Il IGNORE_DUP_KEY opzione per indici univoci specifica come SQL Server risponde a un tentativo di INSERT valori duplicati:si applica solo alle tabelle (non alle viste) e solo agli inserimenti. Qualsiasi porzione di inserimento di un MERGE l'istruzione ignora qualsiasi IGNORE_DUP_KEY impostazione dell'indice.
Quando IGNORE_DUP_KEY è OFF , il primo duplicato riscontrato genera un errore , e nessuna delle nuove righe viene inserita.
Quando IGNORE_DUP_KEY è ON , le righe inserite che violerebbero l'unicità vengono eliminate. Le righe rimanenti sono state inserite correttamente. Un avviso viene emesso un messaggio invece di un errore:
Riepilogo articolo
Il IGNORE_DUP_KEY l'opzione index può essere specificata per gli indici univoci sia cluster che non cluster. Il suo utilizzo su un indice cluster può comportare prestazioni molto inferiori rispetto a un indice univoco non cluster.
L'entità della differenza di prestazioni dipende dal numero di violazioni dell'unicità riscontrate durante l'INSERT operazione. Maggiore è il numero di violazioni, peggiori saranno le prestazioni dell'indice univoco cluster rispetto al confronto. Se non ci sono violazioni, l'inserimento dell'indice cluster potrebbe anche funzionare meglio.
Inserti di indice univoci in cluster
Per un indice univoco cluster con IGNORE_DUP_KEY impostato, i duplicati vengono gestiti dal motore di archiviazione .
Gran parte del lavoro coinvolto nell'inserimento di ogni riga viene eseguito prima che venga rilevato il duplicato. Ad esempio, un Inserimento indice cluster l'operatore naviga lungo il cluster b-tree dell'indice fino al punto in cui andrebbe la nuova riga, prendendo i latch di pagina e la consueta gerarchia di blocchi, prima di scoprire la chiave duplicata.
Quando viene rilevata la condizione di chiave duplicata, si verifica un errore è sollevato. Invece di annullare l'esecuzione e restituire l'errore al client, l'errore viene gestito internamente. La riga problematica non viene inserita e l'esecuzione continua, cercando la riga successiva da inserire. Se quella riga incontra una chiave duplicata, viene generato e gestito un altro errore e così via.
Le eccezioni sono molto costose da lanciare e catturare. Un numero significativo di duplicati rallenterà notevolmente l'esecuzione.
Inserti di indici univoci non cluster
Per un indice univoco non cluster con IGNORE_DUP_KEY impostato, i duplicati vengono gestiti dal processore di query . I duplicati vengono rilevati e viene emesso un avviso prima di ogni tentativo di inserimento.
Il Query Processor rimuove i duplicati dal flusso di inserimento, assicurando che nessun duplicato venga visualizzato dal motore di archiviazione. Di conseguenza, non vengono rilevati o gestiti internamente errori di violazione della chiave univoca.
Il compromesso
Esiste un compromesso tra il costo del rilevamento e della rimozione delle chiavi duplicate nel piano di esecuzione, rispetto al costo dell'esecuzione di un lavoro significativo relativo all'inserimento, e la generazione e la cattura di errori quando viene trovato un duplicato.
Se si prevede che i duplicati siano molto rari , la soluzione del motore di archiviazione (indice cluster) potrebbe essere più efficiente. Quando i duplicati sono meno rari, l'approccio del Query Processor probabilmente pagherà i dividendi. L'esatto punto di crossover dipenderà da fattori quali l'efficienza di runtime dei componenti del piano di esecuzione utilizzati per rilevare e rimuovere i duplicati.
Il resto di questo articolo fornisce una demo ed esamina più in dettaglio il motivo per cui l'approccio del motore di archiviazione può funzionare così male.
Demo
Lo script seguente crea una tabella temporanea con un milione di righe. Ha 1.000 valori univoci e 1.000 righe per ogni valore univoco. Questo set di dati verrà utilizzato come origine dati per gli inserimenti in tabelle con diverse configurazioni dell'indice.
DROP TABLE IF EXISTS #Data;
GO
CREATE TABLE #Data (c1 integer NOT NULL);
GO
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE
@Loop integer = 1,
@N integer = 1;
WHILE @N <= 1000
BEGIN
SET @Loop = 1;
BEGIN TRANSACTION;
-- Add 1,000 copies of the current loop value
WHILE @Loop <= 50
BEGIN
INSERT #Data
(c1)
VALUES
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N);
SET @Loop += 1;
END;
COMMIT TRANSACTION;
SET @N += 1;
END;
CREATE CLUSTERED INDEX cx
ON #Data (c1)
WITH (MAXDOP = 1); Linea di base
Il seguente inserimento in una variabile di tabella con un indice cluster non univoco richiede circa 900 ms :
DECLARE @T table
(
c1 integer NOT NULL
INDEX cuq CLUSTERED (c1)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D;
Nota la mancanza di IGNORE_DUP_KEY sulla variabile della tabella di destinazione.
Indice univoco cluster
Inserimento degli stessi dati in un cluster univoco indice con IGNORE_DUP_KEY imposta ON impiega circa 15.900 ms — quasi 18 volte peggio:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Indice univoco non cluster
Inserimento dei dati in un non cluster univoco indice con IGNORE_DUP_KEY imposta ON impiega circa 700 ms :
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE NONCLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Riepilogo delle prestazioni
Il test di base richiede 900 ms per inserire tutte le un milione di righe. Il test dell'indice non cluster richiede 700 ms per inserire solo le 1.000 chiavi distinte. Il test dell'indice cluster richiede 15.900 ms per inserire le stesse 1000 righe univoche.
Questo test è impostato deliberatamente per evidenziare le scarse prestazioni dell'implementazione del motore di archiviazione, generando 999 unità di lavoro sprecato (latch, blocchi, gestione degli errori) per ogni riga riuscita.
Il messaggio previsto non è quel IGNORE_DUP_KEY avrà sempre prestazioni scarse sugli indici cluster, solo che potrebbe, e potrebbe esserci una grande differenza tra indici cluster e non cluster.
Piano di esecuzione dell'indice cluster
Non c'è molto da vedere nel piano di inserimento dell'indice cluster:
Sono presenti 1.000.000 di righe trasferite all'Inserimento indice cluster operatore, che viene mostrato come "restituendo" 1.000 righe. Scavando nei dettagli del piano, possiamo vedere:
- 1.244.008 letture logiche presso l'operatore di inserimento.
- La maggior parte del tempo di esecuzione viene speso nell'Inserisci operatore.
- 11 ms di
SOS_SCHEDULER_YIELDwaits (cioè nessun'altra attesa).
Niente che spieghi davvero i 15.900 ms del tempo trascorso.
Perché le prestazioni sono così scarse
È evidente che questo piano dovrà fare molto lavoro per ogni riga:
- Esplora i livelli dell'albero b dell'indice cluster, bloccandoli e bloccandoli man mano che procedono, per trovare il punto di inserimento per il nuovo record.
- Se una qualsiasi delle pagine di indice necessarie non è in memoria, dovrà essere recuperata dal disco.
- Costruisci una nuova riga b-tree in memoria.
- Prepara i record di registro.
- Se viene trovata una chiave duplicata (che non è un record fantasma), genera un errore, gestisci quell'errore internamente, rilascia la riga corrente e riprendi in un punto adatto del codice per elaborare la riga candidata successiva.
È tutto un bel po' di lavoro e ricorda che accade tutto per ogni riga .
La parte su cui voglio concentrarmi è l'errore di sollevare e gestire, perché è estremamente costoso. Gli aspetti rimanenti sopra menzionati sono già stati resi il più economici possibile utilizzando una variabile table e una tabella temporanea nella demo.
Eccezioni
La prima cosa che voglio fare è mostrare che l'Inserimento indice cluster l'operatore solleva davvero un'eccezione quando incontra una chiave duplicata.
Un modo per mostrarlo direttamente è allegare un debugger e acquisire una traccia dello stack nel punto in cui viene generata l'eccezione:
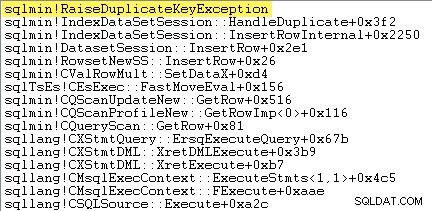
Il punto importante qui è che lanciare e catturare eccezioni è molto costoso.
Il monitoraggio di SQL Server tramite Windows Performance Recorder durante l'esecuzione del test e l'analisi dei risultati in Windows Performance Analyzer mostra:
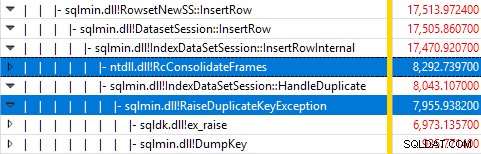
Quasi tutto il tempo di esecuzione della query viene speso in sqlmin!IndexDataSetSession::InsertRowInternal come ci si aspetterebbe per una query che non fa altro che inserire righe.
La sorpresa è che il 45% di quel tempo viene speso per sollevare eccezioni tramite sqlmin!RaiseDuplicateKeyException e un altro 47% viene speso nel blocco catch dell'eccezione associato (il ntdll!RcConsolidateFrames gerarchia).
Per riassumere:la raccolta e la cattura delle eccezioni rappresenta il 92% del tempo di esecuzione della nostra query di inserimento dell'indice cluster di prova.
Problemi relativi alla raccolta dei dati
I lettori più attenti potrebbero notare una quantità significativa, circa il 12%, del tempo speso in sqlmin!DumpKey per aumentare le eccezioni nell'immagine di Windows Performance Analyzer. Vale la pena esplorarlo rapidamente, insieme a un paio di elementi correlati.
Nell'ambito della generazione di un'eccezione, SQL Server deve raccogliere alcuni dati disponibili solo nel momento in cui si è verificato l'errore. Il numero di errore associato a un'eccezione di chiave duplicata è 2627. Il testo del messaggio in sys.messages per quel numero di errore è:
Le informazioni per popolare quei segnaposto devono essere raccolte nel momento in cui viene generato l'errore:non saranno disponibili in seguito! Ciò significa cercare e formattare il tipo di vincolo, il suo nome, il nome completo dell'oggetto di destinazione e il valore chiave specifico. Tutto ciò richiede tempo.
La seguente traccia dello stack mostra il server che formatta il valore della chiave duplicata come stringa Unicode durante il DumpKey chiama:
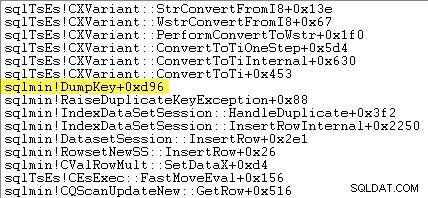
La gestione delle eccezioni implica anche l'acquisizione di una traccia dello stack:
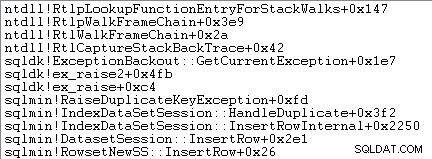
SQL Server registra anche le informazioni sulle eccezioni (inclusi i frame dello stack) in un piccolo buffer ad anello, come illustrato di seguito:
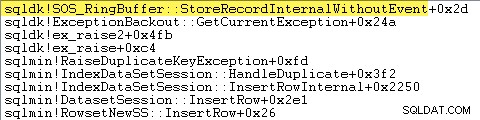
Puoi vedere quelle voci del buffer dell'anello usando un comando come:
SELECT TOP (10)
date_time =
DATEADD
(
MILLISECOND,
DORB.[timestamp] - DOSI.ms_ticks,
SYSDATETIME()
),
record = CONVERT(xml, DORB.record)
FROM sys.dm_os_ring_buffers AS DORB
CROSS JOIN sys.dm_os_sys_info AS DOSI
WHERE
DORB.ring_buffer_type = N'RING_BUFFER_EXCEPTION'
ORDER BY
DORB.[timestamp] DESC; Segue un esempio del record xml per un'eccezione di chiave duplicata. Nota gli stack frame:
<Record id="4611442" type="RING_BUFFER_EXCEPTION" time="93079430">
<Exception>
<Task address="0x00000245B5E1FC28" />
<Error>2627</Error>
<Severity>14</Severity>
<State>1</State>
<UserDefined>0</UserDefined>
<Origin>0</Origin>
</Exception>
<Stack>
<frame id="0">0X00007FFAC659E80A</frame>
<frame id="1">0X00007FFACBAC0EFD</frame>
<frame id="2">0X00007FFACBAA1252</frame>
<frame id="3">0X00007FFACBA9E040</frame>
<frame id="4">0X00007FFACAB55D53</frame>
<frame id="5">0X00007FFACAB55C06</frame>
<frame id="6">0X00007FFACB3E3D0B</frame>
<frame id="7">0X00007FFAC92020EC</frame>
<frame id="8">0X00007FFACAB5B2FA</frame>
<frame id="9">0X00007FFACABA3B9B</frame>
<frame id="10">0X00007FFACAB3D89F</frame>
<frame id="11">0X00007FFAC6A9D108</frame>
<frame id="12">0X00007FFAC6AB2BBF</frame>
<frame id="13">0X00007FFAC6AB296F</frame>
<frame id="14">0X00007FFAC6A9B7D0</frame>
<frame id="15">0X00007FFAC6A9B233</frame>
</Stack>
</Record> Tutto questo lavoro in background avviene per ogni eccezione. Nel nostro test, ciò significa che si verifica 999.000 volte, una per ogni riga che incontra una violazione della chiave duplicata.
Ci sono molti modi per vederlo, ad esempio eseguendo una traccia di Profiler usando l'eccezione evento in Errori e avvisi classe. Nel nostro test case, questo alla fine produrre 999.000 righe con TextData elementi come questo:
Violazione del vincolo UNIQUE KEY 'UQ__#AC166DE__3213663B8B6E2E0E'Impossibile inserire la chiave duplicata nell'oggetto 'dbo.@T'.
Il valore della chiave duplicata è (173).
Allegare Profiler significa che ogni evento di gestione delle eccezioni acquisisce una grande quantità di sovraccarico aggiuntivo, poiché i dati aggiuntivi necessari vengono raccolti e formattati. I dati predefiniti menzionati in precedenza vengono sempre raccolti, anche se nessuno sta consumando attivamente le informazioni.
Per essere chiari:i numeri delle prestazioni riportati in questo articolo sono stati tutti ottenuti senza un debugger collegato e nessun altro monitoraggio attivo.
Piano di esecuzione dell'indice non cluster
Nonostante sia molto più veloce, il piano di inserimento dell'indice non cluster è un po' più complesso, quindi lo suddividerò in due parti.
Il tema generale è che questo piano è più veloce perché elimina i duplicati prima cercando di inserirli nella tabella di destinazione.
Parte 1
Innanzitutto, il lato destro del piano dell'indice non cluster:
Questa parte del piano rifiuta tutte le righe che hanno una corrispondenza chiave nella tabella di destinazione per l'indice univoco con IGNORE_DUP_KEY imposta ON .
Potresti aspettarti di vedere un Anti Semi Join qui, ma SQL Server non dispone dell'infrastruttura necessaria per emettere l'avviso di chiave duplicata richiesto con un Anti Semi Join operatore. (Se ciò non ha già senso, dovrebbe farlo a breve.)
Invece, otteniamo un piano con una serie di caratteristiche interessanti:
- La Scansione indice cluster è
Ordered:Trueper fornire input al Unisci semi join sinistro ordinato per colonnac1nel#Datatabella. - La Scansione dell'indice della variabile della tabella è
Ordered:False - Il ordinamento ordina righe per colonna
c1nella variabile tabella. Questo ordine potrebbe essere stato fornito da un ordinato scansione dell'indice delle variabili della tabella suc1, ma l'ottimizzatore decide l'Ordina è il modo più economico per fornire il livello richiesto di protezione di Halloween. - La variabile della tabella Scansione indice ha un
UPDLOCKinterno eSERIALIZABLEsuggerimenti applicati per garantire la stabilità dell'obiettivo durante l'esecuzione del piano. - Il Unisci semi join sinistro controlla le corrispondenze nella variabile della tabella per ogni valore di
c1restituito da#Datatavolo. A differenza di un normale semi join, emette ogni riga ricevuta sul suo input superiore. Imposta un flag in una colonna sonda per indicare se la riga corrente ha trovato una corrispondenza o meno. La colonna probe viene emessa da Unisci semi join sinistro come espressione denominataExpr1012. - La affermazione l'operatore controlla il valore della colonna probe
Expr1012. La prima volta che vede una riga con un valore di colonna probe non nullo (che indica che è stata trovata una corrispondenza della chiave dell'indice), emette un "Chiave duplicata è stata ignorata" messaggio. - La affermazione passa solo le righe in cui la colonna probe è nulla. Ciò elimina le righe in arrivo che produrrebbero un errore di chiave duplicata.
Tutto ciò potrebbe sembrare complesso, ma essenzialmente è semplice come impostare un flag se viene trovata una corrispondenza, emettere un avviso la prima volta che viene impostato il flag e passare solo righe verso l'inserto che non esistono già nella tabella di destinazione .
Parte 2
La seconda parte del piano segue l'Assert operatore:
La parte precedente del piano ha rimosso le righe che avevano una corrispondenza nella tabella di destinazione. Questa parte del piano rimuove i duplicati all'interno del set di inserti .
Ad esempio, immagina che non ci siano righe nella tabella di destinazione in cui c1 = 1 . Potremmo comunque causare un errore di chiave duplicata se proviamo a inserire due righe con c1 = 1 dalla tabella di origine. Dobbiamo evitarlo per onorare la semantica di IGNORE_DUP_KEY = ON .
Questo aspetto è gestito dal Segmento e In alto operatori.
Il segmento l'operatore imposta un nuovo flag (etichettato Segment1015 ) quando incontra una riga con un nuovo valore per c1 . Poiché le righe sono presentate in c1 ordine (grazie alla conservazione dell'ordine Unisci ), il piano può fare affidamento su tutte le righe con lo stesso c1 valore che arriva in un flusso contiguo.
Il Top l'operatore passa una riga per ogni gruppo di duplicati, come indicato dal Segmento bandiera. Se il Top l'operatore incontra più di una riga per lo stesso segmento gruppo (c1 valore), emette un "Chiave duplicata ignorata" avviso, se è la prima volta che il piano incontra tale condizione.
L'effetto netto di tutto ciò è che agli operatori di inserimento viene passata solo una riga per ogni valore univoco di c1 e, se necessario, viene generato un avviso.
Il piano di esecuzione ha ora eliminato tutte le potenziali violazioni delle chiavi duplicate, quindi il restante Inserimento tabella e Inserimento indice gli operatori possono inserire in modo sicuro righe nell'heap e nell'indice non cluster senza timore di un errore di chiave duplicata.
Ricorda che il UPDLOCK e SERIALIZABLE i suggerimenti applicati alla tabella di destinazione assicurano che il set non possa cambiare durante l'esecuzione. In altre parole, un'istruzione simultanea non può modificare la tabella di destinazione in modo tale che si verifichi un errore di chiave duplicata in Inserisci operatori. Questo non è un problema qui poiché stiamo usando una variabile di tabella privata, ma SQL Server aggiunge ancora i suggerimenti come misura di sicurezza generale.
Senza questi suggerimenti, un processo simultaneo potrebbe aggiungere una riga alla tabella di destinazione che genererebbe una violazione della chiave duplicata, nonostante i controlli effettuati dalla parte 1 del piano. SQL Server deve essere sicuro che i risultati del controllo di esistenza rimangano validi.
Il lettore curioso può vedere alcune delle funzionalità sopra descritte abilitando i flag di traccia 3604 e 8607 per vedere l'albero di output dell'ottimizzatore:
PhyOp_RestrRemap
PhyOp_StreamUpdate(INS TBL: @T, iid 0x2 as IDX, Sort(QCOL: .c1, )), {
- COL: Bmk10001013 = COL: Bmk1000
- COL: c11014 = QCOL: .c1}
PhyOp_StreamUpdate(INS TBL: @T, iid 0x0 as TBLInsLocator(COL: Bmk1000 ) REPORT-COUNT), {
- QCOL: .c1= QCOL: [D].c1}
PhyOp_GbTop Group(QCOL: [D].c1,) WARN-DUP
PhyOp_StreamCheck (WarnIgnoreDuplicate TABLE)
PhyOp_MergeJoin x_jtLeftSemi M-M, Probe COL: Expr1012 ( QCOL: [D].c1) = ( QCOL: .c1)
PhyOp_Range TBL: #Data(alias TBL: D)(1) ASC
PhyOp_Sort +s -d QCOL: .c1
PhyOp_Range TBL: @T(2) ASC Hints( UPDLOCK SERIALIZABLE FORCEDINDEX )
ScaOp_Comp x_cmpIs
ScaOp_Identifier QCOL: [D].c1
ScaOp_Identifier QCOL: .c1
ScaOp_Logical x_lopIsNotNull
ScaOp_Identifier COL: Expr1012
Pensieri finali
Il IGNORE_DUP_KEY l'opzione index non è qualcosa che la maggior parte delle persone userà molto spesso. Tuttavia, è interessante osservare come viene implementata questa funzionalità e perché possono esserci grandi differenze di prestazioni tra IGNORE_DUP_KEY su indici cluster e non cluster.
In molti casi, pagherà seguire l'esempio del Query Processor e cercare di scrivere query che eliminino esplicitamente i duplicati, piuttosto che fare affidamento su IGNORE_DUP_KEY . Nel nostro esempio, ciò significherebbe scrivere:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED -- no IGNORE_DUP_KEY!
);
INSERT @T
(c1)
SELECT DISTINCT -- Remove duplicates
D.c1
FROM #Data AS D; Questo viene eseguito in circa 400 ms , solo per la cronaca.