L'importanza del failover
Il failover è una delle pratiche di database più importanti per la governance del database. È utile non solo quando si gestiscono database di grandi dimensioni in produzione, ma anche se si desidera essere sicuri che il proprio sistema sia sempre disponibile ogni volta che si accede, soprattutto a livello di applicazione.
Prima che possa aver luogo un failover, le istanze del database devono soddisfare determinati requisiti. Questi requisiti sono, infatti, molto importanti per un'elevata disponibilità. Uno dei requisiti che le istanze del database devono soddisfare è la ridondanza. La ridondanza consente il proseguimento del failover, in cui la ridondanza è configurata per avere un candidato al failover che può essere un nodo di replica (secondario) o da un pool di repliche che agiscono come nodi di standby o hot-standby. Il candidato viene selezionato manualmente o automaticamente in base al nodo più avanzato o aggiornato. Di solito, si desidera una replica hot-standby in quanto può salvare il database dall'estrazione di indici dal disco poiché un hot-standby popola spesso gli indici nel pool di buffer del database.
Failover è il termine usato per descrivere che si è verificato un processo di ripristino. Prima del processo di ripristino, ciò si verifica quando un nodo del database primario (o master) si guasta dopo un arresto anomalo, dopo disastri naturali, dopo un guasto hardware o potrebbe aver subito un partizionamento di rete; questi sono i casi più comuni in cui potrebbe verificarsi un failover. Il processo di recupero di solito procede automaticamente e quindi cerca il secondario (replica) più desiderato e aggiornato come indicato in precedenza.
Failover avanzato
Sebbene il processo di ripristino durante un failover sia automatico, in alcune occasioni non è necessario automatizzare il processo e deve subentrare un processo manuale. La complessità è spesso la considerazione principale associata alle tecnologie che compongono l'intero stack del database:il failover automatico può essere combinato anche con il failover manuale.
Nella maggior parte delle considerazioni quotidiane sulla gestione dei database, la maggior parte delle preoccupazioni relative al failover automatico non sono davvero banali. Spesso risulta utile implementare e configurare un failover automatico in caso di problemi. Anche se sembra promettente in quanto copre le complessità, arrivano i meccanismi di failover avanzati e ciò coinvolge gli eventi "pre" e gli eventi "post" che sono legati come hook in un software o una tecnologia di failover.
Questi eventi pre e post presentano controlli o determinate azioni da eseguire prima che possa finalmente procedere con il failover e, dopo che un failover è stato eseguito, alcune pulizie per assicurarsi che il failover sia finalmente un successo uno. Fortunatamente, sono disponibili strumenti che consentono non solo il failover automatico, ma anche la capacità di applicare hook pre e post script.
In questo blog, utilizzeremo il failover automatico ClusterControl (CC) e spiegheremo come utilizzare gli hook pre e post script e a quale cluster si applicano.
Failover replica ClusterControl
Il meccanismo di failover ClusterControl è applicabile in modo efficiente sulla replica asincrona applicabile alle varianti MySQL (MySQL/Percona Server/MariaDB). È applicabile anche ai cluster PostgreSQL/TimescaleDB:ClusterControl supporta la replica in streaming. I cluster MongoDB e Galera hanno il proprio meccanismo per il failover automatico integrato nella propria tecnologia di database. Ulteriori informazioni su come ClusterControl esegue il ripristino automatico del database e il failover.
Il failover di ClusterControl non funziona a meno che il ripristino del nodo e del cluster (ripristino automatico siano abilitati). Ciò significa che questi pulsanti dovrebbero essere verdi.

La documentazione afferma che queste opzioni di configurazione possono essere utilizzate anche per abilitare / disabilitare quanto segue:
| enable_cluster_autorecovery= |
|
| enable_node_autorecovery= |
|
$ systemctl restart cmon
Per questo blog, ci stiamo concentrando principalmente su come utilizzare gli hook pre/post script, che è essenzialmente un grande vantaggio per il failover avanzato della replica.
Supporto per la replica di failover del cluster pre/post script
Come accennato in precedenza, le varianti di MySQL che utilizzano la replica asincrona (inclusa semi-sincrona) e la replica in streaming per PostgreSQL/TimescaleDB supportano questo meccanismo. ClusterControl ha le seguenti opzioni di configurazione che possono essere utilizzate per hook pre e post script. Fondamentalmente, queste opzioni di configurazione possono essere impostate tramite i loro file di configurazione o possono essere impostate tramite l'interfaccia utente web (ne parleremo più avanti).
La nostra documentazione afferma che queste sono le seguenti opzioni di configurazione che possono alterare il meccanismo di failover utilizzando gli hook pre/post script:
| replication_pre_failover_script= |
|
| replication_post_failover_script= |
|
| replication_post_unsuccessful_failover_script= |
|
Tecnicamente, una volta impostate le seguenti opzioni di configurazione nel file di configurazione /etc/cmon.d/cmon_
$ systemctl restart cmonIn alternativa, puoi anche impostare le opzioni di configurazione andando su
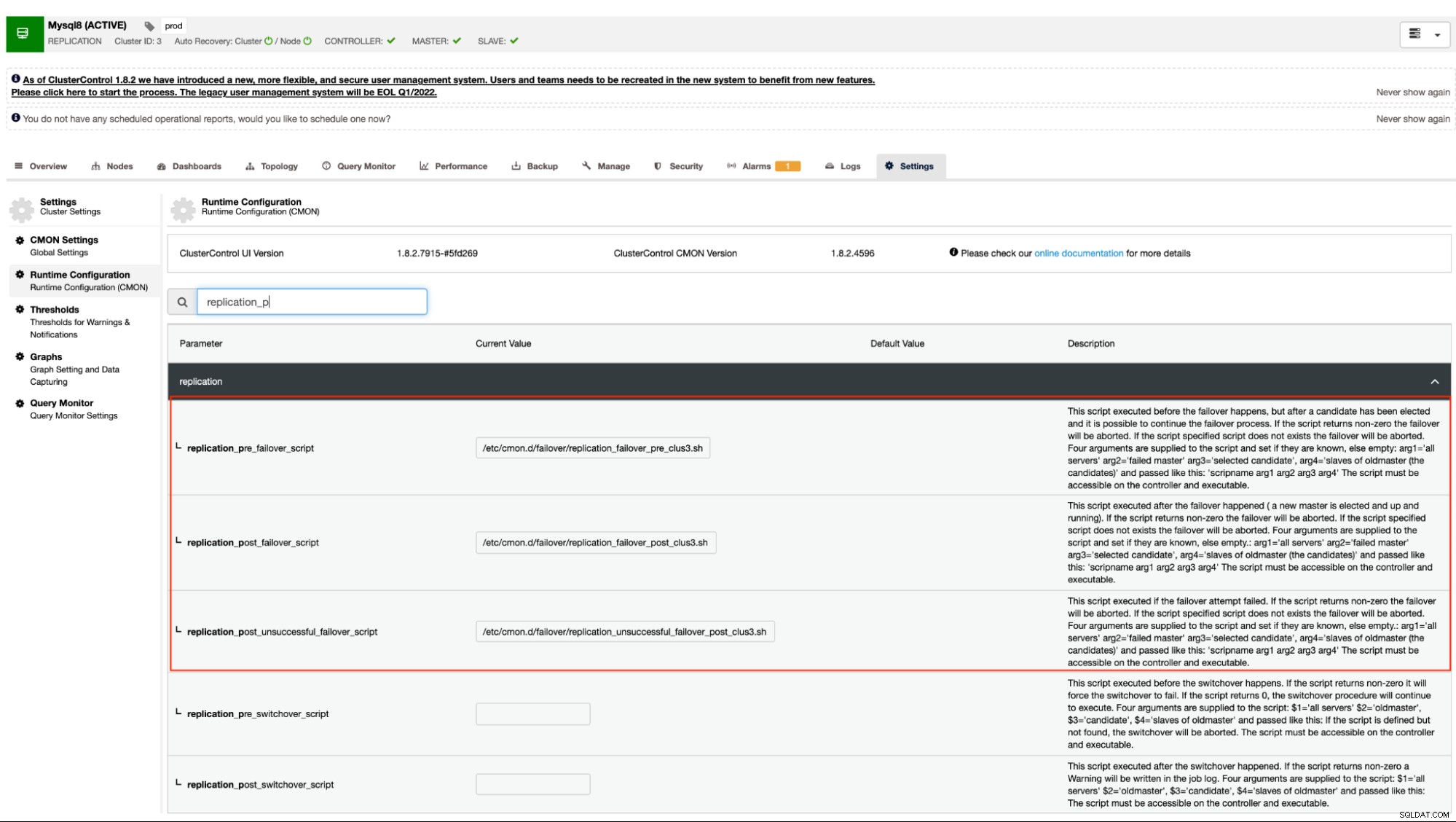
Questo approccio richiederebbe comunque un riavvio del servizio cmon prima che possa riflettere il modifiche apportate a queste opzioni di configurazione per hook pre/post script.
Esempio di hook pre/post script
Idealmente, gli hook pre/post script sono dedicati quando è necessario un failover avanzato per il quale ClusterControl non è in grado di gestire la complessità della configurazione del database. Ad esempio, se gestisci diversi data center con maggiore sicurezza e desideri determinare se l'avviso di irraggiungibilità della rete non è un falso allarme positivo. Deve verificare se il primario e lo slave possono raggiungersi e viceversa e può raggiungere anche dai nodi del database andando all'host ClusterControl.
Facciamolo nel nostro esempio e dimostriamo come puoi trarne vantaggio.
Dettagli del server e script
In questo esempio, sto utilizzando un cluster di replica MariaDB con solo un primario e una replica. Gestito da ClusterControl per la gestione del failover.
Controllo cluster =192.168.40.110
primario (debnode5) =192.168.30.50
replica (debnode9) =192.168.30.90
Nel nodo primario, crea lo script come indicato di seguito,
example@sqldat.com:~# cat /opt/pre_failover.sh
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat >> /tmp/debnode5.tmp"Assicurati che /opt/pre_failover.sh sia eseguibile, ovvero
$ chmod +x /opt/pre_failover.shQuindi usa questo script per essere coinvolto tramite cron. In questo esempio, ho creato un file /etc/cron.d/ccfailover e ho i seguenti contenuti:
example@sqldat.com:~# cat /etc/cron.d/ccfailover
#!/bin/bash
* * * * * vagrant /opt/pre_failover.shNella tua replica, usa i seguenti passaggi che abbiamo fatto per il primario, tranne cambiare il nome host. Vedi quanto segue di ciò che ho di seguito nella mia replica:
example@sqldat.com:~# tail -n+1 /etc/cron.d/ccfailover /opt/pre_failover.sh
==> /etc/cron.d/ccfailover <==
#!/bin/bash
* * * * * vagrant /opt/pre_failover.sh
==> /opt/pre_failover.sh <==
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat > /tmp/debnode9.tmp"e assicurati che lo script invocato nel nostro cron sia eseguibile,
example@sqldat.com:~# ls -alth /opt/pre_failover.sh
-rwxr-xr-x 1 root root 104 Jun 14 05:09 /opt/pre_failover.shClusterControl pre/post script
In questa dimostrazione, il mio cluster_id è 3. Come affermato in precedenza nella nostra documentazione, è necessario che questi script risiedano nel nostro host controller CC. Quindi nel mio /etc/cmon.d/cmon_3.cnf, ho quanto segue:
[example@sqldat.com cmon.d]# tail -n3 /etc/cmon.d/cmon_3.cnf
replication_pre_failover_script = /etc/cmon.d/failover/replication_failover_pre_clus3.sh
replication_post_failover_script = /etc/cmon.d/failover/replication_failover_post_clus3.sh
replication_post_unsuccessful_failover_script = /etc/cmon.d/failover/replication_unsuccessful_failover_post_clus3.shConsiderando che il seguente script di failover "pre" determina se entrambi i nodi sono stati in grado di raggiungere l'host del controller CC. Vedi quanto segue:
[example@sqldat.com cmon.d]# tail -n+1 /etc/cmon.d/failover/replication_failover_pre_clus3.sh
#!/bin/bash
arg1=$1
debnode5_tstamp=$(tail /tmp/debnode5.tmp)
debnode9_tstamp=$(tail /tmp/debnode9.tmp)
cc_tstamp=$(date -u +%s)
diff_debnode5=$(expr $cc_tstamp - $debnode5_tstamp)
diff_debnode9=$(expr $cc_tstamp - $debnode5_tstamp)
if [[ "$diff_debnode5" -le 60 && "$diff_debnode9" -le 60 ]]; then
echo "failover cannot proceed. It's just a false alarm. Checkout the firewall in your CC host";
exit 1;
elif [[ "$diff_debnode5" -gt 60 || "$diff_debnode9" -gt 60 ]]; then
echo "Either both nodes ($arg1) or one of them were not able to connect the CC host. One can be unreachable. Failover proceed!";
exit 0;
else
echo "false alarm. Failover discarded!"
exit 1;
fi
Whereas my post scripts just simply echoes and redirects the output to a file, just for the test.
[example@sqldat.com failover]# tail -n+1 replication_*_post*3.sh
==> replication_failover_post_clus3.sh <==
#!/bin/bash
echo "post failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_failover_script_cid3.txt
==> replication_unsuccessful_failover_post_clus3.sh <==
#!/bin/bash
echo "post unsuccessful failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_unsuccessful_failover_script_cid3.txt
Dimostra il failover
Ora, proviamo a simulare un'interruzione di rete sul nodo primario e vediamo come reagirà. Nel mio nodo principale, rimuovo l'interfaccia di rete utilizzata per comunicare con la replica e il controller CC.
example@sqldat.com:~# ip link set enp0s8 downDurante il primo tentativo di failover, CC è stato in grado di eseguire il mio pre-script che si trova in /etc/cmon.d/failover/replication_failover_pre_clus3.sh. Vedi sotto come funziona:
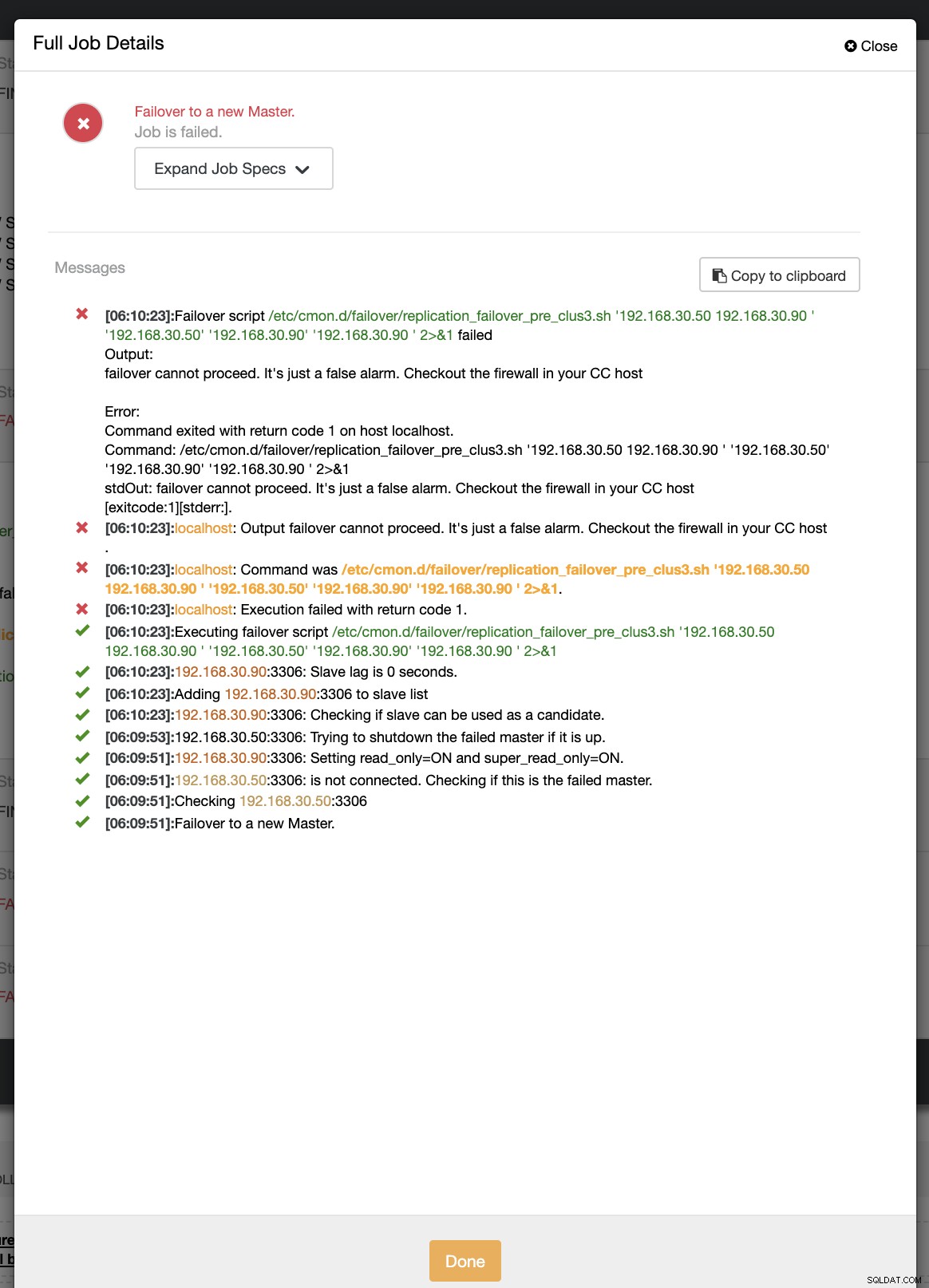
Ovviamente, fallisce perché il timestamp che è stato registrato non è ancora più di un minuto o è stato solo pochi secondi fa che il primario era ancora in grado di connettersi con il controller CC. Ovviamente, questo non è l'approccio perfetto quando si ha a che fare con uno scenario reale. Tuttavia, ClusterControl è stato in grado di richiamare ed eseguire lo script perfettamente come previsto. Ora, che ne dici se raggiunge effettivamente più di un minuto (cioè> 60 secondi)?
Nel nostro secondo tentativo di failover, poiché il timestamp raggiunge più di 60 secondi, viene considerato un vero positivo e ciò significa che dobbiamo eseguire il failover come previsto. CC è stato in grado di eseguirlo perfettamente e persino di eseguire lo script del post come previsto. Questo può essere visto nel registro dei lavori. Vedi lo screenshot qui sotto:
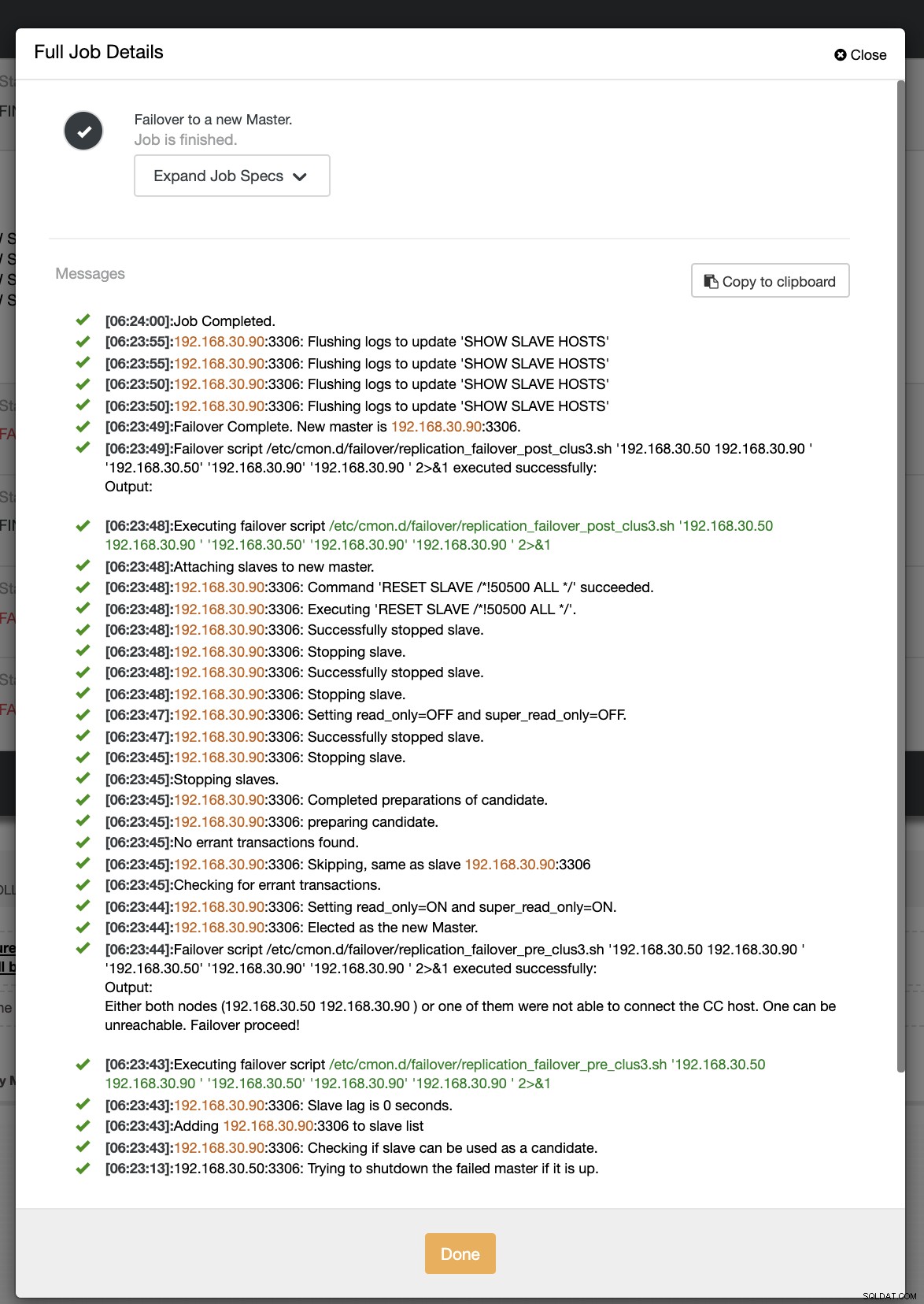
Verificando se il mio post script è stato eseguito, è stato in grado di creare il registro file nella directory CC /tmp come previsto,
[example@sqldat.com tmp]# cat /tmp/post_failover_script_cid3.txtScript post failover sul cluster 3 con args:192.168.30.50 192.168.30.90 192.168.30.50 192.168.30.90 192.168.30.90
Ora, la mia topologia è stata modificata e il failover è riuscito!
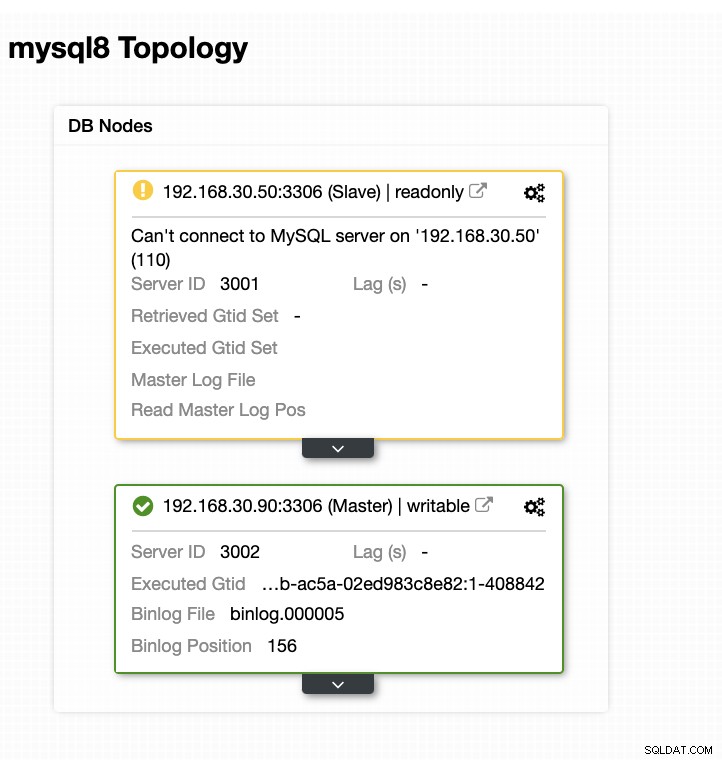
Conclusione
Per qualsiasi configurazione di database complicata che potresti avere, quando è richiesto un failover avanzato, gli script pre/post possono essere molto utili per rendere le cose realizzabili. Poiché ClusterControl supporta queste funzionalità, abbiamo dimostrato quanto sia potente e utile. Anche con i suoi limiti, ci sono sempre modi per rendere le cose realizzabili e utili soprattutto negli ambienti di produzione.