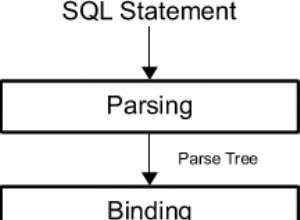
RDBMS è uno dei database più comunemente usati fino ad oggi, e quindi competenze SQL sono indispensabili nella maggior parte dei ruoli lavorativi. In questo articolo SQL Interview Questions, ti presenterò le domande più frequenti su SQL (Structured Query Language). Questo articolo è la guida perfetta per imparare tutti i concetti relativi a SQL, Oracle, MS SQL Server e database MySQL. Il nostro articolo sulle 65 principali domande sulle interviste SQL è la risorsa unica da dove puoi migliorare la tua preparazione al colloquio.
Vuoi migliorare te stesso per andare avanti nella tua carriera? Dai un'occhiata alle Tecnologie più di tendenza .Iniziamo!
Domande sull'intervista SQL
- Qual è la differenza tra SQL e MySQL?
- Quali sono i diversi sottoinsiemi di SQL?
- Cosa intendi per DBMS? Quali sono i suoi diversi tipi?
- Cosa intendi per tabella e campo in SQL?
- Cosa sono i join in SQL?
- Qual è la differenza tra i tipi di dati CHAR e VARCHAR2 in SQL?
- Qual è la chiave primaria?
- Cosa sono i vincoli?
- Qual è la differenza tra le istruzioni DELETE e TRUNCATE?
- Cos'è una chiave univoca?
Q1. Qual è la differenza tra SQL e MySQL?
| SQL | MySQL |
| SQL è un linguaggio standard che sta per Structured Query Language basato su lingua inglese | MySQL è un sistema di gestione di database. |
| SQL è il nucleo del database relazionale utilizzato per l'accesso e la gestione del database | MySQL è un RDMS (Relational Database Management System) come SQL Server, Informix ecc. |
Q2. Quali sono i diversi sottoinsiemi di SQL?
- Data Definition Language (DDL):consente di eseguire varie operazioni sul database come CREATE, ALTER e DELETE oggetti.
- Data Manipulation Language (DML) – Ti consente di accedere e manipolare i dati. Ti aiuta a inserire, aggiornare, eliminare e recuperare dati dal database.
- Data Control Language (DCL) – Consente di controllare l'accesso al database. Esempio:Concedi, revoca le autorizzazioni di accesso.
Q3. Cosa intendi per DBMS? Quali sono i suoi diversi tipi?
 Un Sistema di gestione del database (DBMS ) è un'applicazione software che interagisce con l'utente, le applicazioni e il database stesso per acquisire e analizzare i dati. Un database è una raccolta strutturata di dati.
Un Sistema di gestione del database (DBMS ) è un'applicazione software che interagisce con l'utente, le applicazioni e il database stesso per acquisire e analizzare i dati. Un database è una raccolta strutturata di dati.
Un DBMS consente a un utente di interagire con il database. I dati memorizzati nel database possono essere modificati, recuperati ed eliminati e possono essere di qualsiasi tipo come stringhe, numeri, immagini, ecc.
Esistono due tipi di DBMS:
- Sistema di gestione di database relazionali :I dati sono memorizzati nelle relazioni (tabelle). Esempio:MySQL.
- Sistema di gestione di database non relazionali :Non esiste un concetto di relazioni, tuple e attributi. Esempio – MongoDB
Passiamo alla domanda successiva in queste domande di intervista SQL.
Q4. Cos'è l'RDBMS? In che cosa differisce dal DBMS?
Un sistema di gestione di database relazionali (RDBMS) è un insieme di applicazioni e funzionalità che consentono ai professionisti IT e ad altri di sviluppare, modificare, amministrare e interagire con i database relazionali. La maggior parte dei sistemi di gestione di database relazionali commerciali utilizza SQL (Structured Query Language) per accedere al database, che è archiviato sotto forma di tabelle.
L'RDBMS è il sistema di database più utilizzato nelle aziende di tutto il mondo. Offre un mezzo stabile per archiviare e recuperare enormi quantità di dati.
I database, in generale, contengono raccolte di dati a cui è possibile accedere e utilizzare in altre applicazioni. Lo sviluppo, l'amministrazione e l'uso di piattaforme di database sono tutti supportati da un sistema di gestione di database.
Un sistema di gestione di database relazionali (RDBMS) è un tipo di sistema di gestione di database (DBMS) che archivia i dati in una struttura di tabelle basata su righe che collega i componenti di dati correlati. Un RDBMS contiene funzioni che garantiscono la sicurezza, l'accuratezza, l'integrità e la coerenza dei dati. Questo non è lo stesso dell'archiviazione di file utilizzata da un sistema di gestione del database.
Di seguito sono riportate alcune ulteriori distinzioni tra i sistemi di gestione di database e i sistemi di gestione di database relazionali:
Il numero di utenti a cui è consentito utilizzare il sistema
Un DBMS può gestire un solo utente alla volta, mentre un RDBMS può gestire numerosi utenti.
Specifiche hardware e software
Rispetto a un RDBMS, un DBMS richiede meno software e hardware.
Quantità di informazioni
I DBMS possono gestire qualsiasi quantità di dati, da piccoli a enormi, mentre i DBMS sono limitati a piccole quantità.
La struttura del database
I dati vengono archiviati in un formato gerarchico in un DBMS, mentre un RDBMS utilizza una tabella con intestazioni che fungono da nomi di colonna e righe che contengono i valori associati.
Attuazione del principio ACID
Il concetto di atomicità, coerenza, isolamento e durabilità (ACID) non viene utilizzato dai DBMS per l'archiviazione dei dati. Gli RDBMS, d'altra parte, utilizzano il modello ACID per organizzare i propri dati e garantire la coerenza.
Banche dati distribuite
Un DBMS non fornirà il supporto completo per i database distribuiti, mentre un RDBMS lo farà.
Programmi gestiti
Un DBMS si concentra sulla conservazione dei database presenti all'interno della rete di computer e dei dischi rigidi di sistema, mentre un RDBMS aiuta a gestire le relazioni tra le sue tabelle di dati incorporate.
La normalizzazione dei database è supportata
Un RDBMS può essere normalizzato, ma un DBMS non può essere normalizzato.
Q5. Che cos'è un self-join?
Un self-join è un tipo di join che può essere utilizzato per collegare due tabelle. Di conseguenza, è una relazione unaria. Ogni riga della tabella è collegata a se stessa ea tutte le altre righe della stessa tabella in un self-join. Di conseguenza, un'unione automatica viene utilizzata principalmente per combinare e confrontare righe dalla stessa tabella del database.
Q6. Che cos'è l'istruzione SELECT?
Un comando SELECT ottiene zero o più righe da una o più tabelle o viste del database. Il comando del linguaggio di manipolazione dei dati (DML) più frequente è SELECT nella maggior parte delle applicazioni. Le query SELECT definiscono un set di risultati, ma non come calcolarlo, perché SQL è un linguaggio di programmazione dichiarativo.
Q7. Quali sono alcune clausole comuni utilizzate con la query SELECT in SQL?
Di seguito sono riportate alcune clausole SQL frequenti utilizzate insieme a una query SELECT:
DOVE clausola:in SQL, la clausola WHERE viene utilizzata per filtrare i record richiesti in base a determinati criteri.
ORDINA PER clausola:La clausola ORDER BY in SQL viene utilizzata per ordinare i dati in ordine crescente (ASC) o decrescente (DESC) a seconda dei campi specificati (DESC).
GRUPPO PER clausola:La clausola GROUP BY in SQL viene utilizzata per raggruppare voci con dati identici e può essere utilizzata con metodi di aggregazione per ottenere risultati di database riepilogati.
AVERE La clausola in SQL viene utilizzata per filtrare i record in combinazione con la clausola GROUP BY. È diverso da WHERE, poiché la clausola WHERE non può filtrare i record aggregati.
D8. Cosa sono i comandi UNION, MENO e INTERSETTO?
L'operatore UNION viene utilizzato per combinare i risultati di due tabelle rimuovendo anche le voci duplicate.
L'operatore MENO viene utilizzato per restituire righe dalla prima query ma non dalla seconda query.
L'operatore INTERSECT viene utilizzato per combinare i risultati di entrambe le query in un'unica riga.
Prima di eseguire una delle precedenti istruzioni SQL, è necessario soddisfare determinati requisiti:
All'interno della clausola, ogni query SELECT deve avere la stessa quantità di colonne.
Anche i tipi di dati nelle colonne devono essere confrontabili.
In ogni istruzione SELECT, le colonne devono essere nello stesso ordine.
D9. Cos'è il cursore? Come utilizzare un cursore?
Dopo ogni dichiarazione di variabile, DICHIARA un cursore. Un'istruzione SELECT deve sempre essere accoppiata con la definizione del cursore.
Per avviare il set di risultati, sposta il cursore su di esso. Prima di ottenere righe dal set di risultati, è necessario eseguire l'istruzione OPEN.
Per recuperare e passare alla riga successiva nel set di risultati, utilizzare il comando FETCH.
Per disabilitare il cursore, usa il comando CHIUDI.
Infine, usa il comando DEALLOCATE per rimuovere la definizione del cursore e liberare le risorse ad essa collegate.
Q10. Elenca i diversi tipi di relazioni in SQL.
Ci sono diversi tipi di relazioni nel database:
Uno a uno – Questa è una connessione tra due tabelle in cui ogni record in una tabella corrisponde al massimo di un record nell'altra.
Uno a molti e Molti a uno – Questa è la connessione più frequente, in cui un record in una tabella è collegato a più record in un'altra.
Molti a molti – Viene utilizzato quando si definisce una relazione che richiede diverse istanze su ciascun lato.
Relazioni autoreferenziali – Quando una tabella deve dichiarare una connessione con se stessa, questo è il metodo da utilizzare.
Q12. Che cos'è OLTP?
OLTP, o elaborazione transazionale online, consente a grandi gruppi di persone di eseguire enormi quantità di transazioni di database in tempo reale, di solito tramite Internet. Una transazione di database si verifica quando i dati in un database vengono modificati, inseriti, eliminati o interrogati.
Q13. Quali sono le differenze tra OLTP e OLAP?
OLTP sta per elaborazione delle transazioni online, mentre OLAP sta per elaborazione analitica online. OLTP è un sistema di modifica del database online, mentre OLAP è un sistema di risposta alle query del database online.
Q14. Come creare tabelle vuote con la stessa struttura di un'altra tabella?
Per creare tabelle vuote:
Utilizzando l'operatore INTO per recuperare i record di una tabella in una nuova tabella impostando una clausola WHERE su false per tutte le voci, è possibile creare tabelle vuote con la stessa struttura. Di conseguenza, SQL crea una nuova tabella con una struttura duplicata per accettare le voci recuperate, ma nulla viene memorizzato nella nuova tabella poiché la clausola WHERE è attiva.
Q15. Che cos'è PostgreSQL?
Nel 1986, un team guidato dal professore di informatica Michael Stonebraker ha creato PostgreSQL con il nome di Postgres. È stato creato per aiutare gli sviluppatori nello sviluppo di applicazioni a livello aziendale garantendo l'integrità dei dati e la tolleranza agli errori nei sistemi. PostgreSQL è un sistema di gestione di database a livello aziendale, versatile, resiliente, open source e relazionale a oggetti che supporta carichi di lavoro variabili e utenti simultanei. La comunità internazionale degli sviluppatori lo ha costantemente sostenuto. PostgreSQL ha ottenuto un notevole interesse tra gli sviluppatori grazie alle sue caratteristiche di tolleranza ai guasti.
È un sistema di gestione del database molto affidabile, con oltre due decenni di lavoro della comunità da ringraziare per i suoi alti livelli di resilienza, integrità e precisione. Molte applicazioni online, mobili, geospaziali e di analisi utilizzano PostgreSQL come archivio dati o data warehouse principale.
Q16. Cosa sono i commenti SQL?
I commenti SQL vengono utilizzati per chiarire parti di istruzioni SQL e per impedire l'esecuzione di istruzioni SQL. I commenti sono abbastanza importanti in molti linguaggi di programmazione. I commenti non sono supportati da un database di Microsoft Access. Di conseguenza, il database di Microsoft Access viene utilizzato negli esempi in Mozilla Firefox e Microsoft Edge.
Commenti a riga singola:inizia con due trattini consecutivi (–).
Commenti su più righe:inizia con /* e termina con */.
Q17. Qual è l'utilizzo della funzione NVL()?
È possibile utilizzare la funzione NVL per sostituire i valori nulli con un valore predefinito. La funzione restituisce il valore del secondo parametro se il primo parametro è null. Se il primo parametro è diverso da null, viene lasciato solo.
Questa funzione è utilizzata in Oracle, non in SQL e MySQL. Invece della funzione NVL(), MySQL ha IFNULL() e SQL Server ha la funzione ISNULL().
Passiamo alla domanda successiva in queste domande di intervista SQL.
Q18. Spiegare le funzioni di manipolazione del personaggio? Spiega i suoi diversi tipi in SQL.
Modifica, estrai e modifica la stringa di caratteri utilizzando le routine di manipolazione dei caratteri. La funzione eseguirà la sua azione sulle stringhe di input e restituirà il risultato quando vengono forniti uno o più caratteri e parole.
Le funzioni di manipolazione dei caratteri in SQL sono le seguenti:
A) CONCAT (unione di due o più valori):questa funzione viene utilizzata per unire due o più valori insieme. La seconda stringa viene sempre aggiunta alla fine della prima stringa.
B) SUBSTR:questa funzione restituisce un segmento di una stringa da un determinato punto iniziale a un determinato punto finale.
C) LENGTH:Questa funzione restituisce la lunghezza della stringa in forma numerica, inclusi gli spazi vuoti.
D) INSTR:Questa funzione calcola la posizione numerica precisa di un carattere o di una parola in una stringa.
E) LPAD:per i valori giustificati a destra, restituisce il riempimento del valore del carattere di sinistra.
F) RPAD:per un valore giustificato a sinistra, restituisce il riempimento del valore del carattere di destra.
G) TRIM:questa funzione rimuove tutti i caratteri definiti dall'inizio, dalla fine o da entrambe le estremità di una stringa. Ha anche ridotto la quantità di spazio sprecato.
H) REPLACE:questa funzione sostituisce tutte le istanze di una parola o una sezione di una stringa (sottostringa) con l'altro valore di stringa specificato.
Q19. Scrivi la query SQL per ottenere il terzo stipendio massimo di un dipendente da una tabella denominata dipendenti.
Tabella dei dipendenti
| nome_dipendente | stipendio |
| A | 24000 |
| C | 34000 |
| D | 55000 |
| E | 75000 |
| V | 21000 |
| G | 40000 |
| H | 50000 |
SELEZIONA * DA(
SELECT impiegato_nome, stipendio, DENSE_RANK()
OVER(ORDER BY stipendio DESC)r DA Dipendente)
DOVE r=&n;
Per trovare il 3° stipendio più alto, imposta n =3
Q20. Qual è la differenza tra le funzioni RANK() e DENSE_RANK()?
La funzione RANK() nel set di risultati definisce il rango di ogni riga all'interno della partizione ordinata. Se entrambe le righe hanno lo stesso rango, il numero successivo nella classifica sarà il rango precedente più un numero di duplicati. Se abbiamo tre record al rango 4, ad esempio, il livello successivo indicato è 7.
La funzione DENSE_RANK() assegna un rango distinto a ciascuna riga all'interno di una partizione in base al valore della colonna fornito, senza spazi vuoti. Indica sempre una graduatoria in ordine di precedenza. Questa funzione assegnerà lo stesso rango alle due righe se hanno lo stesso rango, con il rango successivo il numero consecutivo successivo. Se abbiamo tre record al rango 4, ad esempio, il livello successivo indicato è 5.
Q21. Cosa sono le tabelle e i campi?
Una tabella è una raccolta di componenti di dati organizzati in righe e colonne in un database relazionale. Una tabella può anche essere pensata come un'utile rappresentazione delle relazioni. La forma più semplice di archiviazione dei dati è la tabella. Di seguito viene mostrato un esempio di tabella Dipendente.
| ID | Nome | Dipartimento | Stipendio |
| 1 | Rahul | Vendite | 24000 |
| 2 | Rohini | Marketing | 34000 |
| 3 | Shylesh | Vendite | 24000 |
| 4 | Tarun | Analisi | 30000 |
Un record o una riga è una singola voce in una tabella. In una tabella, un record rappresenta una raccolta di dati connessi. La tabella Dipendente, ad esempio, ha quattro record.
Una tabella è composta da numerosi record (righe), ognuno dei quali può essere suddiviso in unità più piccole denominate Campi (colonne). ID, Nome, Dipartimento e Stipendio sono i quattro campi nella tabella Dipendente sopra.
Q22. Che cos'è un vincolo UNICO?
Il vincolo UNIQUE impedisce la visualizzazione di valori identici in una colonna in due record. Il vincolo UNIQUE garantisce che ogni valore in una colonna sia unico.
Q23. Che cos'è un self-join?
Un self-join è un tipo di join che può essere utilizzato per collegare due tabelle. Di conseguenza, è una relazione unaria. Ogni riga della tabella è collegata a se stessa ea tutte le altre righe della stessa tabella in un self-join. Di conseguenza, un'unione automatica viene utilizzata principalmente per combinare e confrontare righe dalla stessa tabella del database.
Q24. Che cos'è l'istruzione SELECT?
Un comando SELECT ottiene zero o più righe da una o più tabelle o viste del database. Il comando del linguaggio di manipolazione dei dati (DML) più frequente è SELECT nella maggior parte delle applicazioni. Le query SELECT definiscono un set di risultati, ma non come calcolarlo, perché SQL è un linguaggio di programmazione dichiarativo.
Q25. Quali sono alcune clausole comuni utilizzate con la query SELECT in SQL?
Di seguito sono riportate alcune clausole SQL frequenti utilizzate insieme a una query SELECT:
Clausola WHERE:in SQL, la clausola WHERE viene utilizzata per filtrare i record richiesti in base a determinati criteri.
Clausola ORDER BY:la clausola ORDER BY in SQL viene utilizzata per ordinare i dati in ordine crescente (ASC) o decrescente (DESC) a seconda dei campi specificati (DESC).
Clausola GROUP BY:la clausola GROUP BY in SQL viene utilizzata per raggruppare voci con dati identici e può essere utilizzata con metodi di aggregazione per ottenere risultati di database riepilogati.
La clausola HAVING in SQL viene utilizzata per filtrare i record in combinazione con la clausola GROUP BY. È diverso da WHERE, poiché la clausola WHERE non può filtrare i record aggregati.
Q26. Cosa sono i comandi UNION, MENO e INTERSETTO?
L'operatore UNION viene utilizzato per combinare i risultati di due tabelle rimuovendo anche le voci duplicate.
L'operatore MENO viene utilizzato per restituire righe dalla prima query ma non dalla seconda query.
L'operatore INTERSECT viene utilizzato per combinare i risultati di entrambe le query in un'unica riga.
Prima di eseguire una delle precedenti istruzioni SQL, è necessario soddisfare determinati requisiti –
All'interno della clausola, ogni query SELECT deve avere la stessa quantità di colonne.
Anche i tipi di dati nelle colonne devono essere confrontabili.
In ogni istruzione SELECT, le colonne devono essere nello stesso ordine.
Passiamo alla domanda successiva in queste domande di intervista SQL.
Q27. Cos'è il cursore? Come utilizzare un cursore?
Dopo ogni dichiarazione di variabile, DICHIARA un cursore. Un'istruzione SELECT deve sempre essere accoppiata con la definizione del cursore.
Per avviare il set di risultati, sposta il cursore su di esso. Prima di ottenere righe dal set di risultati, è necessario eseguire l'istruzione OPEN.
Per recuperare e passare alla riga successiva nel set di risultati, utilizzare il comando FETCH.
Per disabilitare il cursore, usa il comando CHIUDI.
Infine, usa il comando DEALLOCATE per rimuovere la definizione del cursore e liberare le risorse ad essa collegate.
Q28. Elenca i diversi tipi di relazioni in SQL.
Esistono diversi tipi di relazioni nel database:
One-to-One – Questa è una connessione tra due tabelle in cui ogni record in una tabella corrisponde al massimo di un record nell'altra.
Uno a molti e Molti a uno:questa è la connessione più frequente, in cui un record in una tabella è collegato a più record in un'altra.
Molti-a-molti:viene utilizzato quando si definisce una relazione che richiede diverse istanze su ciascun lato.
Relazioni autoreferenziali:quando una tabella deve dichiarare una connessione con se stessa, questo è il metodo da utilizzare.
Q29. Che cos'è l'esempio SQL?
SQL è un linguaggio di query del database che consente di modificare, rimuovere e richiedere dati dai database. Le seguenti istruzioni sono alcuni esempi di istruzioni SQL:
- SELEZIONARE
- INSERIRE
- AGGIORNAMENTO
- CANCELLA
- CREA DATABASE
- ALTER DATABASE
Q30. Quali sono le competenze SQL di base?
Le competenze SQL aiutano gli analisti di dati nella creazione, manutenzione e recupero dei dati dai database relazionali, che dividono i dati in colonne e righe. Consente inoltre agli utenti di recuperare, aggiornare, manipolare, inserire e modificare i dati in modo efficiente.
Le abilità più fondamentali che un esperto di SQL dovrebbe possedere sono:
- Gestione database
- Struttura di un database
- Creazione di clausole e istruzioni SQL
- Competenze di sistema SQL come MYSQL, PostgreSQL
- L'esperienza PHP è utile.
- Analizza dati SQL
- Utilizzare WAMP con SQL per creare un database
- Competenze OLAP
Q31. Che cos'è lo schema in SQL Server?
Uno schema è una rappresentazione visiva del database che è logica. Costruisce e specifica le relazioni tra le numerose entità del database. Si riferisce ai diversi tipi di vincoli che possono essere applicati a un database. Descrive anche i vari tipi di dati. Può essere utilizzato anche su tabelle e viste.
Gli schemi sono disponibili in una varietà di forme e dimensioni. Lo schema a stella e lo schema Snowflake sono due dei più popolari. Le entità in uno schema a stella sono rappresentate a forma di stella, mentre quelle in uno schema a fiocco di neve sono mostrate a forma di fiocco di neve.
Qualsiasi architettura di database è costruita sulla base di schemi.
T32. Come creare una tabella temporanea in SQL Server?
Le tabelle temporanee vengono create in TempDB e vengono cancellate automaticamente dopo la chiusura dell'ultima connessione. Possiamo utilizzare le tabelle temporanee per archiviare ed elaborare i risultati provvisori. Quando abbiamo bisogno di archiviare dati temporanei, le tabelle temporanee tornano utili.
La seguente è la sintassi per la creazione di una tabella temporanea:
CREATE TABLE #Employee (id INT, nome VARCHAR(25))
INSERT IN #Employee VALUES (01, 'Ashish'), (02, 'Atul')
Passiamo alla domanda successiva in queste domande di intervista SQL.
T33. Come installare SQL Server in Windows 11?
Installa SQL Server Management Studio in Windows 11
Passaggio 1: Fai clic su SSMS, che ti porterà alla pagina di SQL Server Management Studio.
Passaggio 2: Inoltre, fare clic sul collegamento SQL Server Management Studio e toccare Salva file.
Passaggio 3: Salva questo file sul tuo disco locale e vai alla cartella.
Passaggio 4: Apparirà la finestra di configurazione e qui puoi scegliere la posizione in cui vuoi salvare il file.
Passaggio 5: Fare clic su Installa.
Passaggio 6: Chiudere la finestra al termine dell'installazione.
Passaggio 7: Inoltre, torna al menu Start e cerca SQL Server Management Studio.
Passaggio 8: Inoltre, fai doppio clic su di esso e la pagina di accesso apparirà una volta visualizzata.
Passaggio 9: Dovresti essere in grado di vedere il nome del tuo server. Tuttavia, se non è visibile, fai clic sulla freccia a discesa sul server e tocca Sfoglia.
Passaggio 10: Scegli il tuo server SQL e fai clic su Connetti.
Successivamente, il server SQL si connetterà e Windows 11 funzionerà correttamente.
Q34. Qual è il caso in SQL Server?
L'istruzione CASE viene utilizzata per costruire una logica in cui il valore di una colonna è determinato dai valori di altre colonne.
Almeno un set di comandi WHEN e THEN costituisce l'istruzione CASE di SQL Server. La condizione da testare è specificata dall'istruzione WHEN. Se la condizione WHEN restituisce VERO, la frase THEN spiega cosa fare.
Quando nessuna delle condizioni WHEN restituisce true, viene eseguita l'istruzione ELSE. La parola chiave END conclude l'istruzione CASE.
CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 WHEN conditionN THEN resultN ELSE result END;
T35. NoSQL vs SQL
In sintesi, le cinque principali distinzioni tra SQL e NoSQL sono le seguenti:
I database relazionali sono SQL, mentre i database non relazionali sono NoSQL.
I database SQL hanno uno schema specifico e utilizzano un linguaggio di query strutturato. Per i dati non strutturati, i database NoSQL utilizzano schemi dinamici.
I database SQL vengono ridimensionati verticalmente, ma i database NoSQL vengono ridimensionati orizzontalmente.
I database NoSQL sono archivi di documenti, valori-chiave, grafici o colonne larghe, mentre i database SQL sono basati su tabelle.
I database SQL eccellono nelle transazioni multiriga, mentre NoSQL eccelle nei dati non strutturati come documenti e JSON.
Q36. Qual è la differenza tra NOW() e CURRENT_DATE()?
NOW() restituisce un tempo costante che indica l'ora in cui l'istruzione ha iniziato a essere eseguita. (All'interno di una funzione o di un trigger memorizzato, NOW() restituisce l'ora in cui la funzione o l'istruzione di attivazione ha iniziato a essere eseguita.
La semplice differenza tra NOW() e CURRENT_DATE() è che NOW() recupererà la data e l'ora correnti sia nel formato "YYYY-MM_DD HH:MM:SS" mentre CURRENT_DATE() recupererà la data del giorno corrente "YYYY -MM_GG'.
Passiamo alla domanda successiva in queste domande di intervista SQL.
Q37. Che cos'è BLOB e TEXT in MySQL?
BLOB sta per Binary Huge Objects e può essere utilizzato per archiviare dati binari, mentre TEXT può essere utilizzato per archiviare un numero elevato di stringhe. BLOB può essere utilizzato per archiviare dati binari, che includono immagini, filmati, audio e applicazioni.
I valori BLOB funzionano in modo simile alle stringhe di byte e mancano di un set di caratteri. Di conseguenza, i valori numerici dei byte dipendono completamente dal confronto e dall'ordinamento.
I valori TEXT si comportano in modo simile a una stringa di caratteri oa una stringa non binaria. Il confronto/l'ordinamento di TESTO dipende completamente dalla raccolta del set di caratteri.
Q38. Come rimuovere le righe duplicate in SQL?
Se la tabella SQL ha righe duplicate, le righe duplicate devono essere rimosse.
Assumiamo la seguente tabella come nostro set di dati:
| ID | Nome | Età |
| 1 | A | 21 |
| 2 | B | 23 |
| 2 | B | 23 |
| 4 | D | 22 |
| 5 | E | 25 |
| 6 | G | 26 |
| 5 | E | 25 |
La seguente query SQL rimuove gli ID duplicati dalla tabella:
CANCELLA DA tabella WHERE ID IN (
SELEZIONARE
ID, COUNT(ID)
DA tavolo
GRUPPO PER ID
AVENDO
CONTEGGIO (ID)> 1);
Q39. Come creare una stored procedure utilizzando SQL Server?
Una stored procedure è un pezzo di codice SQL preparato che puoi salvare e riutilizzare ancora e ancora.
Quindi, se hai una query SQL che crei frequentemente, salvala come stored procedure e quindi chiamala per eseguirla.
Puoi anche fornire parametri a una procedura memorizzata in modo che possa agire in base ai valori dei parametri forniti.
Sintassi della procedura memorizzata
CREA PROCEDURA nome_procedura
COME
istruzione_sql
VAI;
Eseguire una procedura memorizzata
EXEC nome_procedura;
Q40. Che cos'è il test della scatola nera del database?
Black Box Testing è un approccio di test del software che prevede il test delle funzioni delle applicazioni software senza conoscere la struttura del codice interno, i dettagli di implementazione o i percorsi interni. Black Box Testing è un tipo di test del software che si concentra sull'input e sull'output delle applicazioni software ed è totalmente guidato dai requisiti e dalle specifiche del software. Test comportamentale è un altro nome per questo.
Q41. Quali sono i diversi tipi di sandbox SQL?
SQL Sandbox è un ambiente protetto all'interno di SQL Server in cui è possibile eseguire programmi non attendibili. Esistono tre diversi tipi di sandbox SQL:
Safe Access Sandbox:in questo ambiente, un utente può eseguire attività SQL come la creazione di stored procedure, trigger e così via, ma non può accedere alla memoria o creare file.
Sandbox per l'accesso esterno:gli utenti possono accedere ai file senza avere la possibilità di alterare l'allocazione della memoria.
Sandbox di accesso non sicuro:contiene codice non affidabile che consente a un utente di accedere alla memoria.
Passiamo alla domanda successiva in queste domande di intervista SQL.
Q42. Dove è archiviata la tabella MyISAM?
Prima dell'introduzione di MySQL 5.5 nel dicembre 2009, MyISAM era il motore di archiviazione predefinito per le versioni del sistema di gestione dei database relazionali MySQL. Si basa sul vecchio codice ISAM, ma include molte funzionalità extra. Ogni tabella MyISAM è divisa in tre file su disco (se non è partizionato). I nomi dei file iniziano con il nome della tabella e terminano con un'estensione che indica il tipo di file. La definizione della tabella è memorizzata in un file.frm, tuttavia questo file non fa parte del motore MyISAM; invece, fa parte del server. Il suffisso del file di dati è.MYD (MYData). L'estensione del file di indice è.MYI (MYIndex). Se perdi il file di indice, puoi sempre ripristinarlo ricreando gli indici.
Q43. Come trovare l'ennesimo stipendio più alto in SQL?
La domanda più tipica dell'intervista è trovare l'ennesima paga più alta in una tabella. Questo lavoro può essere eseguito utilizzando la funzione denso rank().
Tabella dei dipendenti
| nome_dipendente | stipendio |
| A | 24000 |
| C | 34000 |
| D | 55000 |
| E | 75000 |
| V | 21000 |
| G | 40000 |
| H | 50000 |
SELEZIONA * DA(
SELECT impiegato_nome, stipendio, DENSE_RANK()
OVER(ORDER BY stipendio DESC)r DA Dipendente)
DOVE r=&n;
Per trovare il secondo stipendio più alto, impostare n =2
Per trovare il 3° stipendio più alto, imposta n =3 e così via.
Q44. Cosa intendi per tabella e campo in SQL?
Una tabella si riferisce a una raccolta di dati in modo organizzato sotto forma di righe e colonne. Un campo si riferisce al numero di colonne in una tabella. Ad esempio:
Tabella :Informazioni sullo studente
Campo :Stu Id, Stu Nome, Stu Marks
Q45. Cosa sono i join in SQL?
Una clausola JOIN viene utilizzata per combinare righe di due o più tabelle, in base a una colonna correlata tra di loro. Viene utilizzato per unire due tabelle o recuperare dati da lì. Esistono 4 tipi di join, come puoi fare riferimento di seguito:
- Inner join: Inner Join in SQL is the most common type of join. It is used to return all the rows from multiple tables where the join condition is satisfied.
Left Join: Left Join in SQL is used to return all the rows from the left table but only the matching rows from the right table where the join condition is fulfilled.
Right Join: Right Join in SQL is used to return all the rows from the right table but only the matching rows from the left table where the join condition is fulfilled.
Full Join: Full join returns all the records when there is a match in any of the tables. Therefore, it returns all the rows from the left-hand side table and all the rows from the right-hand side table.
Let’s move to the next question in this SQL Interview Questions.
Q46. What is the difference between CHAR and VARCHAR2 datatype in SQL?
Both Char and Varchar2 are used for characters datatype but varchar2 is used for character strings of variable length whereas Char is used for strings of fixed length. For example, char(10) can only store 10 characters and will not be able to store a string of any other length whereas varchar2(10) can store any length i.e 6,8,2 in this variable.
Q47. What is a Primary key?
- A Primary key in SQL is a column (or collection of columns) or a set of columns that uniquely identifies each row in the table.
- Uniquely identifies a single row in the table
- Null values not allowed
Example- In the Student table, Stu_ID is the primary key.
Q48. What are Constraints?
Constraints in SQL are used to specify the limit on the data type of the table. It can be specified while creating or altering the table statement. The sample of constraints are:
- NOT NULL
- CHECK
- DEFAULT
- UNIQUE
- PRIMARY KEY
- FOREIGN KEY
Q49. What is the difference between DELETE and TRUNCATE statements?
| DELETE | TRUNCATE |
| Delete command is used to delete a row in a table. | Truncate is used to delete all the rows from a table. |
| You can rollback data after using delete statement. | You cannot rollback data. |
| It is a DML command. | It is a DDL command. |
| It is slower than truncate statement. | It is faster. |
Q50. What is a Unique key?
- Uniquely identifies a single row in the table.
- Multiple values allowed per table.
- Null values allowed.
Apart from this SQL Interview Questions blog, if you want to get trained from professionals on this technology, you can opt for structured training from edureka!
Q51. What is a Foreign key in SQL?
- Foreign key maintains referential integrity by enforcing a link between the data in two tables.
- The foreign key in the child table references the primary key in the parent table.
- The foreign key constraint prevents actions that would destroy links between the child and parent tables.
Q52. What do you mean by data integrity?
Data Integrity defines the accuracy as well as the consistency of the data stored in a database. It also defines integrity constraints to enforce business rules on the data when it is entered into an application or a database.
Q53. What is the difference between clustered and non-clustered index in SQL?
The differences between the clustered and non clustered index in SQL are :
- Clustered index is used for easy retrieval of data from the database and its faster whereas reading from non clustered index is relatively slower.
- Clustered index alters the way records are stored in a database as it sorts out rows by the column which is set to be clustered index whereas in a non clustered index, it does not alter the way it was stored but it creates a separate object within a table which points back to the original table rows after searching.
One table can only have one clustered index whereas it can have many non clustered index.
Q54. Write a SQL query to display the current date?
In SQL, there is a built-in function called GetDate() which helps to return the current timestamp/date.
Q55. What do you understand by query optimization?
The phase that identifies a plan for evaluation query which has the least estimated cost is known as query optimization.
The advantages of query optimization are as follows:
- The output is provided faster
- A larger number of queries can be executed in less time
- Reduces time and space complexity
Q56. What do you mean by Denormalization?
Denormalization refers to a technique which is used to access data from higher to lower forms of a database. It helps the database managers to increase the performance of the entire infrastructure as it introduces redundancy into a table. It adds the redundant data into a table by incorporating database queries that combine data from various tables into a single table.
Q57. What are Entities and Relationships?
Entities :A person, place, or thing in the real world about which data can be stored in a database. Tables store data that represents one type of entity. For example – A bank database has a customer table to store customer information. The customer table stores this information as a set of attributes (columns within the table) for each customer.
Relationships :Relation or links between entities that have something to do with each other. For example – The customer name is related to the customer account number and contact information, which might be in the same table. There can also be relationships between separate tables (for example, customer to accounts).
Let’s move to the next question in this SQL Interview Questions.
Q58. What is an Index?
An index refers to a performance tuning method of allowing faster retrieval of records from the table. An index creates an entry for each value and hence it will be faster to retrieve data.
Q59 . Explain different types of index in SQL.
There are three types of index in SQL namely:
Unique Index:
This index does not allow the field to have duplicate values if the column is unique indexed. If a primary key is defined, a unique index can be applied automatically.
Clustered Index:
This index reorders the physical order of the table and searches based on the basis of key values. Each table can only have one clustered index.
Non-Clustered Index:
Non-Clustered Index does not alter the physical order of the table and maintains a logical order of the data. Each table can have many nonclustered indexes.
Q60. What is Normalization and what are the advantages of it?
Normalization in SQL is the process of organizing data to avoid duplication and redundancy. Some of the advantages are:
- Better Database organization
- More Tables with smaller rows
- Efficient data access
- Greater Flexibility for Queries
- Quickly find the information
- Easier to implement Security
- Allows easy modification
- Reduction of redundant and duplicate data
- More Compact Database
- Ensure Consistent data after modification
Apart from this SQL Interview Questions Blog, if you want to get trained from professionals on this technology, you can opt for structured training from edureka!
Q61. What is the difference between DROP and TRUNCATE commands?
DROP command removes a table and it cannot be rolled back from the database whereas TRUNCATE command removes all the rows from the table.
Q62. Explain different types of Normalization.
There are many successive levels of normalization. These are called normal forms . Each consecutive normal form depends on the previous one.The first three normal forms are usually adequate.
Normal Forms are used in database tables to remove or decrease duplication. The following are the many forms:
First Normal Form:
When every attribute in a relation is a single-valued attribute, it is said to be in first normal form. The first normal form is broken when a relation has a composite or multi-valued property.
Second Normal Form:
A relation is in second normal form if it meets the first normal form’s requirements and does not contain any partial dependencies. In 2NF, a relation has no partial dependence, which means it has no non-prime attribute that is dependent on any suitable subset of any table candidate key. Often, the problem may be solved by setting a single column Primary Key.
Third Normal Form:
If a relation meets the requirements for the second normal form and there is no transitive dependency, it is said to be in the third normal form.
Q63. What is OLTP?
OLTP, or online transactional processing, allows huge groups of people to execute massive amounts of database transactions in real time, usually via the internet. A database transaction occurs when data in a database is changed, inserted, deleted, or queried.
What are the differences between OLTP and OLAP?
OLTP stands for online transaction processing, whereas OLAP stands for online analytical processing. OLTP is an online database modification system, whereas OLAP is an online database query response system.
Q64. How to create empty tables with the same structure as another table?
To create empty tables:
Using the INTO operator to fetch the records of one table into a new table while setting a WHERE clause to false for all entries, it is possible to create empty tables with the same structure. As a result, SQL creates a new table with a duplicate structure to accept the fetched entries, but nothing is stored into the new table since the WHERE clause is active.
Q65. What is PostgreSQL?
In 1986, a team lead by Computer Science Professor Michael Stonebraker created PostgreSQL under the name Postgres. It was created to aid developers in the development of enterprise-level applications by ensuring data integrity and fault tolerance in systems. PostgreSQL is an enterprise-level, versatile, resilient, open-source, object-relational database management system that supports variable workloads and concurrent users. The international developer community has constantly backed it. PostgreSQL has achieved significant appeal among developers because to its fault-tolerant characteristics.
It’s a very reliable database management system, with more than two decades of community work to thank for its high levels of resiliency, integrity, and accuracy. Many online, mobile, geospatial, and analytics applications utilise PostgreSQL as their primary data storage or data warehouse.
Q66. What are SQL comments?
SQL Comments are used to clarify portions of SQL statements and to prevent SQL statements from being executed. Comments are quite important in many programming languages. The comments are not supported by a Microsoft Access database. As a result, the Microsoft Access database is used in the examples in Mozilla Firefox and Microsoft Edge.
Single Line Comments:It starts with two consecutive hyphens (–).
Multi-line Comments:It starts with /* and ends with */.
Let’s move to the next question in this SQL Interview Questions.
Q67. What is the difference between the RANK() and DENSE_RANK() functions?
The RANK() function in the result set defines the rank of each row within your ordered partition. If both rows have the same rank, the next number in the ranking will be the previous rank plus a number of duplicates. If we have three records at rank 4, for example, the next level indicated is 7.
The DENSE_RANK() function assigns a distinct rank to each row within a partition based on the provided column value, with no gaps. It always indicates a ranking in order of precedence. This function will assign the same rank to the two rows if they have the same rank, with the next rank being the next consecutive number. If we have three records at rank 4, for example, the next level indicated is 5.
Q68. What is SQL Injection?
SQL injection is a sort of flaw in website and web app code that allows attackers to take control of back-end processes and access, retrieve, and delete sensitive data stored in databases. In this approach, malicious SQL statements are entered into a database entry field, and the database becomes exposed to an attacker once they are executed. By utilising data-driven apps, this strategy is widely utilised to get access to sensitive data and execute administrative tasks on databases. SQLi attack is another name for it.
The following are some examples of SQL injection:
- Getting access to secret data in order to change a SQL query to acquire the desired results.
- UNION attacks are designed to steal data from several database tables.
- Examine the database to get information about the database’s version and structure
Q69. How many Aggregate functions are available in SQL?
SQL aggregate functions provide information about a database’s data. AVG, for example, returns the average of a database column’s values.
SQL provides seven (7) aggregate functions, which are given below:
AVG():returns the average value from specified columns.
COUNT():returns the number of table rows, including rows with null values.
MAX():returns the largest value among the group.
MIN():returns the smallest value among the group.
SUM():returns the total summed values(non-null) of the specified column.
FIRST():returns the first value of an expression.
LAST():returns the last value of an expression.
Q70. What is the default ordering of data using the ORDER BY clause? How could it be changed?
The ORDER BY clause in MySQL can be used without the ASC or DESC modifiers. The sort order is preset to ASC or ascending order when this attribute is absent from the ORDER BY clause.
Q71. How do we use the DISTINCT statement? What is its use?
The SQL DISTINCT keyword is combined with the SELECT query to remove all duplicate records and return only unique records. There may be times when a table has several duplicate records.
The DISTINCT clause in SQL is used to eliminate duplicates from a SELECT statement’s result set.
Q72. What are the syntax and use of the COALESCE function?
From a succession of expressions, the COALESCE function returns the first non-NULL value. The expressions are evaluated in the order that they are supplied, and the function’s result is the first non-null value. Only if all of the inputs are null does the COALESCE method return NULL.
The syntax of COALESCE function is COALESCE (exp1, exp2, …. expn)
Q73. What is the ACID property in a database?
ACID stands for Atomicity, Consistency, Isolation, Durability. It is used to ensure that the data transactions are processed reliably in a database system.
- Atomicity: Atomicity refers to the transactions that are completely done or failed where transaction refers to a single logical operation of a data. It means if one part of any transaction fails, the entire transaction fails and the database state is left unchanged.
- Consistency: Consistency ensures that the data must meet all the validation rules. In simple words, you can say that your transaction never leaves the database without completing its state.
- Isolation: The main goal of isolation is concurrency control.
- Durability: Durability means that if a transaction has been committed, it will occur whatever may come in between such as power loss, crash or any sort of error.
Top 10 Technologies to Learn in 2022 | Edureka
Q74. What do you mean by “Trigger” in SQL?
Trigger in SQL is are a special type of stored procedures that are defined to execute automatically in place or after data modifications. It allows you to execute a batch of code when an insert, update or any other query is executed against a specific table.
Q75. What are the different operators available in SQL?
There are three operators available in SQL, namely:
- Operatori aritmetici
- Operatori logici
- Operatori di confronto
Apart from this SQL Interview Questions blog, if you want to get trained from professionals on this technology, you can opt for structured training from edureka!
Q76. Are NULL values same as that of zero or a blank space?
A NULL value is not at all same as that of zero or a blank space. NULL value represents a value which is unavailable, unknown, assigned or not applicable whereas a zero is a number and blank space is a character.
Q77. What is the difference between cross join and natural join?
The cross join produces the cross product or Cartesian product of two tables whereas the natural join is based on all the columns having the same name and data types in both the tables.
Q78. What is subquery in SQL?
A subquery is a query inside another query where a query is defined to retrieve data or information back from the database. In a subquery, the outer query is called as the main query whereas the inner query is called subquery. Subqueries are always executed first and the result of the subquery is passed on to the main query. It can be nested inside a SELECT, UPDATE or any other query. A subquery can also use any comparison operators such as>, There are two types of subquery namely, Correlated and Non-Correlated. Correlated subquery :These are queries which select the data from a table referenced in the outer query. It is not considered as an independent query as it refers to another table and refers the column in a table. Non-Correlated subquery :This query is an independent query where the output of subquery is substituted in the main query.
Let’s move to the next question in this SQL Interview Questions. To count the number of records in a table in SQL, you can use the below commands: Apart from this SQL Interview Questions Blog, if you want to get trained from professionals on this technology, you can opt for structured training from edureka!
To display name of the employees that begin with ‘A’, type in the below command: Group functions work on the set of rows and return one result per group. Some of the commonly used group functions are:AVG, COUNT, MAX, MIN, SUM, VARIANCE. Relation or links are between entities that have something to do with each other. Relationships are defined as the connection between the tables in a database. There are various relationships, namely: NULL values in SQL can be inserted in the following ways: BETWEEN operator is used to display rows based on a range of values in a row whereas the IN condition operator is used to check for values contained in a specific set of values. SQL functions are used for the following purposes: This statement allows conditional update or insertion of data into a table. It performs an UPDATE if a row exists, or an INSERT if the row does not exist. Recursive stored procedure refers to a stored procedure which calls by itself until it reaches some boundary condition. This recursive function or procedure helps the programmers to use the same set of code n number of times. SQL clause helps to limit the result set by providing a condition to the query. A clause helps to filter the rows from the entire set of records. For example – WHERE, HAVING clause. Apart from this SQL Interview Questions Blog, if you want to get trained from professionals on this technology, you can opt for a structured training from edureka! Click below to know more. HAVING clause can be used only with SELECT statement. It is usually used in a GROUP BY clause and whenever GROUP BY is not used, HAVING behaves like a WHERE clause. Following are the ways in which dynamic SQL can be executed: Constraints are the representation of a column to enforce data entity and consistency. There are two levels of a constraint, namely: You can fetch common records from two tables using INTERSECT. For example:
There are three case manipulation functions in SQL, namely: Apart from this SQL Interview Questions blog, if you want to get trained from professionals on this technology, you can opt for a structured training from edureka! Click below to know more. Some of the available set operators are – Union, Intersect or Minus operators. ALIAS command in SQL is the name that can be given to any table or a column. This alias name can be referred in WHERE clause to identify a particular table or a column. For example- In the above example, emp refers to alias name for employee table and dept refers to alias name for department table.
Let’s move to the next question in this SQL Interview Questions. Aggregate functions are used to evaluate mathematical calculation and returns a single value. These calculations are done from the columns in a table. For example- max(),count() are calculated with respect to numeric. Scalar functions return a single value based on the input value. For example – UCASE(), NOW() are calculated with respect to string.
Let’s move to the next question in this SQL Interview Questions. You can fetch alternate records i.e both odd and even row numbers. For example- To display even numbers, use the following command:
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=0 Now, to display odd numbers: LIKE operator is used for pattern matching, and it can be used as -. For example- select * from students where studentname like ‘a%’ _ (Underscore) – it matches exactly one character. Apart from this SQL Interview Questions Blog, if you want to get trained from professionals on this technology, you can opt for structured training from edureka! You can select unique records from a table by using the DISTINCT keyword. Using this command, it will print unique student id from the table Student. There are a lot of ways to fetch characters from a string. For example: Select SUBSTRING(StudentName,1,5) as studentname from student SQL is a query language that allows you to issue a single query or execute a single insert/update/delete whereas PL/SQL is Oracle’s “Procedural Language” SQL, which allows you to write a full program (loops, variables, etc.) to accomplish multiple operations such as selects/inserts/updates/deletes. A view is a virtual table which consists of a subset of data contained in a table. Since views are not present, it takes less space to store. View can have data of one or more tables combined and it depends on the relationship.
Let’s move to the next question in this SQL Interview Questions. A view refers to a logical snapshot based on a table or another view. It is used for the following reasons: A Stored Procedure is a function which consists of many SQL statements to access the database system. Several SQL statements are consolidated into a stored procedure and execute them whenever and wherever required which saves time and avoid writing code again and again. A Stored Procedure can be used as a modular programming which means create once, store and call for several times whenever it is required. This supports faster execution. It also reduces network traffic and provides better security to the data. The only disadvantage of Stored Procedure is that it can be executed only in the database and utilizes more memory in the database server. There are three types of user-defined functions, namely: Scalar returns the unit, variant defined the return clause. Other two types of defined functions return table.
Let’s move to the next question in this SQL Interview Questions. Collation is defined as a set of rules that determine how data can be sorted as well as compared. Character data is sorted using the rules that define the correct character sequence along with options for specifying case-sensitivity, character width etc.
Let’s move to the next question in this SQL Interview Questions. Following are the different types of collation sensitivity: Apart from this SQL Interview Questions Blog, if you want to get trained from professionals on this technology, you can opt for structured training from edureka! These variables can be used or exist only inside the function. These variables are not used or referred by any other function. These variables are the variables which can be accessed throughout the program. Global variables cannot be created whenever that function is called. Autoincrement keyword allows the user to create a unique number to get generated whenever a new record is inserted into the table. AUTO INCREMENT keyword can be used in Oracle and IDENTITY keyword can be used in SQL SERVER. Datawarehouse refers to a central repository of data where the data is assembled from multiple sources of information. Those data are consolidated, transformed and made available for the mining as well as online processing. Warehouse data also have a subset of data called Data Marts. Windows mode and Mixed Mode – SQL and Windows. You can go to the below steps to change authentication mode in SQL Server:
So this brings us to the end of the SQL interview questions blog. I hope this set of SQL Interview Questions will help you ace your job interview. All the best for your interview! Apart from this SQL Interview Questions Blog, if you want to get trained from professionals on SQL, you can opt for a structured training from edureka! Click below to know more. Check out this MySQL DBA Certification Training by Edureka, a trusted online learning company with a network di di oltre 250.000 studenti soddisfatti sparsi in tutto il mondo. Questo corso ti insegna i concetti fondamentali e gli strumenti e le tecniche avanzati per gestire i dati e amministrare il database MySQL. It includes hands-on learning on concepts like MySQL Workbench, MySQL Server, Data Modeling, MySQL Connector, Database Design, MySQL Command line, MySQL Functions etc. End of the training you will be able to create and administer your own MySQL Database and manage data. Hai una domanda per noi? Please mention it in the comments section of this “ SQL Interview Questions” blog and we will get back to you as soon as possible. Q79. What are the different types of a subquery?
Q80. List the ways to get the count of records in a table?
SELECT * FROM table1
SELECT COUNT(*) FROM table1
SELECT rows FROM sysindexes WHERE id = OBJECT_ID(table1) AND indid < 2
Q81. Write a SQL query to find the names of employees that begin with ‘A’?
SELECT * FROM Table_name WHERE EmpName like 'A%'
Q82. Write a SQL query to get the third-highest salary of an employee from employee_table?
SELECT TOP 1 salary
FROM(
SELECT TOP 3 salary
FROM employee_table
ORDER BY salary DESC) AS emp
ORDER BY salary ASC;
Q83. What is the need for group functions in SQL?
Q84. What is a Relationship and what are they?
Q85. How can you insert NULL values in a column while inserting the data?
Q86. What is the main difference between ‘BETWEEN’ and ‘IN’ condition operators?
Example of BETWEEN:
SELECT * FROM Students where ROLL_NO BETWEEN 10 AND 50;
Example of IN: SELECT * FROM students where ROLL_NO IN (8,15,25);
Q87. Why are SQL functions used?
Q88. What is the need for MERGE statement?
Q89. What do you mean by recursive stored procedure?
Q90. What is CLAUSE in SQL?
Q91. What is the difference between ‘HAVING’ CLAUSE and a ‘WHERE’ CLAUSE?
Having Clause is only used with the GROUP BY function in a query whereas WHERE Clause is applied to each row before they are a part of the GROUP BY function in a query.Q92. List the ways in which Dynamic SQL can be executed?
Q93. What are the various levels of constraints?
Q94. How can you fetch common records from two tables?
Select studentID from student. INTERSECT Select StudentID from ExamQ95. List some case manipulation functions in SQL?
LOWER(‘string’)
UPPER(‘string’)
INITCAP(‘string’)
Q96. What are the different set operators available in SQL?
Q97. What is an ALIAS command?
Select emp.empID, dept.Result from employee emp, department as dept where emp.empID=dept.empID
Q98. What are aggregate and scalar functions?
Q99. How can you fetch alternate records from a table?
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=1
Q100. Name the operator which is used in the query for pattern matching?
For example- select * from student where studentname like ‘abc_’Q101. How can you select unique records from a table?
Select DISTINCT studentID from Student
Q102. How can you fetch first 5 characters of the string?
Q103 . What is the main difference between SQL and PL/SQL?
Q104. What is a View?
Q105. What are Views used for?
Q106. What is a Stored Procedure?
Q107. List some advantages and disadvantages of Stored Procedure?
Advantages :
Disadvantage :
Q108. List all the types of user-defined functions?
Q109. What do you mean by Collation?
Q110. What are the different types of Collation Sensitivity?
Q111. What are Local and Global variables?
Local variables:
Global variables:
Q112. What is Auto Increment in SQL?
This keyword is usually required whenever PRIMARY KEY in SQL is used.Q113. What is a Datawarehouse?
Q114. What are the different authentication modes in SQL Server? How can it be changed?
Q115. What are STUFF and REPLACE function?
STUFF Function :This function is used to overwrite existing character or inserts a string into another string. Syntax:STUFF(string_expression,start, length, replacement_characters)
where,
string_expression :it is the string that will have characters substitutedstart: This refers to the starting position
length :It refers to the number of characters in the string which are substituted.replacement_string :They are the new characters which are injected in the string. REPLACE (string_expression, search_string, replacement_string)
Here every search_string in the string_expression will be replaced with the replacement_string.