Spark è nato nel 2009 come progetto all'interno dell'AMPLab presso l'Università della California, Berkeley. Nello specifico, nasce dalla necessità di mettere alla prova il concetto di Mesos, anch'esso creato nell'AMPLab. Spark è stato discusso per la prima volta nel white paper di Mesos intitolato Mesos:A Platform for Fine-Grained Resource Sharing in the Data Center, scritto in particolare da Benjamin Hindman e Matei Zaharia.
È emerso come una soluzione rapida e conveniente per eseguire analisi complesse di dati su larga scala. Spark si è evoluto come un nuovo framework di elaborazione per i big data che risolve molte delle carenze nel modello MapReduce. Supporta analisi dei dati su larga scala e i dati potrebbero provenire da diverse fonti come tempo reale, elaborazione batch in vari formati come immagini, testi, grafici e molti altri. Oltre al core Apache Spark, fornisce anche alcuni utili set di librerie per l'analisi dei big data.
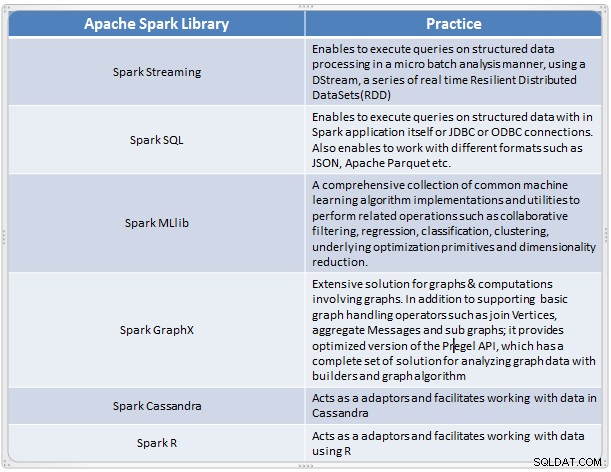
Panoramica dei componenti Spark
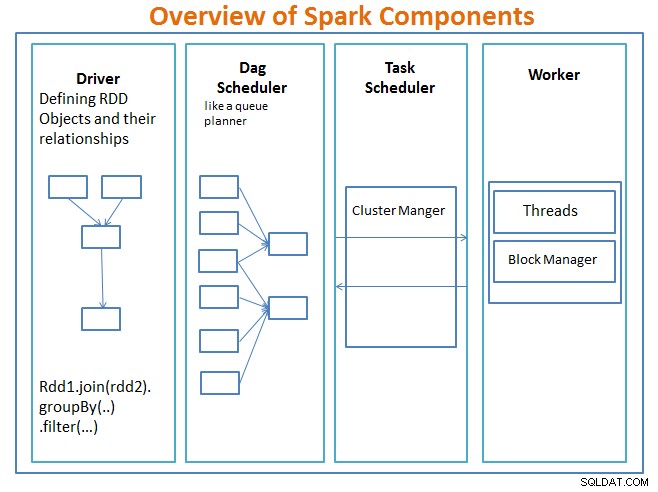
Il autista è il codice che include la funzione principale e definisce i dataset distribuiti resilienti (RDD) e le loro trasformazioni. Gli RDD sono le principali strutture di dati che verranno utilizzate nei nostri programmi Spark.
Le operazioni parallele sugli RDD vengono inviate allo schedulatore DAG , che ottimizzerà il codice e arriverà a un DAG efficiente che rappresenti i passaggi di elaborazione dei dati nell'applicazione.
Il DAG risultante viene inviato al gestore del cluster e il gestore del cluster ha informazioni sui lavoratori, i thread assegnati e la posizione dei blocchi di dati ed è responsabile dell'assegnazione di attività di elaborazione specifiche ai lavoratori. Gestisce anche il paly indietro nel caso in cui il lavoratore fallisce. Il gestore del cluster può essere YARN, Mesos, il cluster Manager di Spark.
Il lavoratore riceve unità di lavoro e dati da gestire e il lavoratore esegue il suo compito specifico senza conoscere l'intero DAG e i suoi risultati vengono inviati alle applicazioni del driver.
Spark, come altri strumenti per big data, è potente, capace e adatto per affrontare una serie di sfide relative ai dati. Spark, come altre tecnologie per i big data, non è necessariamente la scelta migliore per ogni attività di elaborazione dei dati.
Nella parte 2, parleremo dei concetti di base di Spark come set di dati distribuiti resilienti, variabili condivise, SparkContext, trasformazioni, azione e i vantaggi dell'utilizzo di Spark insieme a esempi e quando utilizzare Spark.
Riferimento:
Impara Spark in un giorno dalle architetture di applicazioni Acodemy e Hadoop.