Lavorando nel settore IT, probabilmente abbiamo sentito la parola "failover" molte volte, ma può anche sollevare domande come:che cos'è davvero un failover? Per cosa possiamo usarlo? È importante averlo? Come possiamo farlo?
Sebbene possano sembrare domande piuttosto semplici, è importante tenerne conto in qualsiasi ambiente di database. E il più delle volte, non prendiamo in considerazione le basi...
Per iniziare, diamo un'occhiata ad alcuni concetti di base.
Cos'è il failover?
Il failover è la capacità di un sistema di continuare a funzionare anche se si verifica un errore. Suggerisce che le funzioni del sistema siano assunte dai componenti secondari se i componenti primari si guastano.
Nel caso di PostgreSQL, esistono diversi strumenti che consentono di implementare un cluster di database resiliente ai guasti. Un meccanismo di ridondanza disponibile in modo nativo in PostgreSQL è la replica. E la novità di PostgreSQL 10 è l'implementazione della replica logica.
Cos'è la replica?
È il processo di copia e mantenimento dei dati aggiornati in uno o più nodi del database. Utilizza un concetto di nodo master che riceve le modifiche e nodi slave in cui vengono replicate.
Abbiamo diversi modi per classificare la replica:
- Replica sincrona:non c'è perdita di dati anche se il nostro nodo master è perso, ma i commit nel master devono attendere una conferma dallo slave, che può influire sulle prestazioni.
- Replica asincrona:esiste la possibilità di perdita di dati nel caso in cui perdiamo il nostro nodo master. Se la replica per qualche motivo non viene aggiornata al momento dell'incidente, le informazioni che non sono state copiate potrebbero andare perse.
- Replica fisica:i blocchi del disco vengono copiati.
- Replica logica:streaming delle modifiche ai dati.
- Slave Warm Standby:non supportano le connessioni.
- Slave Hot Standby:supportano connessioni di sola lettura, utili per report o query.
A cosa serve il failover?
Esistono diversi possibili usi del failover. Vediamo alcuni esempi.
Migrazione
Se vogliamo migrare da un datacenter a un altro riducendo al minimo i tempi di inattività, possiamo utilizzare il failover.
Supponiamo che il nostro master si trovi nel datacenter A e desideriamo migrare i nostri sistemi nel datacenter B.
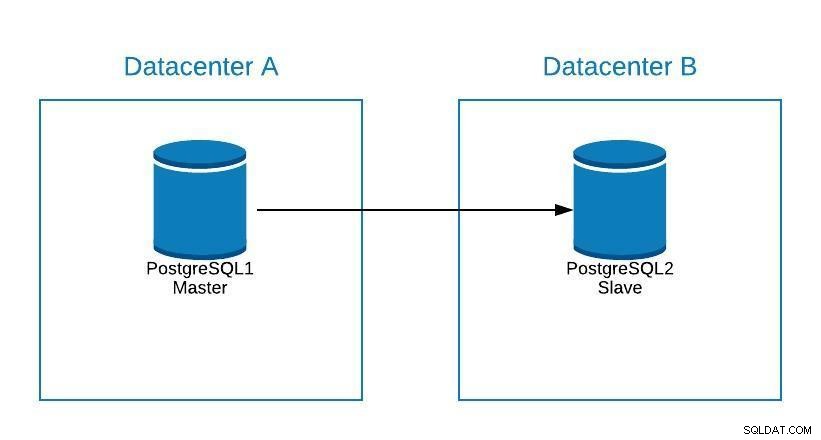 Diagramma di migrazione 1
Diagramma di migrazione 1 Possiamo creare una replica nel datacenter B. Una volta sincronizzata, dobbiamo arrestare il nostro sistema, promuovere la nostra replica a nuovo master e failover, prima di indirizzare il nostro sistema al nuovo master nel datacenter B.
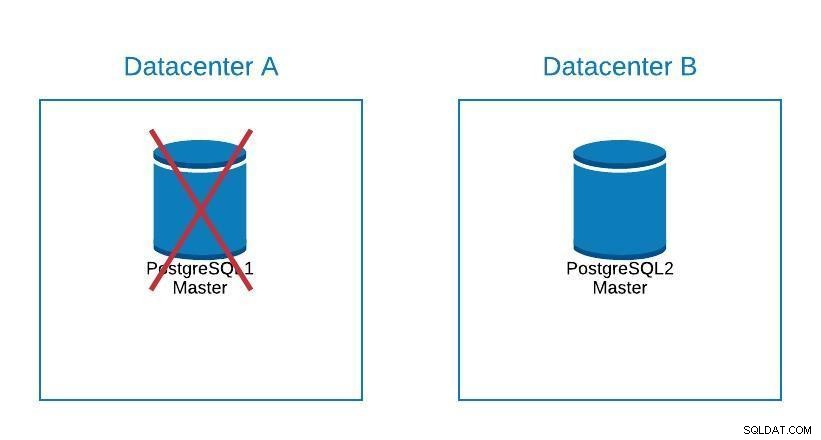 Diagramma di migrazione 2
Diagramma di migrazione 2 Il failover non riguarda solo il database, ma anche le applicazioni. Come fanno a sapere a quale database connettersi? Certamente non vogliamo dover modificare la nostra applicazione, poiché ciò estenderà solo i nostri tempi di inattività. Quindi, possiamo configurare un bilanciamento del carico in modo che quando interrompiamo il nostro master, punti automaticamente al server successivo che viene promosso.
Un'altra opzione è l'uso del DNS. Promuovendo la replica master nel nuovo datacenter, modifichiamo direttamente l'indirizzo IP dell'hostname che punta al master. In questo modo evitiamo di dover modificare la nostra applicazione e, sebbene non possa essere eseguita automaticamente, è un'alternativa se non vogliamo implementare un bilanciamento del carico.
Avere una singola istanza del servizio di bilanciamento del carico non è eccezionale in quanto può diventare un singolo punto di errore. Pertanto, puoi anche implementare il failover per il servizio di bilanciamento del carico, utilizzando un servizio come keepalived. In questo modo, se abbiamo un problema con il nostro sistema di bilanciamento del carico principale, keepalived è responsabile della migrazione dell'IP al nostro sistema di bilanciamento del carico secondario e tutto continua a funzionare in modo trasparente.
Manutenzione
Se dobbiamo eseguire qualsiasi manutenzione sul nostro server di database master postgreSQL, possiamo promuovere il nostro slave, eseguire l'attività e ricostruire uno slave sul nostro vecchio master.
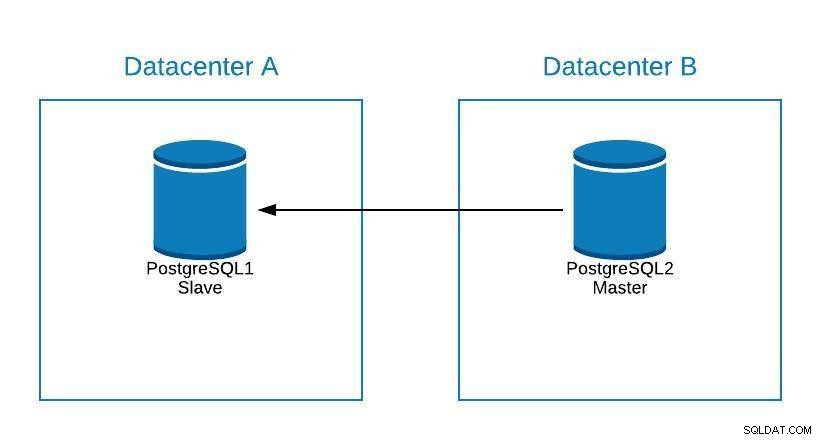 Schema di manutenzione 1
Schema di manutenzione 1 Dopodiché possiamo ripromozionare il vecchio padrone, e ripetere il processo di ricostruzione dello schiavo, tornando allo stato iniziale.
Schema di manutenzione 2 In questo modo potremmo lavorare sul nostro server, senza correre il rischio di essere offline o di perdere informazioni durante l'esecuzione della manutenzione.
Aggiorna
Sebbene PostgreSQL 11 non sia ancora disponibile, sarebbe tecnicamente possibile eseguire l'aggiornamento da PostgreSQL versione 10, utilizzando la replica logica, come si può fare con altri motori.
I passaggi sarebbero gli stessi della migrazione a un nuovo datacenter (vedere la sezione sulla migrazione), solo che il nostro slave sarebbe in PostgreSQL 11.
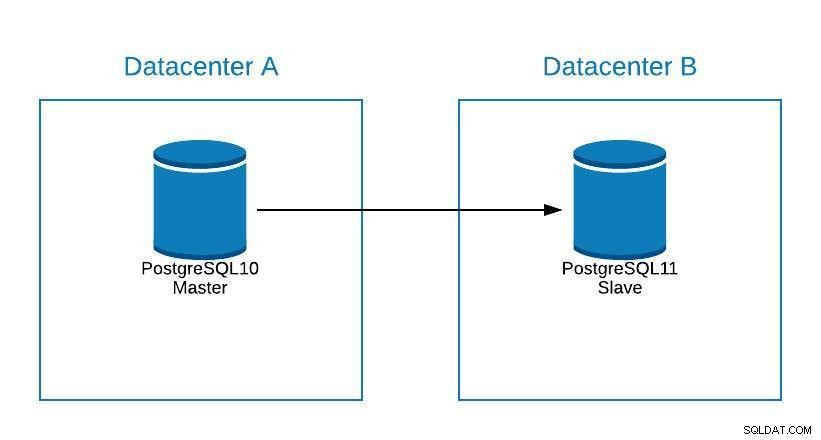 Schema di aggiornamento 1
Schema di aggiornamento 1 Problemi
La funzione più importante del failover è ridurre al minimo i nostri tempi di inattività o evitare la perdita di informazioni, quando si verifica un problema con il nostro database principale.
Se per qualche motivo perdiamo il nostro database master, possiamo eseguire un failover promuovendo il nostro slave a master e mantenendo in funzione i nostri sistemi.
Per fare ciò, PostgreSQL non ci fornisce alcuna soluzione automatizzata. Possiamo farlo manualmente, oppure automatizzarlo tramite uno script o uno strumento esterno.
Per promuovere il nostro schiavo a padrone:
-
Esegui pg_ctl promuovi
bash-4.2$ pg_ctl promote -D /var/lib/pgsql/10/data/ waiting for server to promote.... done server promoted - Crea un file trigger_file che dobbiamo aver aggiunto nel recovery.conf della nostra directory di dati.
bash-4.2$ cat /var/lib/pgsql/10/data/recovery.conf standby_mode = 'on' primary_conninfo = 'application_name=pgsql_node_0 host=postgres1 port=5432 user=replication password=****' recovery_target_timeline = 'latest' trigger_file = '/tmp/failover.trigger' bash-4.2$ touch /tmp/failover.trigger
Per implementare una strategia di failover, è necessario pianificarla e testarla a fondo attraverso diversi scenari di errore. Poiché i guasti possono verificarsi in diversi modi e la soluzione dovrebbe idealmente funzionare per la maggior parte degli scenari comuni. Se stiamo cercando un modo per automatizzare questo, possiamo dare un'occhiata a ciò che ClusterControl ha da offrire.
ClusterControl per il failover di PostgreSQL
ClusterControl ha una serie di funzionalità relative alla replica PostgreSQL e al failover automatico.
Aggiungi slave
Se desideriamo aggiungere uno slave in un altro data center, sia come emergenza sia per migrare i tuoi sistemi, possiamo andare su Cluster Actions e selezionare Aggiungi replica slave.
 ClusterControl Aggiungi slave 1
ClusterControl Aggiungi slave 1 Dovremo inserire alcuni dati di base, come IP o nome host, directory dei dati (opzionale), slave sincrono o asincrono. Dovremmo avere il nostro schiavo attivo e funzionante dopo pochi secondi.
Nel caso di utilizzo di un altro datacenter, consigliamo di creare uno slave asincrono, altrimenti la latenza può influire notevolmente sulle prestazioni.
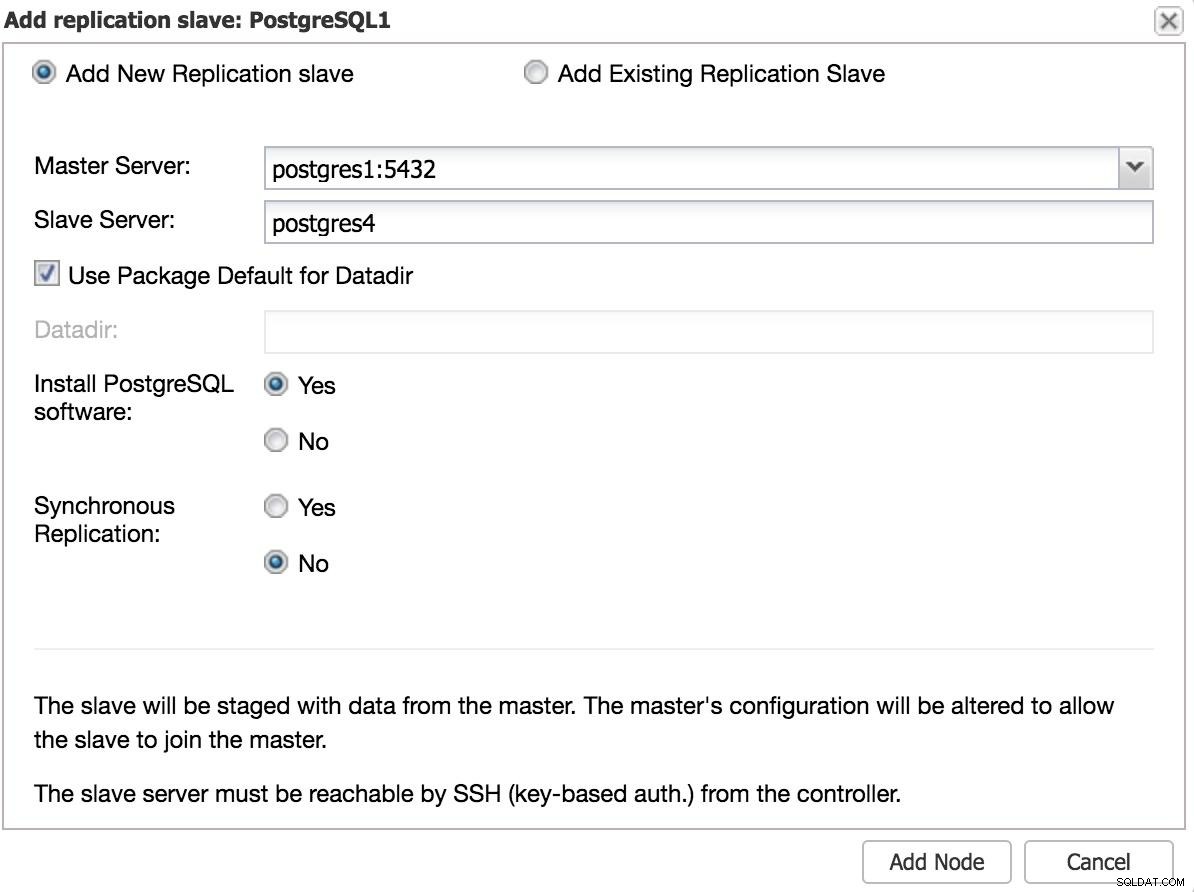 ClusterControl Aggiungi slave 2
ClusterControl Aggiungi slave 2 Failover manuale
Con ClusterControl, il failover può essere eseguito manualmente o automaticamente.
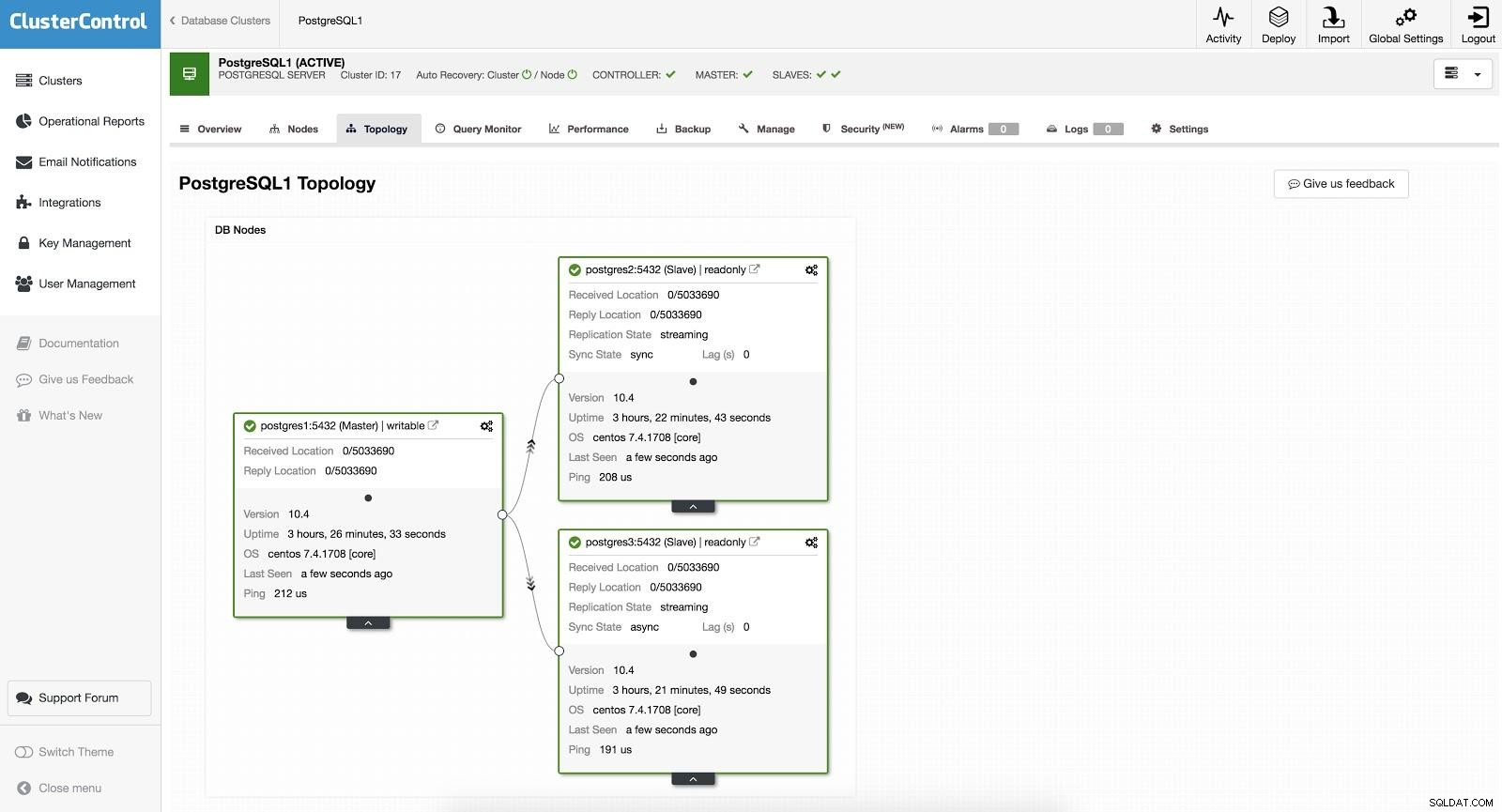 Failover ClusterControl 1
Failover ClusterControl 1 Per eseguire un failover manuale, vai su ClusterControl -> Seleziona Cluster -> Nodi, e nel Nodo Azione di uno dei nostri slave, seleziona "Promuovi Slave". In questo modo, dopo pochi secondi, il nostro schiavo diventa padrone, e quello che prima era il nostro padrone, si trasforma in schiavo.
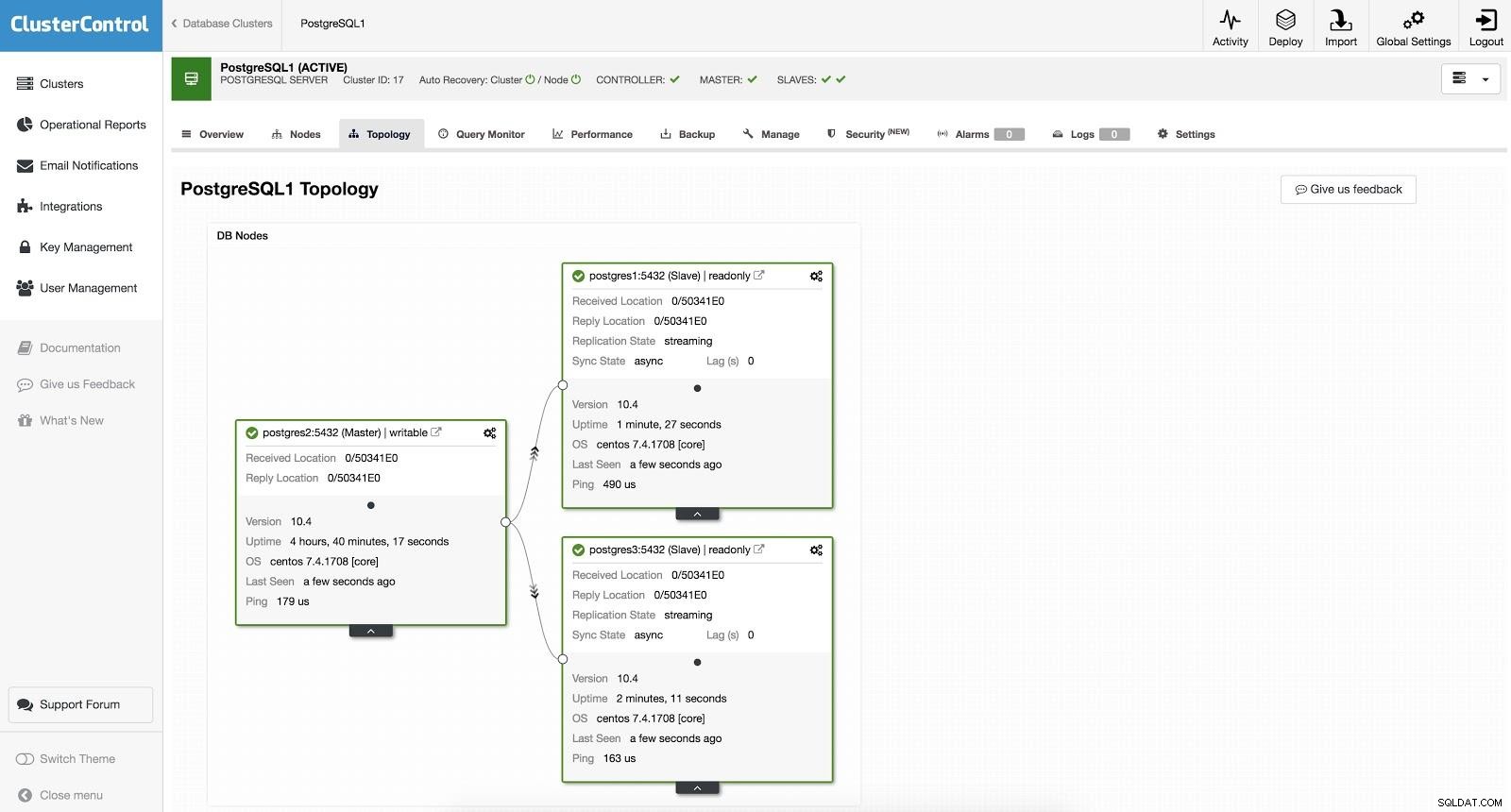 ClusterControl Failover 2
ClusterControl Failover 2 Quanto sopra è utile per le attività di migrazione, manutenzione e upgrade che abbiamo visto in precedenza.
Failover automatico
In caso di failover automatico, ClusterControl rileva i guasti nel master e promuove uno slave con i dati più aggiornati come nuovo master. Funziona anche sul resto degli slave per farli replicare dal nuovo master.
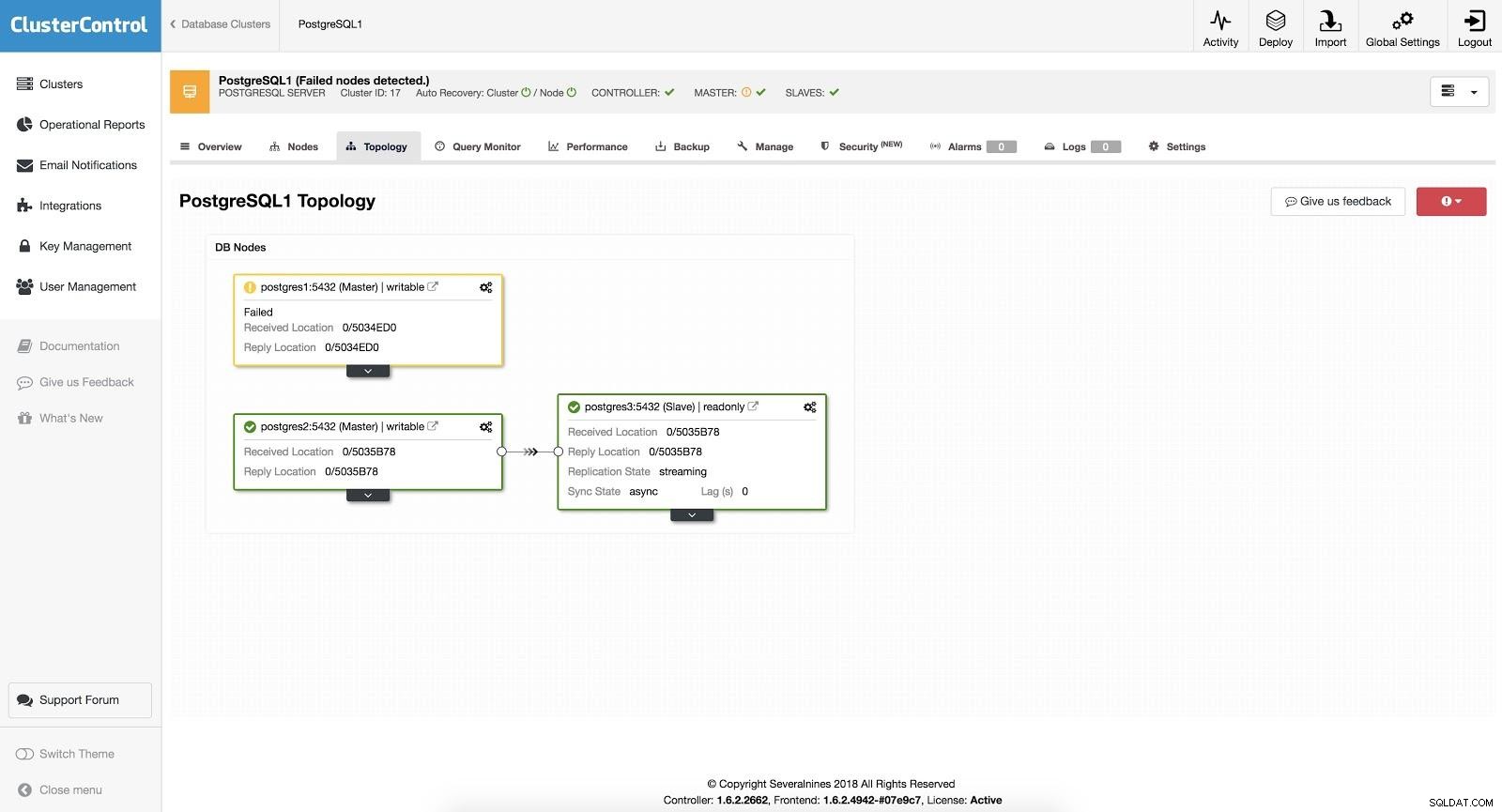 ClusterControl Failover 3
ClusterControl Failover 3 Avendo l'opzione "Autorecovery" su ON, il nostro ClusterControl eseguirà un failover automatico e ci informerà del problema. In questo modo, i nostri sistemi possono riprendersi in pochi secondi e senza il nostro intervento.
Cluster Control ci offre la possibilità di configurare una whitelist/blacklist per definire come vogliamo che i nostri server vengano presi (o non presi in considerazione) al momento di decidere un candidato master.
Tra quelli disponibili secondo la configurazione di cui sopra, ClusterControl sceglierà lo slave più avanzato, utilizzando a tale scopo pg_current_xlog_location (PostgreSQL 9+) o pg_current_wal_lsn (PostgreSQL 10+) a seconda della versione del nostro database.
ClusterControl esegue anche diversi controlli sul processo di failover, al fine di evitare alcuni errori comuni. Un esempio è che se riusciamo a recuperare il nostro vecchio master guasto, NON verrà reintrodotto automaticamente nel cluster, né come master né come slave. Dobbiamo farlo manualmente. Ciò eviterà la possibilità di perdita o incoerenza dei dati nel caso in cui il nostro slave (che abbiamo promosso) fosse in ritardo al momento dell'errore. Potremmo anche voler analizzare il problema in dettaglio, ma quando lo aggiungiamo al nostro cluster, potremmo perdere le informazioni diagnostiche.
Inoltre, se il failover ha esito negativo, non vengono effettuati ulteriori tentativi, è necessario un intervento manuale per analizzare il problema ed eseguire le azioni corrispondenti. Questo per evitare la situazione in cui ClusterControl, in qualità di gestore dell'alta disponibilità, cerca di promuovere lo slave successivo e il successivo. Potrebbe esserci un problema e non vogliamo peggiorare le cose tentando più failover.
Bilanciatori del carico
Come accennato in precedenza, il sistema di bilanciamento del carico è uno strumento importante da considerare per il nostro failover, soprattutto se vogliamo utilizzare il failover automatico nella topologia del nostro database.
Affinché il failover sia trasparente sia per l'utente che per l'applicazione, è necessario un componente intermedio, poiché non è sufficiente promuovere un master in uno slave. Per questo, possiamo usare HAProxy + Keepalived.
Cos'è HAProxy?
HAProxy è un sistema di bilanciamento del carico che distribuisce il traffico da un'origine a una o più destinazioni e può definire regole e/o protocolli specifici per questa attività. Se una qualsiasi delle destinazioni smette di rispondere, viene contrassegnata come offline e il traffico viene inviato alle altre destinazioni disponibili. Ciò impedisce che il traffico venga inviato a una destinazione inaccessibile e previene la perdita di questo traffico indirizzandolo a una destinazione valida.
Cos'è Keepalived?
Keepalived consente di configurare un IP virtuale all'interno di un gruppo di server attivo/passivo. Questo IP virtuale è assegnato a un server "primario" attivo. Se questo server si guasta, l'IP viene automaticamente migrato al server "Secondario" ritenuto passivo, consentendogli di continuare a lavorare con lo stesso IP in modo trasparente per i nostri sistemi.
Per implementare questa soluzione con ClusterControl, abbiamo iniziato come se dovessimo aggiungere uno slave. Vai su Cluster Actions e seleziona Aggiungi Load Balancer (vedi ClusterControl Aggiungi immagine Slave 1).
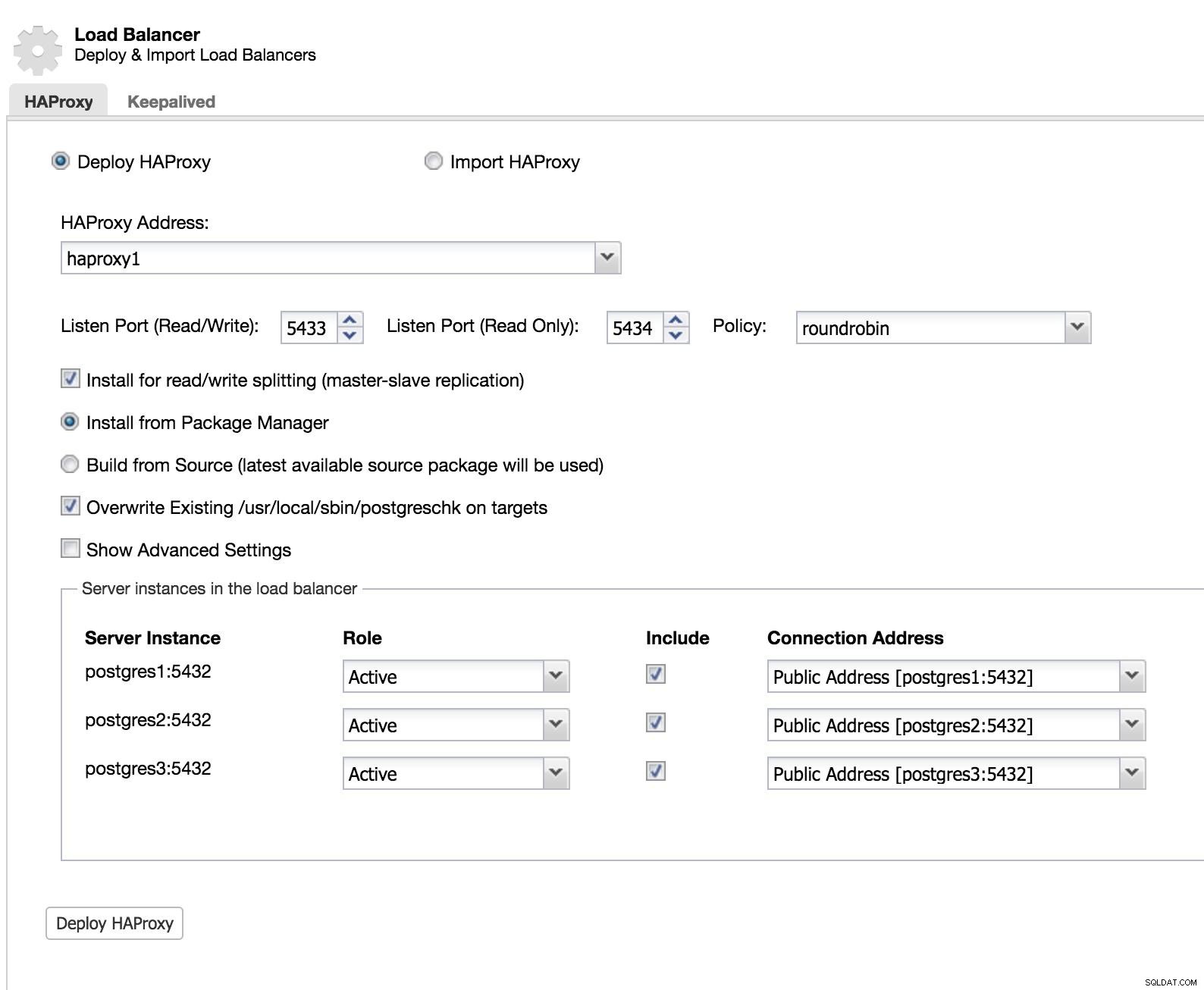 ClusterControl Load Balancer 1
ClusterControl Load Balancer 1 Aggiungiamo le informazioni sul nostro nuovo sistema di bilanciamento del carico e su come vogliamo che si comporti (Politica).
Nel caso in cui desideriamo implementare il failover per il nostro sistema di bilanciamento del carico, dobbiamo configurare almeno due istanze.
Quindi possiamo configurare Keepalived (Seleziona Cluster -> Gestisci -> Load Balancer -> Keepalived).
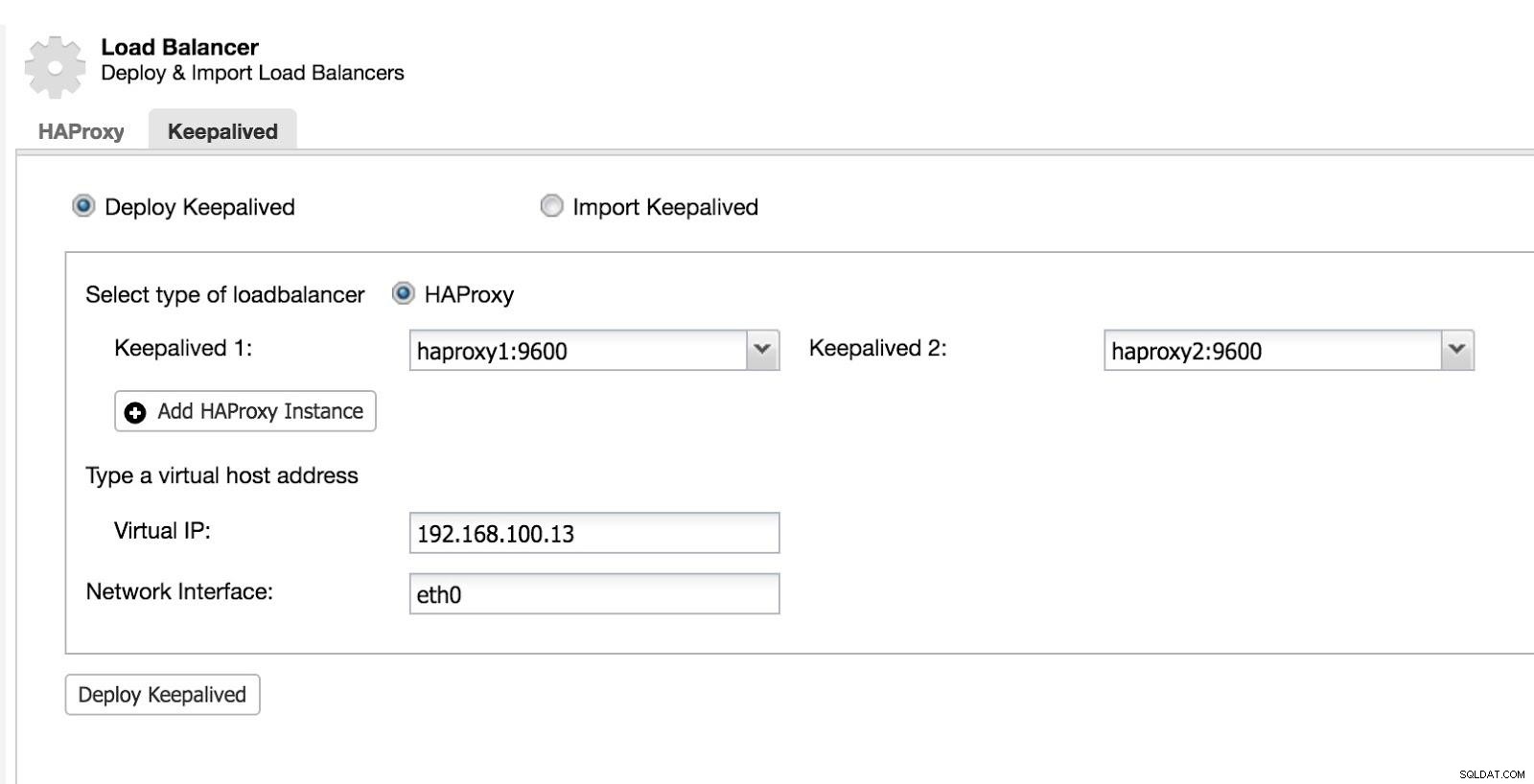 ClusterControl Load Balancer 2
ClusterControl Load Balancer 2 Dopo questo, abbiamo la seguente topologia:
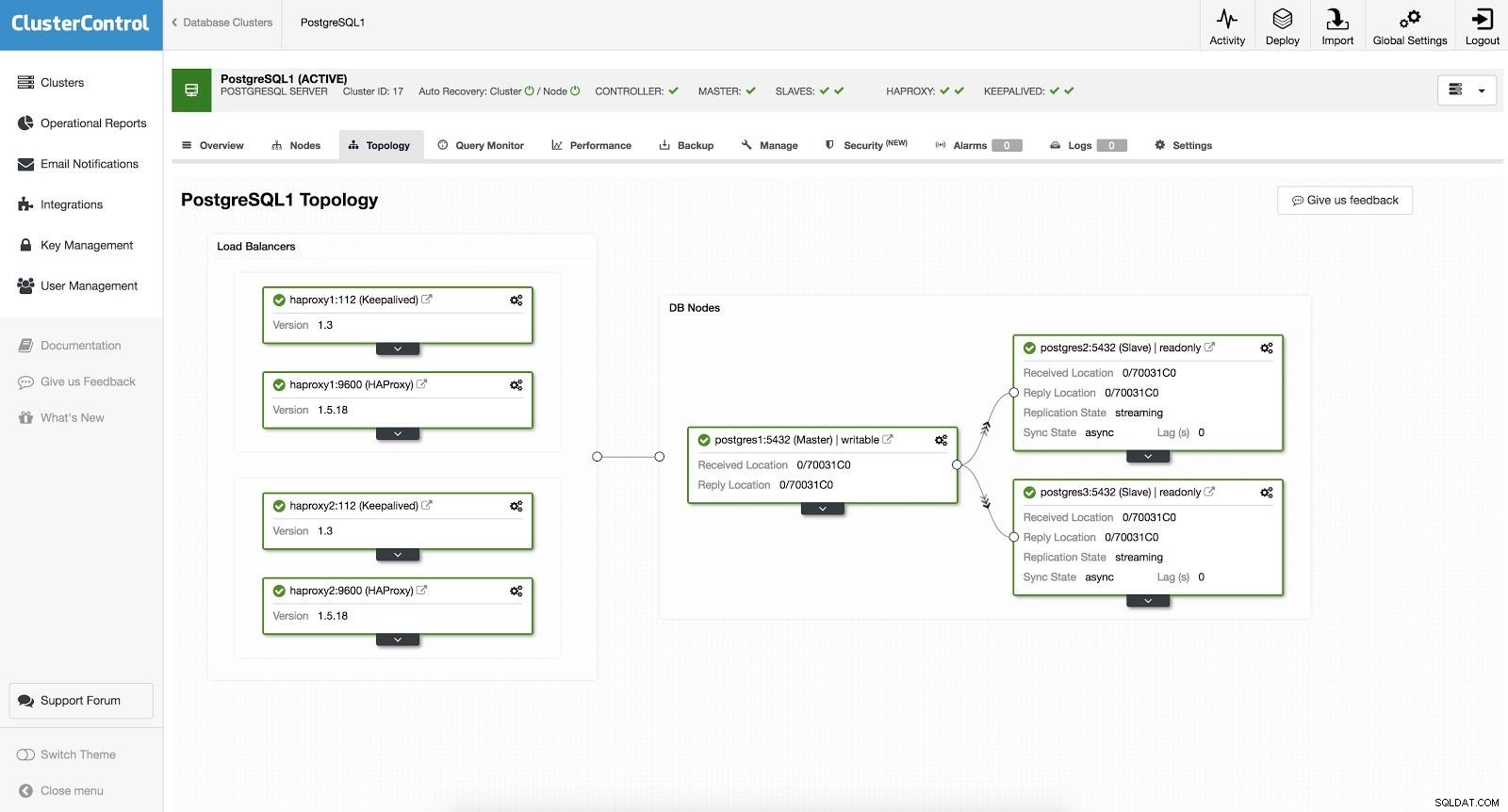 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 HAProxy è configurato con due porte diverse, una di lettura-scrittura e una di sola lettura.
Nella nostra porta di lettura-scrittura, abbiamo il nostro server master online e il resto dei nostri nodi offline. Nella porta di sola lettura abbiamo sia il master che gli slave online. In questo modo possiamo bilanciare il traffico di lettura tra i nostri nodi. Durante la scrittura verrà utilizzata la porta di lettura-scrittura, che punterà al master.
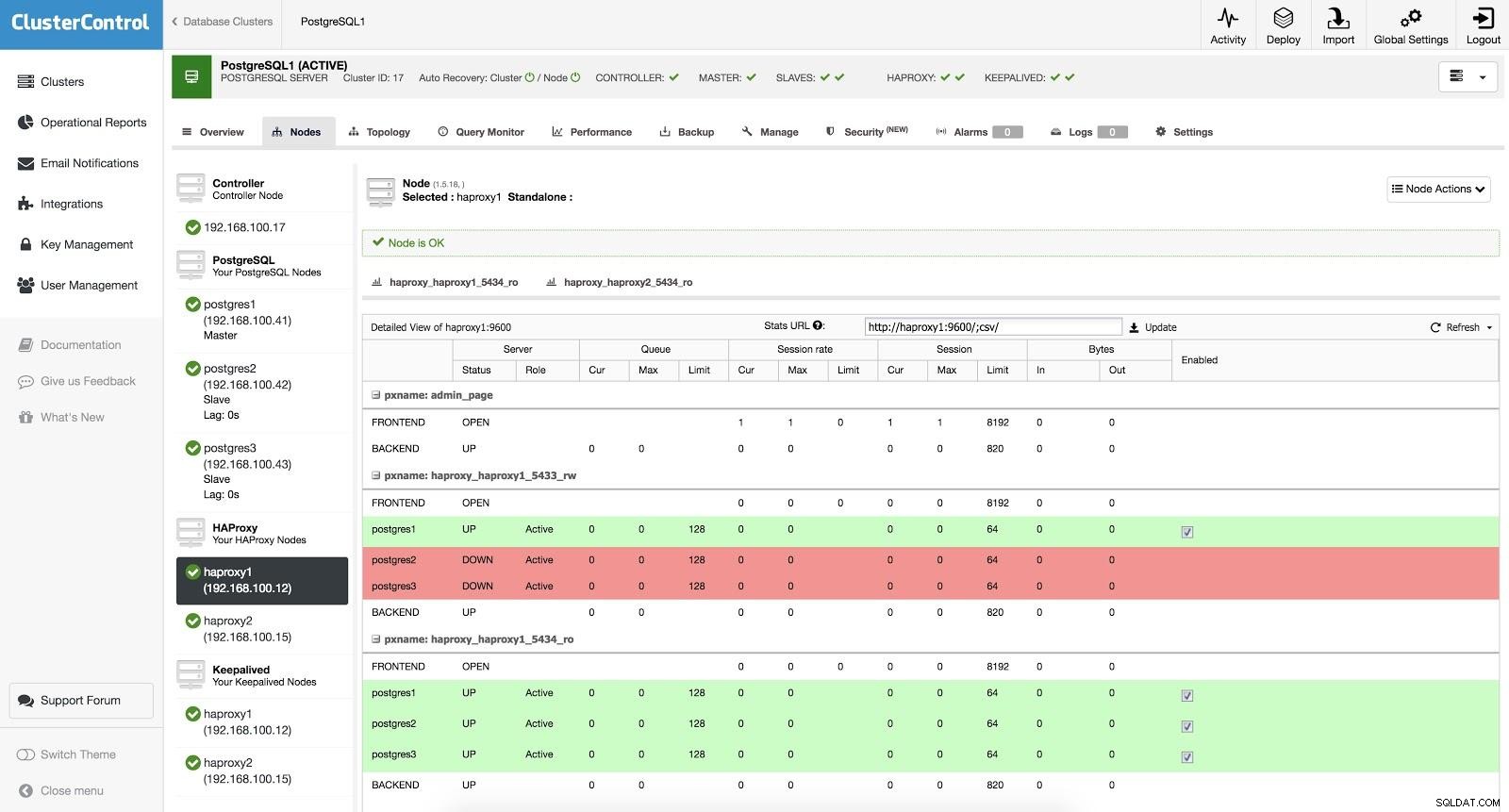 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 Quando HAProxy rileva che uno dei nostri nodi, master o slave, non è accessibile, lo contrassegna automaticamente come offline. HAProxy non invierà alcun traffico ad esso. Questo controllo viene eseguito dagli script di controllo dello stato configurati da ClusterControl al momento della distribuzione. Questi controllano se le istanze sono attive, se sono in fase di ripristino o sono di sola lettura.
Quando ClusterControl promuove uno slave a master, HAProxy contrassegna il vecchio master come offline (per entrambe le porte) e mette il nodo promosso in linea (nella porta di lettura-scrittura). In questo modo, i nostri sistemi continuano a funzionare normalmente.
Se il nostro HAProxy attivo (a cui è assegnato un indirizzo IP virtuale a cui si connettono i nostri sistemi) fallisce, Keepalived migra automaticamente questo IP al nostro HAProxy passivo. Ciò significa che i nostri sistemi sono quindi in grado di continuare a funzionare normalmente.
Conclusione
Come abbiamo potuto vedere, il failover è una parte fondamentale di qualsiasi database di produzione. Può essere utile durante l'esecuzione di attività di manutenzione o migrazioni comuni. Ci auguriamo che questo blog sia stato utile come introduzione all'argomento, in modo che tu possa continuare a ricercare e creare le tue strategie di failover.