Le query tipiche nel formato tabella SELECT * FROM a volte non sono sufficienti. Quando i dati di una query non sono in una tabella, ma in più tabelle o quando è necessario specificare più parametri di selezione contemporaneamente, avrai bisogno di query più sofisticate.
Questo articolo spiegherà come creare tali query e fornirà esempi di query SQL complesse.
Che aspetto ha una query complessa?
Innanzitutto, definiamo le condizioni per la composizione della query SQL. In particolare, dovrai utilizzare i seguenti parametri di selezione:
- i nomi delle tabelle da cui vuoi estrarre i dati;
- i valori dei campi che devono essere restituiti a quelli originali dopo aver apportato modifiche al database;
- le relazioni tra le tabelle;
- le condizioni di campionamento;
- i criteri di selezione ausiliari (restrizioni, modalità di presentazione delle informazioni, tipo di ordinamento).
Per comprendere meglio l'argomento, consideriamo un esempio che utilizza le seguenti quattro semplici tabelle. La prima riga è il nome della tabella che nelle query complesse funge da chiave esterna. Lo considereremo ulteriormente in dettaglio con un esempio:
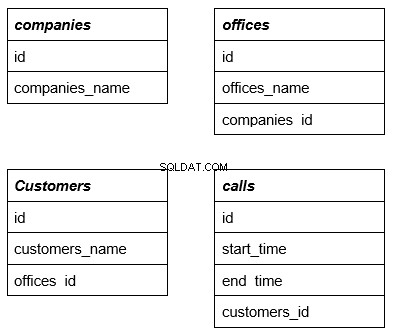
Ogni tabella ha righe relative ad altre tabelle. Spiegheremo ulteriormente perché è necessario.
Ora, diamo un'occhiata alla query SQL di base:
SELECT * FROM companies WHERE companies_name %STARTSWITH 'P';Il %STARTSWITH il predicato seleziona le righe che iniziano con il carattere/i caratteri specificati.
Il risultato è simile al seguente:

Consideriamo ora una query SQL complessa:
SELECT
companies.companies_name,
SUM(CASE WHEN call.id IS NOT NULL THEN 1 ELSE 0 END) AS calls,
AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) AS avgdifference
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
GROUP BY
companies.id,
companies.companies_name
HAVING AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) > (SELECT AVG(DATEDIFF(SECOND, calls.start_time, calls.end_time)) FROM calls)
ORDER BY calls DESC, companies.id ASC;
Il risultato è la seguente tabella:

La tabella mostra le società, il numero di telefonate corrispondente e la loro durata approssimativa.
Inoltre, elenca solo i nomi di società in cui la durata media delle chiamate è maggiore della durata media delle chiamate in altre società.
Quali sono le regole principali per la creazione di query SQL complesse?
Proviamo a creare un algoritmo multiuso per la composizione di query complesse.
Prima di tutto, devi decidere le tabelle costituite dai dati che partecipano alla query.
L'esempio sopra riguarda le aziende e chiamate tavoli. Se le tabelle con i dati richiesti non sono direttamente correlate tra loro, è necessario includere anche le tabelle intermedie che le uniscono.
Per questo colleghiamo anche tavoli, come uffici e clienti , utilizzando chiavi esterne. Pertanto, qualsiasi risultato della query con le tabelle di questo esempio includerà sempre le righe seguenti:
SELECT
...
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
...;
After that, you must test the correctness of the behavior in the following part of the query:
SELECT * FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id;
Una tabella combinata suggerisce i tre punti più importanti:
- Fai attenzione all'elenco dei campi dopo SELECT. L'operazione di lettura dei dati dalle tabelle unite richiede di specificare il nome della tabella da unire nel nome campo.
- La tua query complessa avrà sempre la tabella principale (aziende ). La maggior parte dei campi vengono letti da esso. La tabella allegata, nel nostro esempio, utilizza tre tabelle:uffici , clienti e chiamate . Il nome viene determinato dopo l'operatore JOIN.
- Oltre a specificare il nome della seconda tabella, assicurati di specificare la condizione per l'esecuzione del join. Discuteremo ulteriormente questa condizione.
- La query visualizzerà una tabella con un numero elevato di righe. Non è necessario pubblicarlo qui, poiché mostra risultati intermedi. Tuttavia, puoi sempre controllarne l'output tu stesso. Questo è molto importante, poiché aiuta a evitare errori nel risultato finale.
Ora esaminiamo la parte della query che confronta le durate delle chiamate all'interno di ciascuna azienda e tra tutte le società. Dobbiamo calcolare la durata media di tutte le chiamate. Usa la seguente query:
SELECT AVG(DATEDIFF(SECOND, calls.start_time, calls.end_time)) FROM calls
Tieni presente che abbiamo utilizzato DATEDIFF funzione che restituisce la differenza tra i periodi specificati. Nel nostro caso la durata media della chiamata è pari a 335 secondi.
Ora aggiungiamo alla query i dati sulle chiamate di tutte le aziende.
SELECT
companies.companies_name,
SUM(CASE WHEN calls.id IS NOT NULL THEN 1 ELSE 0 END) AS calls,
AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) AS avgdifference
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
GROUP BY
companies.id,
companies.companies_name
ORDER BY calls DESC, companies.id ASC;
In questa query,
- SOMMA (CASE QUANDO call.id NON È NULL ALLORA 1 ALTRO 0 FINE) – per evitare operazioni inutili, riassumiamo solo le chiamate esistenti – quando il numero di chiamate in un'azienda non è zero. Questo è molto importante in tabelle di grandi dimensioni con possibili valori nulli.
- AVG (ISNULL (DATEDIFF (SECONDO, call.start_time, call.end_time), 0)) – la query è identica alla query AVG sopra. Tuttavia, qui utilizziamo ISNULL operatore che sostituisce NULL con 0. È necessario per le aziende senza alcuna chiamata.
I nostri risultati:
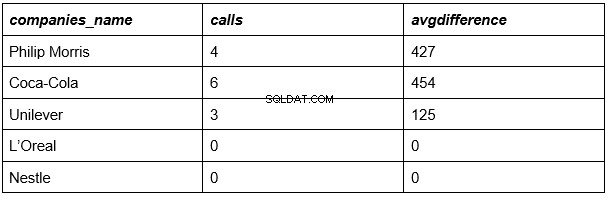
Abbiamo quasi finito. La tabella sopra presenta l'elenco delle società, il numero di chiamate corrispondente per ciascuna di esse e la durata media delle chiamate in ciascuna di esse.
Non resta che confrontare i numeri dell'ultima colonna con la durata media di tutte le chiamate di tutte le società (335 secondi).
Se inserisci la query che abbiamo presentato all'inizio, aggiungi semplicemente HAVING parte, otterrai ciò di cui hai bisogno.
Ti consigliamo vivamente di aggiungere commenti su ogni riga in modo da non confonderti in futuro quando dovrai correggere alcune query SQL complesse esistenti.
Pensieri finali
Sebbene ogni query SQL complessa richieda un approccio individuale, alcuni consigli sono adatti per la preparazione della maggior parte di tali query.
- determinare quali tabelle parteciperanno alla query;
- crea query complesse da parti più semplici;
- verifica l'accuratezza delle query in sequenza, in parti;
- verifica l'accuratezza della tua query con tabelle più piccole;
- scrivi commenti dettagliati su ogni riga contenente l'operando, utilizzando i simboli '-'.
Strumenti specializzati rendono questo lavoro molto più semplice. Tra questi, ti consigliamo di utilizzare Query Builder, uno strumento visivo che consente di costruire anche le query più complesse molto più velocemente in modalità visiva. Questo strumento è disponibile come soluzione autonoma o come parte del multifunzionale dbForge Studio per SQL Server.
Ci auguriamo che questo articolo ti abbia aiutato a chiarire questo problema specifico.