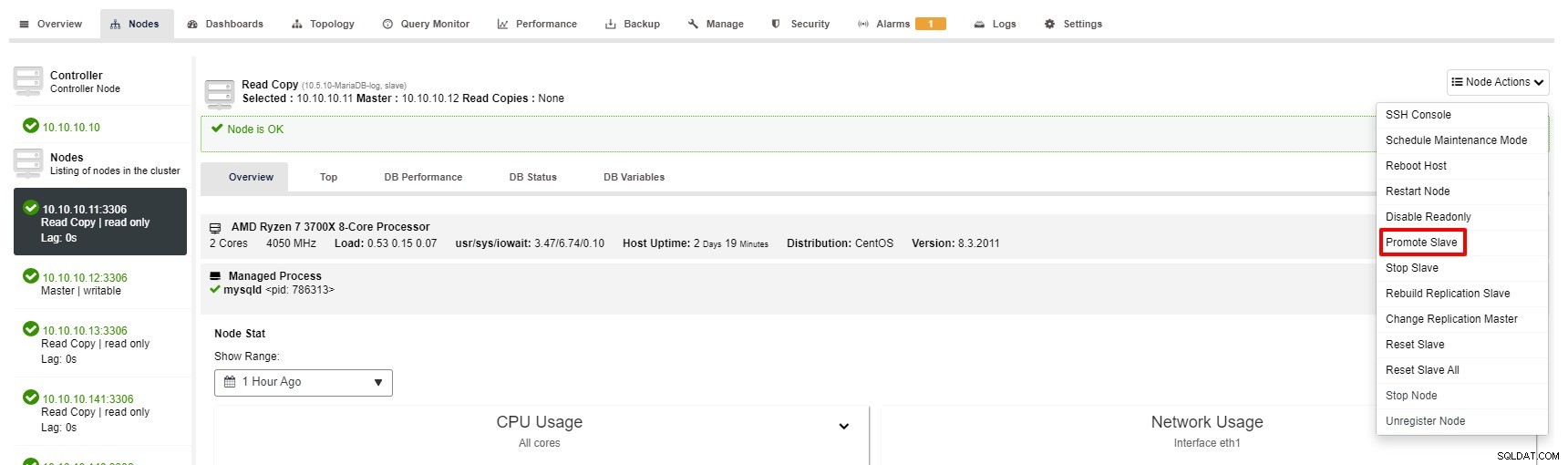
Il master diventa non disponibile
Immagina di avere grandi transazioni da eseguire ma il database è inattivo. Non importa quanto stai attento, questa è probabilmente la situazione più seria o critica per una configurazione di replica. Quando ciò accade, il tuo database non è in grado di accettare una singola scrittura, il che è negativo. Inoltre, le tue applicazioni, ovviamente, non funzioneranno correttamente.
Ci sono alcuni motivi o cause che portano a questo problema. Alcuni degli esempi sono guasti hardware, danneggiamento del sistema operativo, danneggiamento del database e così via. In qualità di DBA, devi agire rapidamente per ripristinare il database principale.
Grazie alla funzione cluster “Auto Recovery” disponibile in ClusterControl, il processo di failover può essere automatizzato. Può essere abilitato o disabilitato con un solo clic. Come dice il nome, ciò che farà è visualizzare l'intera topologia del cluster quando necessario. Ad esempio, una replica master-slave deve avere almeno un master attivo in un dato momento, indipendentemente dal numero di slave disponibili. Quando il master non è disponibile, promuoverà automaticamente uno degli slave.
Diamo un'occhiata allo screenshot qui sotto:
Nello screenshot sopra, possiamo vedere che "Ripristino automatico" è abilitato sia per il cluster che per il nodo. Nella topologia, notare che l'indirizzo IP principale corrente è 10.10.10.11. Cosa accadrà se interrompiamo il nodo master a scopo di test?
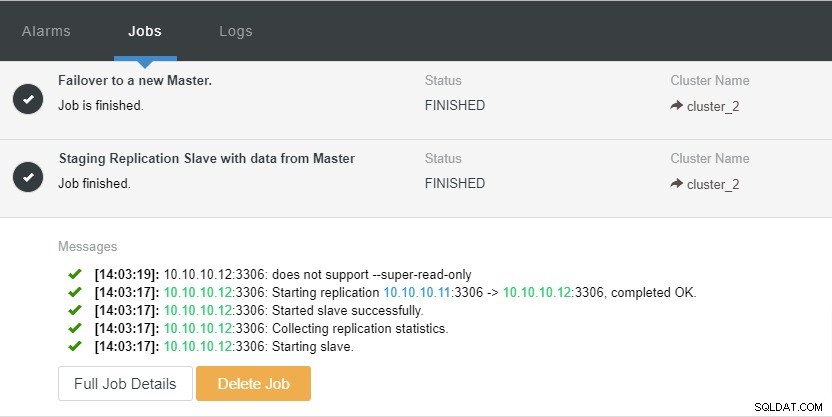
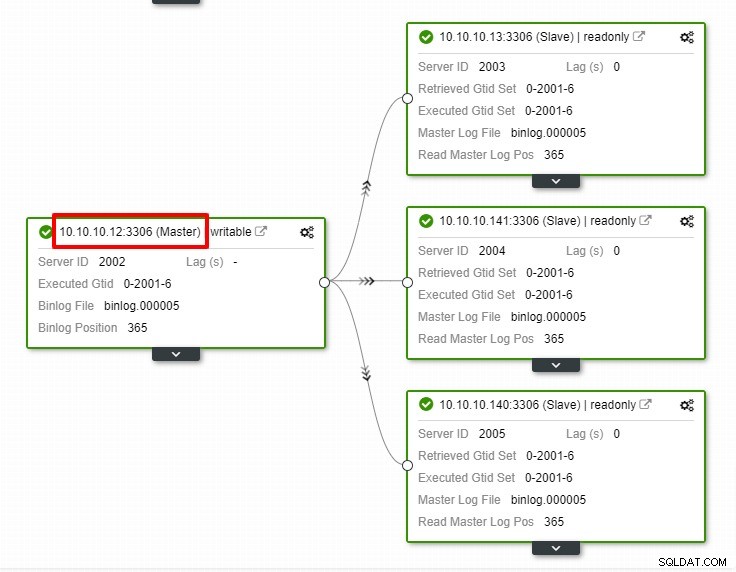
Come puoi vedere, il nodo slave con IP 10.10.10.12 è automaticamente promosso a master, in modo che la topologia di replica venga riconfigurata. Invece di farlo manualmente che, ovviamente, comporterà molti passaggi, ClusterControl ti aiuta a mantenere la tua configurazione di replica senza problemi.
Conclusione
In ogni sfortunato caso con la tua replica, la correzione è molto semplice e meno fastidiosa con ClusterControl. ClusterControl ti aiuta a recuperare rapidamente i tuoi problemi di replica, il che aumenta il tempo di attività dei tuoi database.



