In precedenza ho scritto sui vantaggi dell'utilizzo di NOEXPAND suggerimenti, anche in Enterprise Edition. I dettagli sono tutti nell'articolo collegato, ma per riassumere brevemente:
- SQL Server verrà solo creato automaticamente statistiche su una vista indicizzata quando un
NOEXPANDviene utilizzato il suggerimento tabella. L'omissione di questo suggerimento può portare a avvisi del piano di esecuzione su statistiche mancanti che non possono essere risolte creando statistiche manualmente. - SQL Server usa solo statistiche della vista create automaticamente o manualmente nei calcoli della stima della cardinalità quando la query fa riferimento direttamente alla vista e a
NOEXPANDviene utilizzato il suggerimento. Per tutte le definizioni di visualizzazione tranne le più banali, ciò significa che è probabile che la qualità delle stime di cardinalità sia inferiore quando questo suggerimento non viene utilizzato, risultando spesso in piani di esecuzione meno ottimali. - La mancanza o l'impossibilità di utilizzare le statistiche di visualizzazione può indurre l'ottimizzatore a indovinare le stime di cardinalità, anche quando sono disponibili le statistiche della tabella di base. Ciò può verificarsi quando una parte del piano di query viene sostituita con un riferimento di vista indicizzato dalla funzione di corrispondenza automatica delle viste, ma le statistiche delle viste non sono disponibili, come descritto sopra.
C'è un'altra conseguenza del non usare NOEXPAND suggerimento, che ho menzionato di sfuggita un paio di anni fa nel mio articolo, Limitazioni dello strumento di ottimizzazione con indici filtrati:
Il NOEXPAND sono necessari suggerimenti anche in Enterprise Edition per garantire che la garanzia di unicità fornita dagli indici di visualizzazione venga utilizzata dall'ottimizzatore.
Questo articolo esamina questa affermazione e le sue implicazioni in modo più dettagliato.
Configurazione demo
Lo script seguente crea una tabella semplice e una vista indicizzata:
CREATE TABLE dbo.T
(
col1 integer NOT NULL
);
GO
INSERT dbo.T WITH (TABLOCKX)
(col1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.type = N'P';
GO
CREATE VIEW dbo.VT
WITH SCHEMABINDING
AS
SELECT T.col1
FROM dbo.T AS T;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.VT (col1); Ciò crea una singola tabella heap di colonna e una vista illimitata della stessa tabella con un indice cluster univoco. Questo non vuole essere un caso d'uso realistico per una vista indicizzata; ma aiuterà a illustrare i punti chiave con il minimo di distrazioni. Il punto importante è che la tabella di base qui non ha alcun indice (nemmeno un indice cluster), ma la vista sì e quell'indice è univoco.
La query di esempio
Considera la seguente semplice query sulla tabella di base:
SELECT DISTINCT
T.col1
FROM dbo.T AS T; Il piano di esecuzione che vedrai per questa query dipende dall'edizione di SQL Server in uso. Se non Enterprise Edition (o equivalente), vedrai un piano come questo:

Query Optimizer di SQL Server ha scelto di analizzare la tabella di base e applicare la distinzione specificata utilizzando un operatore di ordinamento distinto. Questa forma del piano è completamente prevista, poiché la corrispondenza automatica della vista indicizzata non è disponibile al di fuori di Enterprise Edition. Da questo momento in poi smetterò di dire "Edizione Enterprise o equivalente", ma continua a dedurre che intendo qualsiasi edizione che supporta la corrispondenza automatica delle visualizzazioni quando dico "Edizione Enterprise" d'ora in poi.
Il suggerimento ESPANDI VISUALIZZAZIONI
Questo è un po' da parte, ma per ottenere lo stesso piano su Enterprise Edition, dobbiamo utilizzare un EXPAND VIEWS suggerimento per la query:
SELECT DISTINCT
T.col1
FROM dbo.T AS T
OPTION (EXPAND VIEWS);
Potrebbe sembrare un po' strano usare questo suggerimento quando non ci sono nessun riferimento di visualizzazione nella query, ma è così che funziona. Il EXPAND VIEWS hint specifica in modo efficace che la corrispondenza della vista indicizzata deve essere disabilitata durante la compilazione e l'ottimizzazione della query. Per essere chiari:senza questo suggerimento, Enterprise Edition potrebbe altrimenti abbinare (parti della) query a una o più viste indicizzate.
Con corrispondenza automatica delle viste abilitata
Senza un EXPAND VIEWS suggerimento, la compilazione della stessa query su Developer Edition (ad esempio) produce un piano diverso:
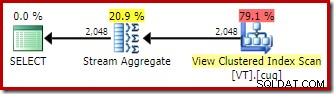
L'applicazione della corrispondenza delle viste indicizzate significa che il piano di esecuzione prevede una scansione dell'indice cluster della vista invece di una scansione della tabella di base.
Lo stesso piano viene prodotto in questo caso se la query fa riferimento direttamente alla vista (anziché alla tabella di base):
SELECT DISTINCT
V.col1
FROM dbo.VT AS V; In tutte le edizioni, il riferimento alla vista viene espanso prima dell'inizio dell'ottimizzazione della query. Nelle edizioni equivalenti a Enterprise, il modulo espanso può essere abbinato alla vista in un secondo momento. Questo è un concetto chiave da comprendere quando si pensa a come il compilatore di query e l'ottimizzatore utilizzano le viste indicizzate in SQL Server.
L'aggregato di flusso
La differenza più interessante tra i due piani che abbiamo visto finora è lo Stream Aggregate nel piano con corrispondenza della vista. Se guardi i costi stimati degli operatori Table Scan e View Scan, vedrai che sono esattamente gli stessi. L'ottimizzatore non ha deciso di utilizzare la vista indicizzata perché rendeva l'accesso ai dati più economico. Piuttosto, la scansione dell'indice di visualizzazione consente il DISTINCT requisito per essere implementato come Stream Aggregate, piuttosto che come Hash Aggregate o Distinct Sort (come nel primo piano).
Uno Stream Aggregate richiede l'input ordinato in base alle colonne di raggruppamento. In questo caso, il distinto equivale al raggruppamento per singola colonna e l'indice cluster univoco della vista fornisce la necessaria garanzia di ordinamento. Il modello di costo dell'ottimizzatore identifica Stream Aggregate come un'opzione più economica rispetto a Distinct Sort o Hash Aggregate per questa query. Questa è la base per l'ottimizzatore che sceglie di accedere alla vista indicizzata quando è disponibile la corrispondenza automatica della vista.
Con tutto ciò che è stato detto e compreso, lo Stream Aggregate è ancora inaspettato:data la garanzia di unicità fornita dall'indice di visualizzazione, non è affatto necessario eseguire questa operazione di raggruppamento. L'unico l'indice cluster garantisce già che la colonna non contenga duplicati.
Questo, in poche parole, è il problema. Quando viene utilizzata la corrispondenza automatica delle viste, l'ottimizzatore riconosce la garanzia di ordinazione fornita dall'indice di vista, ma non la garanzia di unicità.
Utilizzo di un suggerimento NOEXPAND
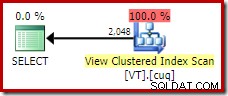
Per ottenere il piano di esecuzione ideale per questa query, dobbiamo fare riferimento direttamente alla vista e utilizzare un NOEXPAND suggerimento per la tabella:
SELECT DISTINCT
V.col1
FROM dbo.VT AS V WITH (NOEXPAND); Questo ci dà il piano che una persona esperta del database si aspetterebbe; uno che riconosca correttamente che l'operazione distinta è ridondante e può essere rimossa:
Un secondo esempio
Il mancato utilizzo della garanzia di unicità fornita da un indice di visualizzazione può avere altri effetti sul piano di esecuzione finale. Considera ora un self join della vista indicizzata (di nuovo, solo per illustrare un concetto:questa non vuole essere una query realistica):
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1; Utilizzando Developer Edition il piano di esecuzione scelto non accede affatto alla vista indicizzata e presenta un hash join (a volte un'indicazione che manca un indice utile):
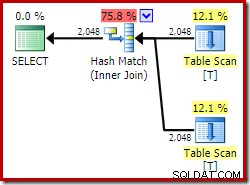
Ora proviamo esattamente la stessa query, ma con un NOEXPAND suggerimento su ogni riferimento di vista:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1 WITH (NOEXPAND)
JOIN dbo.VT AS V2 WITH (NOEXPAND)
ON V2.col1 = V1.col1; Il piano di esecuzione ora include due accessi alla vista indicizzata e un join di unione:
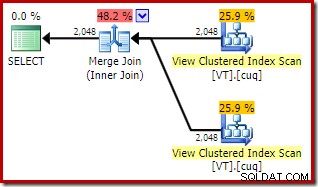
Questo nuovo piano ha un costo stimato molto più basso rispetto al piano hash join, quindi perché l'ottimizzatore non ha scelto questa opzione prima? Possiamo capire perché aggiungendo un suggerimento di unione alla query originale:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1
OPTION (MERGE JOIN);
Questo dà un aspetto simile piano che sceglie di accedere alla vista anche se NOEXPAND non è stato specificato:
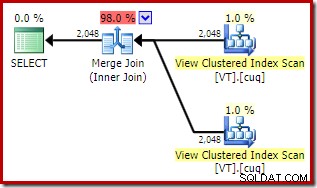
Il costo complessivo stimato di questo piano è superiore a entrambi gli esempi precedenti. Il Merge Join in questo piano rappresenta anche una percentuale maggiore del costo totale stimato rispetto a prima (98% contro 48,2%).
La ragione di ciò può essere vista osservando le proprietà del join di unione. Nel NOEXPAND piano, era un join uno a molti. Nel piano direttamente sopra, è un join molti-a-molti. Il modello di costo dell'ottimizzatore assegna un costo maggiore ai join di unione molti-a-molti perché è necessaria una tabella di lavoro tempdb per gestire eventuali duplicati.
Conclusioni
Le garanzie fornite da un indice univoco possono essere un potente strumento di ottimizzazione, quindi è un peccato che la corrispondenza automatica dell'indice non sia attualmente in grado di trarne vantaggio. I potenziali vantaggi vanno oltre l'eliminazione di aggregazioni non necessarie o l'abilitazione di un merge join uno-a-molti, come mostrato nei semplici esempi precedenti. In generale, può essere difficile individuare che un piano di esecuzione non è ottimale perché l'ottimizzatore ha mancato di sfruttare una garanzia di unicità.
Questa limitazione dell'ottimizzatore non si applica solo all'indice cluster univoco che una vista deve avere per essere materializzata. In scenari più complessi, nella vista possono essere presenti anche indici non cluster aggiuntivi; forse per riflettere relazioni incrociate difficili da imporre o rappresentare in altro modo. Se questi indici non cluster sono definiti come univoci, l'ottimizzatore ignorerà anche queste garanzie, se viene utilizzata la corrispondenza automatica degli indici.
Aggiungendo questo alle limitazioni relative alla creazione e all'utilizzo di informazioni statistiche, sembra che fare affidamento sulla corrispondenza automatica delle viste possa comportare piani di esecuzione inferiori. L'opzione più sicura è probabilmente fare riferimento a viste indicizzate in modo esplicito e utilizzare un NOEXPAND suggerimento ogni volta, almeno fino a quando questi problemi non vengono risolti nel prodotto.
Fattori attenuanti
Vorrei sottolineare che il problema descritto in questo articolo si applica solo alla garanzia di unicità fornita da un indice di visualizzazione univoco. Se l'ottimizzatore può ottenere le informazioni sull'unicità richieste in un altro modo , ci sono buone probabilità che i problemi di ottimizzazione vengano evitati.
Ad esempio, potrebbe essere presente un indice univoco adatto su una tabella di base a cui fa riferimento la vista. Oppure, nel caso di una vista che contiene un'aggregazione, l'ottimizzatore può già dedurre un'utile garanzia di unicità dal GROUP BY della vista clausola. La pratica comune di aggiungere un indice cluster di viste alle chiavi di raggruppamento non aggiunge ulteriori informazioni sull'univocità in questo caso.
Tuttavia, ci sono momenti in cui questa "supervisione dell'unicità" può significare che otterrai piani di esecuzione di qualità migliore utilizzando un riferimento di visualizzazione esplicito e NOEXPAND suggerimenti, anche in Enterprise Edition.