Mentre Jeff Atwood e Joe Celko sembrano pensare che il costo dei GUID non sia un grosso problema (vedi il post sul blog di Jeff, "Chiavi primarie:ID contro GUID" e questo thread del newsgroup, intitolato "Identity Vs. Uniqueidentifier"), altri esperti - più specificamente, gli esperti di indici e architettura che si concentrano sullo spazio di SQL Server tendono a non essere d'accordo. Ad esempio, Kimberly Tripp esamina alcuni dettagli nel suo post, "Lo spazio su disco è a buon mercato - NON È QUESTO IL PUNTO!", dove spiega che l'impatto non è solo sullo spazio su disco e sulla frammentazione, ma soprattutto sulla dimensione dell'indice e sulla memoria orma.
Quello che dice Kimberly è davvero vero:mi imbatto sempre nella giustificazione "lo spazio su disco è economico" per i GUID (esempio della scorsa settimana). Esistono altre giustificazioni per i GUID, inclusa la necessità di generare identificatori univoci all'esterno del database (e talvolta prima che la riga venga effettivamente creata) e la necessità di identificatori univoci su sistemi distribuiti separati (e dove gli intervalli di identità non sono pratici). Ma voglio davvero sfatare il mito secondo cui i GUID non costano molto, perché sì, e devi soppesare questi costi nella tua decisione.
Ho intrapreso questa missione per testare le prestazioni di chiavi di dimensioni diverse, dati gli stessi dati sullo stesso numero di righe, con gli stessi indici e all'incirca lo stesso carico di lavoro (riprodurre lo *esatto* carico di lavoro può essere piuttosto impegnativo). Non solo volevo misurare le cose di base come la dimensione dell'indice e la frammentazione dell'indice, ma anche gli effetti che hanno su tutta la linea, come ad esempio:
- impatto sull'utilizzo del pool di buffer
- frequenza delle divisioni di pagina "cattive"
- impatto complessivo sulla durata realistica del carico di lavoro
- impatto sui tempi di esecuzione medi delle singole query
- impatto sulla durata del runtime dei trigger successivi
- impatto sull'utilizzo di tempdb
Userò una varietà di tecniche per analizzare questi dati, inclusi gli eventi estesi, la traccia predefinita, i DMV relativi a tempdb e SQL Sentry Performance Advisor.
Configurazione
Innanzitutto, ho creato un milione di clienti da inserire in una tabella seme utilizzando alcuni metadati di SQL Server incorporati; ciò assicurerebbe che i clienti "casuali" siano costituiti dagli stessi dati naturali durante ogni test.
CREATE TABLE dbo.CustomerSeeds( rn INT PRIMARY KEY CLUSTERED, FirstName NVARCHAR(64), LastName NVARCHAR(64), EMail NVARCHAR(320) NOT NULL UNIQUE, Active BIT); INSERT dbo.CustomerSeeds WITH (TABLOCKX) (rn, FirstName, LastName, EMail, [Active])SELECT rn =ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, aFROM ( SELECT TOP (1000000) fn, ln , em, a =MAX(a), n =MAX(NEWID()) FROM ( SELECT fn, ln, em, a, r =ROW_NUMBER() OVER (PARTITION BY em ORDER BY em) FROM ( SELECT TOP (2000000) fn =LEFT(o.name, 64), ln =LEFT(c.name, 64), em =LEFT(o.name, LEN(c.name)%5+1) + '.' + LEFT(c. nome, LEN(o.name)%5+2) + '@' + RIGHT(c.name, LEN(o.name+c.name)%12 + 1) + LEFT(RTRIM(CHECKSUM(NEWID()) ),3) + '.com', a =CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c ORDER BY NEWID() ) AS x ) AS y WHERE r =1 GRUPPO PER fn, ln, em ORDINA PER n) AS z ORDINA PER rn;GO SELEZIONA TOP (10) * DA dbo.CustomerSeeds ORDINA PER rn;GO
Il tuo chilometraggio può variare, ma sul mio sistema, questa popolazione ha impiegato 86 secondi. Dieci file rappresentative (clicca per ingrandire):
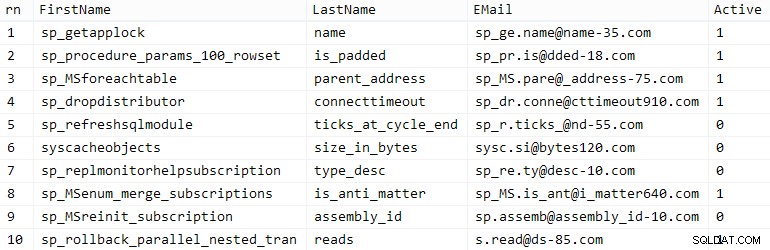 Clienti campione
Clienti campione
Successivamente, avevo bisogno di tabelle per ospitare i dati iniziali per ogni caso d'uso, con alcuni indici extra per simulare una sorta di realtà, e ho inventato brevi suffissi per rendere più semplici tutti i tipi di diagnostica in seguito:
| tipo di dati | predefinito | compressione | suffisso caso d'uso |
|---|---|---|---|
| INT | IDENTITÀ | nessuno | Io |
| INT | IDENTITÀ | pagina + riga | Ic |
| GRANDE | IDENTITÀ | nessuno | B |
| GRANDE | IDENTITÀ | pagina + riga | Bc |
| IDENTIFICATORE UNICO | NEWID() | nessuno | G |
| IDENTIFICATORE UNICO | NEWID() | pagina + riga | Gc |
| IDENTIFICATORE UNICO | NEWSEQUENTIALID() | nessuno | S |
| IDENTIFICATORE UNICO | NEWSEQUENTIALID() | pagina + riga | Sc |
Tabella 1:casi d'uso, tipi di dati e suffissi
Otto tabelle in tutto, tutte basate sullo stesso modello (vorrei semplicemente cambiare i commenti in modo che corrispondano al caso d'uso e sostituire $use_case$ con il suffisso appropriato dalla tabella sopra):
CREA TABELLA dbo.Customers_$use_case$ -- I,Ic,B,Bc,G,Gc,S,Sc( CustomerID INT NOT NULL IDENTITY(1,1), --CustomerID BIGINT NOT NULL IDENTITY(1, 1), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID(), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWSEQUENTIALID(), FirstName NVARCHAR(64) NOT NULL, LastName NVARCHAR(64) NOT NULL, EMail NVARCHAR(320) NOT NULL, Active BIT NOT NULL DEFAULT 1, Creato DATETIME NOT NULL DEFAULT SYSDATETIME(), DATETIME NULL aggiornato, CONSTRAINT C_PK_Customers_$use_case$ CHIAVE PRIMARIA (CustomerID)) --WITH (DATA_COMPRESSION =PAGE)GO;CREATE UNIQUE INDEX C_Email_Customers_$use_case$ ON dbo. Customers_$use_case$(EMail) --CON (COMPRESSION_DATI =PAGINA);GOCREATE INDEX C_Active_Customers_$use_case$ SU dbo.Customers_$use_case$(Nome, Cognome, EMail) DOVE Attivo =1 --WITH (COMPRESSION_DATI =PAGINA);GOCREATE INDEX C_Name_Customers_$use_case$ ON dbo.Customers_$use_case$(LastName, FirstName) INCLUDE (EMail) --WITH (DATA_COMPRESSION =PAGE);GOUna volta create le tabelle, ho proceduto a popolare le tabelle ea misurare molte delle metriche a cui ho accennato sopra. Ho riavviato il servizio SQL Server tra ogni test per assicurarmi che partissero tutti dalla stessa linea di base, che i DMV sarebbero stati reimpostati, ecc.
Inserti non contestati
Il mio obiettivo finale era riempire la tabella con 1.000.000 di righe, ma prima volevo vedere l'impatto del tipo di dati e della compressione sugli inserti grezzi senza contese. Ho generato la seguente query, che avrebbe popolato la tabella con i primi 200.000 contatti, 2000 righe alla volta, e l'ho eseguita su ciascuna tabella:
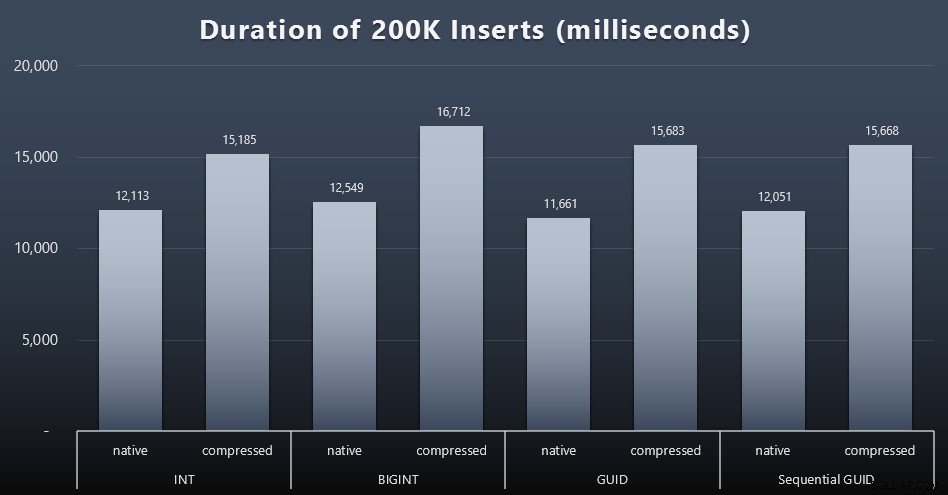
DECLARE @i INT =1;WHILE @i <=100BEGIN INSERT dbo.Customers_$use_case$(FirstName, LastName, Email, Active) SELECT FirstName, LastName, Email, Active FROM dbo.CustomerSeeds AS c ORDER BY rn OFFSET 2000 * (@i-1) RIGHE RECUPERO SOLO 2000 RIGHE SUCCESSIVE; SET @i +=1;ENDRisultati (clicca per ingrandire):
Ogni caso ha richiesto circa 12 secondi (senza compressione) e 16 secondi (con compressione), senza un chiaro vincitore in nessuna delle modalità di archiviazione. L'effetto della compressione (principalmente sull'overhead della CPU) è abbastanza consistente, ma poiché è in esecuzione su un SSD veloce, l'impatto I/O dei diversi tipi di dati è trascurabile. In effetti la compressione contro BIGINT sembrava avere l'impatto maggiore (e questo ha senso, dal momento che ogni singolo valore inferiore a 2 miliardi sarebbe compresso).
Carico di lavoro più controverso
Successivamente volevo vedere come un carico di lavoro misto sarebbe in competizione per le risorse e in genere si sarebbe comportato rispetto a ciascun tipo di dati. Quindi ho creato queste procedure (sostituendo
$use_case$e$data_type$opportunamente per ogni prova):-- aggiornamenti casuali singleton ai dati in più di un indexCREATE PROCEDURE [dbo].[Customers_$use_case$_RandomUpdate] @Customers_$use_case$ $data_type$ASBEGIN SET NOCOUNT ON; AGGIORNAMENTO dbo.Customers_$use_case$ SET LastName =COALESCE(STUFF(LastName, 4, 1, 'x'),'x') WHERE CustomerID =@Customers_$use_case$;ENDGO -- reads ("paginazione") - supporto multiplo ordina:usa l'SQL dinamico per tenere traccia delle statistiche della query separatamenteCREATE PROCEDURE [dbo].[Customers_$use_case$_Page] @PageNumber INT =1, @PageSize INT =100, @sort SYSNAMEASBEGIN SET NOCOUNT ON; DICHIARA @sql NVARCHAR(MAX) =N'SELECT CustomerID, FirstName, LastName, Email, Active, Created, Updated FROM dbo.Customers_$use_case$ ORDER BY ' + @sort + N' OFFSET (@pn-1)*@ ps) RICHIEDERE LE RIGHE SUCCESSIVE @ps SOLO RIGHE;'; EXEC sys.sp_executesql @sql, N'@pn INT, @ps INT', @PageNumber, @PageSize;ENDGOPoi ho creato posti di lavoro che avrebbero richiamato quelle procedure ripetutamente, con leggeri ritardi, e anche – contemporaneamente – finito di popolare i restanti 800.000 contatti. Questo script crea tutti i 32 lavori e stampa anche l'output che può essere utilizzato in seguito per chiamare tutti i lavori per un test specifico in modo asincrono:
USE msdb;GO DECLARE @typ TABLE(use_case VARCHAR(2), data_type SYSNAME);INSERT @typ(use_case, data_type) VALUES('I', N'INT'), ('Ic',N'INT '),('B', N'BIGINT'), ('Bc', N'BIGINT'),('G', N'UNIQUEIDENTIFIER'), ('Gc', N'UNIQUEIDENTIFIER'),('S ', N'UNIQUEIDENTIFIER'), ('Sc', N'UNIQUEIDENTIFIER'); DECLARE @jobs TABLE(name SYSNAME, cmd NVARCHAR(MAX));INSERT @jobs(name, cmd) VALUES( N'Carico di lavoro di aggiornamento casuale', N'DECLARE @CustomerID $data_type$, @i INT =1; WHILE @i <=500 BEGIN SELECT TOP (1) @CustomerID =CustomerID FROM dbo.Customers_$use_case$ ORDER BY NEWID(); EXEC dbo.Customers_$use_case$_RandomUpdate @Customers_$use_case$ =@CustomerID; WAITFOR DELAY ''00:00 :01''; SET @i +=1; END'),( N'Popola clienti', N'SET QUOTED_IDENTIFIER ON; DECLARE @i INT =101; WHILE @i <=500 BEGIN INSERT dbo.Customers_$use_case$ (Nome, Cognome, E-mail, Attivo) SELEZIONA Nome, Cognome, E-mail, Attivo DA dbo.CustomerSeeds AS c ORDINA PER rn OFFSET 2000 * (@i-1) RIGHE FETCH SUCCESSIVE 2000 SOLO RIGHE; WAITFOR DELAY ''00:00:01''; SET @i +=1; END'),( N'Paging workload 1', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- ordina per SET ID cliente @sql =N ''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''CustomerID'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; ATTESA RITARDO ''00:00:01''; SET @i +=2; END'),( N'Paging workload 2', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- ordina per cognome, nome SET @sql =N''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''LastName, FirstName'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; ATTESA RITARDO ''00:00:01''; SET @i +=2; FINE'); DICHIARA @n SYSNAME, @c NVARCHAR(MAX); DICHIARA c CURSOR LOCAL FAST_FORWARD FORSELECT name =t.use_case + N' ' + j.name, cmd =REPLACE(REPLACE(j.cmd, N'$use_case$', t.use_case), N'$data_type$', t .data_type) FROM @typ AS t CROSS JOIN @jobs AS j; APERTO c; RECUPERA c IN @n, @c; WHILE @@FETCH_STATUS <> -1BEGIN SE ESISTE (SELEZIONARE 1 DA msdb.dbo.sysjobs DOVE nome =@n) BEGIN EXEC msdb.dbo.sp_delete_job @job_name =@n; END EXEC msdb.dbo.sp_add_job @job_name =@n, @enabled =0, @notify_level_eventlog =0, @category_id =0, @owner_login_name =N'sa'; EXEC msdb.dbo.sp_add_jobstep @job_name =@n, @step_name =@n, @command =@c, @database_name =N'ID'; EXEC msdb.dbo.sp_add_jobserver @job_name =@n, @server_name =N'(locale)'; PRINT 'EXEC msdb.dbo.sp_start_job @nome_lavoro =N''' + @n + ''';'; FETCH c INTO @n, @c;ENDMisurare i tempi di lavoro in ogni caso è stato banale:ho potuto controllare le date di inizio/fine in
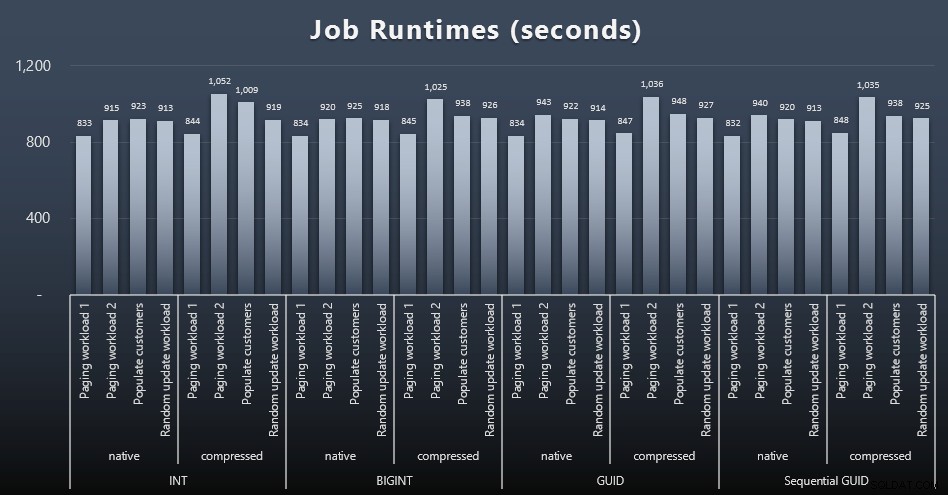
msdb.dbo.sysjobhistoryo estrarli da SQL Sentry Event Manager. Ecco i risultati (clicca per ingrandire):
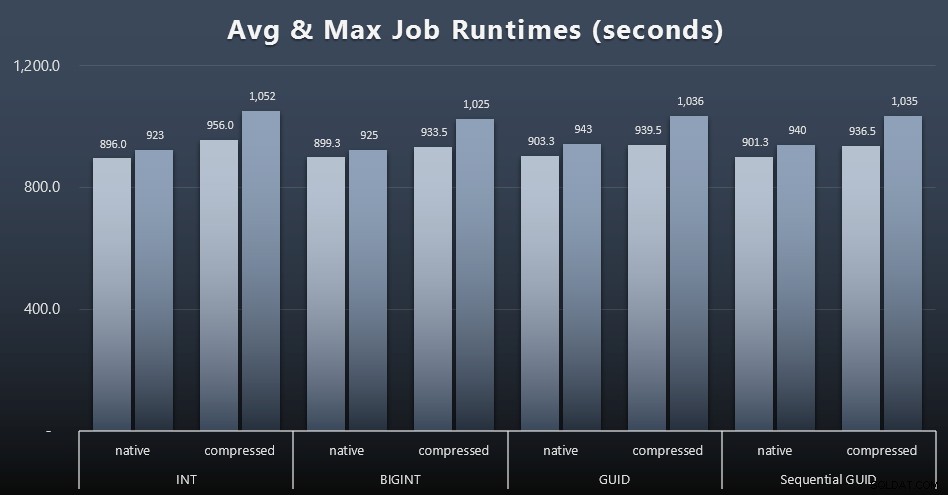
E se vuoi avere un po' meno da digerire, guarda i tempi di esecuzione medi e massimi dei quattro lavori (clicca per ingrandire):
Ma anche in questo secondo grafico non c'è davvero una varianza sufficiente per sostenere o contro uno qualsiasi degli approcci.
Runtime di query
Ho preso alcune metriche da
sys.dm_exec_query_statsesys.dm_exec_trigger_statsper determinare quanto tempo impiegavano in media le singole query.
Popolazione
I primi 200.000 clienti sono stati caricati abbastanza rapidamente, in meno di 20 secondi, a causa dell'assenza di carichi di lavoro concorrenti. Tuttavia, una volta che i quattro lavori venivano eseguiti contemporaneamente, c'era un impatto significativo sulla durata delle scritture a causa della simultaneità. Le restanti 800.000 righe richiedevano in media almeno un ordine di grandezza in più di tempo per essere completate. Ecco i risultati della media di ogni 2.000 inserimenti cliente (clicca per ingrandire):
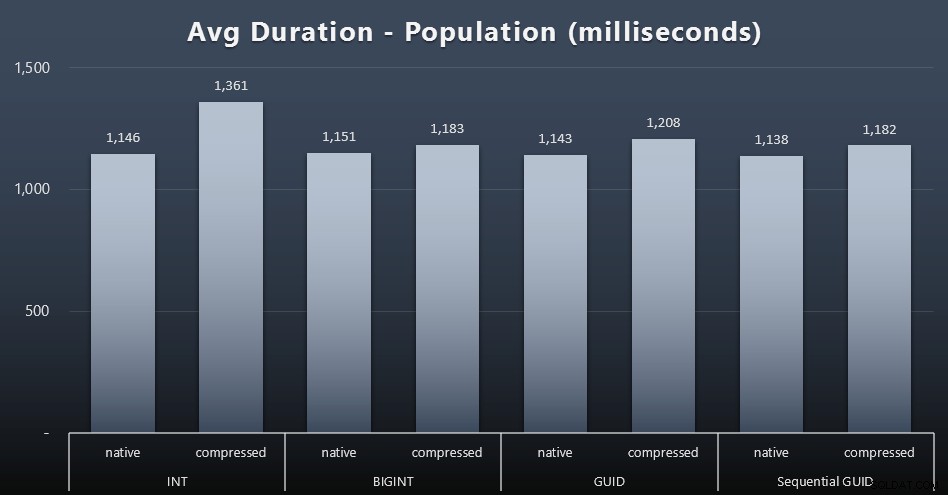
Vediamo qui che la compressione di un INT era l'unico vero valore anomalo:ho alcune teorie al riguardo, ma ancora niente di conclusivo.
Impostazione dei carichi di lavoro
Anche i tempi di esecuzione medi delle query di paging sembrano essere stati significativamente influenzati dalla concorrenza rispetto ai miei test eseguiti in isolamento. Ecco i risultati (clicca per ingrandire):
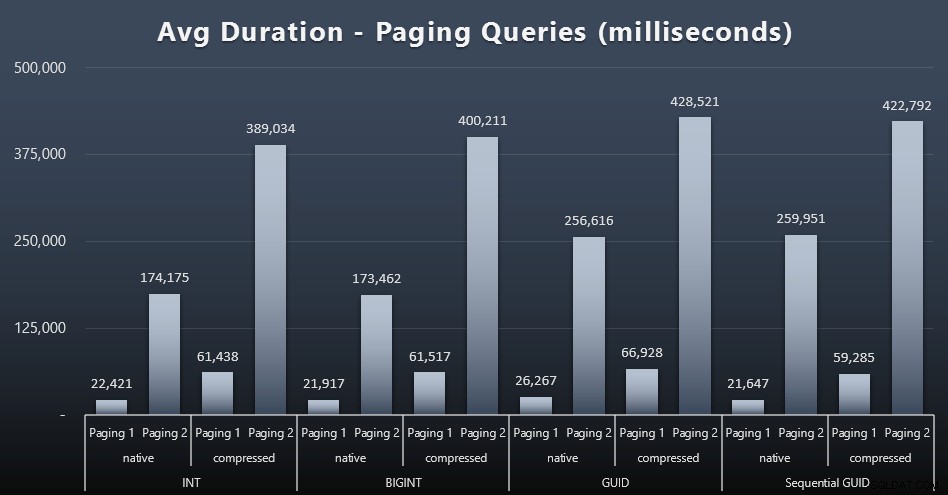
(Pagina 1 =ordine per CustomerID, Pagina 2 =ordine per Cognome, Nome.)
Vediamo che sia per il Paging 1 (ordine per CustomerID) che per il Paging 2 (ordine per nome), c'è un impatto significativo sul tempo di esecuzione dovuto alla compressione (fino a ~700%). Entrambi i GUID sembrano essere i cavalli più lenti in questa gara, con NEWID() che ha le peggiori prestazioni.
Aggiorna carichi di lavoro
Gli aggiornamenti singleton sono stati abbastanza veloci anche in condizioni di forte simultaneità, ma c'erano ancora alcune differenze evidenti dovute alla compressione e persino alcune differenze sorprendenti tra i tipi di dati (fai clic per ingrandire):
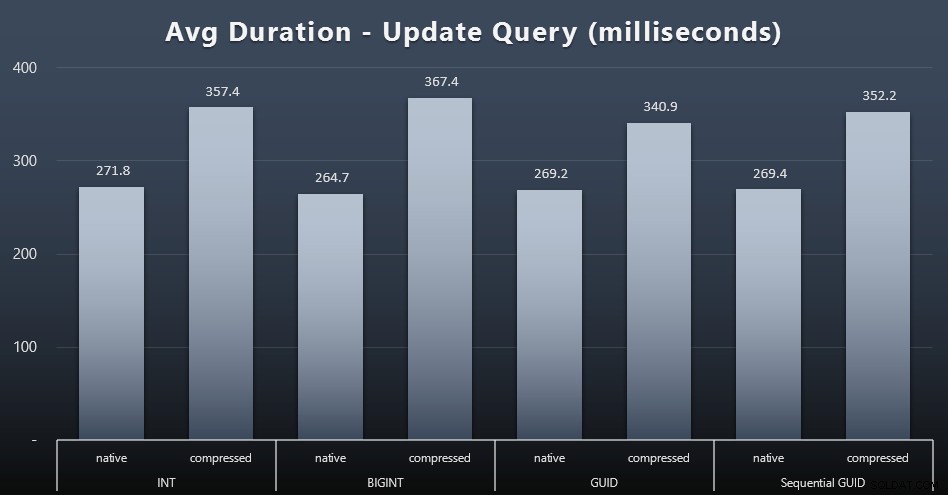
In particolare, gli aggiornamenti alle righe contenenti valori GUID sono stati effettivamente più veloci rispetto agli aggiornamenti contenenti INT/BIGINT, quando era in uso la compressione. Con l'archiviazione nativa, le differenze erano meno degne di nota (ma INT era ancora un perdente).
Statistiche di attivazione
Di seguito sono riportati i tempi di esecuzione medi e massimi per il trigger semplice in ciascun caso (fare clic per ingrandire):
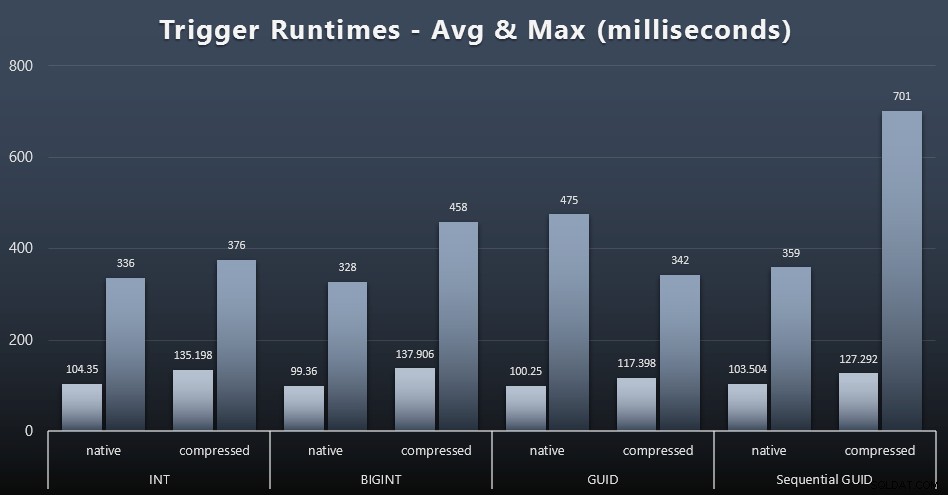
La compressione sembra avere un impatto molto maggiore qui rispetto alla scelta del tipo di dati (anche se questo sarebbe probabilmente più pronunciato se parte del mio carico di lavoro di aggiornamento avesse aggiornato molte righe invece di consistere esclusivamente in ricerche a riga singola). Il massimo per il GUID sequenziale è chiaramente un valore anomalo di qualche tipo che non ho studiato (puoi dire che è insignificante in base alla media che è ancora in linea su tutta la linea).
Che cosa stavano aspettando queste domande?
Dopo ogni carico di lavoro, ho anche dato un'occhiata alle attese principali del sistema, eliminando le ovvie attese di coda/timer (come descritto da Paul Randal) e attività irrilevanti dal software di monitoraggio (come TRACEWRITE ). Ecco le prime 3 attese in ciascun caso (clicca per ingrandire):
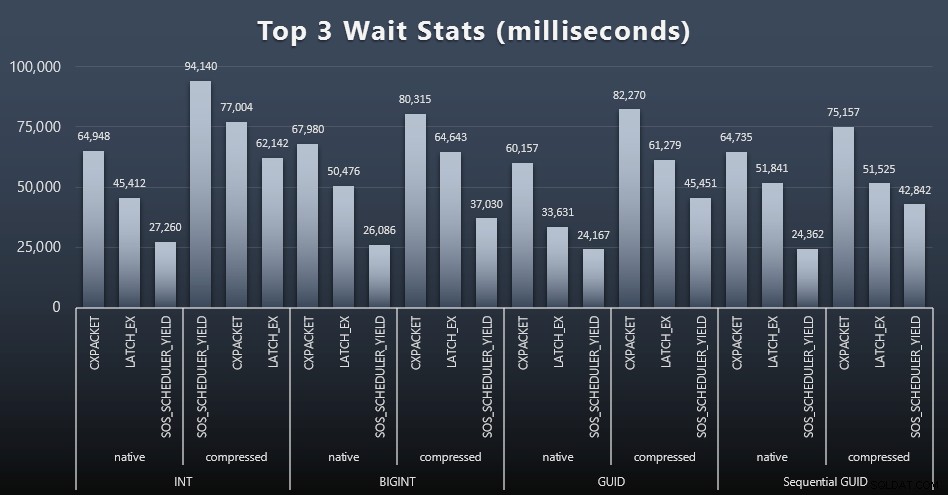
Nella maggior parte dei casi, le attese erano CXPACKET, quindi LATCH_EX, quindi SOS_SCHEDULER_YIELD. Nel caso d'uso che coinvolge numeri interi e compressione, tuttavia, SOS_SCHEDULER_YIELD ha preso il sopravvento, il che implica per me una certa inefficienza nell'algoritmo per la compressione di interi (che potrebbe essere completamente estraneo all'algoritmo utilizzato per spremere BIGINT in INT). Non ho indagato ulteriormente, né ho trovato giustificazione per il monitoraggio delle attese per singola query.
Spazio su disco / Frammentazione
Anche se tendo a concordare sul fatto che non si tratta dello spazio su disco, è comunque una metrica che vale la pena presentare. Anche in questo caso molto semplicistico in cui esiste una sola tabella e la chiave non è presente in tutte le altre tabelle correlate (che sicuramente esisterebbero in un'applicazione reale), la differenza è significativa. Per prima cosa diamo un'occhiata al reserved colonna da sp_spaceused (clicca per ingrandire):
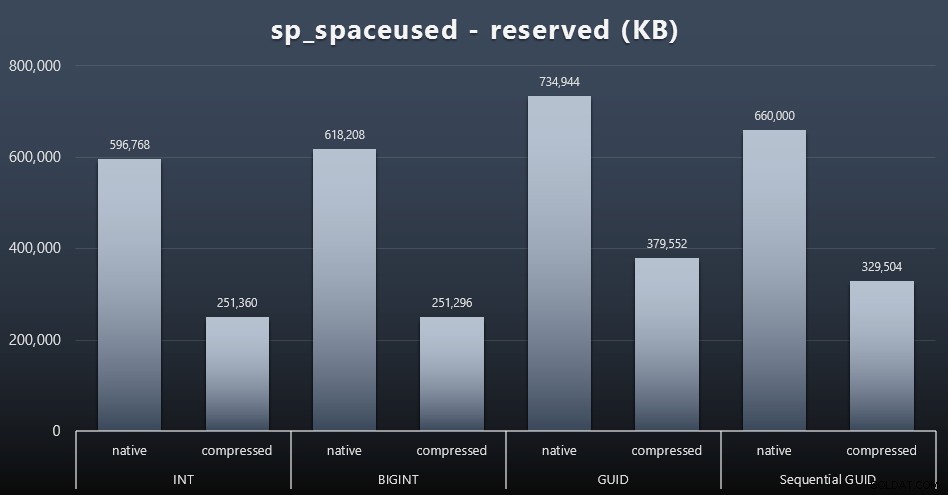
Qui, BIGINT ha preso solo un po' più di spazio di INT e GUID (come previsto) ha avuto un salto maggiore. Il GUID sequenziale ha avuto un aumento meno significativo dello spazio utilizzato e anche compresso molto meglio del GUID tradizionale. Ancora una volta, nessuna sorpresa qui:un GUID è più grande di un numero, punto. Ora, i sostenitori del GUID potrebbero obiettare che il prezzo da pagare in termini di spazio su disco non è molto (18% su BIGINT senza compressione, circa il 50% con compressione). Ma ricorda che questa è una singola tabella di 1 milione di righe. Immagina come si estrapolerà quando avrai 10 milioni di clienti e molti di loro hanno 10, 30 o 500 ordini:quelle chiavi potrebbero essere ripetute in una dozzina di altre tabelle e occupare lo stesso spazio extra in ogni riga.
Quando ho esaminato la frammentazione dopo ogni carico di lavoro (ricorda, non viene eseguita alcuna manutenzione dell'indice) utilizzando questa query:
SELECT index_id, FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('dbo.Customers_$use_case$'), -1, 0, 'DETAILED'); I risultati hanno prodotto immagini molto meno interessanti; tutti gli indici non cluster erano frammentati di oltre il 99%. Gli indici raggruppati, tuttavia, erano molto frammentati o non erano affatto frammentati (fare clic per ingrandire):
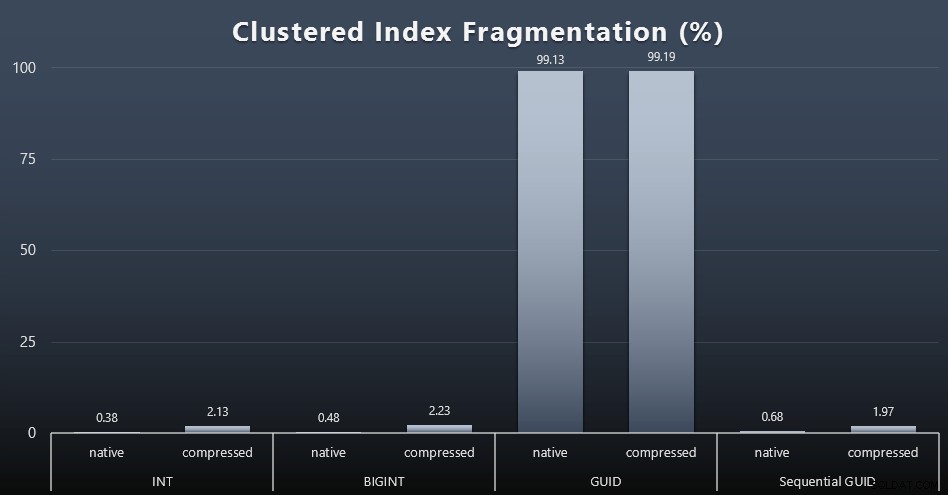
La frammentazione è un'altra metrica che spesso significa molto meno quando si parla di SSD, ma è importante notare lo stesso, poiché non tutti i sistemi possono permettersi di essere beatamente inconsapevoli dell'impatto che la frammentazione può avere sui modelli di I/O. Ritengo che l'utilizzo di GUID non sequenziali, su un sistema più legato all'I/O, l'impatto di questa sola frammentazione sarebbe drasticamente amplificato sulla maggior parte delle altre metriche in questo test.
Utilizzo del pool di buffer
È qui che essere giudizioso sulla quantità di spazio su disco utilizzato dalle tue tabelle ripaga davvero:più grandi sono le tue tabelle, più spazio occupano nel pool di buffer. Spostare i dati dentro e fuori dal pool di buffer è costoso e, ancora una volta, questo è un caso molto semplicistico in cui i test sono stati eseguiti in isolamento e non c'erano altre applicazioni e database sull'istanza in competizione per memoria preziosa.
Questa è una semplice misura della seguente query alla fine di ogni carico di lavoro:
SELECT total_kb FROM sys.dm_os_memory_broker_clerks WHERE clerk_name =N'Buffer Pool';
Risultati (clicca per ingrandire):
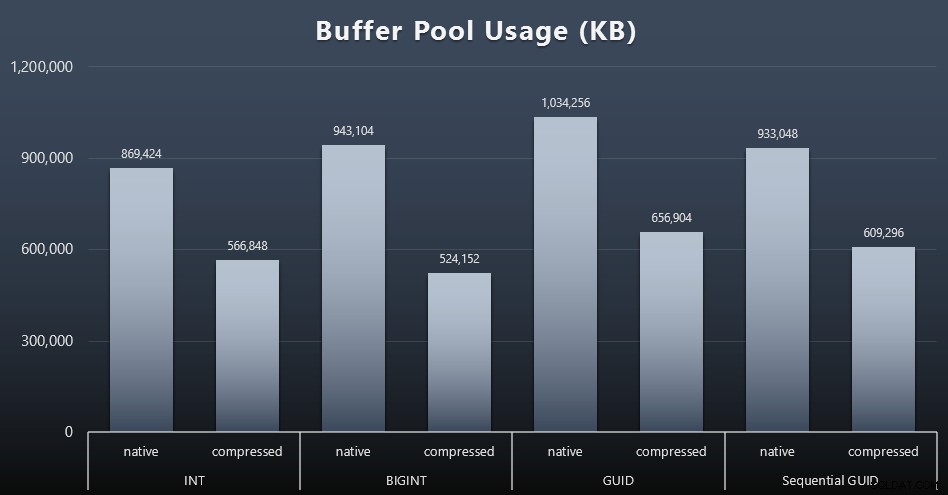
Sebbene la maggior parte di questo grafico non sia affatto sorprendente – GUID occupa più spazio di BIGINT, BIGINT più di INT – ho trovato interessante che un GUID sequenziale occupasse meno spazio di un BIGINT, anche senza compressione. Ho preso nota di eseguire alcune analisi forensi a livello di pagina per determinare che tipo di efficienza si sta verificando qui sotto le coperte.
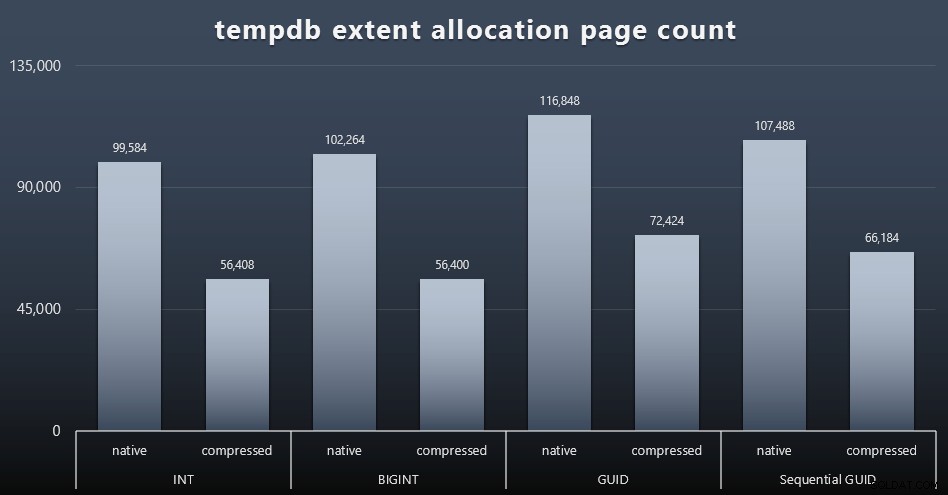
Utilizzo tempdb
Non sono sicuro di cosa mi aspettassi qui, ma dopo ogni carico di lavoro, ho raccolto i contenuti dei tre DMV relativi all'utilizzo dello spazio relativi a tempdb, sys.dm_db_file|session|task_space_usage . L'unico che sembrava mostrare volatilità in base al tipo di dati era sys.dm_db_file_space_usage extent_allocation_page_count . Ciò mostra che, almeno nella mia configurazione e in questo carico di lavoro specifico, i GUID sottoporranno tempdb a un allenamento leggermente più approfondito (fai clic per ingrandire):
Separazioni di pagina "cattive"
Una delle cose che volevo misurare era l'impatto sulle divisioni di pagina:non le normali divisioni di pagina (quando aggiungi una nuova pagina), ma quando devi effettivamente spostare i dati tra le pagine per fare spazio a più righe. Jonathan Kehayias ne parla in modo più approfondito nel suo post sul blog, "Tracciamento delle divisioni di pagine problematiche negli eventi estesi di SQL Server 2012 - No Really This Time!", che fornisce anche la base per la sessione di eventi estesi che ho usato per acquisire i dati:
CREA SESSIONE EVENTO [BadPageSplits] SUL SERVER AGGIUNGI EVENTO sqlserver.transaction_log (WHERE operation =11 AND database_id =10) AGGIUNGI TARGET package0.histogram ( SET filtering_event_name ='sqlserver.transaction_log', source_type =0, source ='alloc_unit_id' );SESSIONE EVENTO DEL GOALTER [BadPageSplits] IN STATO SERVER =INIZIO;Vai
E la query che ho usato per tracciarla:
SELECT t.name, SUM(tab.split_count)DA ( SELECT n.value('(value)[1]', 'bigint') AS alloc_unit_id, n.value('(@count)[1]' , 'bigint') AS split_count FROM ( SELECT CAST(target_data as XML) target_data FROM sys.dm_xe_sessions AS s INNER JOIN sys.dm_xe_session_targets AS t ON s.address =t.event_session_address WHERE s.name ='BadPageSplits' AND t.target_name ='istogramma' ) AS x CROSS APPLY target_data.nodes('HistogramTarget/Slot') as q(n)) AS tabINNER JOIN sys.allocation_units AS au ON tab.alloc_unit_id =au.allocation_unit_idINNER JOIN sys.partitions AS p ON au. container_id =p.partition_idINNER UNISCITI a sys.tables AS t ON p.object_id =t.[object_id]GRUPPO PER t.name; Ed ecco i risultati (clicca per ingrandire):
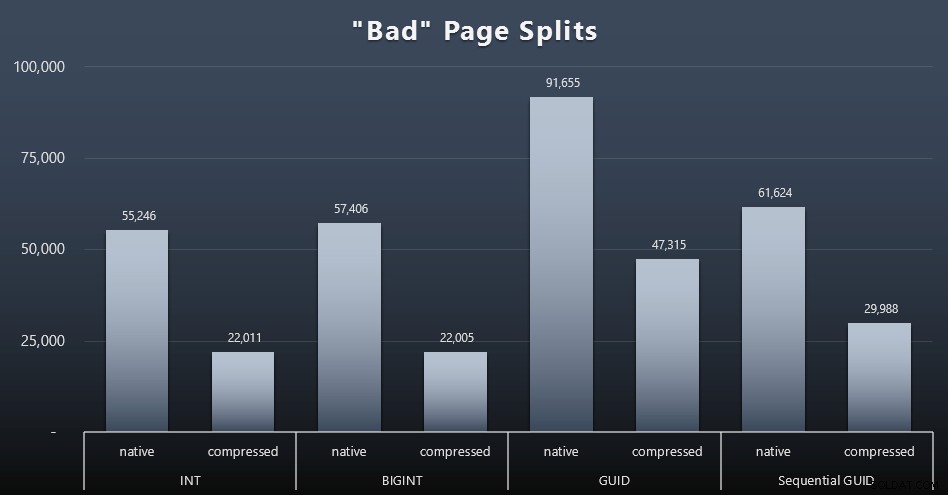
Anche se ho già notato che nel mio scenario (in cui sono in esecuzione su SSD veloci) l'indiscutibile differenza nell'attività di I/O non ha un impatto diretto sul tempo di esecuzione complessivo, questa è comunque una metrica che vorrai considerare, in particolare se non hai SSD o se il tuo carico di lavoro è già legato all'I/O.
Conclusione
Sebbene questi test mi abbiano aperto gli occhi un po' di più su quanto le percezioni di lunga durata che ho avuto siano state alterate da hardware più moderno, sono ancora fermamente contrario allo spreco di spazio su disco o in memoria. Anche se ho cercato di dimostrare un certo equilibrio e di far brillare i GUID, qui c'è ben poco dal punto di vista delle prestazioni per supportare il passaggio da INT/BIGINT a una delle due forme di IDENTIFICATIVO UNICO, a meno che non sia necessario per altri motivi meno tangibili (come la creazione della chiave in l'applicazione o il mantenimento di valori chiave univoci in sistemi diversi). Un breve riassunto, che mostra che NEWSEQUENTIALID() è la scelta peggiore in molte delle metriche in cui c'era una differenza sostanziale (e nella maggior parte di questi casi, NEWSEQUENTIALID() era un secondo vicino)):
| Metrico | Chiari perdenti? |
|---|---|
| Inserti non contestati | – disegna – |
| Carico di lavoro simultaneo | – disegna – |
| Query individuali – Popolazione | INT (compresso) |
| Query individuali – Cercapersone | NEWID() / NEWSEQUENTIALID() |
| Query individuali – Aggiornamento | INT (nativo) / BIGINT (compresso) |
| Query individuali – DOPO l'attivazione | – disegna – |
| Spazio su disco | NEWID() |
| Frammentazione dell'indice a grappolo | NEWID() |
| Utilizzo del pool di buffer | NEWID() |
| Utilizzo tempdb | NEWID() |
| Separazioni di pagina "cattive" | NEWID() |
Tabella 2:i più grandi perdenti
Sentiti libero di testare queste cose per te stesso; Posso assemblare il mio set completo di script se desideri eseguirli nel tuo ambiente. Lo scopo breve di questo intero post è abbastanza semplice:ci sono molte metriche importanti da considerare oltre al prevedibile impatto sullo spazio su disco, quindi non dovrebbe essere usato da solo come argomento in nessuna delle direzioni.
Ora, non voglio che questa linea di pensiero sia limitata alle chiavi, di per sé. Dovrebbe davvero essere pensato ogni volta che viene effettuata una scelta del tipo di dati. Vedo datetime essendo scelto spesso, ad esempio, quando solo una date o smalldatetime è necessario. Sulle tabelle transazionali, anche questo può produrre molto spazio su disco sprecato e questo si riduce anche ad alcune di queste altre risorse.
In un test futuro vorrei confrontare i risultati per una tabella molto più grande (> 2 miliardi di righe). Posso simularlo con INT impostando il seme dell'identità su -2 miliardi, consentendo ~ 4 miliardi di righe. E vorrei che il confronto tra carico di lavoro e spazio su disco/ingombro di memoria coinvolgesse più di una singola tabella, poiché uno dei vantaggi di una chiave sottile è quando tale chiave è rappresentata in dozzine di tabelle correlate. Stavo monitorando gli eventi di crescita automatica, ma non ce n'erano, poiché il database era sufficientemente grande per accogliere la crescita e non pensavo di misurare l'utilizzo effettivo del registro all'interno del file di registro esistente, quindi vorrei testare di nuovo con le impostazioni predefinite per la dimensione del registro e la crescita automatica, e questa volta misurando DBCC SQLPERF(LOGSPACE); . Sarebbe anche interessante ricostruire il tempo e misurare l'utilizzo del registro anche come risultato di tali operazioni. Infine, vorrei rendere l'I/O un fattore più rilevante trovando un server con dischi rigidi meccanici:so che ce ne sono molti là fuori, ma in alcuni negozi sono piuttosto scarsi.