Nella sezione commenti di uno dei nostri blog un lettore ha chiesto informazioni sull'impatto di wsrep_slave_threads sulle prestazioni e sulla scalabilità di I/O di Galera Cluster. A quel tempo, non potevamo rispondere facilmente a questa domanda ed eseguirne il backup con più dati, ma alla fine siamo riusciti a configurare l'ambiente ed eseguire alcuni test.
Il nostro lettore ha indicato benchmark che hanno mostrato che l'aumento di wsrep_slave_threads non ha avuto alcun impatto sulle prestazioni del cluster Galera.
Per spiegare qual è l'impatto di tale impostazione, abbiamo creato un piccolo cluster di tre nodi (m5d.xlarge). Questo ci ha permesso di utilizzare SSD nvme direttamente collegato per la directory dei dati MySQL. In questo modo, abbiamo ridotto al minimo la possibilità che lo spazio di archiviazione diventasse il collo di bottiglia nella nostra configurazione.
Impostiamo il pool di buffer InnoDB su 8 GB e ripetiamo i registri su due file, 1 GB ciascuno. Abbiamo anche aumentato innodb_io_capacity a 2000 e innodb_io_capacity_max a 10000. Ciò aveva anche lo scopo di garantire che nessuna di queste impostazioni avrebbe avuto un impatto sulle nostre prestazioni.
L'intero problema con tali benchmark è che ci sono così tanti colli di bottiglia che devi eliminarli uno per uno. Solo dopo aver apportato alcune modifiche alla configurazione e dopo essersi assicurati che l'hardware non costituisca un problema, si può sperare che vengano visualizzati alcuni limiti più sottili.
Abbiamo generato circa 90 GB di dati utilizzando sysbench:
sysbench /usr/share/sysbench/oltp_write_only.lua --threads=16 --events=0 --time=600 --mysql-host=172.30.4.245 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=3306 --tables=28 --report-interval=1 --skip-trx=off --table-size=10000000 --db-ps-mode=disable --mysql-db=sbtest_large prepareQuindi il benchmark è stato eseguito. Abbiamo testato due impostazioni:wsrep_slave_threads=1 e wsrep_slave_threads=16. L'hardware non era abbastanza potente per trarre vantaggio dall'aumento ulteriormente di questa variabile. Tieni inoltre presente che non abbiamo eseguito un benchmarking dettagliato per determinare se wsrep_slave_threads debba essere impostato su 16, 8 o forse 4 per ottenere le migliori prestazioni. Eravamo interessati a vedere se possiamo mostrare un impatto sul cluster. E sì, l'impatto era chiaramente visibile. Per cominciare, alcuni grafici di controllo del flusso.
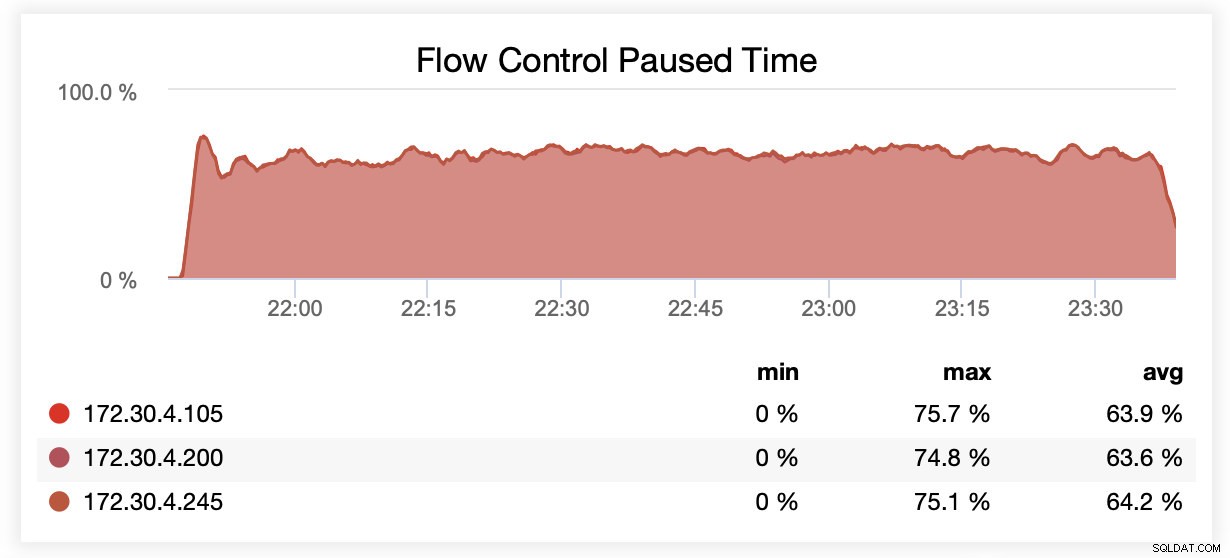
Durante l'esecuzione con wsrep_slave_threads=1, in media, i nodi sono stati sospesi a causa del controllo del flusso circa il 64% delle volte.
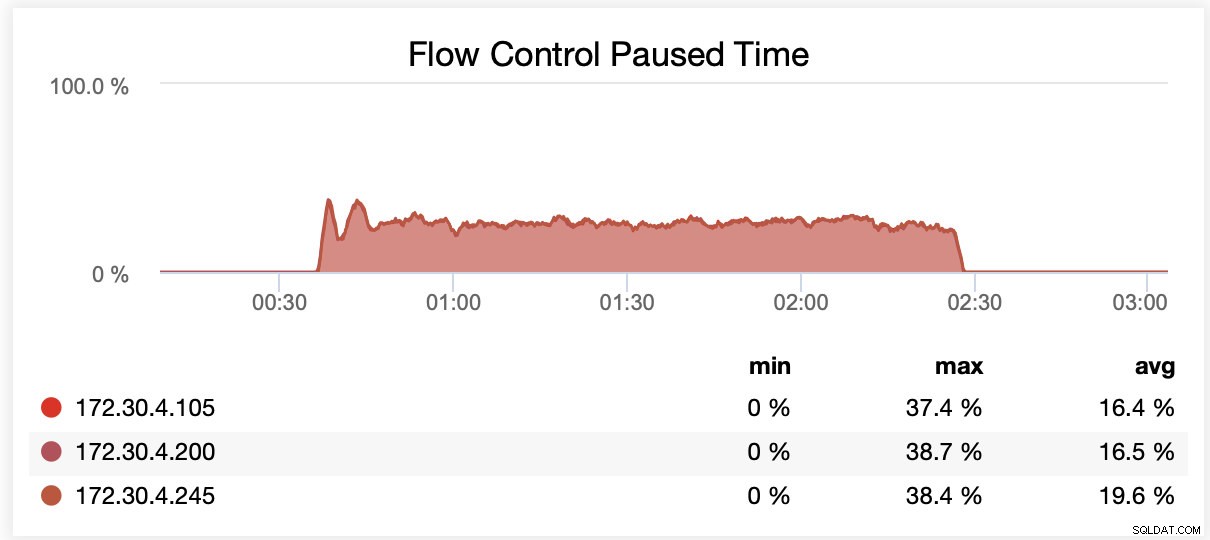
Durante l'esecuzione con wsrep_slave_threads=16, in media, i nodi sono stati sospesi a causa del controllo del flusso circa il 20% delle volte.
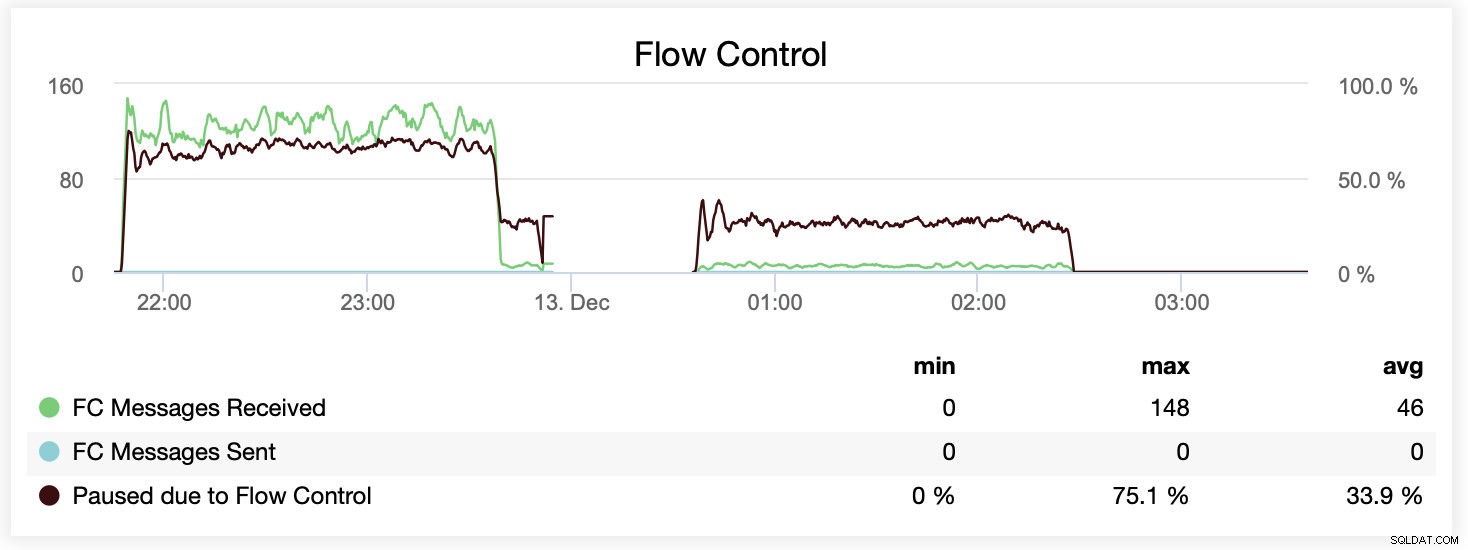
Puoi anche confrontare la differenza su un singolo grafico. Il drop alla fine della prima parte è il primo tentativo di eseguire con wsrep_slave_threads=16. I server hanno esaurito lo spazio su disco per i log binari e abbiamo dovuto rieseguire il benchmark ancora una volta in un secondo momento.
Come si è tradotto questo in termini di prestazioni? La differenza è visibile anche se sicuramente non così spettacolare.
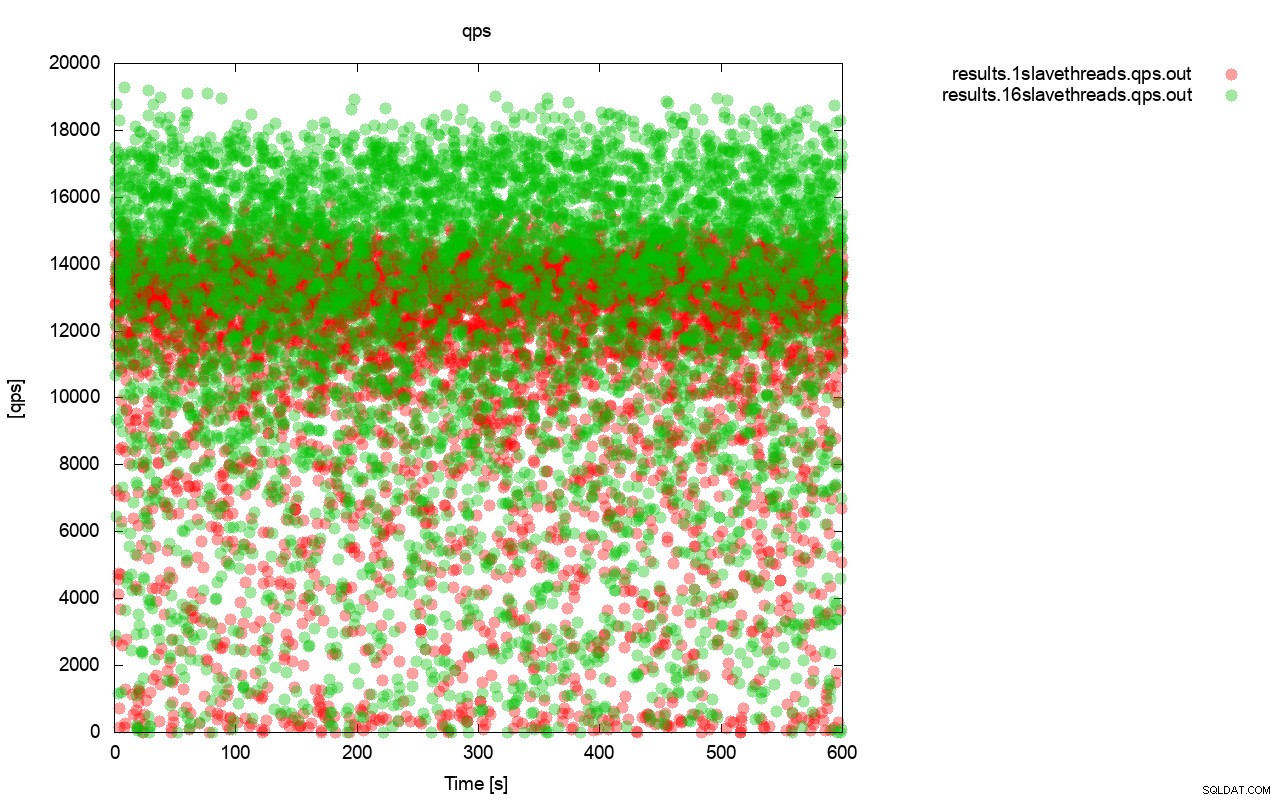
Innanzitutto, il grafico della query al secondo. Innanzitutto, puoi notare che in entrambi i casi i risultati sono dappertutto. Ciò è principalmente correlato alle prestazioni instabili dell'archiviazione I/O e al controllo del flusso che si attiva casualmente. Puoi ancora vedere che le prestazioni del risultato "rosso" (wsrep_slave_threads=1) sono piuttosto inferiori a quello "verde" ( wsrep_slave_threads=16).
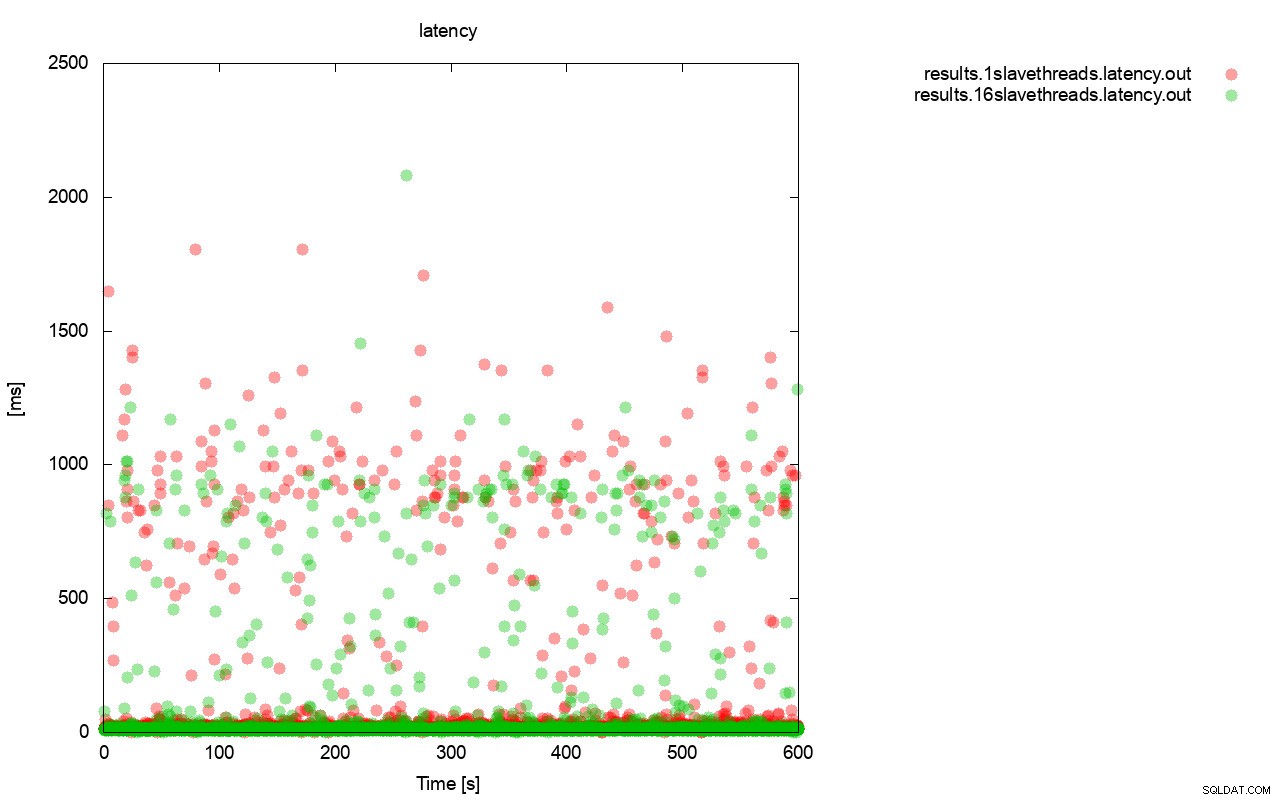
Un'immagine abbastanza simile è quando osserviamo la latenza. Puoi vedere più (e in genere più profondi) stalli per la corsa con wsrep_slave_thread=1.
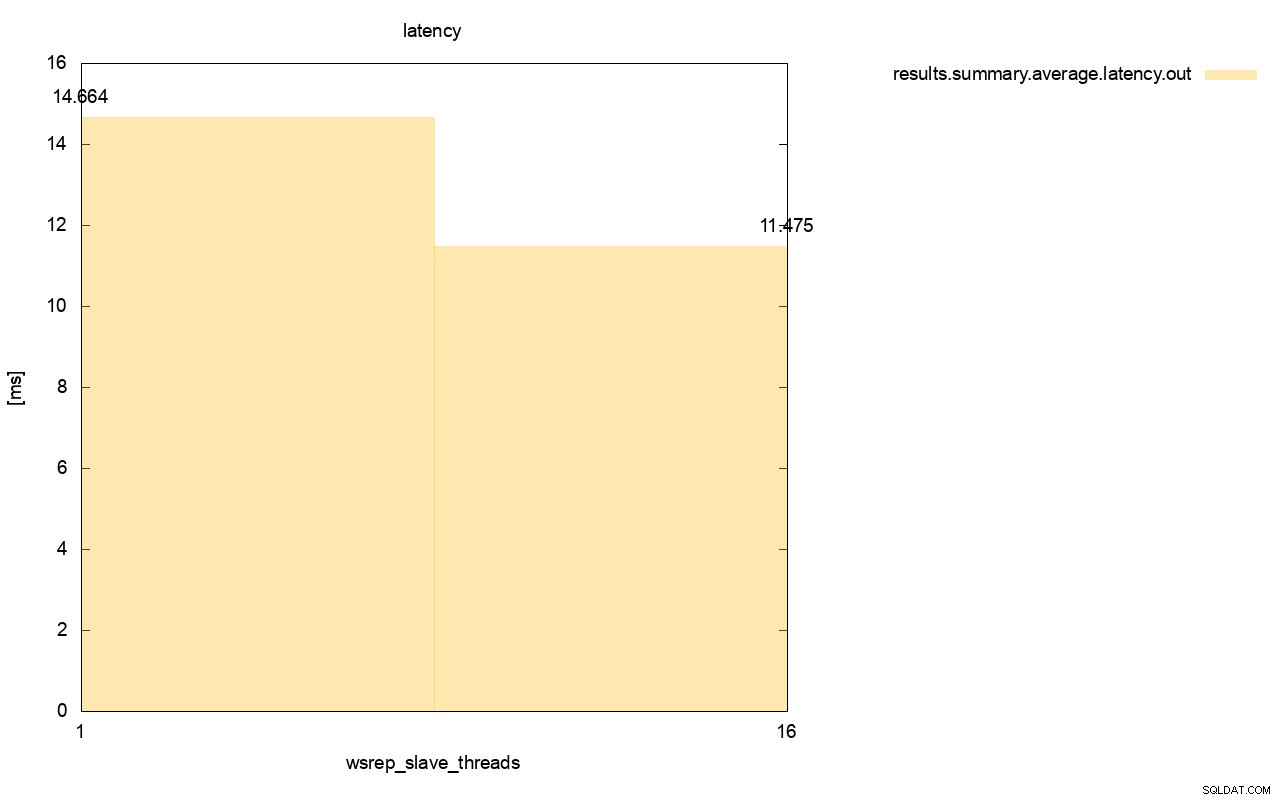
La differenza è ancora più visibile quando abbiamo calcolato la latenza media su tutte le esecuzioni e puoi vedere che la latenza di wsrep_slave_thread=1 è superiore del 27% rispetto alla latenza con 16 thread slave, il che ovviamente non va bene perché vogliamo che la latenza sia inferiore , non superiore.
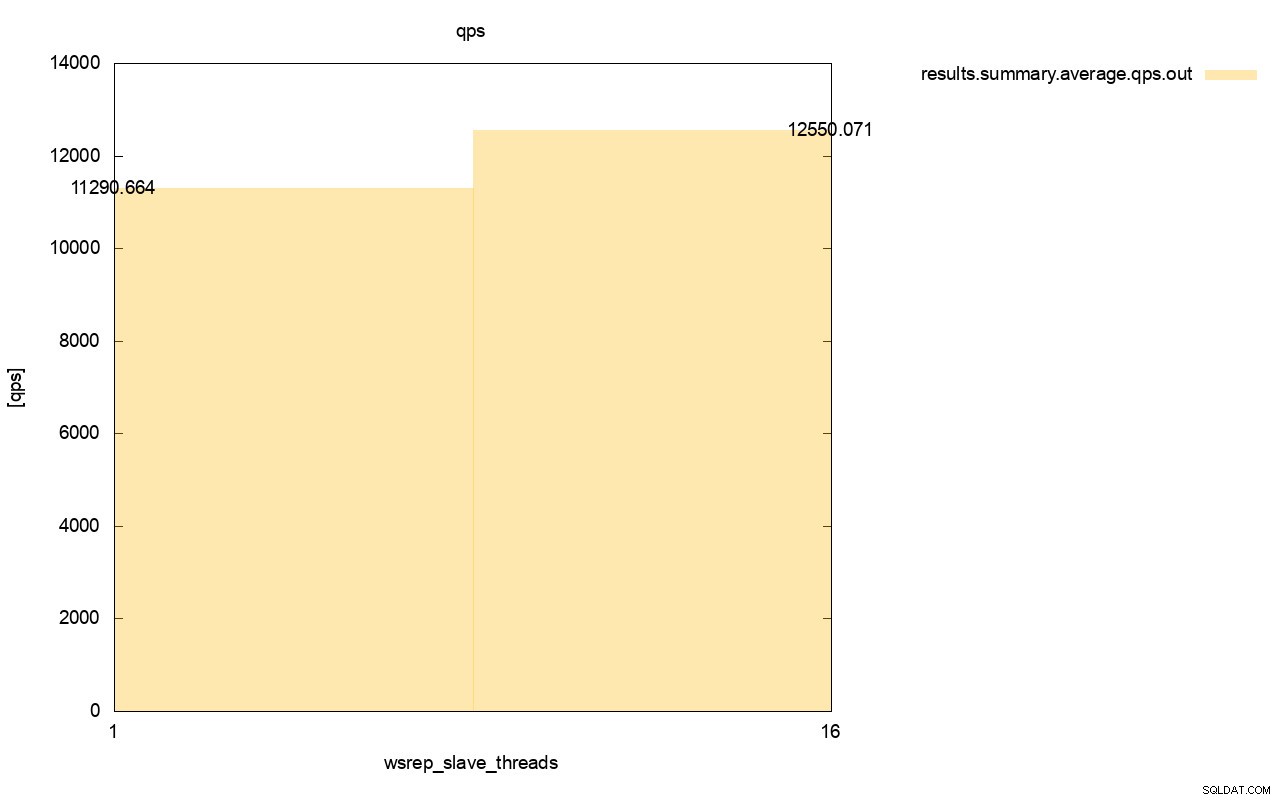
È visibile anche la differenza nel throughput, circa l'11% del miglioramento quando abbiamo aggiunto più wsrep_slave_threads.
Come puoi vedere, l'impatto c'è. Non è affatto 16x (anche se è così che abbiamo aumentato il numero di thread slave in Galera) ma è decisamente abbastanza evidente da non poterlo classificare come una semplice anomalia statistica.
Tieni presente che nel nostro caso abbiamo utilizzato nodi piuttosto piccoli. La differenza dovrebbe essere ancora più significativa se parliamo di istanze di grandi dimensioni in esecuzione su volumi EBS con migliaia di IOPS con provisioning.
Quindi saremmo in grado di eseguire sysbench in modo ancora più aggressivo, con un numero maggiore di operazioni simultanee. Ciò dovrebbe migliorare la parallelizzazione dei set di scrittura, migliorando ulteriormente il guadagno dal multithreading. Inoltre, un hardware più veloce significa che Galera sarà in grado di utilizzare quei 16 thread in modo più efficiente.
Quando si eseguono test come questo, è necessario tenere a mente che è necessario spingere la propria configurazione quasi al limite. La replica a thread singolo può gestire un carico piuttosto elevato ed è necessario eseguire un traffico intenso per renderlo effettivamente non sufficientemente performante per gestire l'attività.
Ci auguriamo che questo post del blog ti fornisca maggiori informazioni sulle capacità di Galera Cluster di applicare i set di scrittura in parallelo e sui fattori limitanti che li circondano.