Essere responsabile delle prestazioni di SQL Server può essere un compito arduo. Ci sono molte aree che dobbiamo monitorare e comprendere. Ci si aspetta anche di essere in grado di rimanere aggiornati su tutte queste metriche e di sapere cosa sta succedendo sui nostri server in ogni momento. Mi piace chiedere ai DBA qual è la prima cosa a cui pensano quando sentono la frase "ottimizzazione di SQL Server"; la risposta travolgente che ottengo è "ottimizzazione delle query". Sono d'accordo sul fatto che l'ottimizzazione delle query sia molto importante ed è un compito infinito che dobbiamo affrontare perché i carichi di lavoro cambiano continuamente.
Tuttavia, ci sono molti altri aspetti da considerare quando si pensa alle prestazioni di SQL Server. Ci sono molte impostazioni a livello di istanza, sistema operativo e database che devono essere modificate rispetto alle impostazioni predefinite. Essere un consulente mi consente di lavorare in molti diversi settori di attività e di essere esposto a tutti i tipi di problemi di prestazioni. Quando lavoro con un nuovo client, cerco sempre di eseguire un audit di integrità del server per sapere con cosa ho a che fare. Durante l'esecuzione di questi controlli, una delle cose che ho riscontrato più volte sono state le latenze di lettura e scrittura eccessive sui dischi in cui risiedono i dati e i file di registro di SQL Server.
Latenza di lettura/scrittura
Per visualizzare le latenze del disco in SQL Server è possibile eseguire rapidamente e facilmente query su DMV sys.dm_io_virtual_file_stats . Questo DMV accetta due parametri:database_id e file_id . La cosa fantastica è che puoi passare NULL come entrambi i valori e restituiscono le latenze per tutti i file per tutti i database. Le colonne di output includono:
- id_database
- id_file
- campione_ms
- numero_di_letture
- numero_di_byte_letti
- io_stall_read_ms
- numero_di_scritture
- numero_di_byte_scritti
- io_stall_write_ms
- io_stallo
- dimensione_su_disco_byte
- file_handle
Come puoi vedere dall'elenco delle colonne, ci sono informazioni davvero utili che questo DMV recupera, tuttavia eseguendo semplicemente SELECT * FROM sys.dm_io_virtual_file_stats(NULL, NULL); non aiuta molto a meno che tu non abbia memorizzato i tuoi database_id e non possa fare un po' di matematica nella tua testa.
Quando eseguo una query sulle statistiche del file, utilizzo una query dal post sul blog di Paul Randal, "Come esaminare le latenze del sottosistema IO dall'interno di SQL Server". Questo script semplifica la lettura dei nomi delle colonne, include l'unità su cui si trova il file, il nome del database e il percorso del file.
Interrogando questo DMV puoi facilmente dire dove si trovano gli hot spot di I/O per i tuoi file. Puoi vedere dove sono le più alte latenze di scrittura e lettura e quali database sono i colpevoli. Sapere questo ti consentirà di iniziare a esaminare le opportunità di ottimizzazione per quei database specifici. Ciò potrebbe includere l'ottimizzazione dell'indice, il controllo per vedere se il pool di buffer è sotto pressione di memoria, eventualmente lo spostamento del database in una parte più veloce del sottosistema di I/O, o eventualmente il partizionamento del database e la distribuzione dei filegroup su altre LUN.
Quindi esegui la query e restituisce molti valori in ms per la latenza:quali valori vanno bene e quali non validi?
Quali valori sono buoni o cattivi?
Se chiedi a SQLskills, ti diremo qualcosa sulla falsariga di:
- Eccellente:<1 ms
- Molto buono:<5 ms
- Buono:5 – 10 ms
- Scarso:10 – 20 ms
- Cattivo:20 – 100 ms
- Davvero pessimo:100 – 500 ms
- OMG!:> 500 ms
Se esegui una ricerca su Bing, troverai articoli di Microsoft che contengono consigli simili a:
- Buono:<10 ms
- Ok:10 – 20 ms
- Cattivo:20 – 50 ms
- Seriamente male:> 50 ms
Come puoi vedere, ci sono alcune lievi variazioni nei numeri, ma il consenso è che qualsiasi cosa oltre i 20 ms può essere considerata problematica. Detto questo, la tua latenza di scrittura media potrebbe essere di 20 ms e questo è accettabile al 100% per la tua organizzazione e va bene. È necessario conoscere le latenze di I/O generali per il proprio sistema in modo che, quando le cose peggiorano, sappiate cos'è la normalità.
Le mie latenze di lettura/scrittura sono pessime, cosa devo fare?
Se stai scoprendo che le latenze di lettura e scrittura non sono buone sul tuo server, ci sono diversi punti in cui puoi iniziare a cercare problemi. Questo non è un elenco completo, ma alcune indicazioni da dove iniziare.
- Analizza il tuo carico di lavoro. La tua strategia di indicizzazione è corretta? Non avere gli indici corretti comporterà la lettura di molti più dati dal disco. Esegue la scansione anziché la ricerca.
- Le tue statistiche sono aggiornate? Statistiche errate possono comportare scelte sbagliate per i piani di esecuzione.
- Hai problemi di sniffing dei parametri che causano piani di esecuzione scadenti?
- Il pool di buffer è sotto pressione di memoria, ad esempio a causa di una cache del piano gonfia?
- Qualche problema di rete? Il tuo tessuto SAN funziona correttamente? Chiedi al tuo tecnico di archiviazione di convalidare il percorso e la rete.
- Sposta gli hot spot su diversi storage array. In alcuni casi può essere un singolo database o solo alcuni database a causare tutti i problemi. Isolarli su un diverso set di dischi o su dischi di fascia alta più veloci come gli SSD potrebbe essere la migliore soluzione logica.
- Puoi partizionare il database per spostare le tabelle problematiche su un disco diverso per distribuire il carico?
Statistiche di attesa
Proprio come il monitoraggio delle statistiche dei file, il monitoraggio delle statistiche di attesa può dirti molto sui colli di bottiglia nel tuo ambiente. Siamo fortunati ad avere un altro fantastico DMV (sys.dm_os_wait_stats ) che possiamo interrogare che estrarrà tutte le informazioni di attesa disponibili raccolte dall'ultimo riavvio o dall'ultima volta che le attese sono state ripristinate; ci sono anche attese relative alle prestazioni del disco. Questo DMV restituirà informazioni importanti tra cui:
- wait_type
- attesa_task_count
- wait_time_ms
- max_wait_time_ms
- signal_wait_time_ms
L'interrogazione di questo DMV sulla mia macchina SQL Server 2014 ha restituito 771 tipi di attesa. SQL Server è sempre in attesa di qualcosa, ma ci sono molte attese di cui non dovremmo preoccuparci. Per questo motivo, utilizzo un'altra query di Paul Randal; il suo post sul blog, "Aspetta le statistiche, o per favore dimmi dove fa male", ha uno script eccellente che esclude un sacco di attese di cui non ci interessa davvero. Paul elenca anche molte delle attese problematiche comuni e offre una guida per le attese comuni.
Perché le statistiche di attesa sono importanti?
Il monitoraggio di tempi di attesa elevati per determinati eventi ti dirà quando ci sono problemi in corso. Hai bisogno di una linea di base per sapere cosa è normale e quando le cose superano una soglia o un livello di dolore. Se hai un PAGEIOLATCH_XX davvero alto quindi sai che SQL Server deve attendere che una pagina di dati venga letta dal disco. Potrebbe trattarsi di disco, memoria, modifica del carico di lavoro o una serie di altri problemi.
Un recente cliente con cui stavo lavorando stava vedendo un comportamento molto insolito. Quando mi sono connesso al server del database e sono stato in grado di osservare il server sotto un carico di lavoro, ho immediatamente iniziato a controllare le statistiche dei file, le statistiche di attesa, l'utilizzo della memoria, l'utilizzo di tempdb, ecc. Una cosa che si è immediatamente distinto è stata WRITELOG essendo l'attesa più diffusa. So che questa attesa ha a che fare con uno scaricamento del registro su disco e mi ha ricordato la serie di Paul su Trimming the Transaction Log Fat. WRITELOG alto le attese di solito possono essere identificate da latenze di scrittura elevate per il file di registro delle transazioni. Quindi ho quindi utilizzato il mio script delle statistiche dei file per rivedere le latenze di lettura e scrittura sul disco. Sono stato quindi in grado di vedere un'elevata latenza di scrittura sul file di dati ma non sul mio file di registro. Guardando il WRITELOG è stata un'attesa elevata ma il tempo di attesa in ms era estremamente basso. Tuttavia qualcosa nel secondo post della serie di Paul era ancora nella mia testa. Dovrei guardare le impostazioni di crescita automatica per il database solo per escludere "Morte per mille tagli". Osservando le proprietà del database del database ho visto che il file di dati era impostato per aumentare automaticamente di 1 MB e il registro delle transazioni impostato per aumentare automaticamente del 10%. Entrambi i file avevano quasi 0 spazio inutilizzato. Ho condiviso con il cliente ciò che ho trovato e come questo stava uccidendo la loro performance. Abbiamo apportato rapidamente le modifiche appropriate e i test sono andati avanti, molto meglio tra l'altro. Purtroppo questa non è l'unica volta che ho riscontrato questo problema esatto. Un'altra volta un database aveva una dimensione di 66 GB, ci arrivava con una crescita di 1 MB.
Acquisizione dei tuoi dati
Molti professionisti dei dati hanno creato processi per acquisire statistiche su file e attendere regolarmente per l'analisi. Poiché le statistiche di attesa sono cumulative, vorrai acquisirle e confrontare i delta tra diverse ore del giorno o prima e dopo l'esecuzione di determinati processi. Questo non è troppo complicato e ci sono numerosi post sul blog disponibili in cui le persone condividono come ci sono riusciti. La parte importante è misurare questi dati in modo da poterli monitorare. Come fai a sapere oggi che le cose vanno meglio o peggio sul tuo server di database se non conosci i dati di ieri?
Come può aiutare SQL Sentry?
Sono felice che tu l'abbia chiesto! SQL Sentry Performance Advisor porta latenza e attese in primo piano e al centro del dashboard. Eventuali anomalie sono facili da individuare; puoi passare alla modalità storica e vedere la tendenza precedente e confrontarla anche con i periodi precedenti. Questo può rivelarsi inestimabile quando si analizzano quei "che cosa è successo?" momenti. Tutti hanno ricevuto quella chiamata:"Ieri intorno alle 15:00 il sistema sembrava bloccarsi, puoi dirci cosa è successo?" Uhm, certo, fammi tirare su Profiler e tornare indietro nel tempo. Se disponi di uno strumento di monitoraggio come Performance Advisor, avresti le informazioni storiche a portata di mano.
Oltre ai grafici e ai grafici sulla dashboard, hai la possibilità di utilizzare avvisi integrati per condizioni come attese del disco elevate, conteggi VLF elevati, CPU elevata, aspettativa di vita della pagina bassa e molti altri. Hai anche la possibilità di creare le tue condizioni personalizzate e puoi imparare dagli esempi sul sito di SQL Sentry o tramite lo scambio di condizioni (Aaron Bertrand ne ha scritto sul blog). Ho toccato il lato di allerta di questo nel mio ultimo articolo sugli avvisi di SQL Server Agent.
Nella scheda Spazio su disco di Performance Advisor, è molto facile vedere cose come le impostazioni di crescita automatica e conteggi VLF elevati. Dovresti saperlo, ma in caso contrario, la crescita automatica di 1 MB o del 10% non è l'impostazione migliore. Se vedi questi valori (il Performance Advisor li evidenzia per te), puoi prendere rapidamente nota e programmare il tempo per apportare le modifiche appropriate. Adoro il modo in cui mostra anche i VLF totali; troppi VLF possono essere molto problematici. Dovresti leggere il post di Kimberly "Transaction Log VLF:troppi o troppo pochi?" se non l'hai già fatto.
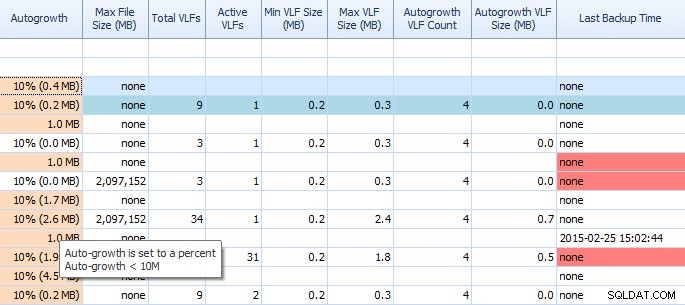 Griglia parziale nella scheda Spazio su disco di Performance Advisor
Griglia parziale nella scheda Spazio su disco di Performance Advisor
Un altro modo in cui Performance Advisor può aiutare è attraverso il suo modulo Disk Activity brevettato. Qui puoi vedere che tempdb su F:sta riscontrando una notevole latenza di scrittura; puoi dirlo dalle spesse linee rosse sotto la grafica del disco. Potresti anche notare che F:è l'unica lettera di unità il cui disco è rappresentato in rosso; questo è un segnale visivo che l'unità ha una partizione disallineata, che può contribuire a problemi di I/O.
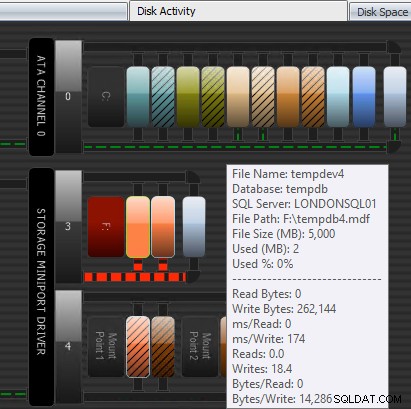 Modulo Attività disco di Performance Advisor
Modulo Attività disco di Performance Advisor
E puoi correlare queste informazioni nelle griglie sottostanti:i problemi sono evidenziati anche nelle griglie lì, e dai un'occhiata a ms/Write colonna:
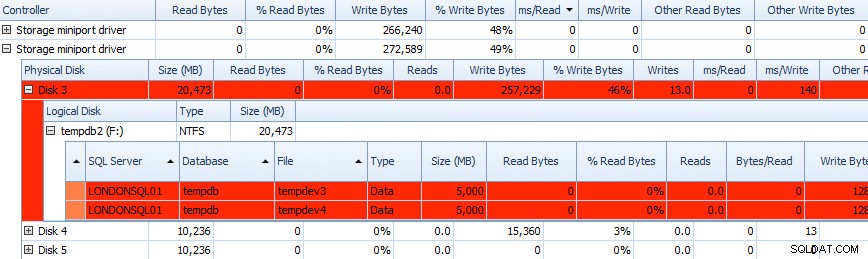 Griglia parziale dei dati sull'attività del disco di Performance Advisor
Griglia parziale dei dati sull'attività del disco di Performance Advisor
Puoi anche guardare queste informazioni retroattivamente; se qualcuno si lamenta di un collo di bottiglia del disco percepito ieri pomeriggio o martedì scorso, puoi semplicemente tornare indietro utilizzando i selettori di data nella barra degli strumenti e vedere il throughput e la latenza medi per qualsiasi intervallo. Per ulteriori informazioni sul modulo Attività del disco, vedere la Guida per l'utente.
Performance Advisor ha anche molti report integrati nelle categorie Performance, Blocking, Top SQL, Disk/File Space e Deadlock. L'immagine seguente mostra come accedere ai rapporti Spazio su disco/file. Avere i rapporti a pochi clic del mouse è molto prezioso per poter accedere immediatamente e visualizzare ciò che sta (o stava) accadendo sul tuo server.
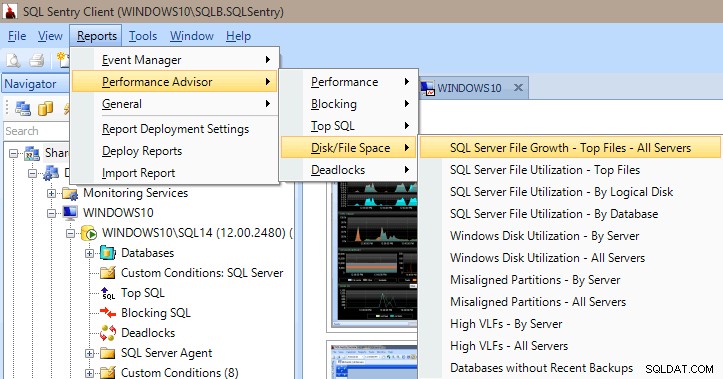 Rapporti di Performance Advisor
Rapporti di Performance Advisor
Riepilogo
L'importante risultato di questo post è conoscere le tue metriche di performance. Un'affermazione comune tra i professionisti dei dati è che il disco è il nostro collo di bottiglia n. 1. Conoscere le statistiche dei file del tuo server aiuterà molto a capire i punti deboli del tuo server. Insieme alle statistiche dei file, anche le tue statistiche di attesa sono un ottimo posto dove guardare. Molte persone, me compreso, iniziano da lì. Avere uno strumento come SQL Sentry Performance Advisor può aiutarti drasticamente a risolvere e trovare problemi di prestazioni prima che diventino troppo problematici; tuttavia, se non disponi di uno strumento del genere, familiarizza con sys.dm_os_wait_stats e sys.dm_io_virtual_file_stats ti servirà bene per iniziare a ottimizzare il tuo server.



