Amazon ha rilasciato S3 all'inizio del 2006 e il primo strumento che consente agli script di backup PostgreSQL di caricare dati nel cloud, s3cmd, è nato poco meno di un anno dopo. Entro il 2010 (secondo le mie capacità di ricerca su Google) aprire blog BI a riguardo. È quindi sicuro affermare che alcuni dei DBA di PostgreSQL hanno eseguito il backup dei dati su AWS S3 per ben 9 anni. Ma come? E cosa è cambiato in quel tempo? Sebbene alcuni facciano ancora riferimento a s3cmd nel contesto di noti strumenti di backup PostgreSQL, i metodi hanno subito modifiche che consentono una migliore integrazione con il filesystem o le opzioni di backup native di PostgreSQL al fine di raggiungere gli obiettivi di ripristino desiderati RTO e RPO.
Perché Amazon S3
Come sottolineato nella documentazione di Amazon S3 (le domande frequenti su S3 sono un ottimo punto di partenza), i vantaggi dell'utilizzo del servizio S3 sono:
- Durata 99.999999999 (undici nove)
- Archiviazione dati illimitata
- costi contenuti (ancora più bassi se abbinati a BitTorrent)
- traffico di rete in entrata gratuito
- È fatturabile solo il traffico di rete in uscita
Preparazioni della CLI di AWS S3
Il toolkit AWS S3 CLI fornisce tutti gli strumenti necessari per trasferire i dati dentro e fuori lo storage S3, quindi perché non utilizzare questi strumenti? La risposta si trova nei dettagli di implementazione di Amazon S3 che includono misure per la gestione delle limitazioni e dei vincoli relativi allo storage degli oggetti:
- Dimensione massima di 5 TB per oggetto archiviato
- Dimensione massima di 5 GB di un oggetto PUT
- Caricamento in più parti consigliato per oggetti di dimensioni superiori a 100 MB
- scegliere una classe di storage appropriata in conformità con il grafico delle prestazioni S3
- sfrutta il ciclo di vita di S3
- Modello di coerenza dei dati S3
A titolo di esempio, fare riferimento alla pagina di aiuto di aws s3 cp:
--expected-size (string) Questo argomento specifica la dimensione prevista di un flusso in termini di byte. Tieni presente che questo argomento è necessario solo quando uno stream viene caricato su s3 e la dimensione è maggiore di 5 GB. La mancata inclusione di questo argomento in queste condizioni potrebbe comportare un caricamento non riuscito a causa di troppe parti in caricamento.
Evitare queste insidie richiede una conoscenza approfondita dell'ecosistema S3, che è ciò che gli strumenti di backup PostgreSQL e S3 appositamente creati stanno cercando di ottenere.
Strumenti di backup nativi PostgreSQL con supporto Amazon S3
L'integrazione S3 è fornita da alcuni dei noti strumenti di backup, che implementano le funzionalità di backup native di PostgreSQL.
BarmanS3
BarmanS3 è implementato come script Barman Hook. Si basa su AWS CLI, senza affrontare i consigli e le limitazioni sopra elencati. La semplice configurazione lo rende un buon candidato per piccole installazioni. Lo sviluppo è in qualche modo bloccato, ultimo aggiornamento circa un anno fa, rendendo questo prodotto una scelta per chi già utilizza Barman nei propri ambienti.
Scarica S3
S3dumps è un progetto attivo, implementato utilizzando la libreria Python di Amazon Boto3. L'installazione è facilmente eseguita tramite pip. Sebbene si basi su Amazon S3 Python SDK, una ricerca nel codice sorgente di parole chiave regex come multi.*part o storage.*class non rivela nessuna delle funzionalità avanzate di S3, come i trasferimenti multipart.
pgBackRest
pgBackRest implementa S3 come opzione di repository. Questo è uno dei ben noti strumenti di backup di PostgreSQL, che fornisce un set ricco di funzionalità di opzioni di backup come backup e ripristino paralleli, crittografia e supporto per tablespace. Si tratta principalmente di codice C, che fornisce la velocità e il throughput che stiamo cercando, tuttavia, quando si tratta di interagire con l'API S3 di AWS, ciò ha il prezzo del lavoro aggiuntivo richiesto per l'implementazione delle funzionalità di storage S3. La versione recente implementa il caricamento in più parti S3.
WAL-G
WAL-G annunciato 2 anni fa viene attivamente mantenuto. Questo solido strumento di backup PostgreSQL implementa classi di archiviazione, ma non il caricamento in più parti (la ricerca nel codice di CreateMultipartUpload non ha trovato alcuna occorrenza).
PGHoard
pghoard è stato rilasciato circa 3 anni fa. È uno strumento di backup PostgreSQL performante e ricco di funzionalità con supporto per trasferimenti multiparte S3. Non offre nessuna delle altre funzionalità di S3 come la classe di archiviazione e la gestione del ciclo di vita degli oggetti.
S3 come filesystem locale
Essere in grado di accedere allo storage S3 come filesystem locale è una caratteristica altamente desiderata in quanto apre la possibilità di utilizzare gli strumenti di backup nativi di PostgreSQL.
Per gli ambienti Linux, Amazon offre due opzioni:NFS e iSCSI. Sfruttano l'AWS Storage Gateway.
NFS
Una condivisione NFS montata localmente viene fornita dal servizio file AWS Storage Gateway. In base al collegamento dobbiamo creare un File Gateway.
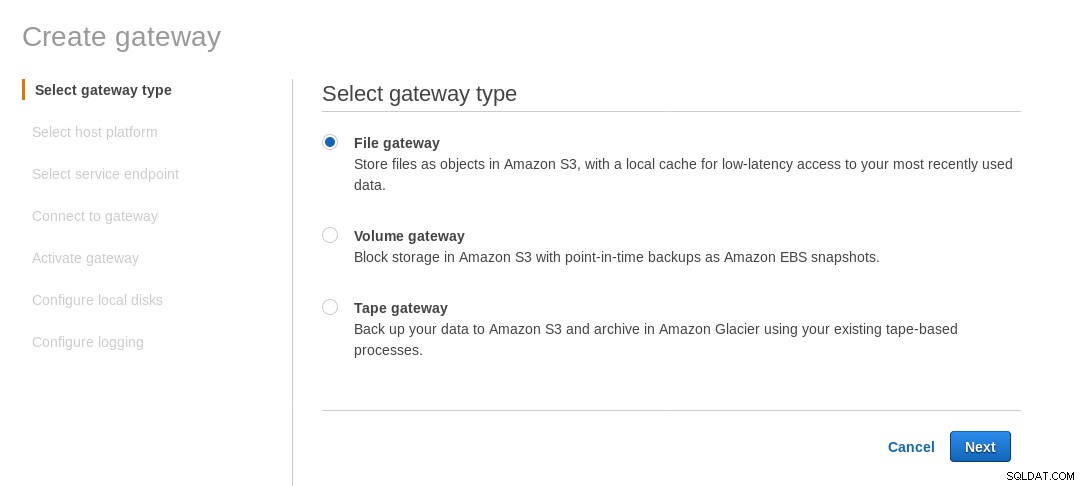
Nella schermata Seleziona piattaforma host, seleziona Amazon EC2 e fai clic sul pulsante Avvia istanza per avviare la procedura guidata EC2 per la creazione dell'istanza.
Ora, solo per la curiosità di questo amministratore di sistema, esaminiamo l'AMI utilizzata dalla procedura guidata in quanto ci offre una prospettiva interessante su alcuni dei pezzi interni di AWS. Con l'ID immagine noto ami-0bab9d6dffb52fef5 diamo un'occhiata ai dettagli:
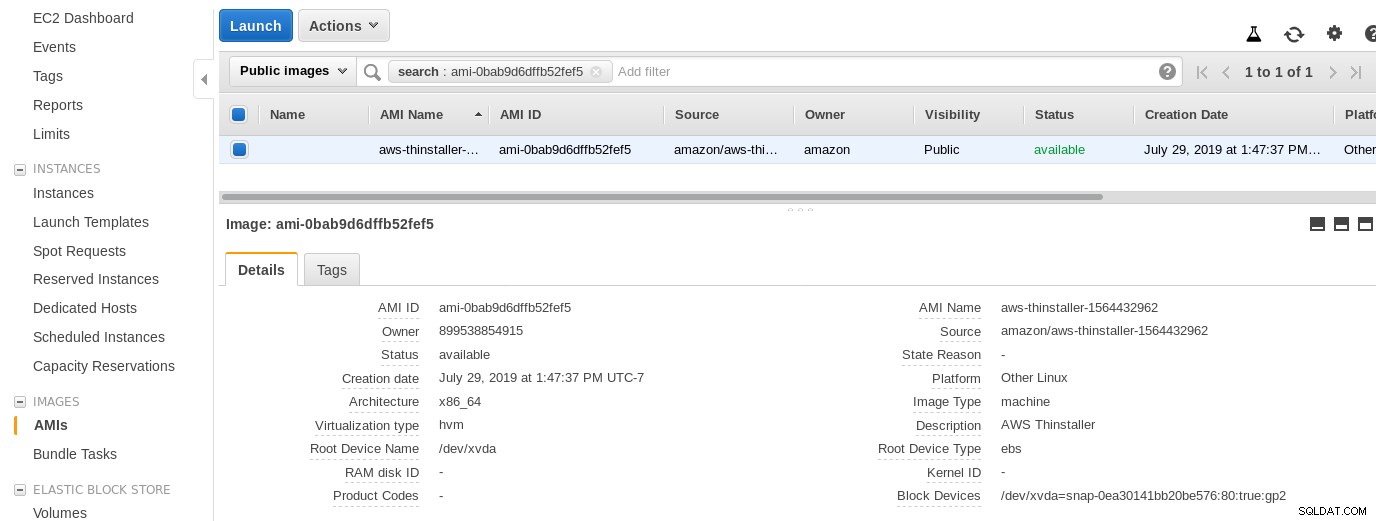
Come mostrato sopra, il nome dell'AMI è aws-thinstaller, quindi cos'è un "thinstaller"? Le ricerche su Internet rivelano che Thinstaller è uno strumento di gestione della configurazione del software IBM Lenovo per i prodotti Microsoft e viene citato prima in questo blog del 2008 e successivamente in questo post sul forum Lenovo e in questa richiesta di servizio del distretto scolastico. Non avevo modo di saperlo, poiché il mio lavoro di amministratore di sistema di Windows è terminato 3 anni prima. Così come questa AMI è stata creata con il prodotto Thinstaller Per rendere le cose ancora più confuse, il sistema operativo AMI è elencato come "Altro Linux" che può essere confermato da SSH-ing nel sistema come amministratore.
Una procedura guidata ha capito:nonostante le istruzioni di configurazione del firewall EC2, il mio browser si stava verificando in timeout durante la connessione al gateway di archiviazione. L'autorizzazione della porta 80 è documentata in Requisiti delle porte:potremmo sostenere che la procedura guidata dovrebbe elencare tutte le porte richieste o collegarsi alla documentazione, tuttavia, nello spirito del cloud, la risposta è "automatizzare" con strumenti come CloudFormation.
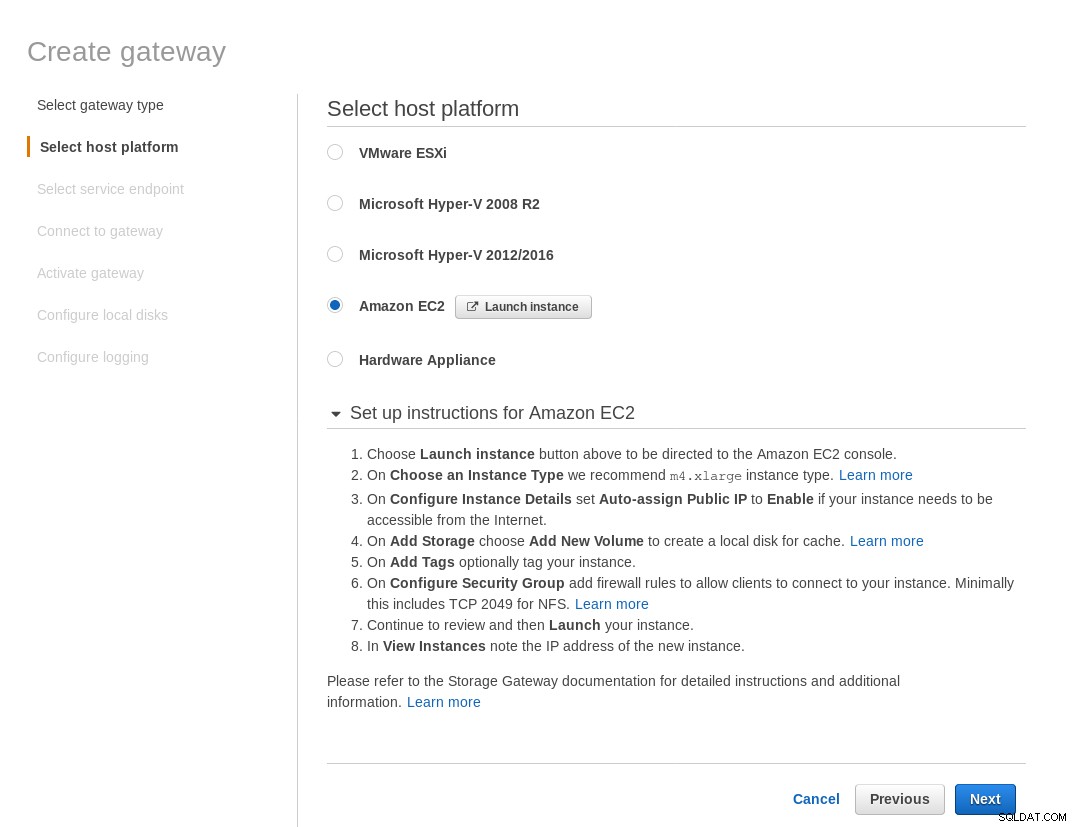
La procedura guidata suggerisce anche di iniziare con un'istanza di dimensioni xlarge.
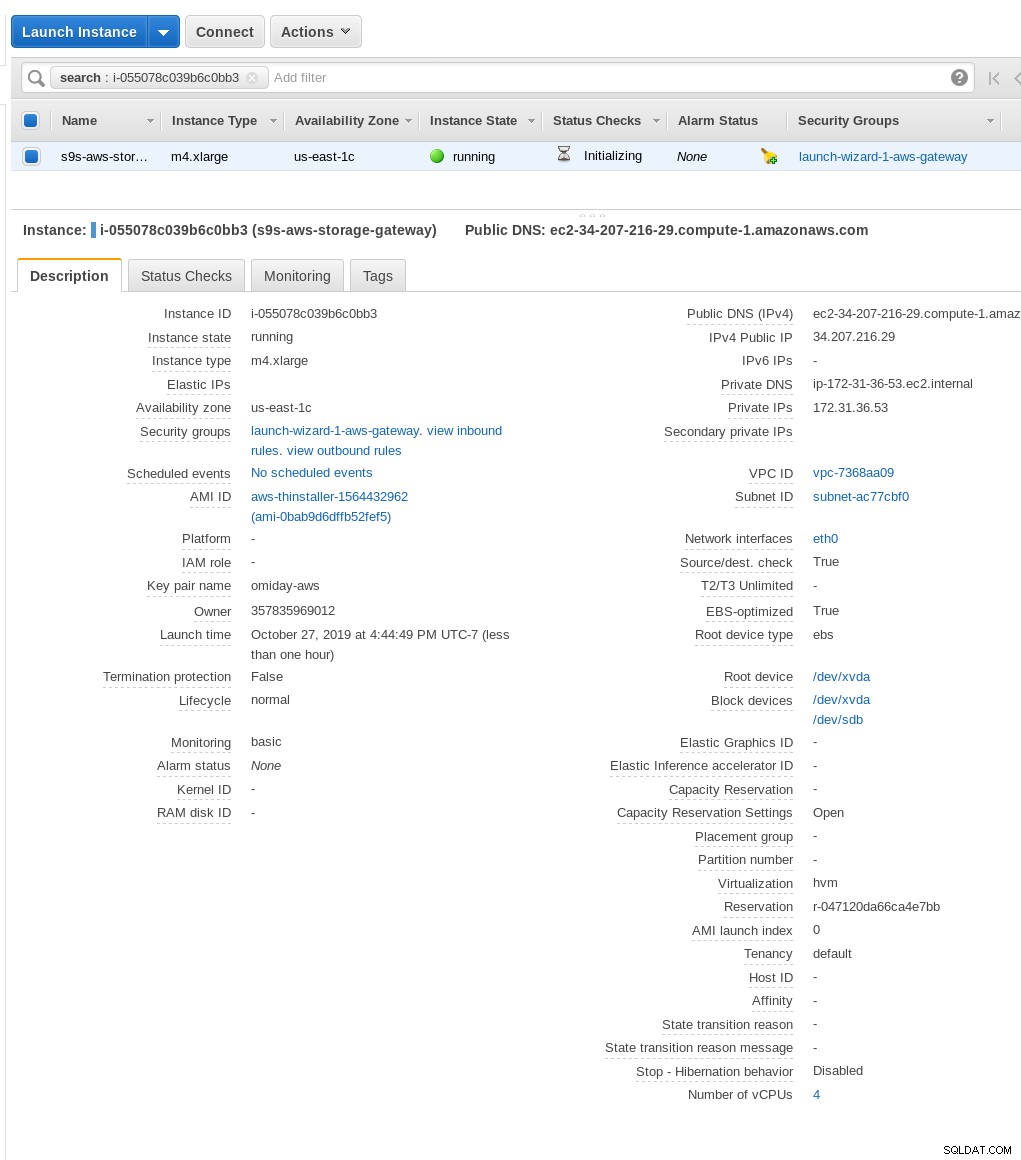
Una volta che il gateway di archiviazione è pronto, configura la condivisione NFS facendo clic su Crea pulsante di condivisione file nel menu Gateway:
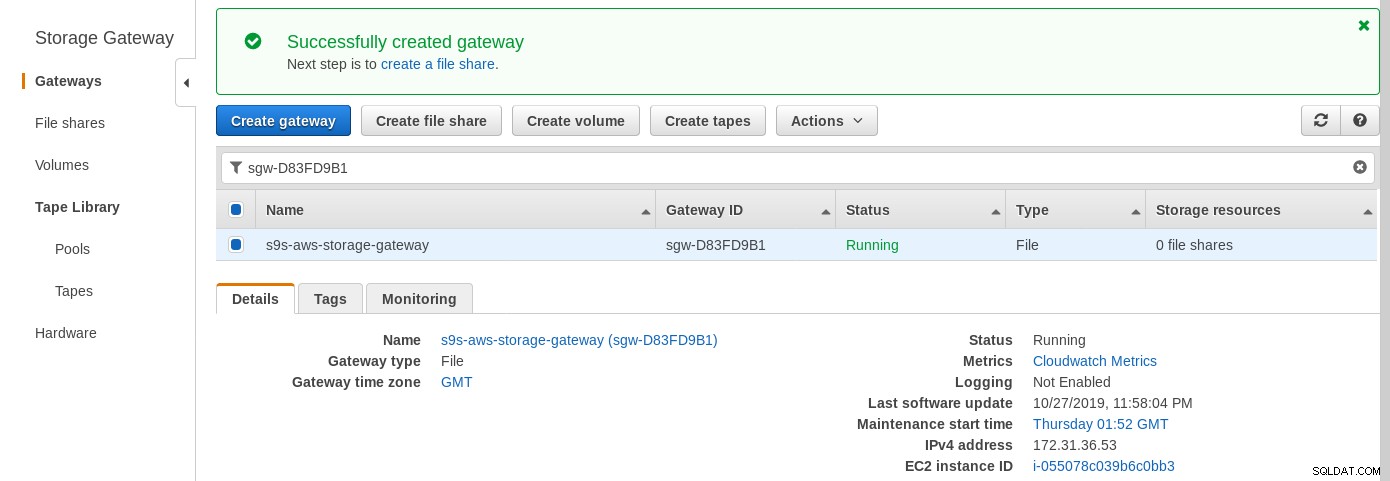
Una volta che la condivisione NFS è pronta, segui le istruzioni per montare il filesystem:
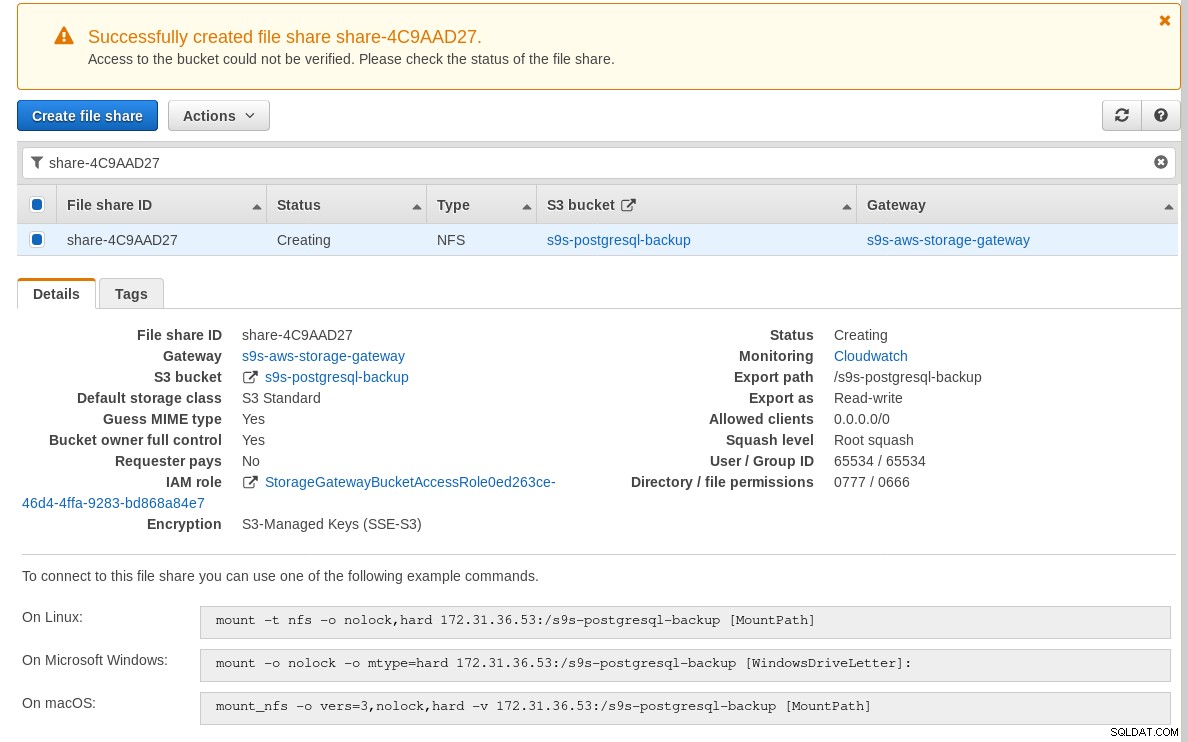
Nello screenshot sopra, nota che il comando mount fa riferimento all'IP privato dell'istanza indirizzo. Per eseguire il montaggio da un host pubblico, utilizza l'indirizzo pubblico dell'istanza come mostrato nei dettagli dell'istanza EC2 sopra.
La procedura guidata non si bloccherà se il bucket S3 non esiste al momento della creazione della condivisione file, tuttavia, una volta creato il bucket S3 è necessario riavviare l'istanza, altrimenti il comando mount fallisce con:
[example@sqldat.com ~]# mount -t nfs -o nolock,hard 34.207.216.29:/s9s-postgresql-backup /mnt
mount.nfs: mounting 34.207.216.29:/s9s-postgresql-backup failed, reason given by server: No such file or directoryVerifica che la condivisione sia stata resa disponibile:
[example@sqldat.com ~]# df -h /mnt
Filesystem Size Used Avail Use% Mounted on
34.207.216.29:/s9s-postgresql-backup 8.0E 0 8.0E 0% /mntOra eseguiamo un rapido test:
example@sqldat.com[local]:54311 postgres# \l+ test
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
test | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 2763 MB | pg_default |
(1 row)
[example@sqldat.com ~]# date ; time pg_dump -d test | gzip -c >/mnt/test.pg_dump.gz ; date
Sun 27 Oct 2019 06:06:24 PM PDT
real 0m29.807s
user 0m15.909s
sys 0m2.040s
Sun 27 Oct 2019 06:06:54 PM PDTTieni presente che il timestamp dell'ultima modifica sul bucket S3 è di circa un minuto dopo, il che, come accennato in precedenza, è dovuto al modello di coerenza dei dati di Amazon S3.
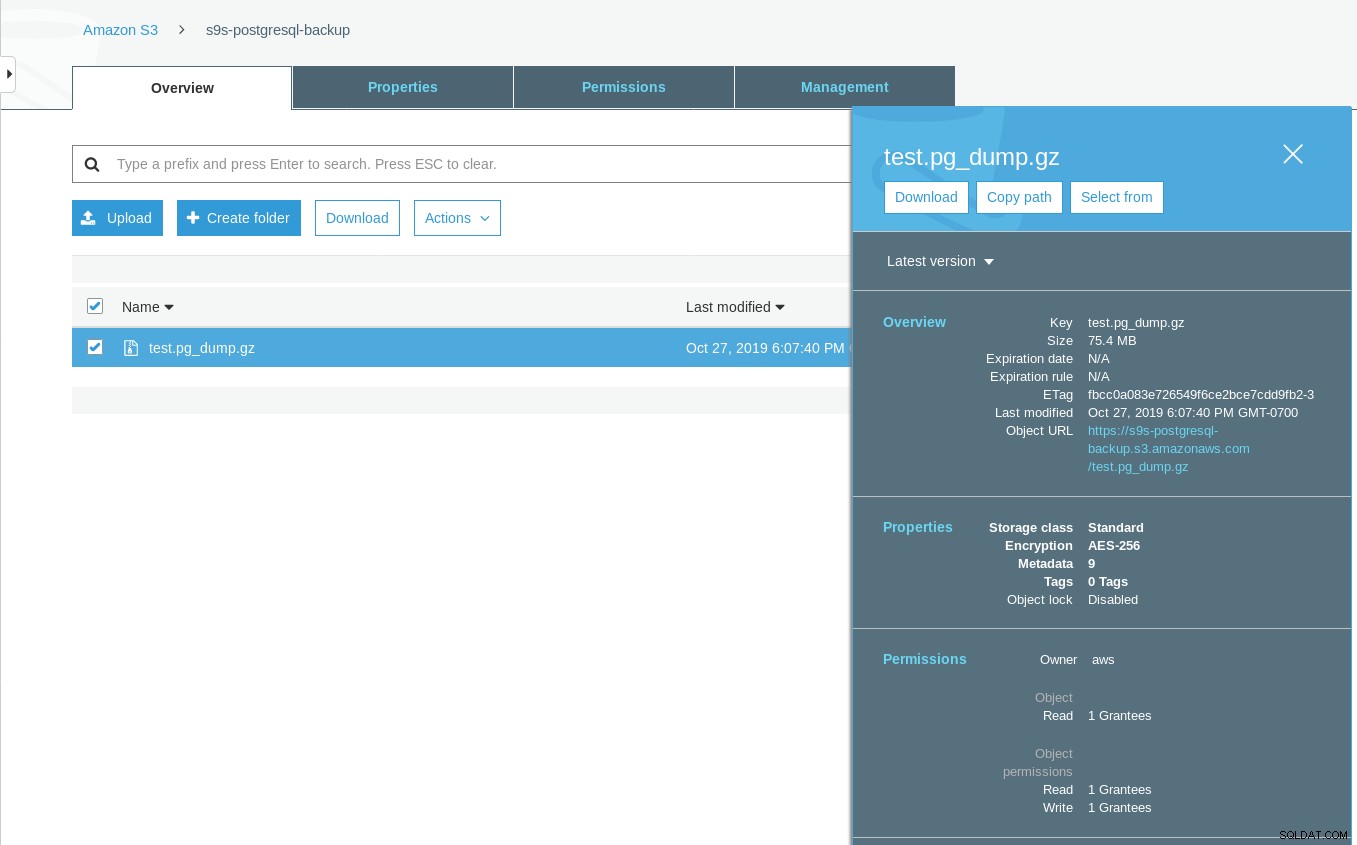
Ecco un test più esauriente:
~ $ for q in {0..20} ; do touch /mnt/touched-at-$(date +%Y%m%d%H%M%S) ;
sleep 1 ; done
~ $ aws s3 ls s3://s9s-postgresql-backup | nl
1 2019-10-27 19:50:40 0 touched-at-20191027194957
2 2019-10-27 19:50:40 0 touched-at-20191027194958
3 2019-10-27 19:50:40 0 touched-at-20191027195000
4 2019-10-27 19:50:40 0 touched-at-20191027195001
5 2019-10-27 19:50:40 0 touched-at-20191027195002
6 2019-10-27 19:50:40 0 touched-at-20191027195004
7 2019-10-27 19:50:40 0 touched-at-20191027195005
8 2019-10-27 19:50:40 0 touched-at-20191027195007
9 2019-10-27 19:50:40 0 touched-at-20191027195008
10 2019-10-27 19:51:10 0 touched-at-20191027195009
11 2019-10-27 19:51:10 0 touched-at-20191027195011
12 2019-10-27 19:51:10 0 touched-at-20191027195012
13 2019-10-27 19:51:10 0 touched-at-20191027195013
14 2019-10-27 19:51:10 0 touched-at-20191027195014
15 2019-10-27 19:51:10 0 touched-at-20191027195016
16 2019-10-27 19:51:10 0 touched-at-20191027195017
17 2019-10-27 19:51:10 0 touched-at-20191027195018
18 2019-10-27 19:51:10 0 touched-at-20191027195020
19 2019-10-27 19:51:10 0 touched-at-20191027195021
20 2019-10-27 19:51:10 0 touched-at-20191027195022
21 2019-10-27 19:51:10 0 touched-at-20191027195024Un altro problema degno di nota:dopo aver giocato con varie configurazioni, creato e distrutto gateway e condivisioni, ad un certo punto durante il tentativo di attivare un gateway di file, stavo ricevendo un errore interno:
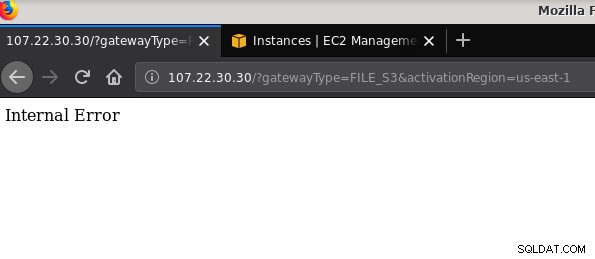
La riga di comando fornisce alcuni dettagli in più, sebbene non indichi alcun problema:
~$ curl -sv "https://107.22.30.30/?gatewayType=FILE_S3&activationRegion=us-east-1"
* Trying 107.22.30.30:80...
* TCP_NODELAY set
* Connected to 107.22.30.30 (107.22.30.30) port 80 (#0)
> GET /?gatewayType=FILE_S3&activationRegion=us-east-1 HTTP/1.1
> Host: 107.22.30.30
> User-Agent: curl/7.65.3
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 500 Internal Server Error
< Date: Mon, 28 Oct 2019 06:33:30 GMT
< Content-type: text/html
< Content-length: 14
<
* Connection #0 to host 107.22.30.30 left intact
Internal Error~ $Questo post del forum ha indicato che il mio problema potrebbe avere qualcosa a che fare con l'endpoint VPC che avevo creato. La mia soluzione è stata l'eliminazione dell'endpoint VPC che avevo configurato durante varie prove iSCSI e esecuzioni di errore.
Mentre S3 crittografa i dati inattivi, il traffico via cavo NFS è in testo normale. Ad esempio, ecco un dump di pacchetto tcpdump:
23:47:12.225273 IP 192.168.0.11.936 > 107.22.30.30.2049: Flags [P.], seq 2665:3377, ack 2929, win 501, options [nop,nop,TS val 1899459538 ecr 38013066], length 712: NFS request xid 3511704119 708 getattr fh 0,2/53
example@sqldat.com@.......k....... ...c..............
q7s..D.......PZ7...........................4........omiday.can.local...................................................5.......]...........!....................C...
..............&...........]....................# inittab is no longer used.
#
# ADDING CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.
#
# Ctrl-Alt-Delete is handled by /usr/lib/systemd/system/ctrl-alt-del.target
#
# systemd uses 'targets' instead of runlevels. By default, there are two main targets:
#
# multi-user.target: analogous to runlevel 3
# graphical.target: analogous to runlevel 5
#
# To view current default target, run:
# systemctl get-default
#
# To set a default target, run:
# systemctl set-default TARGET.target
..... .........0..
23:47:12.331592 IP 107.22.30.30.2049 > 192.168.0.11.936: Flags [P.], seq 2929:3109, ack 3377, win 514, options [nop,nop,TS val 38013174 ecr 1899459538], length 180: NFS reply xid 3511704119 reply ok 176 getattr NON 4 ids 0/33554432 sz -2138196387Fino all'approvazione di questa bozza IEE, l'unica opzione sicura per la connessione dall'esterno di AWS è l'utilizzo di un tunnel VPN. Ciò complica la configurazione, rendendo l'opzione NFS in sede meno interessante rispetto agli strumenti basati su FUSE di cui parlerò un po' più avanti.
iSCSI
Questa opzione è fornita dal servizio AWS Storage Gateway Volume. Una volta configurato il servizio, vai alla sezione di configurazione del client iSCSI Linux.
Il vantaggio dell'utilizzo di iSCSI su NFS consiste nella possibilità di sfruttare i servizi di backup, clonazione e snapshot nativi del cloud Amazon. Per i dettagli e le istruzioni dettagliate, segui i collegamenti a AWS Backup, Volume Cloning e Snapshot EBS
Sebbene ci siano molti vantaggi, c'è un'importante restrizione che probabilmente eliminerà molti utenti:non è possibile accedere al gateway tramite il suo indirizzo IP pubblico. Quindi, proprio come l'opzione NFS, questo requisito aggiunge complessità alla configurazione.
Nonostante la chiara limitazione e convinto che non sarò in grado di completare questa configurazione, volevo comunque avere un'idea di come è stato fatto. La procedura guidata reindirizza a una schermata di configurazione di AWS Marketplace.
Si noti che la procedura guidata Marketplace crea un disco secondario, tuttavia non abbastanza grande in size, e quindi dobbiamo ancora aggiungere i due volumi richiesti come indicato dalle istruzioni di configurazione dell'host. Se i requisiti di archiviazione non sono soddisfatti, la procedura guidata si bloccherà nella schermata di configurazione dei dischi locali:
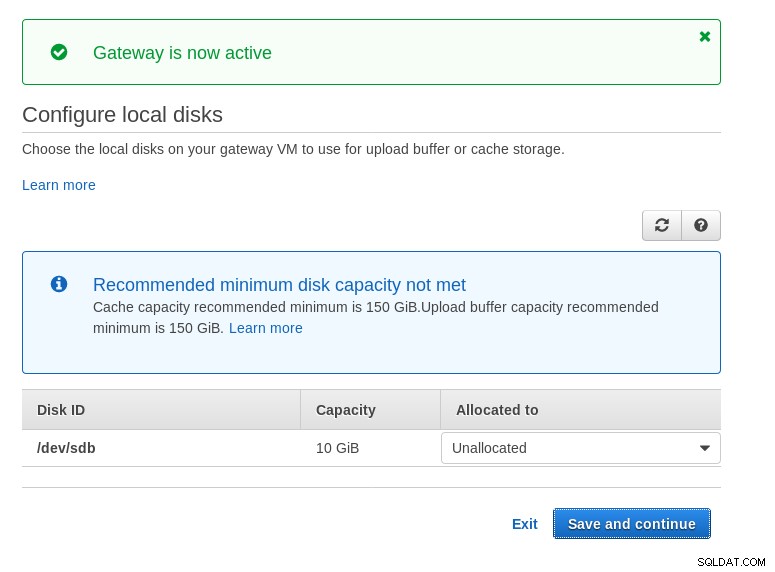
Ecco uno sguardo alla schermata di configurazione di Amazon Marketplace:
C'è un'interfaccia di testo accessibile tramite SSH (accedi come utente sguser) che fornisce strumenti di base per la risoluzione dei problemi di rete e altre opzioni di configurazione che non possono essere eseguite tramite la GUI Web:
~ $ ssh example@sqldat.com
Warning: Permanently added 'ec2-3-231-96-109.compute-1.amazonaws.com,3.231.96.109' (ECDSA) to the list of known hosts.
'screen.xterm-256color': unknown terminal type.
AWS Storage Gateway Configuration
#######################################################################
## Currently connected network adapters:
##
## eth0: 172.31.1.185
#######################################################################
1: SOCKS Proxy Configuration
2: Test Network Connectivity
3: Gateway Console
4: View System Resource Check (0 Errors)
0: Stop AWS Storage Gateway
Press "x" to exit session
Enter command:E un paio di altri punti importanti:
- Contrariamente alla configurazione di NFS, non è disponibile l'accesso diretto allo storage S3, come indicato nella sezione delle domande frequenti su Volume Gateway.
- La documentazione AWS insiste sulla personalizzazione delle impostazioni iSCSI al fine di migliorare le prestazioni e la sicurezza della connessione.
FUSIBILE
In questa categoria ho elencato gli strumenti basati su FUSE che forniscono una compatibilità S3 più completa rispetto agli strumenti di backup PostgreSQL e, a differenza di Amazon Storage Gateway, consentono il trasferimento di dati da un host on-premise su Amazon S3 senza configurazione aggiuntiva. Tale configurazione potrebbe fornire l'archiviazione S3 come filesystem locale che gli strumenti di backup di PostgreSQL possono utilizzare per sfruttare funzionalità come pg_dump parallelo.
s3fs-fuse
s3fs-fuse è scritto in C++, un linguaggio supportato dal toolkit Amazon S3 SDK, e come tale è adatto per implementare funzionalità S3 avanzate come caricamenti multipart, memorizzazione nella cache, classe di storage S3, server- crittografia laterale e selezione della regione. È anche altamente compatibile con POSIX.
L'applicazione è inclusa con il mio Fedora 30 rendendo l'installazione semplice.
Per testare:
~/mnt/s9s $ time pg_dump -d test | gzip -c >test.pg_dump-$(date +%Y%m%d-%H%M%S).gz
real 0m35.761s
user 0m16.122s
sys 0m2.228s
~/mnt/s9s $ aws s3 ls s3://s9s-postgresql-backup
2019-10-28 03:16:03 79110010 test.pg_dump-20191028-031535.gzSi noti che la velocità è leggermente inferiore rispetto all'utilizzo di Amazon Storage Gateway con l'opzione NFS. Compensa le prestazioni inferiori fornendo un filesystem altamente compatibile con POSIX.
S3QL
S3QL fornisce funzionalità S3 come la classe di archiviazione e la crittografia lato server. Le numerose funzionalità sono descritte nell'esauriente documentazione S3QL, tuttavia, se stai cercando il caricamento in più parti, non è menzionato da nessuna parte. Questo perché S3QL implementa il proprio algoritmo di suddivisione dei file per fornire la funzione di deduplicazione. Tutti i file sono suddivisi in blocchi da 10 MB.
L'installazione su un sistema basato su Red Hat è semplice:installa le dipendenze RPM richieste tramite yum:
sqlite-devel-3.7.17-8.14.amzn1.x86_64
fuse-devel-2.9.4-1.18.amzn1.x86_64
fuse-2.9.4-1.18.amzn1.x86_64
system-rpm-config-9.0.3-42.28.amzn1.noarch
python36-devel-3.6.8-1.14.amzn1.x86_64
kernel-headers-4.14.146-93.123.amzn1.x86_64
glibc-headers-2.17-260.175.amzn1.x86_64
glibc-devel-2.17-260.175.amzn1.x86_64
gcc-4.8.5-1.22.amzn1.noarch
gcc48-4.8.5-28.142.amzn1.x86_64
mpfr-3.1.1-4.14.amzn1.x86_64
libmpc-1.0.1-3.3.amzn1.x86_64
libgomp-6.4.1-1.45.amzn1.x86_64
libgcc48-4.8.5-28.142.amzn1.x86_64
cpp48-4.8.5-28.142.amzn1.x86_64
python36-pip-9.0.3-1.26.amzn1.noarch
python36-libs-3.6.8-1.14.amzn1.x86_64
python36-3.6.8-1.14.amzn1.x86_64
python36-setuptools-36.2.7-1.33.amzn1.noarchQuindi installa le dipendenze Python usando pip3:
pip-3.6 install setuptools cryptography defusedxml apsw dugong pytest requests llfuse==1.3.6Una caratteristica notevole di questo strumento è il filesystem S3QL creato sopra il bucket S3.
Goofy
goofys è un'opzione quando le prestazioni superano la conformità POSIX. I suoi obiettivi sono l'opposto di s3fs-fuse. L'attenzione alla velocità si riflette anche nel modello di distribuzione. Per Linux ci sono binari precompilati. Una volta scaricato, esegui:
~/temp/goofys $ ./goofys s9s-postgresql-backup ~/mnt/s9s/E backup:
~/mnt/s9s $ time pg_dump -d test | gzip -c >test.pg_dump-$(date +%Y%m%d-%H%M%S).gz
real 0m27.427s
user 0m15.962s
sys 0m2.169s
~/mnt/s9s $ aws s3 ls s3://s9s-postgresql-backup
2019-10-28 04:29:05 79110010 test.pg_dump-20191028-042902.gzNota che il tempo di creazione dell'oggetto su S3 è a soli 3 secondi dal timestamp del file.
ObjectFS
Sembra che ObjectFS sia stato mantenuto fino a circa 6 mesi fa. Un controllo per il caricamento in più parti rivela che non è implementato, dal documento di ricerca dell'autore apprendiamo che il sistema è ancora in fase di sviluppo e poiché il documento è stato pubblicato nel 2019 ho pensato che valesse la pena menzionarlo.
Clienti S3
Come accennato in precedenza, per utilizzare l'AWS S3 CLI, dobbiamo prendere in considerazione diversi aspetti specifici dell'object storage in generale e di Amazon S3 in particolare. Se l'unico requisito è la capacità di trasferire i dati dentro e fuori lo storage S3, allora uno strumento che segua da vicino i consigli di Amazon S3 può fare il lavoro.
s3cmd è uno degli strumenti che ha superato la prova del tempo. Questo blog di Open BI del 2010 ne parla, in un momento in cui S3 era il nuovo arrivato.
Caratteristiche notevoli:
- Crittografia lato server
- caricamenti multiparte automatici
- Limitazione della larghezza di banda
Vai a S3cmd:FAQ e Knowledge Base per ulteriori informazioni.
Conclusione
Le opzioni disponibili per il backup di un cluster PostgreSQL su Amazon S3 differiscono nei metodi di trasferimento dei dati e nel modo in cui si allineano con le strategie Amazon S3.
AWS Storage Gateway integra lo storage di oggetti S3 di Amazon, a costo di una maggiore complessità e delle conoscenze aggiuntive necessarie per ottenere il massimo da questo servizio. Ad esempio, la selezione del numero corretto di dischi richiede un'attenta pianificazione e una buona conoscenza dei costi relativi a S3 di Amazon è un must per ridurre al minimo i costi operativi.
Sebbene sia applicabile a qualsiasi cloud storage non solo Amazon S3, la decisione di archiviare i dati in un cloud pubblico ha implicazioni sulla sicurezza. Amazon S3 fornisce la crittografia per i dati inattivi e in transito, senza alcuna garanzia di conoscenza zero o prove di conoscenza. Le organizzazioni che desiderano avere il controllo completo sui propri dati dovrebbero implementare la crittografia lato client e archiviare le chiavi di crittografia all'esterno della propria infrastruttura AWS.
Per alternative commerciali alla mappatura di S3 su un filesystem locale vale la pena dare un'occhiata ai prodotti di ObjectiveFS o NetApp.
Infine, le organizzazioni che cercano di sviluppare i propri strumenti di backup, sia basandosi sulle basi fornite dalle numerose applicazioni open source, sia partendo da zero, dovrebbero prendere in considerazione l'utilizzo del test di compatibilità S3, reso disponibile dal progetto Ceph.