Telecamere, porte girevoli, ascensori, sensori di temperatura, allarmi:tutti questi dispositivi producono un gran numero di segnali interconnessi correlati agli eventi che accadono intorno a noi. Ora immagina di essere la persona che ha bisogno di tenere traccia degli stati, produrre report in tempo reale e fare previsioni basate su tutti questi dati di segnale. Per fare ciò, devi prima archiviare quei dati. Un modello di dati che supporti tale elaborazione del segnale è l'argomento dell'articolo di oggi.
Il modo più semplice per memorizzare i segnali in entrata sarebbe semplicemente archiviare una loro rappresentazione testuale in un enorme elenco. Questo approccio ci consentirebbe di eseguire rapidamente gli inserimenti, ma gli aggiornamenti sarebbero problematici. Inoltre, un tale modello non sarebbe normalizzato, e quindi non andremo in quella direzione.
Creeremo un modello di dati normalizzato che potrebbe essere utilizzato per archiviare i dati generati da diversi dispositivi e definiremo anche come i dispositivi sono correlati. Un tale modello memorizzerebbe in modo efficiente tutto ciò di cui abbiamo bisogno e potrebbe essere utilizzato anche per analisi e analisi predittive.
Modello di dati
Il modello dei dati di elaborazione del segnale
Il modello si compone di tre aree tematiche:
ComplexesInstallations & DevicesSignals & Events
Descriveremo ciascuna di queste aree tematiche nell'ordine in cui è elencata.
Complessi
Durante la creazione di questo modello di dati, sono partito dal presupposto che lo useremo per tenere traccia di ciò che sta accadendo in complessi più grandi. I complessi variano in dimensioni da una singola stanza a un centro commerciale. È importante che ogni complesso abbia almeno un dispositivo/sensore, ma probabilmente ne avrà molti di più.
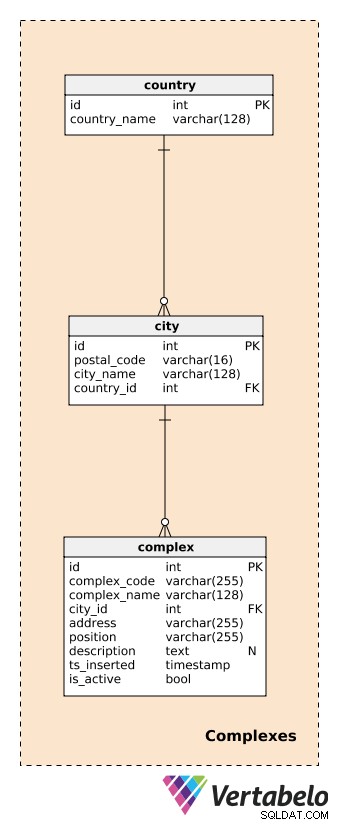
Prima di descrivere i complessi, è necessario definire le tabelle che gestiscono paesi e città. Questi forniranno una descrizione abbastanza dettagliata dell'ubicazione di ciascun complesso.
Per ogni country , memorizzeremo il suo country_name UNICO; per ogni city , memorizzeremo la combinazione UNICA di postal_code , city_name e country_id . Non entrerò nei dettagli qui e daremo per scontato che ogni città abbia un solo codice postale. In realtà, la maggior parte delle città avrà più di un codice postale; in tal caso, possiamo utilizzare il codice principale per ogni città.
Un complex è l'edificio o il luogo effettivo in cui sono installati i dispositivi di generazione dei dati. Come affermato in precedenza, i complessi possono variare da una singola stanza o una stazione di misurazione a luoghi molto più grandi come parcheggi, centri commerciali, cinema, ecc. Sono oggetto della nostra analisi. Vogliamo essere in grado di tracciare ciò che sta accadendo a livello complesso in tempo reale e, successivamente, produrre report e analisi. Per ogni complesso, definiremo a:
complex_code– Un identificatore UNICO per ogni complesso. Anche se abbiamo un attributo di chiave primaria separato (id) per questa tabella, possiamo aspettarci di ereditare un altro codice identificativo per ogni complesso da un altro sistema.complex_name– Un nome usato per descrivere quel complesso. Nel caso di centri commerciali e cinema, questo potrebbe essere il loro nome attuale e noto; per una stazione di misura potremmo usare un nome generico.city_id– Un riferimento alla città in cui si trova il complesso.address– L'indirizzo fisico di quel complesso.position– La posizione del complesso (es. coordinate geografiche) definita in formato testuale.description– Una descrizione testuale che descrive più da vicino questo complesso.ts_inserted– Un timestamp in cui è stato inserito questo record.is_active– Un valore booleano che indica se questo complesso è ancora attivo o meno.
Installazioni e dispositivi
Ora ci avviciniamo al cuore del nostro modello. Probabilmente avremo un numero di dispositivi installati in ogni complesso. Quasi certamente raggrupperemo anche questi dispositivi in base al loro scopo, ad es. potremmo inserire telecamere, sensori per porte e un motore utilizzato per aprire e chiudere una porta in un gruppo perché lavorano insieme.
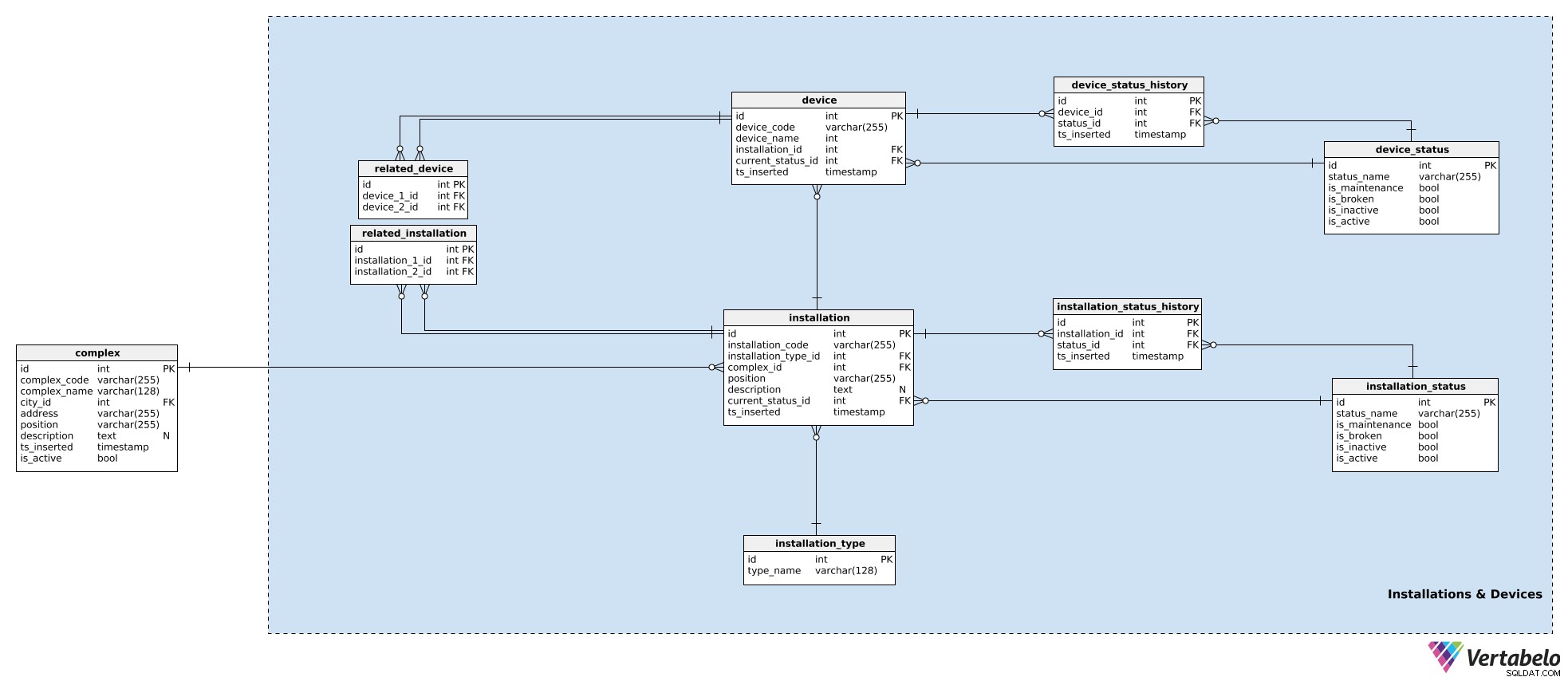
Nel nostro modello, i dispositivi che lavorano insieme in un complesso sono raggruppati in installazioni. Questi potrebbero essere per porte d'ingresso, scale mobili, sensori di temperatura, ecc. Per ogni installazione, memorizzeremo i seguenti dettagli nell'installation tabella:
installation_code– Un codice UNICO utilizzato per denotare tale installazione.installation type_id– Un riferimento alinstallation_typedizionario. Questo dizionario memorizza solo untype_nameUNICO attributo che descrive il tipo, ad es. scala mobile, ascensore.complex_id– Un riferimento alcomplexa cui appartiene l'installazione.position– Le coordinate, in formato testuale, di quell'installazione all'interno del complesso.description– Una descrizione testuale di tale installazione.current_status_id– Un riferimento allo stato corrente (dainstallation_statustabella) di tale installazione.ts_inserted– Un timestamp quando questo record è stato inserito nel nostro sistema.
Abbiamo già menzionato gli stati di installazione. Un elenco di tutti i possibili stati è memorizzato in installation_status dizionario. Ogni stato è UNICAMENTE definito dal suo status_name . Oltre a ciò, memorizzeremo i flag che indicano se tale stato, quando utilizzato, implica che l'installazione is_broken , is_inactive , is_maintenance o is_active . Deve essere impostato solo uno di questi flag alla volta.
Abbiamo già assegnato uno stato corrente all'installazione. Se terremo traccia di ciò che sta accadendo con il dispositivo, dobbiamo anche archiviarne la cronologia. Per farlo, utilizzeremo un'altra tabella, installation_status_history . Per ogni record qui, memorizzeremo i riferimenti all'installazione e allo stato correlati, nonché al momento (ts_inserted ) quando tale stato è stato assegnato.
Gli impianti fanno parte dei nostri complessi. Sebbene ogni installazione sia una singola entità, potrebbe comunque essere correlata ad altre installazioni. (Ad esempio, un sistema video all'ingresso principale di un centro commerciale è ovviamente correlato alle porte principali del centro commerciale:le persone verranno prima viste dalla telecamera e poi le porte si apriranno.) Se vogliamo tenere traccia di queste relazioni, le memorizzeremo nel related_installation tavolo. Si noti che questa tabella contiene solo coppie UNICHE di due chiavi, entrambe riferite all'installation tavolo.
La stessa logica viene utilizzata per memorizzare i dispositivi. I dispositivi sono singoli componenti hardware che producono i segnali che ci interessano. Mentre le installazioni appartengono a complessi, i dispositivi appartengono a installazioni. Per ogni device , memorizzeremo:
device_code– Un modo UNICO per denotare ogni dispositivo.device_name– Un nome per questo dispositivo.installation_id– Un riferimento all'installazione a cui appartiene questo dispositivo.current_status_id– Lo stato attuale del dispositivo.ts_inserted– Un timestamp in cui è stato inserito questo record.
Gli stati vengono gestiti allo stesso modo. Useremo il device_status tabella per memorizzare un elenco di tutti i possibili stati del dispositivo. Questa tabella ha la stessa struttura di installation_status e gli attributi sono usati allo stesso modo. Il motivo per avere i due dizionari di stato separati è che i dispositivi e le relative installazioni potrebbero avere stati diversi, almeno nel nome.
Lo stato corrente è memorizzato nel device.current_status_id attributo e la cronologia dello stato è archiviata in device_status_history tavolo. Per ogni record qui, memorizzeremo le relazioni con il dispositivo e lo stato, nonché il momento in cui questo record è stato inserito.
L'ultima tabella in questa area tematica è il related_device tavolo. Sebbene sia praticamente ovvio che tutti i dispositivi all'interno della stessa installazione sono strettamente correlati, voglio avere la possibilità di collegare due dispositivi qualsiasi appartenenti a qualsiasi installazione. Lo faremo memorizzando i loro due ID dispositivo in questa tabella.
Segnali ed eventi
Ora siamo pronti per il cuore dell'intero modello.
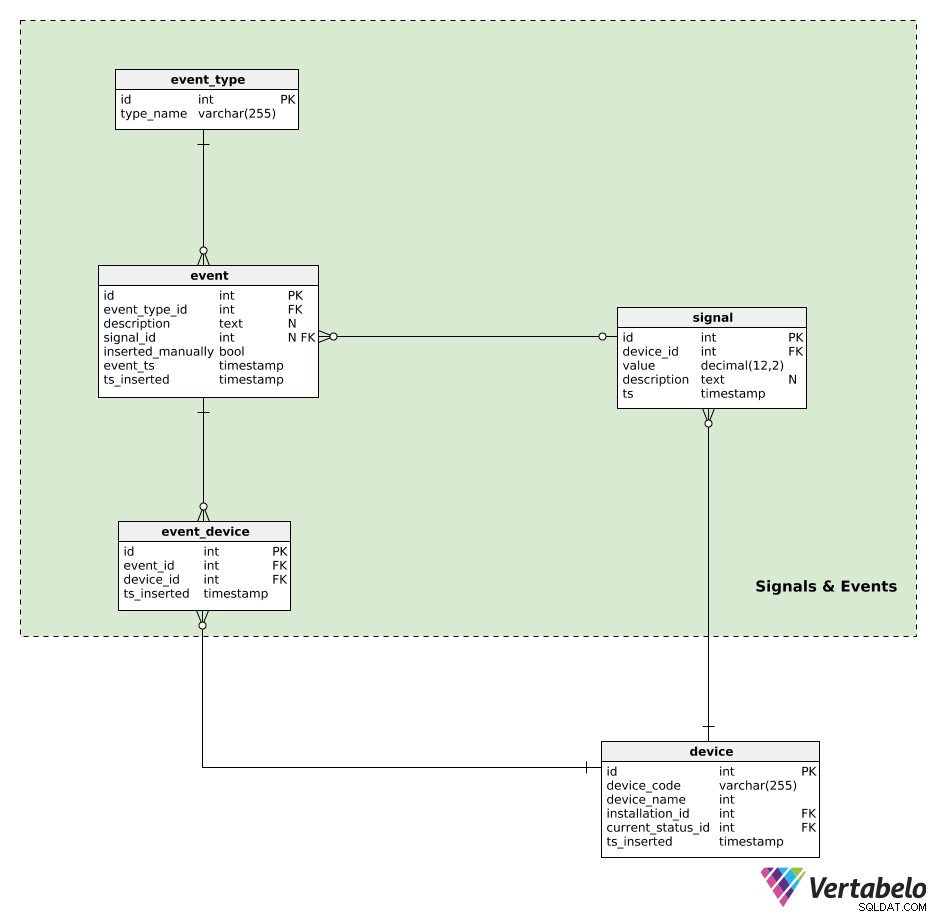
I dispositivi generano segnali. Tutti i dati del segnale sono conservati nel signal tavolo. Per ogni segnale, memorizzeremo:
device_id– Un riferimento al dispositivo che ha generato quel segnale.value– Il valore numerico di quel segnale.description– Un valore testuale che potrebbe contenere eventuali parametri aggiuntivi (es. tipo di segnale, valori, unità di misura utilizzata) relativi a quel singolo segnale. Questi dati vengono archiviati in un formato simile a JSON.ts– Un timestamp quando questo segnale è stato inserito nella tabella.
Possiamo aspettarci che questa tabella avrà un utilizzo estremamente intenso, con un gran numero di inserimenti eseguiti al secondo. Pertanto, la manutenzione del database dovrebbe concentrarsi sul monitoraggio delle dimensioni di questa tabella.
L'ultima cosa che voglio fare è aggiungere eventi al nostro modello di dati. Gli eventi possono essere generati automaticamente da un segnale o inseriti manualmente. Un evento generato automaticamente potrebbe essere "porta aperta per 5 minuti", mentre un evento inserito manualmente potrebbe essere "è stato necessario spegnere il dispositivo a causa di questo segnale". L'idea è di memorizzare le azioni che si sono verificate a seguito del comportamento del dispositivo. Successivamente, potremmo utilizzare questi eventi durante l'esecuzione di un'analisi del comportamento del dispositivo.
Gli eventi saranno granulati da event_type . Ogni tipo è UNICAMENTE definito dal suo type_name .
Tutti gli eventi generati automaticamente o inseriti manualmente vengono registrati nell'event tavolo. Per ogni record qui, memorizzeremo:
event_type_id– Un riferimento al tipo di evento correlato.description– Una descrizione testuale di quell'evento.signal_id– Un riferimento all'eventuale segnale che ha causato l'evento.inserted_manually– Un flag che indica se questo record è stato inserito manualmente o meno.event_tsets_inserted–Timestamp quando questo evento si è effettivamente verificato e quando è stato inserito un record di esso. Questi due potrebbero differire, specialmente quando i record di eventi vengono inseriti manualmente.
L'ultima tabella nel nostro modello è event_device tavolo. Questa tabella viene utilizzata per mettere in relazione gli eventi con tutti i dispositivi coinvolti. Per ogni record, memorizzeremo la coppia UNICA event_id – device_id e il timestamp di inserimento del record.
Cosa ne pensi del nostro modello di dati per l'elaborazione del segnale?
Oggi abbiamo analizzato un modello di dati semplificato che potremmo utilizzare per tracciare i segnali da un insieme di dispositivi installati in luoghi diversi. Il modello stesso dovrebbe essere sufficiente per archiviare tutto ciò di cui abbiamo bisogno per tenere traccia degli stati ed eseguire analisi. Tuttavia, sono possibili molti miglioramenti. Cosa potremmo aggiungere? Per favore, dicci nei commenti qui sotto.