Quali problemi prenderemo in considerazione?
Se il server notifica "non c'è più spazio sull'unità E", non è necessaria un'analisi approfondita. Non prenderemo in considerazione errori la cui soluzione è ovvia dal testo del messaggio e per i quali Google lancia immediatamente un collegamento a MSDN con la soluzione.
Esaminiamo i problemi non evidenti per Google, come ad esempio un calo improvviso delle prestazioni o l'assenza di connessione. Considera i principali strumenti di personalizzazione e analisi. Vediamo dove si trovano i log e altre informazioni utili. Cercherò infatti di raccogliere in un articolo tutte le informazioni necessarie per iniziare velocemente.
Prima di tutto
Inizieremo con le domande più frequenti e le considereremo separatamente.
Se il tuo database improvvisamente, senza una ragione apparente, ha iniziato a funzionare lentamente, ma non avevi cambiato nulla, prima di tutto aggiorna le statistiche e ricostruisci gli indici.
Su Internet ci sono molti metodi come questo, vengono forniti esempi di script. Presumo che tutti questi metodi siano per professionisti. Bene, descriverò il modo più semplice:hai solo bisogno di un mouse per implementarlo.
Abbreviazioni
- SSMS è un'applicazione di Microsoft SQL Server Management Studio. A partire dalla versione 2016, è disponibile gratuitamente sul sito web di MS come applicazione standalone. docs.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
- Profiler è un'applicazione di "SQL Server Profiler" installata con SSMS.
- Performance Monitor è uno snap-in del pannello di controllo che consente di monitorare i contatori delle prestazioni, registrare e visualizzare la cronologia delle misurazioni.
Aggiornamento delle statistiche tramite un "piano di servizio":
- esegui SSMS;
- collegarsi a un server richiesto;
- espandi l'albero in Object Inspector:Gestione\Piani di manutenzione (Piani di servizio);
- fare clic con il pulsante destro del mouse sul nodo e selezionare "Procedura guidata piano di manutenzione";
- nella procedura guidata, contrassegna le attività richieste:ricostruisci l'indice e aggiorna le statistiche
- puoi contrassegnare entrambe le attività contemporaneamente o creare due piani di manutenzione con un'attività in ciascuna (consulta le "note importanti" di seguito);
- inoltre, controlliamo un DB richiesto (o più database). Lo facciamo per ogni attività (se vengono scelte due attività, ci saranno due finestre di dialogo con la scelta di un database);
- Avanti, Avanti, Fine.
Dopo queste azioni, verrà creato un "piano di manutenzione" (non eseguito). Puoi eseguirlo manualmente facendo clic con il pulsante destro del mouse e selezionando "Esegui". In alternativa, puoi configurare l'avvio tramite SQL Agent.
Note importanti:
- L'aggiornamento delle statistiche è un'operazione non bloccante. Puoi eseguirlo in modalità di lavoro.
- La ricostruzione dell'indice è un'operazione di blocco. Puoi eseguirlo solo al di fuori dell'orario di lavoro. Esiste un'eccezione:l'edizione Enterprise del server consente l'esecuzione di una "ricostruzione in linea". Questa opzione può essere abilitata nelle impostazioni dell'attività. Tieni presente che in tutte le edizioni è presente un segno di spunta, ma funziona solo in Enterprise.
- Ovviamente, questi compiti devono essere eseguiti regolarmente. Suggerisco un modo semplice per determinare la frequenza con cui lo fai:
– Con i primi problemi, eseguire il piano di manutenzione;
– Se ha aiutato, attendere che i problemi si ripresentino (di solito fino alla chiusura mensile/calcolo salariale/ecc. di transazioni all'ingrosso successive);
– Il periodo risultante di una normale operazione sarà il tuo punto di riferimento;
– Ad esempio, configurare l'esecuzione del piano di manutenzione con una frequenza doppia.
Il server è lento:cosa dovresti fare?
Le risorse utilizzate dal server
Come qualsiasi altro programma, il server necessita di tempo del processore, dati sul disco, quantità di RAM e larghezza di banda della rete.
Task Manager ti aiuterà a valutare la mancanza di una determinata risorsa in prima approssimazione, non importa quanto possa sembrare terribile.
CPU Carica
Anche uno scolaro può verificare l'utilizzo nel Manager. Dobbiamo solo assicurarci che se il processore è caricato, allora è il processo sqlserver.exe.
Se questo è il tuo caso, devi passare all'analisi dell'attività dell'utente per capire cosa ha causato esattamente il carico (vedi sotto).
Disco Prestito d
Molte persone guardano solo al carico della CPU ma dimenticano che il DBMS è un archivio dati. I volumi di dati stanno crescendo, le prestazioni del processore stanno aumentando mentre la velocità dell'HDD è praticamente la stessa. Con gli SSD la situazione è migliore, ma archiviare terabyte su di essi è costoso.
Si scopre che spesso incontro situazioni in cui il sistema del disco diventa il collo di bottiglia, piuttosto che la CPU.
Per i dischi, le seguenti metriche sono importanti:
- lunghezza media della coda (operazioni di I/O in sospeso, numero);
- Velocità di lettura-scrittura (in Mb/s).
La versione server del Task Manager, di norma (a seconda della versione del sistema), mostra entrambi. In caso contrario, eseguire lo snap-in Performance Monitor (monitor di sistema). Siamo interessati ai seguenti contatori:
- Disco fisico (logico)/Tempo medio di lettura (scrittura)
- Disco fisico (logico)/Lunghezza media della coda del disco
- Velocità fisica (logica) del disco/del disco
Per maggiori dettagli, puoi leggere i manuali del produttore, ad esempio qui:social.technet.microsoft.com/wiki/contents/articles/3214.monitoring-disk-usage.aspx.
In breve:
- La coda non deve superare 1. Sono consentiti brevi raffiche se si attenuano rapidamente. I burst possono essere diversi a seconda del sistema. Per un semplice mirror RAID di due HDD, la coda di oltre 10-20 è un problema. Per una libreria interessante con super caching, ho visto esplosioni fino a 600-800 che sono state risolte immediatamente senza causare ritardi.
- Il tasso di cambio normale dipende anche dal tipo di sistema disco. Il solito HDD (desktop) trasmette a 50-100 MB/s. Una buona libreria di dischi – a 500 MB/s e oltre. Per piccole operazioni casuali, la velocità è inferiore. Questo potrebbe essere il tuo punto di riferimento.
- Questi parametri devono essere considerati nel loro insieme. Se la tua libreria trasmette 50 MB/s e una coda di 50 operazioni si allinea, ovviamente, qualcosa non va nell'hardware. Se la coda si allinea quando la trasmissione è vicina al massimo – molto probabilmente, i dischi non sono da biasimare – semplicemente non possono fare di più – dobbiamo cercare un modo per ridurre il carico.
- Il carico dovrebbe essere controllato separatamente sui dischi (se ce ne sono diversi) e confrontato con la posizione dei file del server. Il Task Manager può mostrare i file utilizzati più attivamente. Questo può essere utilizzato per garantire che il carico sia causato da DBMS.
Cosa può causare i problemi di sistema del disco:
- problemi con l'hardware
- cache esaurita, prestazioni drasticamente diminuite;
- il sistema del disco è usato da qualcos'altro;
- Carenza di RAM. Scambio. Il caricamento è diminuito, le prestazioni sono diminuite (vedi la sezione sulla RAM di seguito).
- Carico utente aumentato. È necessario valutare il lavoro degli utenti (interrogazione problematica/nuove funzionalità/aumento del numero di utenti/aumento della quantità di dati/ecc).
- Frammentazione dei dati del database (vedi ricostruzione dell'indice sopra), frammentazione dei file di sistema.
- Il sistema del disco ha raggiunto le sue massime capacità.
Nel caso dell'ultima opzione, non buttare via l'hardware in una volta. A volte, puoi ottenere un po' di più dal sistema se affronti il problema con saggezza. Verificare la posizione dei file di sistema per la conformità ai requisiti consigliati:
- Non mischiare i file del sistema operativo con i file di dati del database. Archiviali su supporti fisici diversi in modo che il sistema non competa con DBMS per l'I/O.
- Il database è costituito da due tipi di file:dati (*.mdf, *.ndf) e log (*.ldf).
I file di dati, di norma, vengono utilizzati principalmente per la lettura. I registri servono per la scrittura (in cui la scrittura è consecutiva). Si consiglia, quindi, di memorizzare log e dati su diversi supporti fisici in modo che il logging non interrompa la lettura dei dati (di norma, l'operazione di scrittura ha la precedenza sulla lettura). - MS SQL può utilizzare "tabelle temporanee" per l'elaborazione delle query. Sono archiviati nel database di sistema tempdb. Se hai un carico elevato sui file di questo database, puoi provare a renderizzarlo su un supporto fisicamente separato.
Riassumendo il problema con la posizione dei file, usa il principio del "divide et impera". Valuta a quali file si accede e prova a distribuirli su diversi media. Inoltre, utilizzare le funzionalità dei sistemi RAID. Ad esempio, le letture RAID-5 sono più veloci delle scritture, il che è positivo per i file di dati.
Esaminiamo come recuperare informazioni sulle prestazioni degli utenti:chi produce cosa e quante risorse vengono consumate
Ho diviso le attività di controllo delle attività degli utenti nei seguenti gruppi:
- Compiti di analisi di una richiesta particolare.
- Attività di analisi del carico dell'applicazione in condizioni specifiche (ad esempio, quando un utente fa clic su un pulsante in un'applicazione di terze parti compatibile con il database).
- Compiti di analisi della situazione attuale.
Consideriamo ciascuno di essi in dettaglio.
Avviso
L'analisi delle prestazioni richiede una profonda comprensione della struttura e dei principi di funzionamento del server di database e del sistema operativo. Ecco perché leggere solo questi articoli non farà di te un professionista.
I criteri e i contatori considerati nei sistemi reali dipendono notevolmente l'uno dall'altro. Ad esempio, un carico elevato dell'HDD è spesso causato dalla mancanza di RAM. Anche se si effettuano alcune misurazioni, ciò non è sufficiente per valutare ragionevolmente i problemi.
Lo scopo degli articoli è di introdurre gli elementi essenziali su semplici esempi. Non dovresti considerare i miei consigli come una guida. Ti consiglio di usarli come attività di formazione che possono spiegare il flusso dei pensieri.
Spero che imparerai come razionalizzare le tue conclusioni sulle prestazioni del server in cifre.
Invece di dire "il server rallenta", fornirai valori specifici di indicatori specifici.
Analizza una P articolare R richiesta
Il primo punto è abbastanza semplice, soffermiamoci brevemente. Prenderemo in considerazione alcune questioni meno ovvie.
Oltre ai risultati della query, SSMS consente di recuperare informazioni aggiuntive sull'esecuzione della query:
- Puoi ottenere il piano di query facendo clic sui pulsanti "Visualizza piano di esecuzione stimato" e "Includi piano di esecuzione effettivo". La differenza tra loro è che il piano di stima viene creato senza l'esecuzione di una query. Pertanto, verranno stimate le informazioni sul numero di righe elaborate. Nel piano effettivo, ci saranno sia i dati stimati che quelli effettivi. Forti discrepanze di questi valori indicano che le statistiche non sono rilevanti. Tuttavia, l'analisi del piano è oggetto di un altro articolo:finora non andremo più in profondità.
- Possiamo ottenere misurazioni dei costi del processore e delle operazioni del disco del server. Per fare ciò, è necessario abilitare l'opzione SET. Puoi farlo nella finestra di dialogo "Opzioni query" in questo modo:
Oppure con i comandi SET diretti nella query:
SET STATISTICS IO ON
SET STATISTICS TIME ON
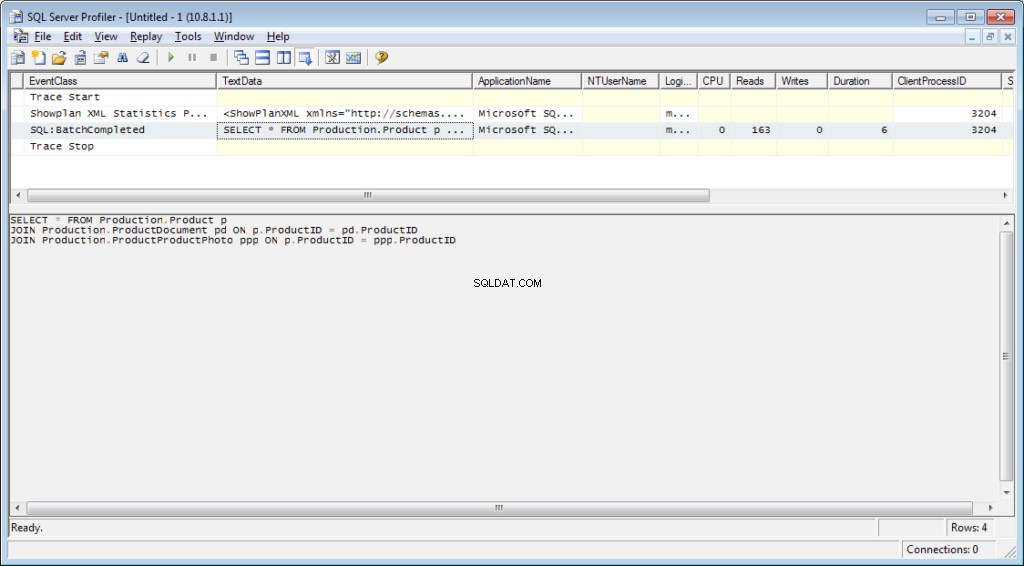
SELECT * FROM Production.Product p
JOIN Production.ProductDocument pd ON p.ProductID = pd.ProductID
JOIN Production.ProductProductPhoto ppp ON p.ProductID = ppp.ProductIDDi conseguenza, otterremo dati sul tempo impiegato per la compilazione e l'esecuzione, nonché il numero di operazioni su disco.
Time of SQL Server parsing and compilation:
CPU time = 16 ms, elapsed time = 89 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
(32 row(s) affected)
The «ProductProductPhoto» table. The number of views is 32, logic reads – 96, physical reads 5, read-ahead reads 0, lob of logical reads 0, lob of physical reads 0, lob of read-ahead reads 0.
The ‘Product’ table. The number of views is 0, logic reads – 64, physical reads – 0, read-ahead reads – 0, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
The «ProductDocument» table. The number of views is 1, logical reads – 3, physical reads – 1, read-ahead reads -, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
Time of SQL activity:
CPU time = 15 ms, spent time = 35 ms.Vorrei attirare la vostra attenzione sul tempo di compilazione, sulle letture logiche 96 e sulle letture fisiche 5. Quando si esegue la stessa query per la seconda volta e in seguito, le letture fisiche potrebbero diminuire e la ricompilazione potrebbe non essere necessaria. Per questo motivo, capita spesso che la query venga eseguita più velocemente durante la seconda volta e quelle successive rispetto alla prima volta. Il motivo, come capisci, sta nella memorizzazione nella cache dei dati e nei piani di query compilati.
- Il pulsante «Includi statistiche client» mostra le informazioni sullo scambio di rete, la quantità di operazioni eseguite e il tempo totale di esecuzione, inclusi i costi sullo scambio di rete e l'elaborazione da parte di un cliente. L'esempio mostra che è necessario più tempo per eseguire la query per la prima volta:
- In SSMS 2016, è presente il pulsante «Includi statistiche sulle query in tempo reale». Visualizza l'immagine come nel caso del piano di query ma contiene le cifre non casuali delle righe elaborate, che cambiano sullo schermo durante l'esecuzione della query. L'immagine è molto chiara:frecce lampeggianti e numeri in esecuzione, puoi vedere immediatamente dove viene perso il tempo. Il pulsante funziona anche con SQL Server 2014 e versioni successive.
Per riassumere:
- Controlla i costi della CPU usando SET STATISTICS TIME ON.
- Operazioni su disco:SET STATISTICS IO ON. Non dimenticare che la lettura logica è un'operazione di lettura completata nella cache del disco senza accedere fisicamente al sistema del disco. La "lettura fisica" richiede molto più tempo.
- Valuta il volume del traffico di rete utilizzando «Includi statistiche client».
- Analizza l'algoritmo di esecuzione della query in base al piano di esecuzione utilizzando «Include Actual Execution Plan» e «Include Live Query Statistics».
Analizza il carico dell'applicazione
Qui useremo SQL Server Profiler. Dopo l'avvio e la connessione al server, è necessario selezionare gli eventi di registro. A tale scopo, eseguire la profilatura con un modello di traccia standard. Sul Generale scheda nella scheda Utilizza il modello campo, seleziona Standard (predefinito) e fai clic su Esegui .
Il modo più complicato consiste nell'aggiungere/eliminare filtri o eventi nel/dal modello selezionato. Queste opzioni possono essere trovate nella seconda scheda del menu di dialogo. Per visualizzare l'intera gamma di possibili eventi e colonne da selezionare, seleziona Mostra tutti gli eventi e Mostra tutte le colonne caselle di controllo.

Avremo bisogno dei seguenti eventi:
- Procedure memorizzate \ RPC:Completato
- TSQL\SQL:BatchCompleted
Questi eventi monitorano tutte le chiamate SQL esterne al server. Appaiono dopo il completamento dell'elaborazione della query. Esistono eventi simili che tengono traccia dell'avvio di SQL Server:
- Procedure memorizzate \ RPC:avvio
- TSQL \ SQL:BatchStarting
Tuttavia, non abbiamo bisogno di queste procedure in quanto non contengono informazioni sulle risorse del server utilizzate per l'esecuzione della query. È ovvio che tali informazioni sono disponibili solo dopo il completamento del processo di esecuzione. Pertanto, le colonne con dati su CPU, letture, scritture negli *Eventi iniziali saranno vuote.
Anche i seguenti eventi potrebbero interessarci, tuttavia, finora non li abiliteremo:
- Stored Procedures \ SP:Starting (*Completed) monitora la chiamata interna alla stored procedure non dal client, ma all'interno della richiesta corrente o di un'altra procedura.
- Stored procedure \ SP:StmtStarting (*Completed) tiene traccia dell'inizio di ogni istruzione all'interno della stored procedure. Se è presente un ciclo nella procedura, il numero di eventi per i comandi nel ciclo sarà uguale al numero di iterazioni nel ciclo.
- TSQL \ SQL:StmtStarting (*Completed) controlla l'inizio di ogni istruzione all'interno del batch SQL. Se nella tua query sono presenti più comandi, ognuno di essi conterrà un evento. Pertanto, funziona per i comandi che si trovano nella query.
Questi eventi sono utili per monitorare il processo di esecuzione.
Di C colonne
Le colonne da selezionare sono chiare dal nome del pulsante. Avremo bisogno dei seguenti:
- TextData, BinaryData contengono il testo della query.
- CPU, Letture, Scritture e Durata visualizzano i dati sul consumo delle risorse.
- StartTime, EndTime è il momento di iniziare e terminare il processo di esecuzione. Sono convenienti per l'ordinamento.
Aggiungi altre colonne in base alle tue preferenze.
I filtri delle colonne... apre la finestra di dialogo per la configurazione dei filtri degli eventi. Se sei interessato all'attività di un determinato utente, puoi impostare il filtro in base al numero SID o al nome utente. Sfortunatamente, nel caso di connessione dell'app tramite l'app-server con il pull delle connessioni, il monitoraggio del particolare utente diventa più complicato.
Puoi utilizzare i filtri per la selezione di query solo complicate (Durata>X), query che causano una scrittura intensiva (Scritture>Y), nonché per la selezione del contenuto delle query, ecc.
Cos'altro ci serve dal profiler? Naturalmente, il piano di esecuzione!
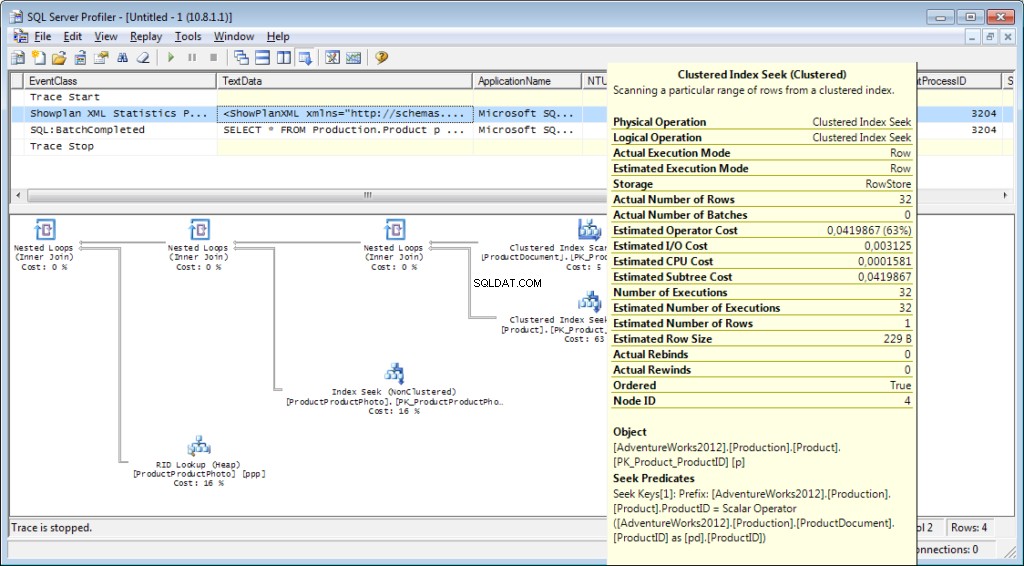
È necessario aggiungere al tracciamento l'evento «Performance \ Showplan XML Statistics Profile». Durante l'esecuzione della nostra query, otterremo la seguente immagine:
Il testo della query:
Il piano di esecuzione:
E non è tutto
È possibile salvare una traccia in un file o in una tabella di database. Le impostazioni di tracciamento possono essere archiviate come modello personale per una rapida esecuzione. È possibile eseguire la traccia senza un profiler, utilizzando semplicemente un codice T-SQL e le procedure sp_trace_create, sp_trace_setevent, sp_trace_setstatus, sp_trace_getdata. Puoi trovare un esempio qui. Questo approccio può essere utile, ad esempio, per avviare automaticamente l'archiviazione di una traccia in un file in base a una pianificazione. Puoi dare un'occhiata furtiva al profiler per vedere come usare questi comandi. Puoi eseguire due tracce e in una di esse tenere traccia di cosa succede quando inizia la seconda. Verifica che non ci siano filtri in base alla colonna "ApplicationName" sul profiler stesso.
L'elenco degli eventi monitorati dal profiler è molto ampio e non si limita alla ricezione di testi di query. Esistono eventi che tengono traccia di scansione completa, ricompilazione, aumento automatico, deadlock e molto altro.
Analisi dell'attività dell'utente sul server
Ci sono diverse situazioni. Una query può rimanere in sospeso per molto tempo e non è chiaro se verrà completata o meno. Vorrei analizzare separatamente la query problematica; tuttavia, dobbiamo prima determinare qual è la query. È inutile prenderlo con un profiler:abbiamo già perso l'evento di partenza e non è chiaro per quanto tempo attendere il completamento del processo.
Scopriamolo
Potresti aver sentito parlare di "Monitoraggio attività". Le sue edizioni superiori hanno funzionalità davvero ricche. Come può aiutarci? Activity Monitor include molte funzioni utili e interessanti. Otterremo tutto ciò di cui abbiamo bisogno dalle viste e dalle funzioni di sistema. Monitor stesso è utile perché puoi impostare il profiler su di esso e vedere quali query esegue.
Avremo bisogno di:
- dm_exec_sessions fornisce informazioni sulle sessioni degli utenti connessi. All'interno del nostro articolo, i campi utili sono quelli che identificano un utente (login_name, login_time, host_name, program_name, …) e i campi con le informazioni sulle risorse spese (cpu_time, reads, writes, memory_usage, …)
- dm_exec_requests fornisce informazioni sulle query eseguite al momento.
- id_sessione è un identificatore della sessione da collegare alla vista precedente.
- start_time è l'ora di esecuzione della vista.
- comando è un campo che contiene un tipo di comando eseguito. Per le query degli utenti, seleziona/aggiorna/elimina/
- sql_handle, statement_start_offset, statement_end_offset forniscono informazioni per recuperare il testo della query:handle, nonché la posizione iniziale e finale nel testo della query, il che significa la parte che è attualmente in esecuzione (nel caso in cui la query contenga diversi comandi).
- plan_handle è un handle del piano generato.
- blocking_session_id indica il numero della sessione che ha causato il blocco se sono presenti blocchi che impediscono l'esecuzione della query
- wait_type, wait_time, wait_resource sono campi con le informazioni sul motivo e sulla durata dell'attesa. Per alcune tipologie di attese, ad esempio data lock, è necessario indicare in aggiunta un codice per la risorsa bloccata.
- percent_complete è la percentuale di completamento. Sfortunatamente, è disponibile solo per i comandi con un andamento chiaramente prevedibile (ad esempio backup o ripristino).
- cpu_time, letture, scritture, logical_reads, grant_query_memory sono costi per le risorse.
- dm_exec_sql_text(sql_handle | plan_handle), sys.dm_exec_query_plan(plan_handle) sono funzioni per ottenere il testo e il piano di esecuzione. Di seguito, considereremo un esempio del suo utilizzo.
- dm_exec_query_stats è una statistica riepilogativa dell'esecuzione delle query. Visualizza la query, il numero delle sue esecuzioni e il volume delle risorse spese.
Note importanti
L'elenco sopra è solo una piccola parte. Un elenco completo di tutte le viste e le funzioni del sistema è descritto nella documentazione. Inoltre, c'è una bella immagine che mostra un diagramma dei collegamenti tra gli oggetti principali.
Il testo della query, il relativo piano e le statistiche di esecuzione sono dati archiviati nella cache delle procedure. Sono disponibili durante l'esecuzione. Quindi, la disponibilità non è garantita e dipende dal carico della cache. Sì, la cache può essere pulita manualmente. A volte, è consigliato quando i piani di esecuzione sono "scoperti". Tuttavia, ci sono molte sfumature.
Il campo "comando" non ha senso per le richieste degli utenti, poiché possiamo ottenere il testo completo. Tuttavia, è molto importante per ottenere informazioni sui processi di sistema. Di norma, svolgono alcune attività interne e non hanno il testo SQL. Per tali processi, le informazioni sul comando sono l'unico suggerimento sul tipo di attività.
Nei commenti all'articolo precedente, c'era una domanda su cosa è coinvolto il server quando non dovrebbe funzionare. La risposta sarà probabilmente nel significato di questo campo. Nella mia pratica, il campo "comando" forniva sempre qualcosa di abbastanza comprensibile per i processi di sistema attivi:autoshrink / autogrow / checkpoint / logwriter / ecc.
Come usarlo
Passiamo alla parte pratica. Fornirò diversi esempi del suo utilizzo. Le possibilità del server non sono limitate:puoi pensare ai tuoi esempi.
Esempio 1. Quale processo consuma CPU/legge/scrive/memoria
Innanzitutto, dai un'occhiata alle sessioni che consumano più risorse, ad esempio CPU. Puoi trovare queste informazioni in sys.dm_exec_sessions. Tuttavia, i dati sulla CPU, incluse letture e scritture, sono cumulativi. Significa che il numero contiene il totale per tutto il tempo della connessione. È chiaro che l'utente che si è connesso un mese fa e non è stato disconnesso avrà un valore maggiore. Ciò non significa che sovraccaricano il sistema.
Un codice con il seguente algoritmo può risolvere questo problema:
- Fai una selezione e salvala in una tabella temporanea
- Aspetta un po' di tempo
- Effettua una selezione per la seconda volta
- Confronta questi risultati. La loro differenza indicherà i costi spesi al passaggio 2.
- Per comodità, la differenza può essere divisa per la durata del passaggio 2 in modo da ottenere i “costi al secondo” medi.
if object_id('tempdb..#tmp') is NULL
BEGIN
SELECT * into #tmp from sys.dm_exec_sessions s
PRINT 'wait for a second to collect statistics at the first run '
-- we do not wait for the next launches, because we compare with the result of the previous launch
WAITFOR DELAY '00:00:01';
END
if object_id('tempdb..#tmp1') is not null drop table #tmp1
declare @d datetime
declare @dd float
select @d = crdate from tempdb.dbo.sysobjects where id=object_id('tempdb..#tmp')
select * into #tmp1 from sys.dm_exec_sessions s
select @dd=datediff(ms,@d,getdate())
select @dd AS [time interval, ms]
SELECT TOP 30 s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, convert(numeric(16,2),(s.cpu_time-isnull(t.cpu_time,0))/@dd*1000) as cpu_sec,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, convert(numeric(16,2),(s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0))/@dd*1000) as totIO_sec,
s.reads-isnull(t.reads,0) as reads_Diff, convert(numeric(16,2),(s.reads-isnull(t.reads,0))/@dd*1000) as reads_sec,
s.writes-isnull(t.writes,0) as writes_Diff, convert(numeric(16,2),(s.writes-isnull(t.writes,0))/@dd*1000) as writes_sec,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, convert(numeric(16,2),(s.logical_reads-isnull(t.logical_reads,0))/@dd*1000) as logical_reads_sec,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_D],
s.nt_user_name,s.nt_domain
from #tmp1 s
LEFT join #tmp t on s.session_id=t.session_id
order BY
cpu_Diff desc
--totIO_Diff desc
--logical_reads_Diff desc
drop table #tmp
GO
select * into #tmp from #tmp1
drop table #tmp1 Uso due tabelle nel codice:#tmp – per la prima selezione, e #tmp1 – per la seconda. Durante la prima esecuzione, lo script crea e riempie #tmp e #tmp1 a intervalli di un secondo, quindi esegue altre attività. Con le esecuzioni successive, lo script utilizza i risultati dell'esecuzione precedente come base per il confronto. Pertanto, la durata del passaggio 2 sarà uguale alla durata dell'attesa tra le esecuzioni dello script.
Prova a eseguirlo, anche sul server di produzione. Lo script creerà solo "tabelle temporanee" (disponibili nella sessione corrente ed eliminate quando disabilitato) e non ha thread.
Coloro a cui non piace eseguire una query in MS SSMS possono racchiuderla in un'applicazione scritta nel loro linguaggio di programmazione preferito. Ti mostrerò come farlo in MS Excel senza una singola riga di codice.
Nel menu Dati, connettiti al server. Se ti viene chiesto di selezionare una tabella, selezionane una a caso. Fare clic su Avanti e Fine finché non viene visualizzata la finestra di dialogo Importazione dati. In quella finestra, devi fare clic su Proprietà. In Proprietà, è necessario sostituire un tipo di comando con il valore SQL e inserire la nostra query modificata nel campo Testo del comando.
Dovrai modificare un po' la query:
- Aggiungi «SET NOCOUNT ON»
- Sostituisci le tabelle temporanee con le tabelle variabili
- Il ritardo durerà entro 1 sec. I campi con valori medi non sono obbligatori
La query modificata per Excel
SET NOCOUNT ON;
declare @tmp table(session_id smallint primary key,login_time datetime,host_name nvarchar(256),program_name nvarchar(256),login_name nvarchar(256),nt_user_name nvarchar(256),cpu_time int,memory_usage int,reads bigint,writes bigint,logical_reads bigint,database_id smallint)
declare @d datetime;
select @d=GETDATE()
INSERT INTO @tmp(session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id)
SELECT session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id
from sys.dm_exec_sessions s;
WAITFOR DELAY '00:00:01';
declare @dd float;
select @dd=datediff(ms,@d,getdate());
SELECT
s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff,
s.reads-isnull(t.reads,0) as reads_Diff,
s.writes-isnull(t.writes,0) as writes_Diff,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_Diff],
s.nt_user_name,s.nt_domain
from sys.dm_exec_sessions s
left join @tmp t on s.session_id=t.session_id Risultato:
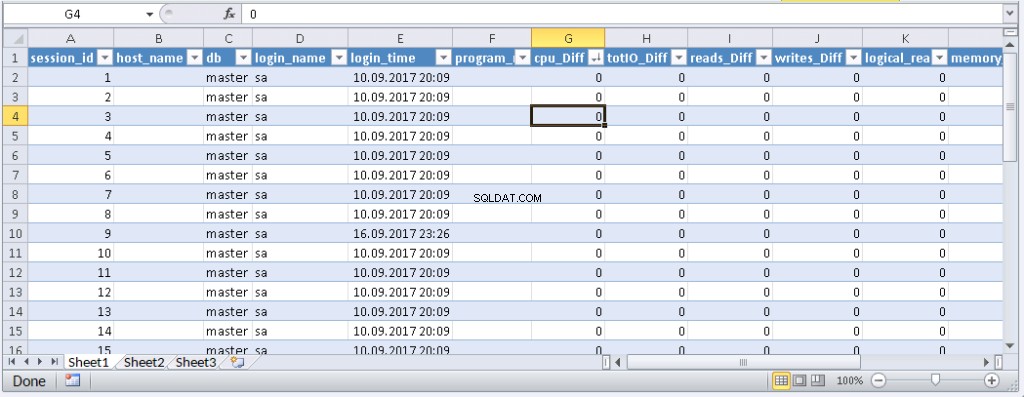
Quando i dati vengono visualizzati in Excel, puoi ordinarli in base alle tue esigenze. Per aggiornare le informazioni, fare clic su "Aggiorna". Nelle impostazioni della cartella di lavoro, puoi inserire "aggiornamento automatico" in un periodo di tempo specificato e "aggiornamento all'inizio". Puoi salvare il file e passarlo ai tuoi colleghi. Pertanto, abbiamo creato uno strumento comodo e semplice.
Esempio 2. Per cosa una sessione spende risorse?
Ora, determineremo cosa fanno effettivamente le sessioni problematiche. A tale scopo, utilizza sys.dm_exec_requests e le funzioni per ricevere il testo della query e il piano della query.
La query e il piano di esecuzione in base al numero di sessione
DECLARE @sql_handle varbinary(64) DECLARE @plan_handle varbinary(64) DECLARE @sid INT Declare @statement_start_offset int, @statement_end_offset INT, @session_id SMALLINT -- for the information by a particular user – indicate a session number SELECT @sid=182 -- receive state variables for further processing IF @sid IS NOT NULL SELECT @sql_handle=der.sql_handle, @plan_handle=der.plan_handle, @statement_start_offset=der.statement_start_offset, @statement_end_offset=der.statement_end_offset, @session_id = der.session_id FROM sys.dm_exec_requests der WHERE example@sqldat.com -- print the text of the query being executed DECLARE @txt VARCHAR(max) IF @sql_handle IS NOT NULL SELECT @txt=[text] FROM sys.dm_exec_sql_text(@sql_handle) PRINT @txt -- output the plan of the batch/procedure being executed IF @plan_handle IS NOT NULL select * from sys.dm_exec_query_plan(@plan_handle) -- and the plan of the query being executed within the batch/procedure IF @plan_handle IS NOT NULL SELECT dbid, objectid, number, encrypted, CAST(query_plan AS XML) AS planxml from sys.dm_exec_text_query_plan(@plan_handle, @statement_start_offset, @statement_end_offset)
Inserisci il numero di sessione nella query ed eseguilo. After execution, there will be plans on the Results tab (the first one is for the whole query, and the second one is for the current step if there are several steps in the query) and the query text on the Messages tab. To view the plan, you need to click the text that looks like the URL in the row. The plan will be opened in a separate tab. Sometimes, it happens that the plan is opened not in a graphical form, but in the form of XML-text. This may happen because the MS SSMS version is lower than the server. Delete the “Version” and “Build” from the first row and then save the result XML to a file with the .sqlplan extension. After that, open it separately. If this does not help, I remind you that the 2016 studio is officially available for free on the MS website.
It is obvious that the result plan will be an estimated one, as the query is being executed. Still, it is possible to receive some execution statistics. To do this, use the sys.dm_exec_query_stats view with the filter by our handles.
Add this information at the end of the previous query
-- plan statistics IF @sql_handle IS NOT NULL SELECT * FROM sys.dm_exec_query_stats QS WHERE example@sqldat.com_handle
As a result, we will get the information about the steps of the executed query:how many times they were executed and what resources were spent. This information is added to the statistics only after the execution process is completed. The statistics are not tied to the user but are maintained within the whole server. If different users execute the same query, the statistics will be total for all users.
Example 3. Can I see all of them?
Let’s combine the system views we considered with the functions in one query. It can be useful for evaluating the whole situation.
-- receive a list of all current queries SELECT LEFT((SELECT [text] FROM sys.dm_exec_sql_text(der.sql_handle)),500) AS txt --,(select top 1 1 from sys.dm_exec_query_profiles where session_id=der.session_id) as HasLiveStat ,der.blocking_session_id as blocker, DB_NAME(der.database_id) AS База, s.login_name, * from sys.dm_exec_requests der left join sys.dm_exec_sessions s ON s.session_id = der.session_id WHERE der.session_id<>@@SPID -- AND der.session_id>50
The query outputs a list of active sessions and texts of their queries. For system processes, usually, there is no query; however, the command field is filled up. You can see the information about blocks and waits, and mix this query with example 1 in order to sort by the load. Still, be careful, query texts may be large. Their massive selection can be resource-intensive and lead to a huge traffic increase. In the example, I limited the result query to the first 500 characters but did not execute the plan.
Conclusione
It would be great to get Live Query Statistics for an arbitrary session. According to the manufacturer, now, monitoring statistics requires many resources and therefore, it is disabled by default. Its enabling is not a problem, but additional manipulations complicate the process and reduce the practical benefit.
In this article, we analyzed user activity in the following ways:using possibilities MS SSMS, profiler, direct calls to system views. All these methods allow estimating costs on executing a query and getting the execution plan. Each method is suitable for a particular situation. Thus, the best solution is to combine them.