Recentemente sono stato rimproverato per aver suggerito che, in alcuni casi, un indice non cluster funzionerà meglio per una query particolare rispetto all'indice cluster. Questa persona ha affermato che l'indice cluster è sempre il migliore perché copre sempre per definizione e che qualsiasi indice non cluster con alcune o tutte le stesse colonne chiave era sempre ridondante.
Sarò felicemente d'accordo sul fatto che l'indice cluster copre sempre (e per evitare qualsiasi ambiguità qui, ci atterremo alle tabelle basate su disco con i tradizionali indici B-tree).
 Non sono d'accordo, tuttavia, che un indice cluster sia sempre più veloce di un indice non cluster. Non sono inoltre d'accordo sul fatto che sia sempre ridondante creare un indice non cluster o un vincolo univoco costituito dalle stesse (o alcune delle stesse) colonne nella chiave di clustering.
Non sono d'accordo, tuttavia, che un indice cluster sia sempre più veloce di un indice non cluster. Non sono inoltre d'accordo sul fatto che sia sempre ridondante creare un indice non cluster o un vincolo univoco costituito dalle stesse (o alcune delle stesse) colonne nella chiave di clustering.
Prendiamo questo esempio, Warehouse.StockItemTransactions , da WideWorldImporters. L'indice cluster viene implementato tramite una chiave primaria solo su StockItemTransactionID colonna (abbastanza tipico quando hai una sorta di ID surrogato generato da un'IDENTITÀ o da una SEQUENZA).
È una cosa abbastanza comune richiedere il conteggio dell'intera tabella (sebbene in molti casi ci siano modi migliori). Questo può essere per un'ispezione casuale o come parte di una procedura di impaginazione. La maggior parte delle persone lo farà in questo modo:
SELECT COUNT(*) FROM Warehouse.StockItemTransactions;
Con lo schema corrente, verrà utilizzato un indice non cluster:
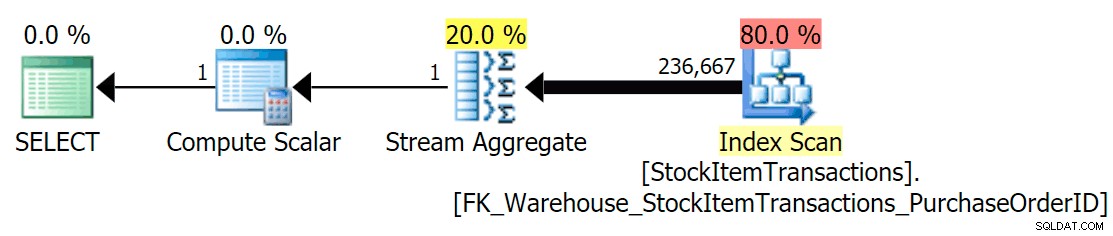
Sappiamo che l'indice non cluster non contiene tutte le colonne nell'indice cluster. L'operazione di conteggio deve solo assicurarsi che tutte le righe siano incluse, senza preoccuparsi di quali colonne siano presenti, quindi SQL Server generalmente sceglierà l'indice con il minor numero di pagine (in questo caso, l'indice scelto ha ~414 pagine).
Ora eseguiamo di nuovo la query, questa volta confrontandola con una query suggerita che forza l'uso dell'indice cluster.
SELECT COUNT(*) FROM Warehouse.StockItemTransactions; SELECT COUNT(*) /* with hint */ FROM Warehouse.StockItemTransactions WITH (INDEX(1));
Otteniamo una forma del piano quasi identica, ma possiamo vedere un'enorme differenza nelle letture (414 per l'indice scelto contro 1.982 per l'indice cluster):
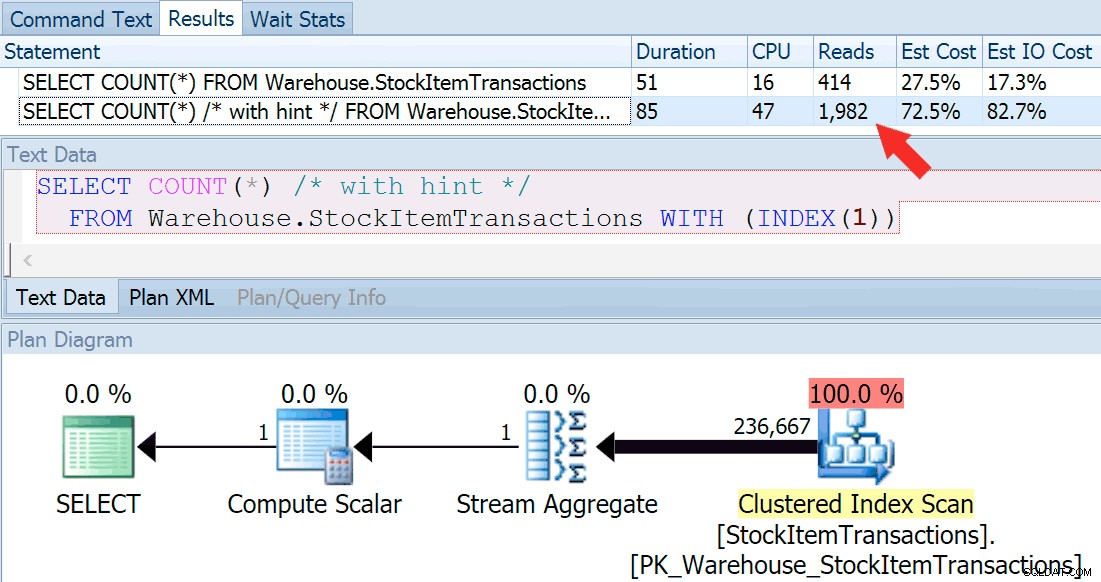
La durata è leggermente superiore per l'indice cluster, ma la differenza è trascurabile quando abbiamo a che fare con una piccola quantità di dati memorizzati nella cache su un disco veloce. Tale discrepanza sarebbe molto più pronunciata con più dati, su un disco lento o su un sistema con memoria insufficiente.
Se osserviamo i suggerimenti per le operazioni di scansione, possiamo vedere che mentre il numero di righe e i costi stimati della CPU sono identici, la grande differenza deriva dal costo di I/O stimato (poiché SQL Server sa che ci sono più pagine nel indice cluster rispetto all'indice non cluster):
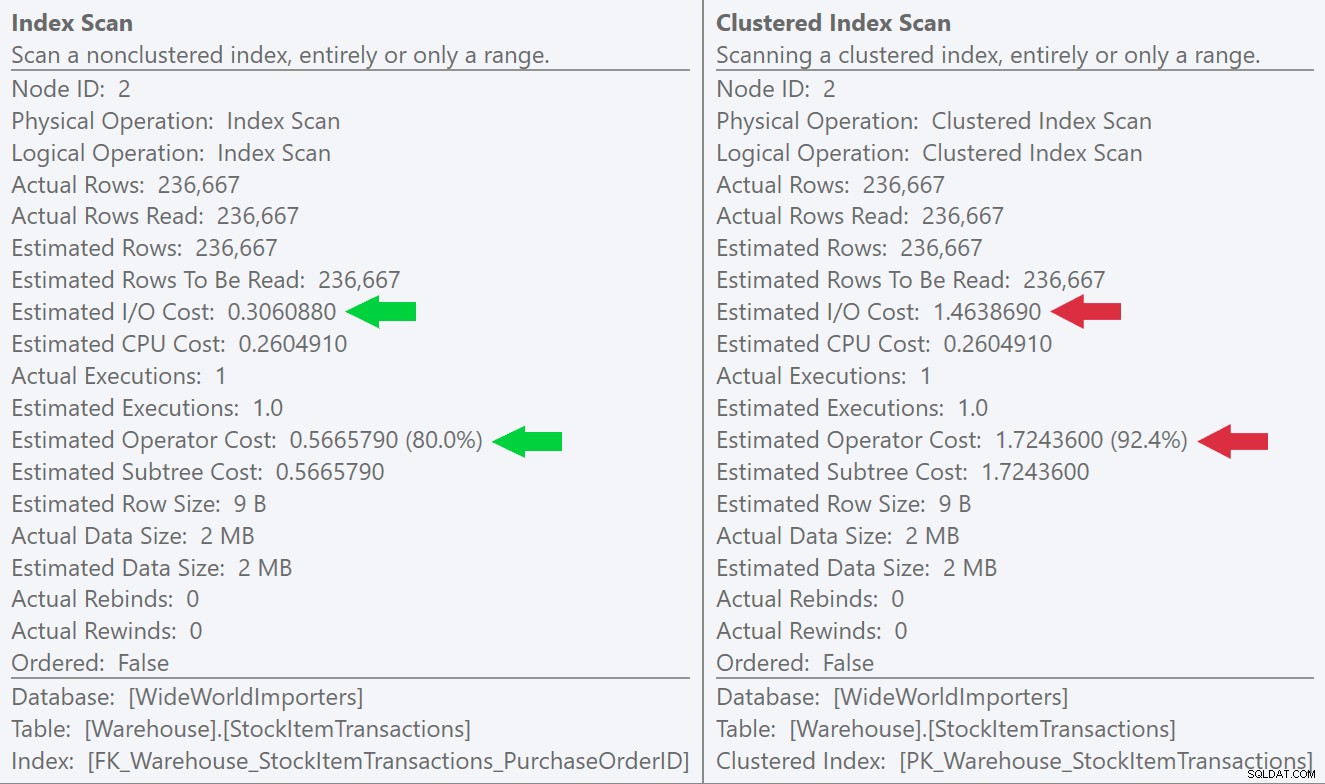
Possiamo vedere questa differenza ancora più chiaramente se creiamo un nuovo indice univoco solo sulla colonna ID (rendendolo "ridondante" con l'indice cluster, giusto?):
CREATE UNIQUE INDEX NewUniqueNCIIndex ON Warehouse.StockItemTransactions(StockItemTransactionID);
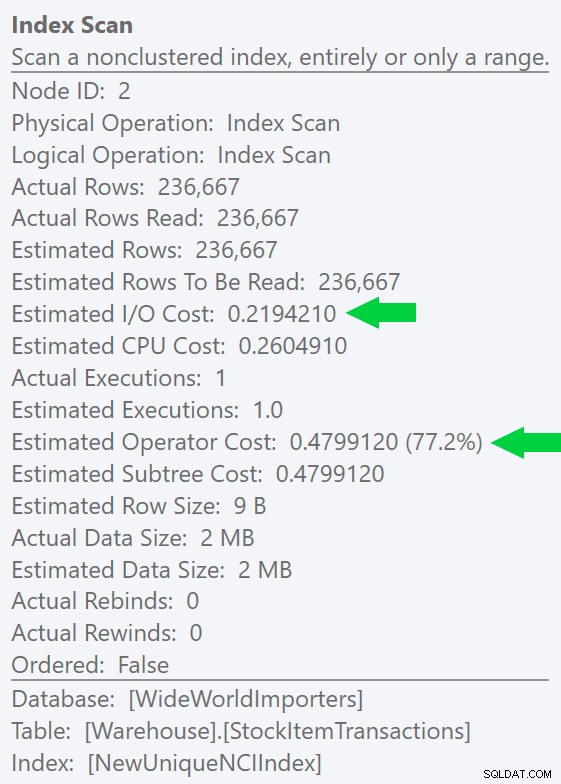 L'esecuzione di una query simile con un suggerimento di indice esplicito produce la stessa forma del piano, ma un I/O stimato ancora inferiore costo (e anche durate inferiori) – vedi immagine a destra. E se esegui la query originale senza il suggerimento, vedrai che SQL Server ora sceglie anche questo indice.
L'esecuzione di una query simile con un suggerimento di indice esplicito produce la stessa forma del piano, ma un I/O stimato ancora inferiore costo (e anche durate inferiori) – vedi immagine a destra. E se esegui la query originale senza il suggerimento, vedrai che SQL Server ora sceglie anche questo indice.
Potrebbe sembrare ovvio, ma molte persone crederebbero che l'indice cluster sia la scelta migliore qui. SQL Server quasi sempre favorirà pesantemente qualsiasi metodo fornirà il modo più economico per eseguire tutto l'I/O e, nel caso di un'analisi completa, sarà l'indice "più magro". Ciò può verificarsi anche con entrambi i tipi di ricerche (scansioni singleton e range), almeno quando l'indice copre.
Ora, come sempre, ciò non in alcun modo significa che dovresti andare a creare indici aggiuntivi su tutte le tue tabelle per soddisfare le query di conteggio. Non solo è un modo inefficiente per controllare le dimensioni della tabella (di nuovo, vedere questo articolo), ma un indice da supportare che dovrebbe significare che stai eseguendo quella query più spesso di quanto non aggiorni i dati. Ricorda che ogni indice richiede spazio su disco, spazio su memoria e tutte le scritture sulla tabella devono anche toccare ogni indice (indici filtrati a parte).
Riepilogo
Potrei trovare molti altri esempi che mostrano quando un non cluster può essere utile e vale il costo della manutenzione, anche quando si duplicano le colonne chiave dell'indice cluster. Gli indici non cluster possono essere creati con le stesse colonne chiave ma in un ordine di chiavi diverso o con ASC/DESC diversi sulle colonne stesse per supportare meglio un ordine di presentazione alternativo. Puoi anche avere indici non cluster che contengono solo un piccolo sottoinsieme di righe tramite l'uso di un filtro. Infine, se riesci a soddisfare le tue query più comuni con indici più magri e non raggruppati, è meglio anche per il consumo di memoria.
Ma in realtà, il mio scopo di questa serie è semplicemente quello di mostrare un controesempio che illustra la follia di fare affermazioni generali come questa. Ti lascio con una spiegazione di Paul White che, in una risposta DBA.SE, spiega perché un tale indice non cluster può effettivamente funzionare molto meglio di un indice cluster. Questo è vero anche quando entrambi usano entrambi i tipi di ricerca:
- Differenza tra ricerca indice cluster e ricerca indice non cluster