PostgreSQL è un progetto fantastico e si evolve a un ritmo incredibile. Ci concentreremo sull'evoluzione delle capacità di tolleranza agli errori in PostgreSQL in tutte le sue versioni con una serie di post sul blog. Questo è il quarto post della serie e parleremo del commit sincrono e dei suoi effetti sulla tolleranza agli errori e sull'affidabilità di PostgreSQL.
Se desideri assistere ai progressi dell'evoluzione dall'inizio, controlla i primi tre post del blog della serie di seguito. Ogni post è indipendente, quindi non è necessario leggerne uno per capirne un altro.
- Evoluzione della tolleranza agli errori in PostgreSQL
- Evoluzione della tolleranza ai guasti in PostgreSQL:fase di replica
- Evoluzione della tolleranza ai guasti in PostgreSQL:viaggio nel tempo
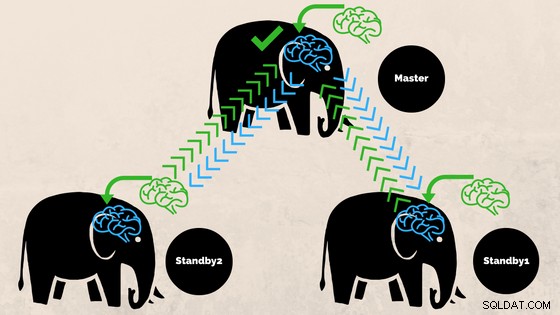
Impegno sincrono
Per impostazione predefinita, PostgreSQL implementa la replica asincrona, in cui i dati vengono trasmessi in streaming ogni volta che è conveniente per il server. Ciò può comportare la perdita di dati in caso di failover. È possibile chiedere a Postgres di richiedere uno (o più) standby per riconoscere la replica dei dati prima del commit, questo è chiamato replica sincrona (commissione sincrona ) .
Con la replica sincrona, il ritardo di replica direttamente influisce sul tempo trascorso delle transazioni sul master. Con la replica asincrona, il master può continuare a piena velocità.
La replica sincrona garantisce che i dati vengano scritti su almeno due nodi prima che all'utente o all'applicazione venga detto che una transazione è stata salvata.
L'utente può selezionare la modalità di commit di ogni transazione , in modo che sia possibile avere transazioni di commit sincrone e asincrone in esecuzione contemporaneamente.
Ciò consente compromessi flessibili tra prestazioni e certezza della durata delle transazioni.
Configurazione del commit sincrono
Per impostare la replica sincrona in Postgres dobbiamo configurare synchronous_commit parametro in postgresql.conf.
Il parametro specifica se il commit della transazione attenderà la scrittura dei record WAL su disco prima che il comando restituisca un successo indicazione al cliente. I valori validi sono on , applicazione_remota , scrittura_remota , locale e disattivato . Discuteremo come funzionano le cose in termini di replica sincrona quando configuriamo synchronous_commit parametro con ciascuno dei valori definiti.
Cominciamo con la documentazione di Postgres (9.6):
Qui comprendiamo il concetto di commit sincrono, come abbiamo descritto nella parte introduttiva del post, sei libero di impostare la replica sincrona ma se non lo fai, c'è sempre il rischio di perdere dati. Ma senza il rischio di creare incoerenze nel database, a differenza della disattivazione di fsync off – comunque questo è argomento per un altro post -. Infine, concludiamo che se necessario non vogliamo perdere alcun dato tra i ritardi di replica e vogliamo essere sicuri che i dati siano scritti su almeno due nodi prima che l'utente/applicazione venga informato che la transazione è stata impegnata , dobbiamo accettare di perdere alcune prestazioni.
Vediamo come funzionano le diverse impostazioni per diversi livelli di sincronizzazione. Prima di iniziare, parliamo di come viene elaborato il commit dalla replica di PostgreSQL. Il client esegue query sul nodo master, le modifiche vengono scritte in un log delle transazioni (WAL) e copiate in rete su WAL sul nodo di standby. Il processo di ripristino sul nodo di standby legge quindi le modifiche da WAL e le applica ai file di dati proprio come durante il ripristino in caso di arresto anomalo. Se lo standby è in hot standby modalità, i client possono emettere query di sola lettura sul nodo mentre ciò sta accadendo. Per ulteriori dettagli su come funziona la replica, puoi consultare il post del blog sulla replica in questa serie.
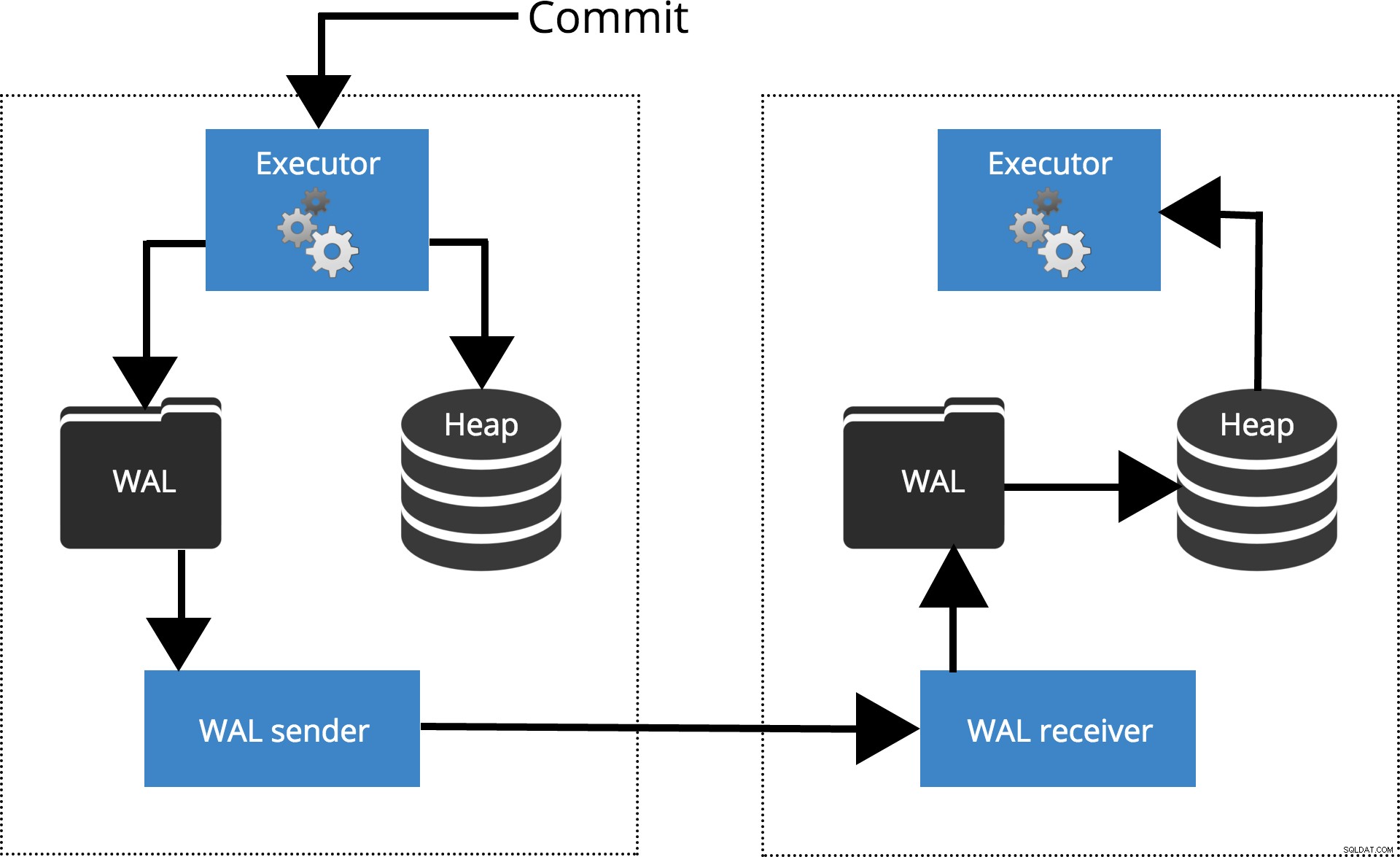
Fig.1 Come funziona la replica
synchronous_commit =disattivato
Quando impostiamo sychronous_commit = off, il COMMIT non attende che il record della transazione venga scaricato sul disco. Questo è evidenziato nella Fig.2 di seguito.
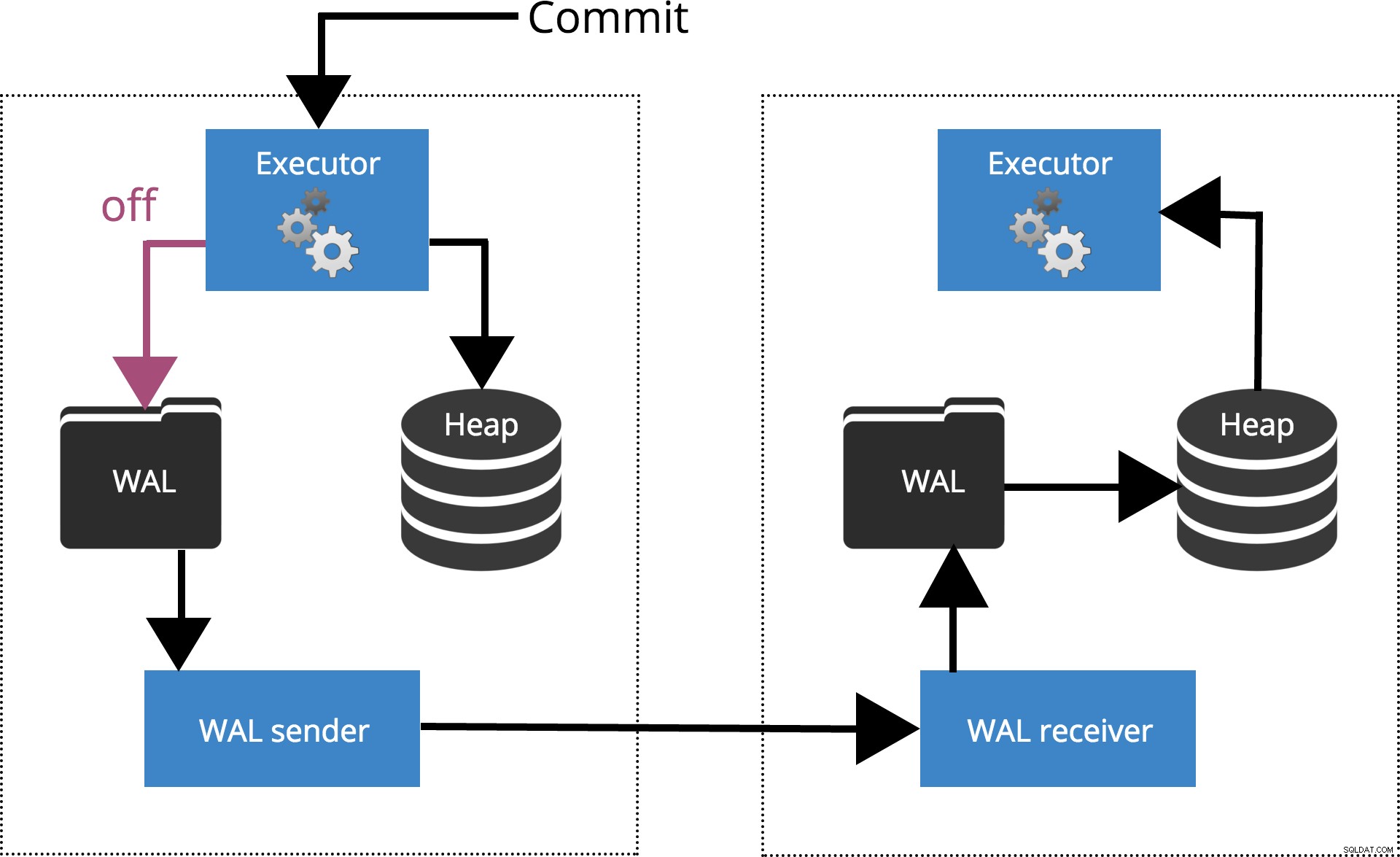
Fig.2 synchronous_commit =off
commit_sincrono =locale
Quando impostiamo synchronous_commit = local, il COMMIT attende fino a quando il record della transazione non viene scaricato sul disco locale. Questo è evidenziato nella Fig.3 di seguito.
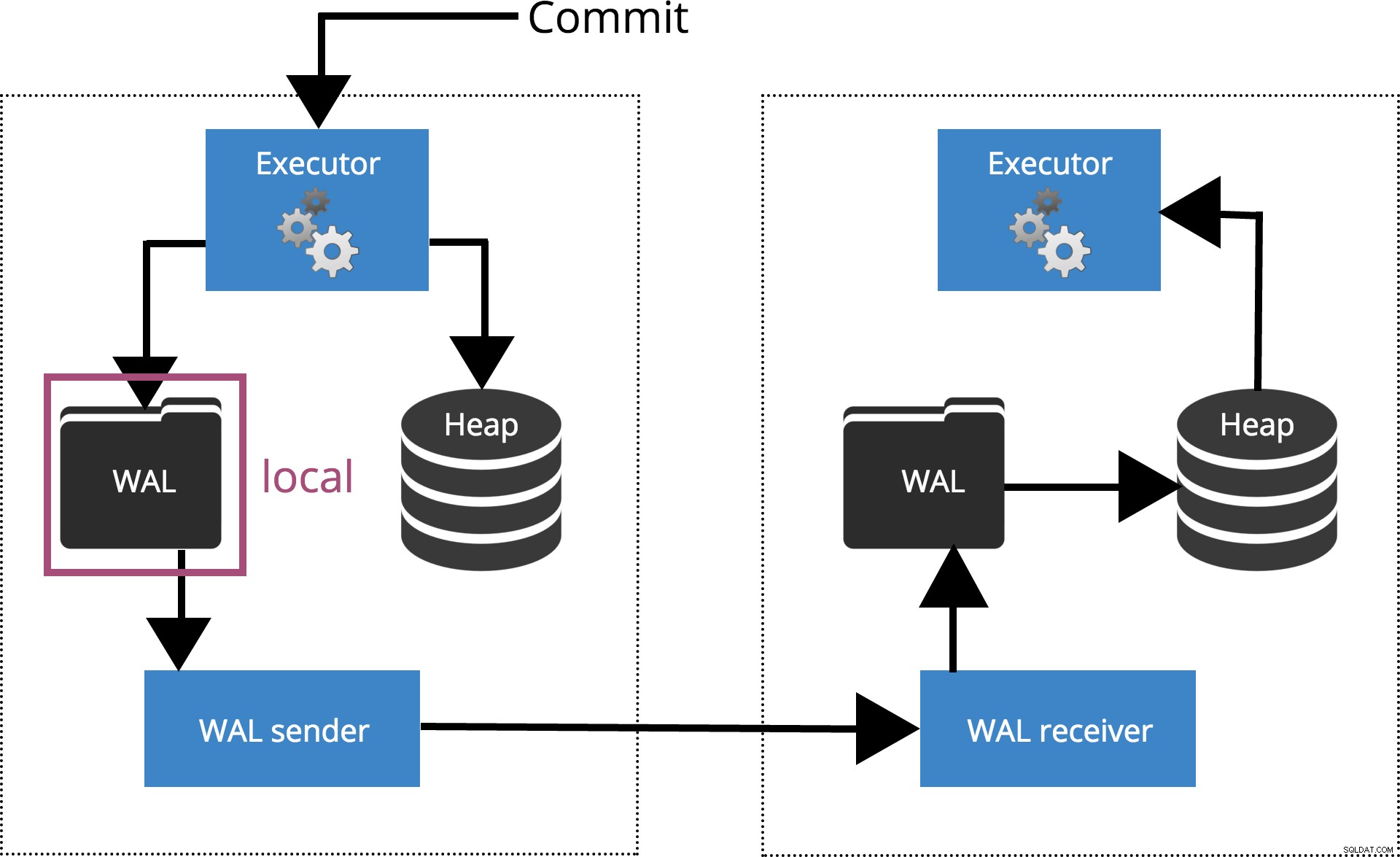
Fig.3 synchronous_commit =locale
synchronous_commit =attivo (predefinito)
Quando impostiamo synchronous_commit = on, il COMMIT aspetterà fino a quando i server specificati da synchronous_standby_names confermare che il record della transazione è stato scritto in modo sicuro su disco. Questo è evidenziato nella Fig.4 di seguito.
Nota: Quando synchronous_standby_names è vuoto, questa impostazione si comporta come synchronous_commit = local .
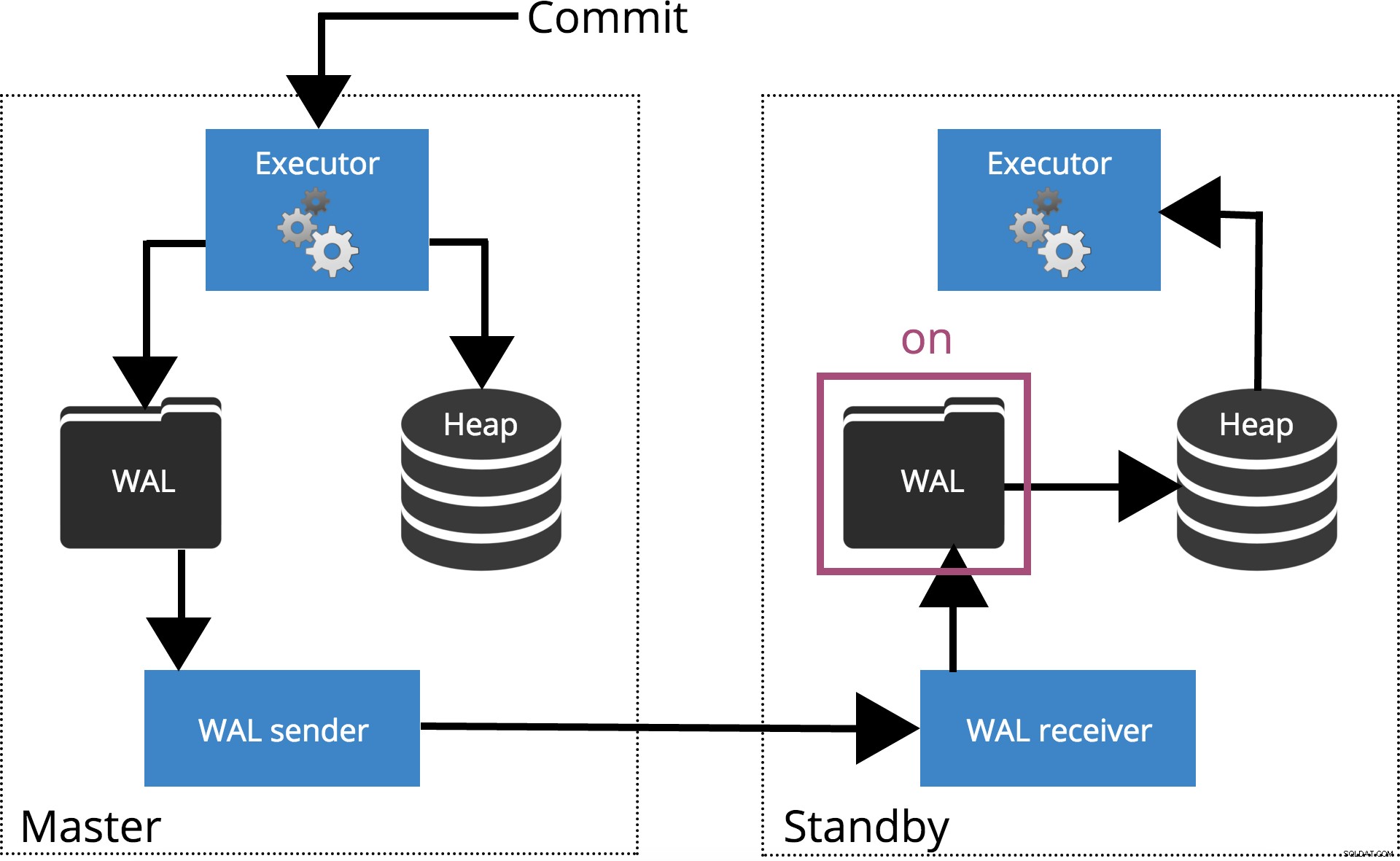
Fig.4 synchronous_commit =attivo
commit_sincrono =scrittura_remota
Quando impostiamo synchronous_commit = remote_write, il COMMIT aspetterà fino a quando i server specificati da synchronous_standby_names confermare la scrittura del record della transazione nel sistema operativo ma non ha necessariamente raggiunto il disco. Questo è evidenziato nella Fig.5 di seguito.
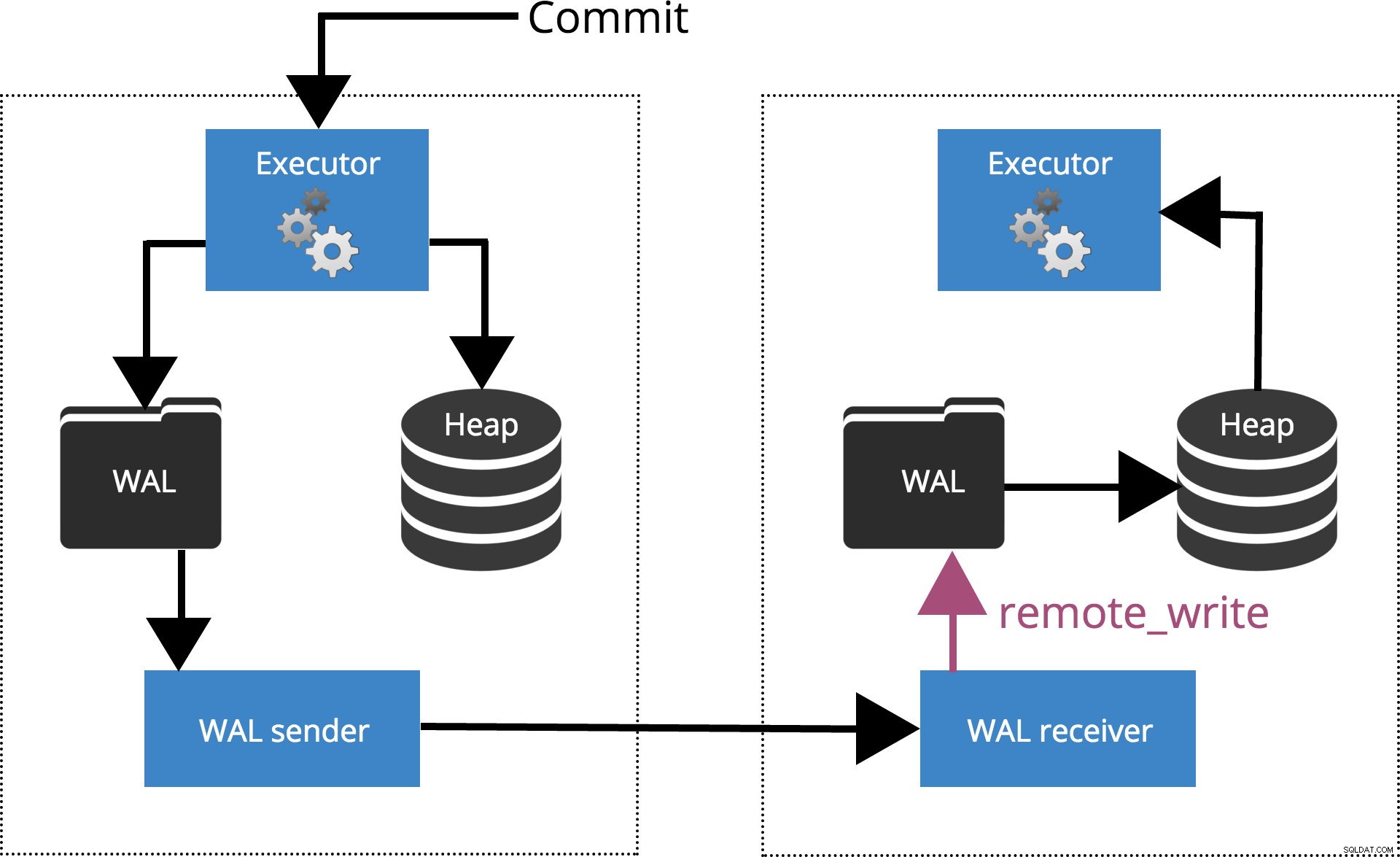
Fig.5 synchronous_commit =remote_write
commit_sincrono =applicazione_remota
Quando impostiamo synchronous_commit = remote_apply, il COMMIT aspetterà fino a quando i server specificati da synchronous_standby_names confermare che il record della transazione è stato applicato al database. Questo è evidenziato nella Fig.6 di seguito.
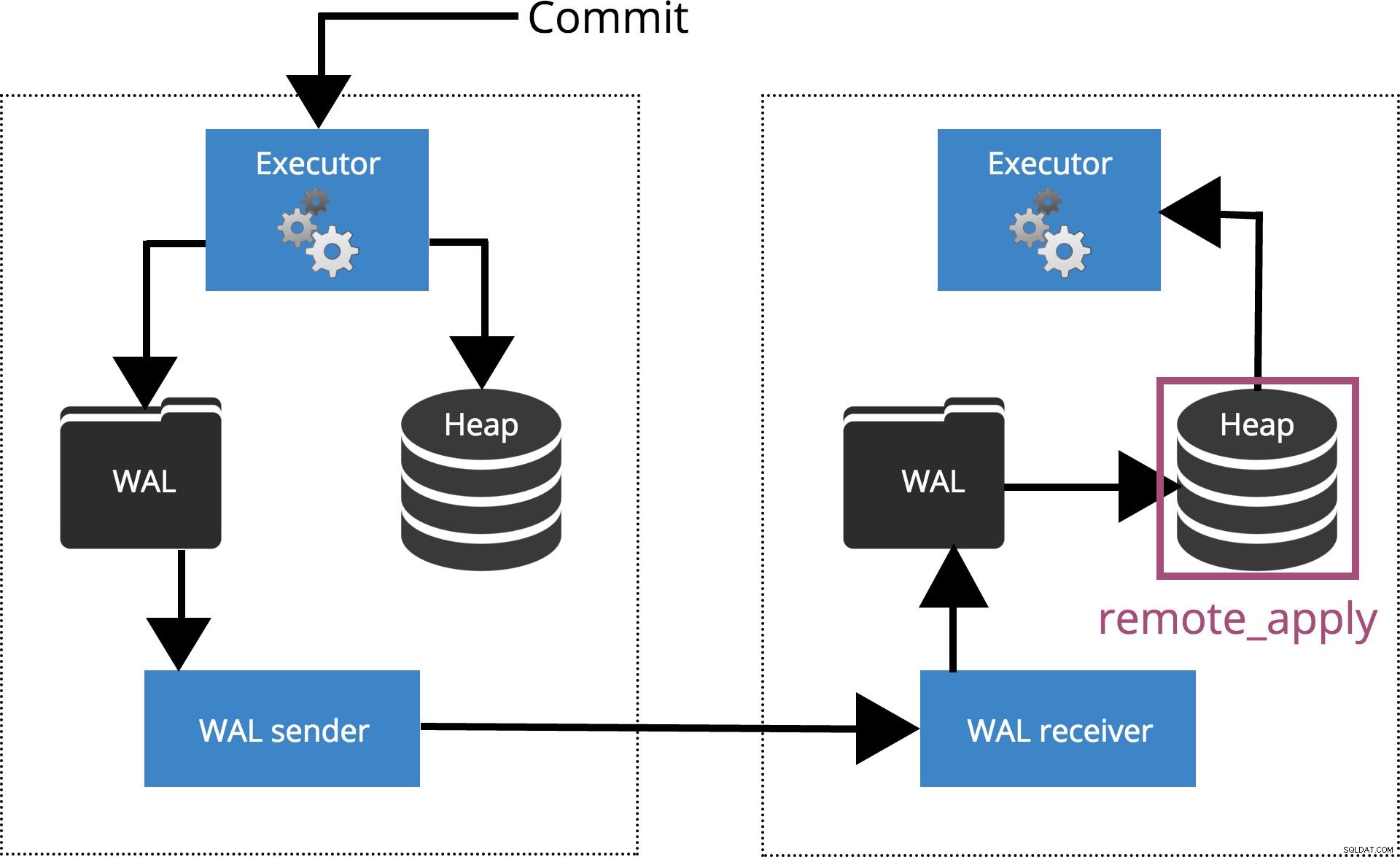
Fig.6 synchronous_commit =remote_apply
Ora, diamo un'occhiata a sychronous_standby_names parametro in dettaglio, a cui si fa riferimento sopra quando si imposta synchronous_commit come on , remote_apply o remote_write .
synchronous_standby_names ='nome_attesa [, …]'
Il commit sincrono attenderà una risposta da uno degli standby elencati nell'ordine di priorità. Ciò significa che se il primo standby è connesso e in streaming, il commit sincrono attenderà sempre una risposta da esso anche se il secondo standby ha già risposto. Il valore speciale di * può essere usato come stanby_name che corrisponderà a qualsiasi standby connesso.
synchronous_standby_names ='num (standby_name [, …])'
Il commit sincrono attenderà una risposta da almeno num numero di standby elencati in ordine di priorità. Si applicano le stesse regole di cui sopra. Quindi, ad esempio, impostando synchronous_standby_names = '2 (*)' farà attendere il commit sincrono per la risposta da qualsiasi 2 server in standby.
synchronous_standby_names è vuoto
Se questo parametro è vuoto come mostrato, cambia il comportamento dell'impostazione di synchronous_commit su on , remote_write o remote_apply comportarsi come local (ovvero, il COMMIT aspetterà solo lo svuotamento sul disco locale).
Conclusione
In questo post del blog, abbiamo discusso della replica sincrona e descritto i diversi livelli di protezione disponibili in Postgres. Continueremo con la replica logica nel prossimo post del blog.
Riferimenti
Un ringraziamento speciale al mio collega Petr Jelinek per avermi dato l'idea per le illustrazioni.
Documentazione PostgreSQL
Libro di cucina per l'amministrazione di PostgreSQL 9 – Seconda edizione