Nel 2014, ho scritto un articolo intitolato Performance Tuning the Whole Query Plan. Ha esaminato i modi per trovare un numero relativamente piccolo di valori distinti da un set di dati moderatamente grande e ha concluso che una soluzione ricorsiva potrebbe essere ottimale. Questo post di follow-up rivisita la domanda per SQL Server 2019, utilizzando un numero maggiore di righe.
Ambiente di prova
Utilizzerò il database Stack Overflow 2013 da 50 GB, ma qualsiasi tabella di grandi dimensioni con un numero basso di valori distinti andrebbe bene.
Cercherò valori distinti nel BountyAmount colonna di dbo.Votes tabella, presentata in ordine crescente di importo del premio. La tabella dei voti ha poco meno di 53 milioni di righe (52.928.720 per l'esattezza). Ci sono solo 19 diversi importi di taglie, incluso NULL .
Il database Stack Overflow 2013 viene fornito senza indici non cluster per ridurre al minimo il tempo di download. C'è un indice di chiave primaria in cluster su Id colonna di dbo.Votes tavolo. Viene impostato sulla compatibilità con SQL Server 2008 (livello 100), ma inizieremo con un'impostazione più moderna di SQL Server 2017 (livello 140):
ALTER DATABASE StackOverflow2013
SET COMPATIBILITY_LEVEL = 140;
I test sono stati eseguiti sul mio laptop utilizzando SQL Server 2019 CU 2. Questa macchina ha quattro CPU i7 (con hyperthreading a 8) con una velocità base di 2,4 GHz. Ha 32 GB di RAM, con 24 GB disponibili per l'istanza di SQL Server 2019. La soglia di costo per il parallelismo è impostata su 50.
Ogni risultato del test rappresenta il meglio delle dieci esecuzioni, con tutti i dati richiesti e le pagine di indice in memoria.
1. Indice raggruppato archivio righe
Per impostare una linea di base, la prima esecuzione è una query seriale senza alcuna nuova indicizzazione (e ricorda che questo è con il database impostato sul livello di compatibilità 140):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (MAXDOP 1);
Questo esegue la scansione dell'indice cluster e utilizza un aggregato hash in modalità riga per trovare i valori distinti di BountyAmount :
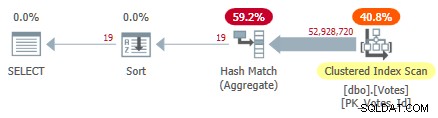 Piano di indici cluster seriali
Piano di indici cluster seriali
Questo richiede 10.500 ms per completare, utilizzando la stessa quantità di tempo della CPU. Ricorda che questo è il momento migliore su dieci esecuzioni con tutti i dati in memoria. Statistiche campionate create automaticamente su BountyAmount colonne sono state create alla prima esecuzione.
Circa la metà del tempo trascorso viene speso per la scansione dell'indice cluster e circa la metà per l'Hash Match Aggregate. L'ordinamento ha solo 19 righe da elaborare, quindi consuma solo 1 ms circa. Tutti gli operatori in questo piano utilizzano l'esecuzione in modalità riga.
Rimozione del MAXDOP 1 suggerimento fornisce un piano parallelo:
 Piano di indici a cluster parallelo
Piano di indici a cluster parallelo
Questo è il piano scelto dall'ottimizzatore senza alcun suggerimento nella mia configurazione. Restituisce risultati in 4.200 ms utilizzando un totale di 32.800 ms di CPU (a DOP 8).
2. Indice non cluster
Scansione dell'intera tabella per trovare solo il BountyAmount sembra inefficiente, quindi è naturale provare ad aggiungere un indice non cluster solo su una colonna di cui questa query ha bisogno:
CREATE NONCLUSTERED INDEX b ON dbo.Votes (BountyAmount);
La creazione di questo indice richiede un po' di tempo (1m 40s). Il MAXDOP 1 la query ora utilizza un aggregato di flusso perché l'ottimizzatore può utilizzare l'indice non cluster per presentare le righe in BountyAmount ordine:
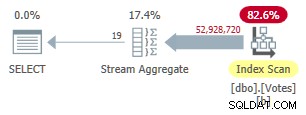 Piano modalità riga non cluster seriale
Piano modalità riga non cluster seriale
Questo viene eseguito per 9.300 ms (consumando la stessa quantità di tempo della CPU). Un utile miglioramento rispetto ai 10.500 ms originali ma difficilmente sconvolgente.
Rimozione del MAXDOP 1 hint fornisce un piano parallelo con l'aggregazione locale (per thread):
 Piano modalità riga parallela non cluster
Piano modalità riga parallela non cluster
Questo viene eseguito in 3.400 ms utilizzando 25.800 ms di tempo della CPU. Potremmo essere in grado di migliorare con la compressione di righe o pagine sul nuovo indice, ma voglio passare a opzioni più interessanti.
3. Modalità batch su Row Store (BMOR)
Ora imposta il database sulla modalità di compatibilità di SQL Server 2019 utilizzando:
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 150;
Ciò offre all'ottimizzatore la libertà di scegliere la modalità batch nell'archivio riga se lo ritiene utile. Ciò può fornire alcuni dei vantaggi dell'esecuzione in modalità batch senza richiedere un indice dell'archivio colonne. Per dettagli tecnici approfonditi e opzioni non documentate, vedere l'eccellente articolo di Dmitry Pilugin sull'argomento.
Sfortunatamente, l'ottimizzatore sceglie ancora l'esecuzione in modalità riga completa utilizzando gli aggregati di flusso per le query di test sia seriali che parallele. Per ottenere una modalità batch sul piano di esecuzione dell'archivio riga, possiamo aggiungere un suggerimento per incoraggiare l'aggregazione utilizzando la corrispondenza hash (che può essere eseguita in modalità batch):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (HASH GROUP, MAXDOP 1); Questo ci fornisce un piano con tutti gli operatori in esecuzione in modalità batch:
 Modalità batch seriale su Row Store Plan
Modalità batch seriale su Row Store Plan
I risultati vengono restituiti in 2.600 ms (tutte le CPU come al solito). Questo è già più veloce del parallelo piano in modalità riga (3.400 ms trascorsi) utilizzando molta meno CPU (2.600 ms contro 25.800 ms).
Rimozione del MAXDOP 1 suggerimento (ma mantenendo HASH GROUP ) fornisce una modalità batch parallela sul piano del negozio di riga:
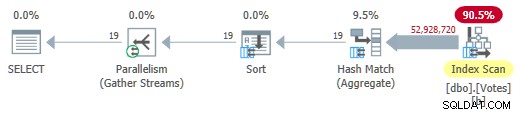 Modalità batch parallela su piano di archiviazione riga
Modalità batch parallela su piano di archiviazione riga
Questo viene eseguito in soli 725 ms utilizzando 5.700 ms di CPU.
4. Modalità batch su Column Store
La modalità batch parallela sul risultato dell'archivio riga è un miglioramento impressionante. Possiamo fare ancora meglio fornendo una rappresentazione di archivio di colonne dei dati. Per mantenere tutto il resto uguale, aggiungerò un non cluster indice archivio colonne solo sulla colonna di cui abbiamo bisogno:
CREATE NONCLUSTERED COLUMNSTORE INDEX nb ON dbo.Votes (BountyAmount);
Questo viene popolato dall'indice non cluster b-tree esistente e richiede solo 15 secondi per essere creato.
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY V.BountyAmount
OPTION (MAXDOP 1); L'ottimizzatore sceglie un piano in modalità completamente batch che include una scansione dell'indice dell'archivio colonne:
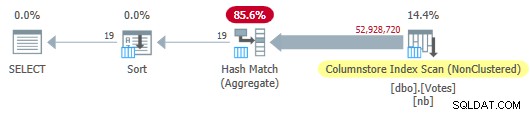 Piano di archiviazione delle colonne seriali
Piano di archiviazione delle colonne seriali
Questo viene eseguito in 115 ms utilizzando la stessa quantità di tempo della CPU. L'ottimizzatore sceglie questo piano senza alcun suggerimento sulla configurazione del mio sistema perché il costo stimato del piano è inferiore alla soglia di costo per il parallelismo .
Per ottenere un piano parallelo, possiamo ridurre la soglia di costo o utilizzare un suggerimento non documentato:
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (USE HINT ('ENABLE_PARALLEL_PLAN_PREFERENCE')); In ogni caso, il piano parallelo è:
 Piano di archiviazione a colonne parallele
Piano di archiviazione a colonne parallele
Il tempo trascorso della query ora è sceso a 30 ms , consumando 210 ms di CPU.
5. Modalità batch su Column Store con Push Down
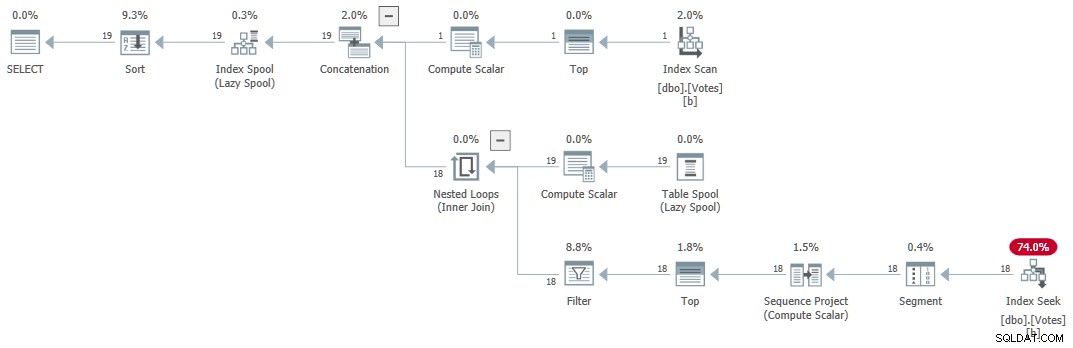
L'attuale miglior tempo di esecuzione di 30 ms è impressionante, soprattutto se confrontato con i 10.500 ms originali. Tuttavia, è un po' un peccato dover passare quasi 53 milioni di righe (in 58.868 batch) dalla scansione all'Hash Match Aggregate.
Sarebbe bello se SQL Server potesse spingere l'aggregazione verso il basso nella scansione e restituire semplicemente valori distinti dall'archivio colonne direttamente. Potresti pensare che dobbiamo esprimere il DISTINCT come GROUP BY per ottenere Grouped Aggregate Pushdown, ma questo è logicamente ridondante e in ogni caso non l'intera storia.
Con l'attuale implementazione di SQL Server, abbiamo effettivamente bisogno di calcolare un aggregato per attivare il pushdown aggregato. Inoltre, dobbiamo usare il risultato aggregato in qualche modo, o l'ottimizzatore lo rimuoverà semplicemente come non necessario.
Un modo per scrivere la query per ottenere il pushdown aggregato consiste nell'aggiungere un requisito di ordinamento secondario logicamente ridondante:
SELECT
V.BountyAmount
FROM dbo.Votes AS V
GROUP BY
V.BountyAmount
ORDER BY
V.BountyAmount,
COUNT_BIG(*) -- New!
OPTION (MAXDOP 1); Il piano seriale è ora:
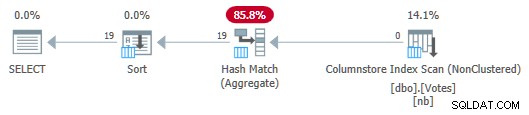 Piano di archiviazione per colonne seriali con push down aggregato
Piano di archiviazione per colonne seriali con push down aggregato
Si noti che nessuna riga viene passata dalla scansione all'aggregato! Sotto le coperte, aggregati parziali del BountyAmount i valori e i conteggi delle righe associati vengono passati all'Hash Match Aggregate, che somma gli aggregati parziali per formare l'aggregato finale (globale) richiesto. Questo è molto efficiente, come confermato dal tempo trascorso di 13 ms (tutto ciò è tempo di CPU). Ricordiamo che il precedente piano seriale richiedeva 115 ms.
Per completare il set, possiamo ottenere una versione parallela nello stesso modo di prima:
 Piano di archiviazione a colonne parallele con push down aggregato
Piano di archiviazione a colonne parallele con push down aggregato
Questo viene eseguito per 7 ms utilizzando 40 ms di CPU in totale.
È un peccato che abbiamo bisogno di calcolare e utilizzare un aggregato di cui non abbiamo bisogno solo per essere spinti verso il basso. Forse questo sarà migliorato in futuro in modo che DISTINCT e GROUP BY senza aggregati possono essere spinti fino alla scansione.
6. Espressione di tabella comune ricorsiva in modalità riga
All'inizio, ho promesso di rivisitare la soluzione CTE ricorsiva utilizzata per trovare un piccolo numero di duplicati in un grande set di dati. Implementare l'attuale requisito utilizzando quella tecnica è abbastanza semplice, anche se il codice è necessariamente più lungo di qualsiasi cosa abbiamo visto fino a questo punto:
WITH R AS
(
-- Anchor
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH FIRST 1 ROW ONLY
UNION ALL
-- Recursive
SELECT
Q1.BountyAmount
FROM
(
SELECT
V.BountyAmount,
rn = ROW_NUMBER() OVER (
ORDER BY V.BountyAmount ASC)
FROM R
JOIN dbo.Votes AS V
ON V.BountyAmount > ISNULL(R.BountyAmount, -1)
) AS Q1
WHERE
Q1.rn = 1
)
SELECT
R.BountyAmount
FROM R
ORDER BY
R.BountyAmount ASC
OPTION (MAXRECURSION 0); L'idea ha le sue radici in una cosiddetta scansione di salto dell'indice:troviamo il valore più basso di interesse all'inizio dell'indice b-tree in ordine crescente, quindi cerchiamo di trovare il valore successivo nell'ordine dell'indice e così via. La struttura di un indice b-tree rende molto efficiente la ricerca del valore successivo più alto:non è necessario eseguire la scansione dei duplicati.
L'unico vero trucco qui è convincere l'ottimizzatore a permetterci di usare TOP nella parte “ricorsiva” del CTE di restituire una copia di ogni valore distinto. Consulta il mio articolo precedente se hai bisogno di un aggiornamento sui dettagli.
Il piano di esecuzione (spiegato in generale da Craig Freedman qui) è:
 CTE seriale ricorsivo
CTE seriale ricorsivo
La query restituisce risultati corretti in 1 ms utilizzando 1 ms di CPU, secondo Sentry One Plan Explorer.
7. T-SQL iterativo
Una logica simile può essere espressa usando un WHILE ciclo continuo. Il codice potrebbe essere più facile da leggere e capire rispetto al CTE ricorsivo. Evita inoltre di dover utilizzare trucchi per aggirare le numerose restrizioni sulla parte ricorsiva di un CTE. Le prestazioni sono competitive a circa 15 ms. Questo codice è fornito a scopo di interesse e non è incluso nella tabella di riepilogo delle prestazioni.
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @Result table
(
BountyAmount integer NULL UNIQUE CLUSTERED
);
DECLARE @BountyAmount integer;
-- First value in index order
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
-- Next higher value
WHILE @@ROWCOUNT > 0
BEGIN
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
WHERE
V.BountyAmount > ISNULL(@BountyAmount, -1)
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
END;
-- Accumulated results
SELECT
R.BountyAmount
FROM @Result AS R
ORDER BY
R.BountyAmount; Tabella di riepilogo delle prestazioni
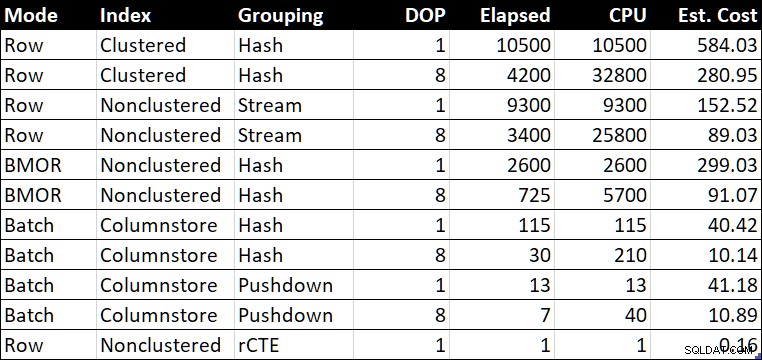 Tabella di riepilogo delle prestazioni (durata/CPU in millisecondi)
Tabella di riepilogo delle prestazioni (durata/CPU in millisecondi)
L'Est. La colonna Costo" mostra la stima del costo dell'ottimizzatore per ciascuna query come riportato nel sistema di test.
Pensieri finali
Trovare un piccolo numero di valori distinti potrebbe sembrare un requisito piuttosto specifico, ma mi sono imbattuto abbastanza frequentemente nel corso degli anni, di solito come parte dell'ottimizzazione di una query più ampia.
Gli ultimi diversi esempi erano abbastanza vicini nelle prestazioni. Molte persone sarebbero contente di qualsiasi risultato in meno di un secondo, a seconda delle priorità. Anche la modalità batch seriale sul risultato dell'archivio riga di 2.600 ms si confronta bene con il miglior parallelo piani in modalità riga, il che fa ben sperare per velocizzazioni significative semplicemente eseguendo l'aggiornamento a SQL Server 2019 e abilitando il livello di compatibilità del database 150. Non tutti saranno in grado di passare rapidamente all'archiviazione dell'archivio a colonne e comunque non sarà sempre la soluzione giusta . La modalità batch nell'archivio riga fornisce un modo accurato per ottenere alcuni dei vantaggi possibili con gli archivi colonna, supponendo che tu possa convincere l'ottimizzatore a scegliere di utilizzarlo.
Il risultato push down aggregato dell'archivio della colonna parallela di 57 milioni di righe elaborato in 7 ms (utilizzando 40 ms di CPU) è notevole, soprattutto considerando l'hardware. Il risultato di push down dell'aggregato seriale di 13 ms è altrettanto impressionante. Sarebbe fantastico se non avessi dovuto aggiungere un risultato aggregato insignificante per ottenere questi piani.
Per coloro che non possono ancora passare a SQL Server 2019 o allo storage dell'archivio colonne, il CTE ricorsivo è ancora una soluzione praticabile ed efficiente quando esiste un indice b-tree adatto e il numero di valori distinti necessari è garantito essere piuttosto piccolo. Sarebbe bello se SQL Server potesse accedere a un b-tree come questo senza dover scrivere un CTE ricorsivo (o codice T-SQL iterativo equivalente utilizzando WHILE ).
Un'altra possibile soluzione al problema è creare una vista indicizzata. Ciò fornirà valori distinti con grande efficienza. Il lato negativo, come al solito, è che ogni modifica alla tabella sottostante dovrà aggiornare il conteggio delle righe memorizzato nella vista materializzata.
Ciascuna delle soluzioni qui presentate ha il suo posto, a seconda delle esigenze. Avere una vasta gamma di strumenti disponibili è generalmente una buona cosa quando si sintonizzano le query. Il più delle volte, sceglierei una delle soluzioni in modalità batch perché le loro prestazioni saranno abbastanza prevedibili indipendentemente dal numero di duplicati presenti.