Le query devono essere memorizzate nella cache in ogni database pesantemente caricato, semplicemente non c'è modo per un database di gestire tutto il traffico con prestazioni ragionevoli. Esistono vari meccanismi in cui è possibile implementare una cache di query. A partire dalla cache delle query MySQL, che in passato funzionava perfettamente per carichi di lavoro prevalentemente di sola lettura, a bassa concorrenza e che non ha posto in carichi di lavoro simultanei elevati (nella misura in cui Oracle l'ha rimossa in MySQL 8.0), agli archivi di valori-chiave esterni come Redis, memcached o CouchBase.
Il problema principale con l'utilizzo di un archivio dati esterno dedicato (poiché non consigliamo di utilizzare la cache delle query MySQL a nessuno) è che questo è l'ennesimo archivio dati da gestire. È ancora un altro ambiente da mantenere, problemi di scalabilità da gestire, bug di cui eseguire il debug e così via.
Allora perché non prendere due piccioni con una fava sfruttando il tuo proxy? Il presupposto qui è che stai usando un proxy nel tuo ambiente di produzione, in quanto aiuta a bilanciare il carico delle query tra istanze e maschera la topologia del database sottostante fornendo un semplice endpoint alle applicazioni. ProxySQL è un ottimo strumento per il lavoro, in quanto può anche funzionare come un livello di memorizzazione nella cache. In questo post del blog, ti mostreremo come memorizzare nella cache le query in ProxySQL utilizzando ClusterControl.
Come funziona la cache delle query in ProxySQL?
Prima di tutto, un po' di sfondo. ProxySQL gestisce il traffico tramite regole di query e può eseguire la memorizzazione nella cache delle query utilizzando lo stesso meccanismo. ProxySQL archivia le query memorizzate nella cache in una struttura di memoria. I dati memorizzati nella cache vengono eliminati utilizzando l'impostazione TTL (time-to-live). Il TTL può essere definito individualmente per ogni regola di query, quindi spetta all'utente decidere se le regole di query devono essere definite per ogni singola query, con TTL distinto o se deve solo creare un paio di regole che corrispondano alla maggior parte delle il traffico.
Esistono due impostazioni di configurazione che definiscono come deve essere utilizzata una cache di query. Innanzitutto, mysql-query_cache_size_MB che definisce un limite morbido alla dimensione della cache della query. Non è un limite rigido, quindi ProxySQL potrebbe utilizzare una quantità di memoria leggermente superiore a quella, ma è sufficiente per tenere sotto controllo l'utilizzo della memoria. La seconda impostazione che puoi modificare è mysql-query_cache_stores_empty_result . Definisce se un set di risultati vuoto è memorizzato nella cache o meno.
La cache delle query ProxySQL è progettata come un archivio di valori-chiave. Il valore è il set di risultati di una query e la chiave è composta da valori concatenati come:utente, schema e testo della query. Quindi viene creato un hash da quella stringa e quell'hash viene utilizzato come chiave.
Configurazione di ProxySQL come cache di query utilizzando ClusterControl
Come configurazione iniziale, abbiamo un cluster di replica di un master e uno slave. Abbiamo anche un unico ProxySQL.
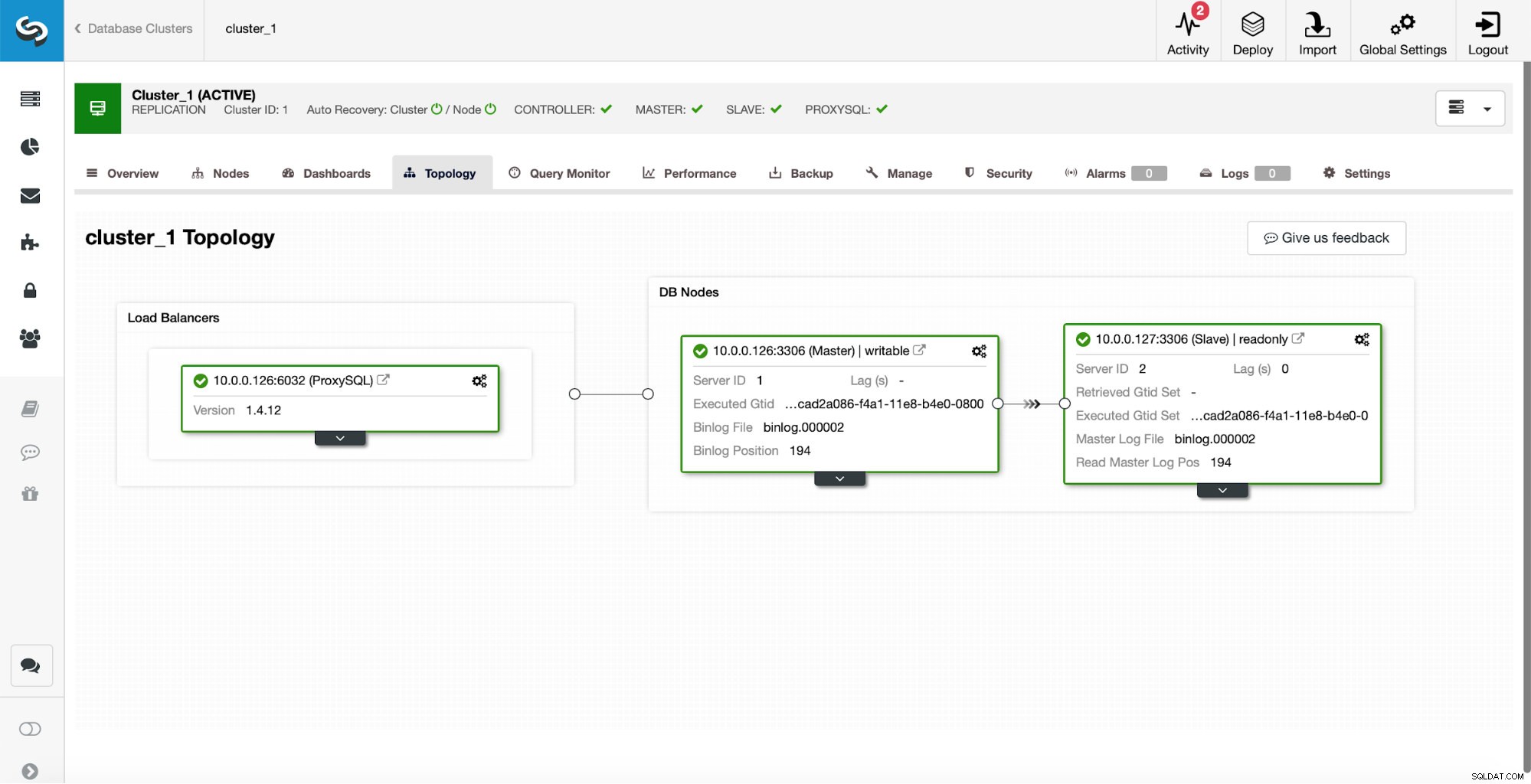
Questa non è affatto una configurazione di livello produttivo in quanto dovremmo implementare una sorta di alta disponibilità per il livello proxy (ad esempio distribuendo più di un'istanza ProxySQL e quindi mantenerle in vita per l'IP virtuale mobile), ma sarà più che sufficiente per i nostri test.
Innanzitutto, verificheremo la configurazione di ProxySQL per assicurarci che le impostazioni della cache delle query siano quelle che vogliamo che siano.
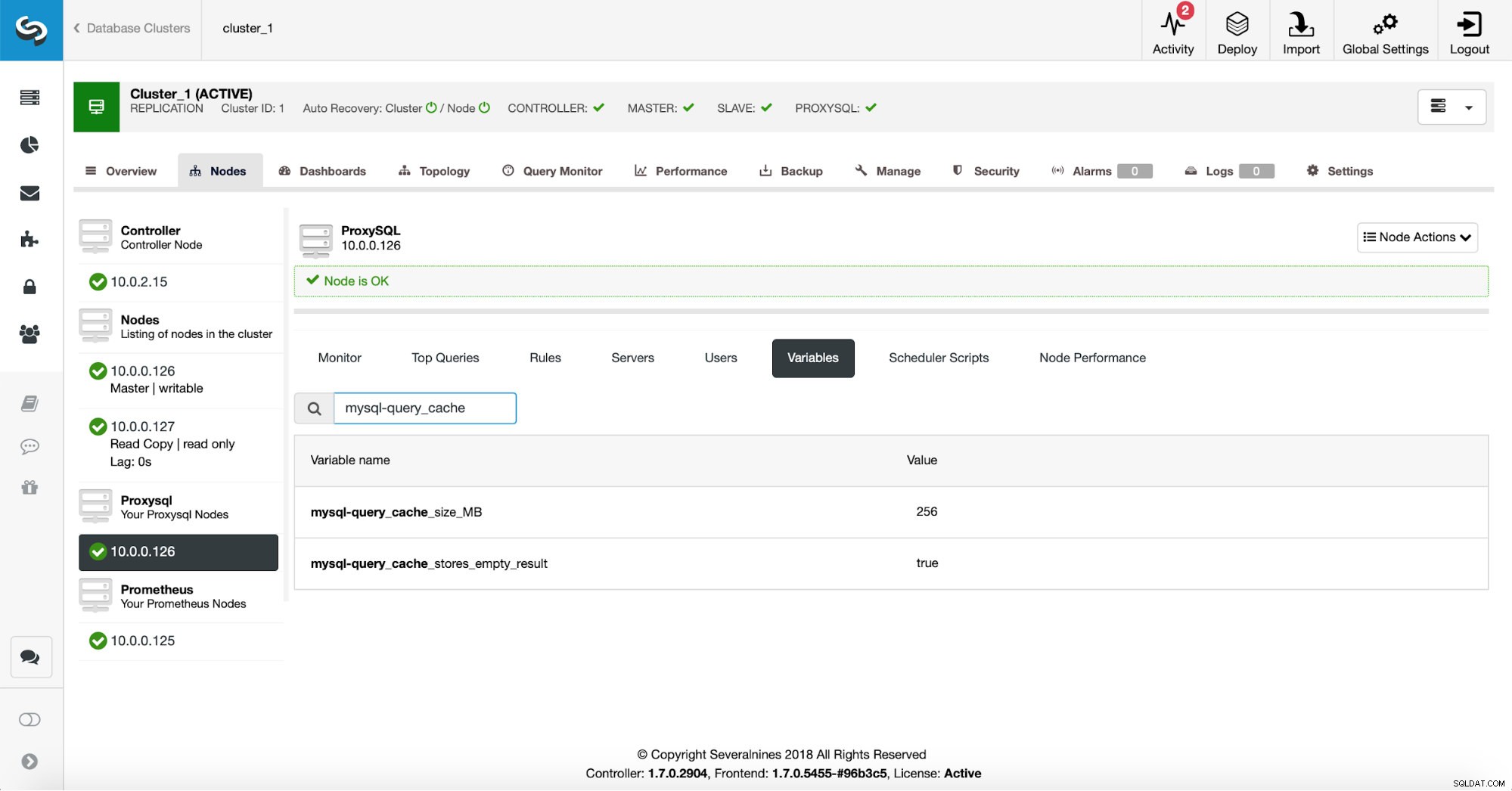
256 MB di cache delle query dovrebbero essere circa corretti e vogliamo memorizzare nella cache anche i set di risultati vuoti:a volte una query che non restituisce dati deve ancora fare molto lavoro per verificare che non ci sia nulla da restituire.
Il passaggio successivo consiste nel creare regole di query che corrispondano alle query che desideri memorizzare nella cache. Esistono due modi per farlo in ClusterControl.
Aggiunta manuale di regole di query
Il primo modo richiede un po' più di azioni manuali. Utilizzando ClusterControl è possibile creare facilmente qualsiasi regola di query desiderata, comprese le regole di query che eseguono la memorizzazione nella cache. Per prima cosa, diamo un'occhiata all'elenco delle regole:
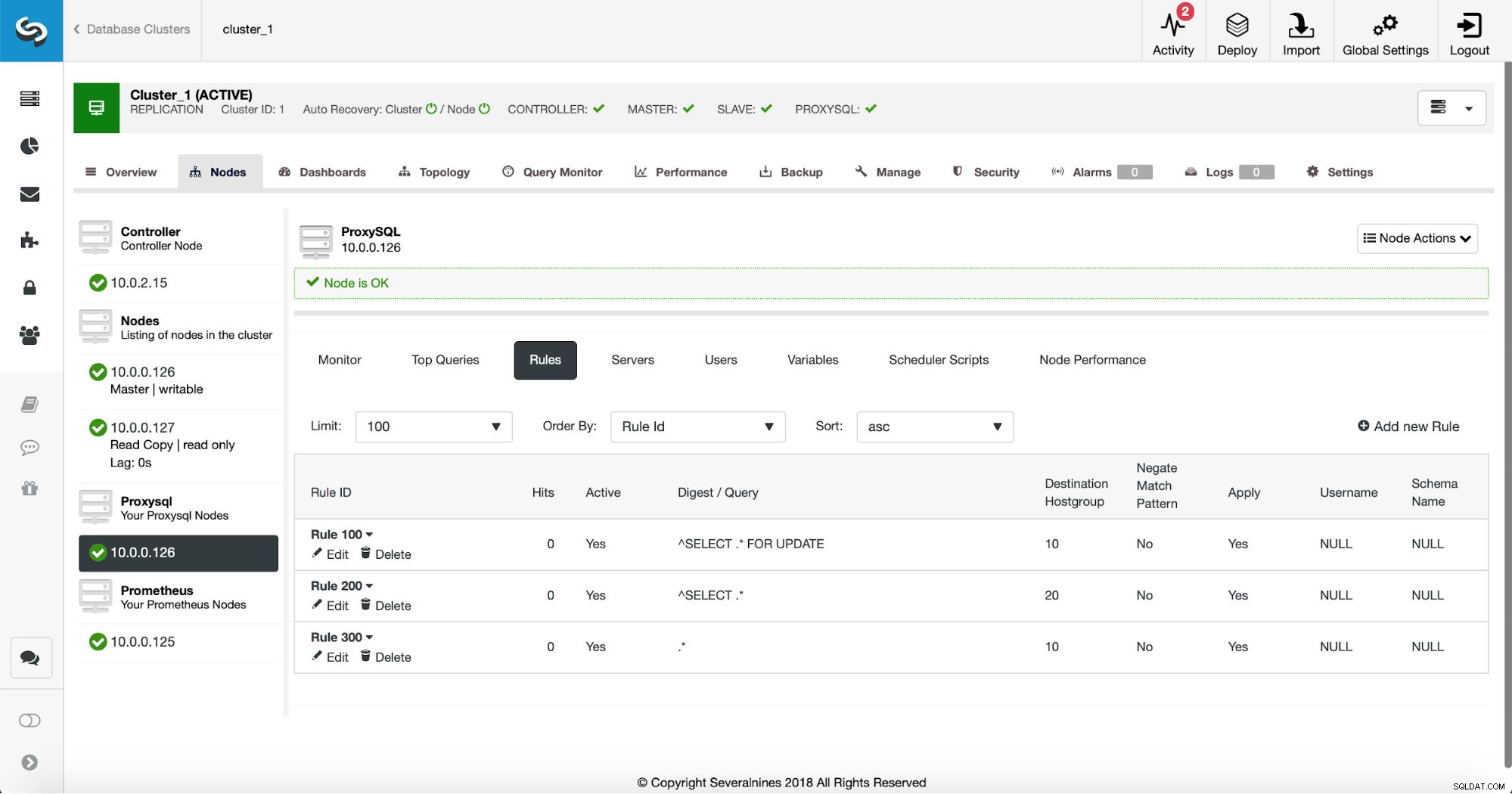
A questo punto, abbiamo una serie di regole di query per eseguire la suddivisione in lettura/scrittura. La prima regola ha un ID di 100. La nostra nuova regola di query deve essere elaborata prima di quella, quindi utilizzeremo un ID regola inferiore. Creiamo una regola di query che eseguirà la memorizzazione nella cache di query simili a questa:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY c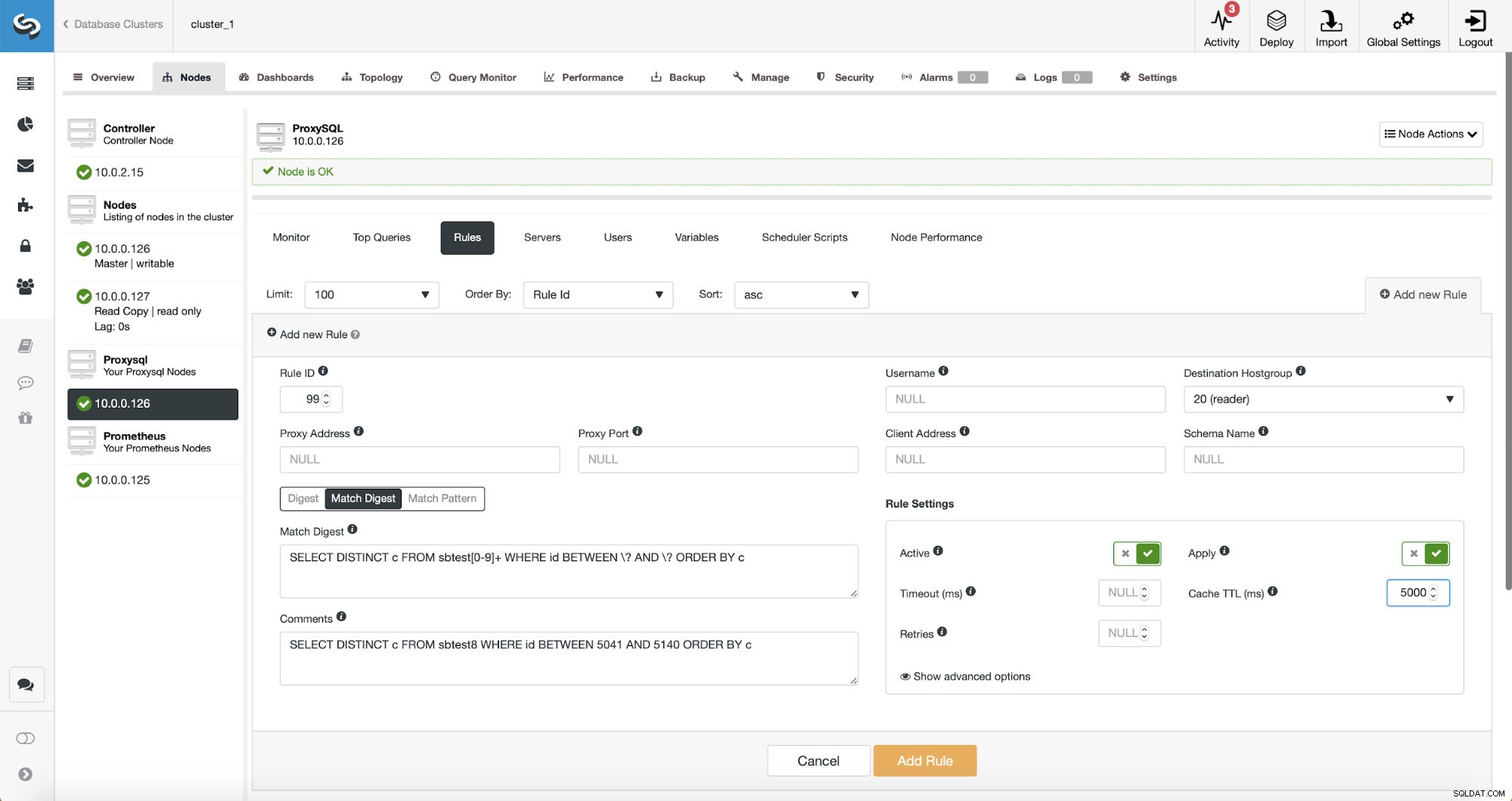
Esistono tre modi per abbinare la query:Digest, Match Digest e Match Pattern. Parliamo un po' di loro qui. Primo, Match Digest. Possiamo impostare qui un'espressione regolare che corrisponderà a una stringa di query generalizzata che rappresenta un tipo di query. Ad esempio, per la nostra domanda:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cLa rappresentazione generica sarà:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN ? AND ? ORDER BY cCome puoi vedere, ha spogliato gli argomenti della clausola WHERE quindi tutte le query di questo tipo sono rappresentate come una singola stringa. Questa opzione è piuttosto piacevole da usare perché corrisponde all'intero tipo di query e, cosa ancora più importante, viene eliminata qualsiasi spazio bianco. Questo rende molto più facile scrivere un'espressione regolare in quanto non devi tenere conto di strane interruzioni di riga, spazi bianchi all'inizio o alla fine della stringa e così via.
Digest è fondamentalmente un hash che ProxySQL calcola sul modulo Match Digest.
Infine, Match Pattern corrisponde al testo completo della query, poiché è stato inviato dal client. Nel nostro caso, la query avrà la forma di:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cUtilizzeremo Match Digest poiché vogliamo che tutte queste query siano coperte dalla regola di query. Se volessimo memorizzare nella cache solo quella particolare query, una buona opzione sarebbe utilizzare Match Pattern.
L'espressione regolare che utilizziamo è:
SELECT DISTINCT c FROM sbtest[0-9]+ WHERE id BETWEEN \? AND \? ORDER BY cStiamo confrontando letteralmente l'esatta stringa di query generalizzata con un'eccezione:sappiamo che questa query ha colpito più tabelle, quindi abbiamo aggiunto un'espressione regolare per corrispondere a tutte.
Una volta fatto, possiamo vedere se la regola di query è attiva o meno.
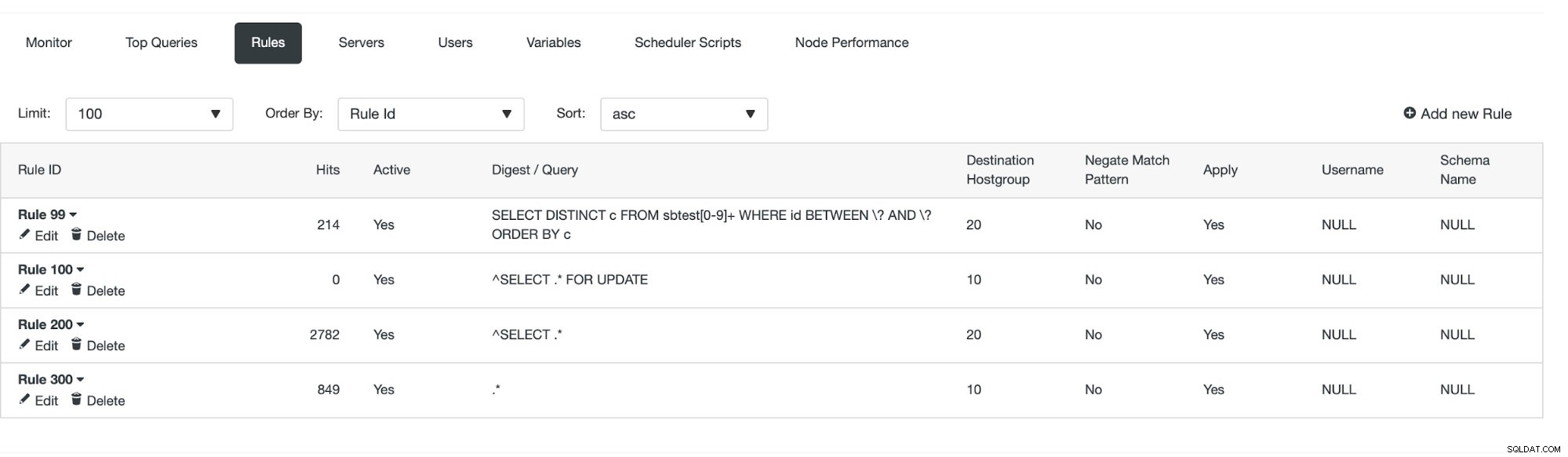
Possiamo vedere che gli "hit" stanno aumentando, il che significa che viene utilizzata la nostra regola di query. Successivamente, esamineremo un altro modo per creare una regola di query.
Utilizzo di ClusterControl per creare regole di query
ProxySQL ha un'utile funzionalità di raccolta delle statistiche delle query instradate. Puoi tenere traccia di dati come il tempo di esecuzione, quante volte è stata eseguita una determinata query e così via. Questi dati sono presenti anche in ClusterControl:
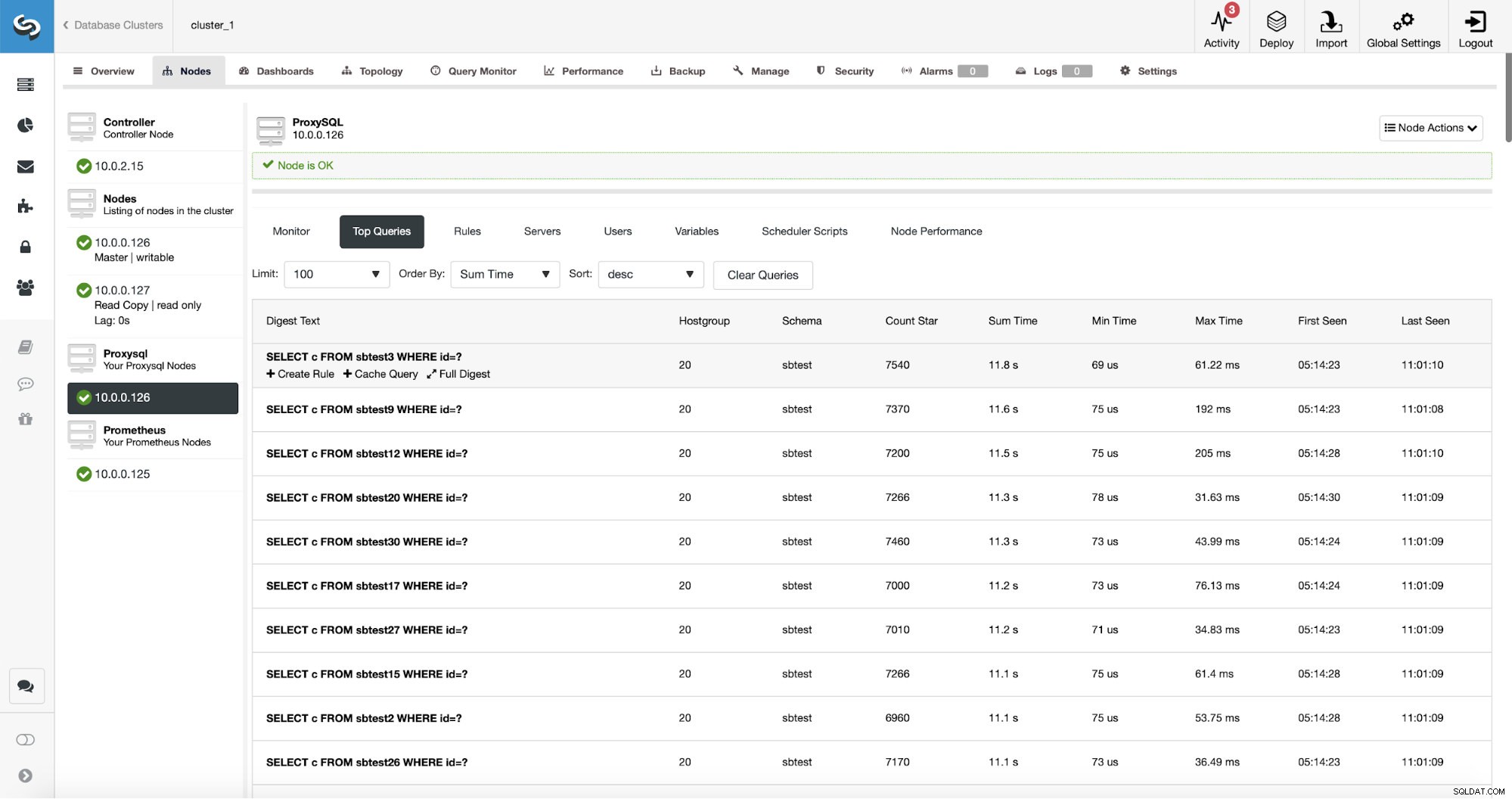
Cosa c'è di meglio, se punti su un determinato tipo di query, puoi creare una regola di query correlata ad esso. Puoi anche memorizzare facilmente nella cache questo particolare tipo di query.
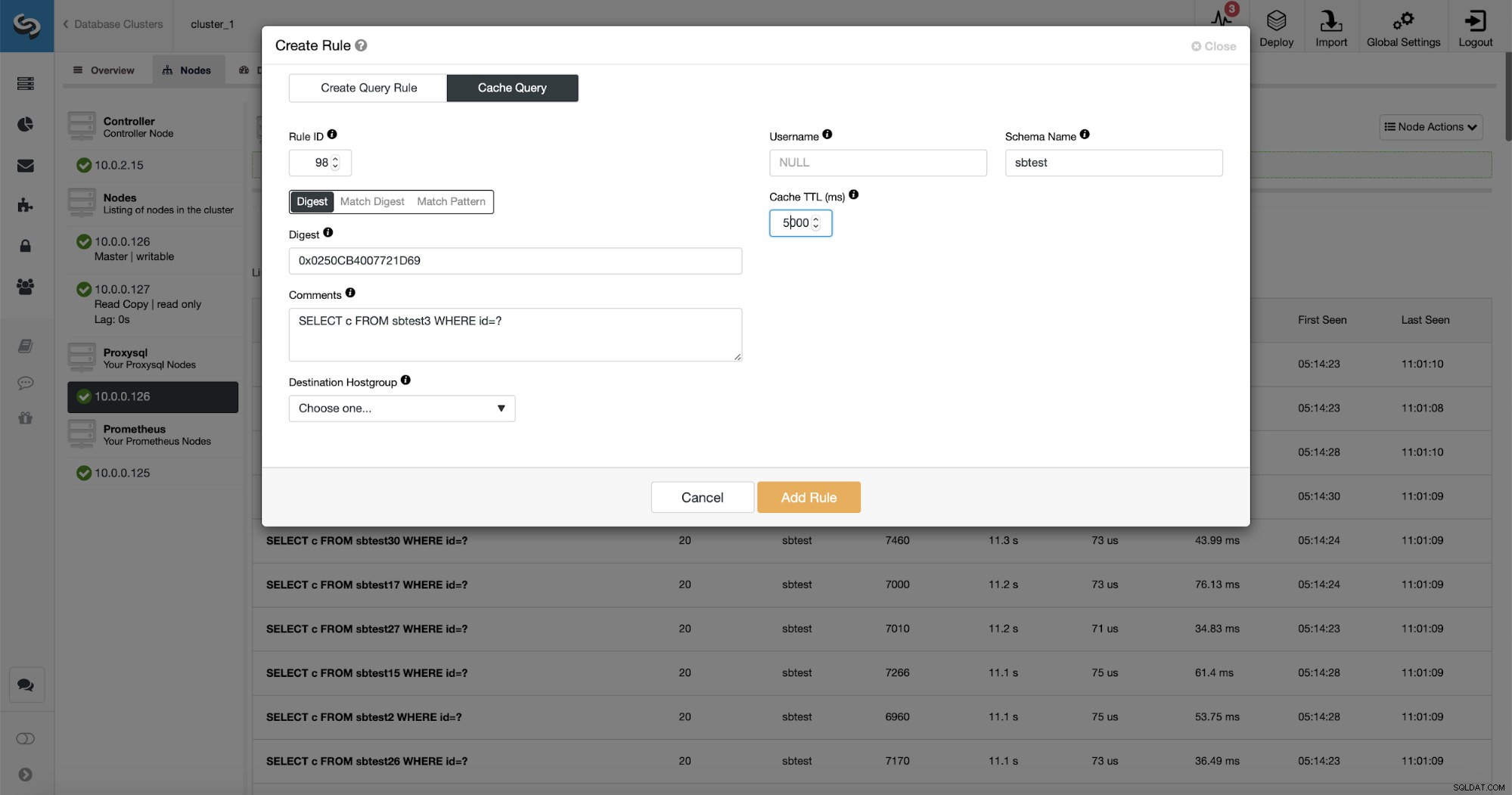
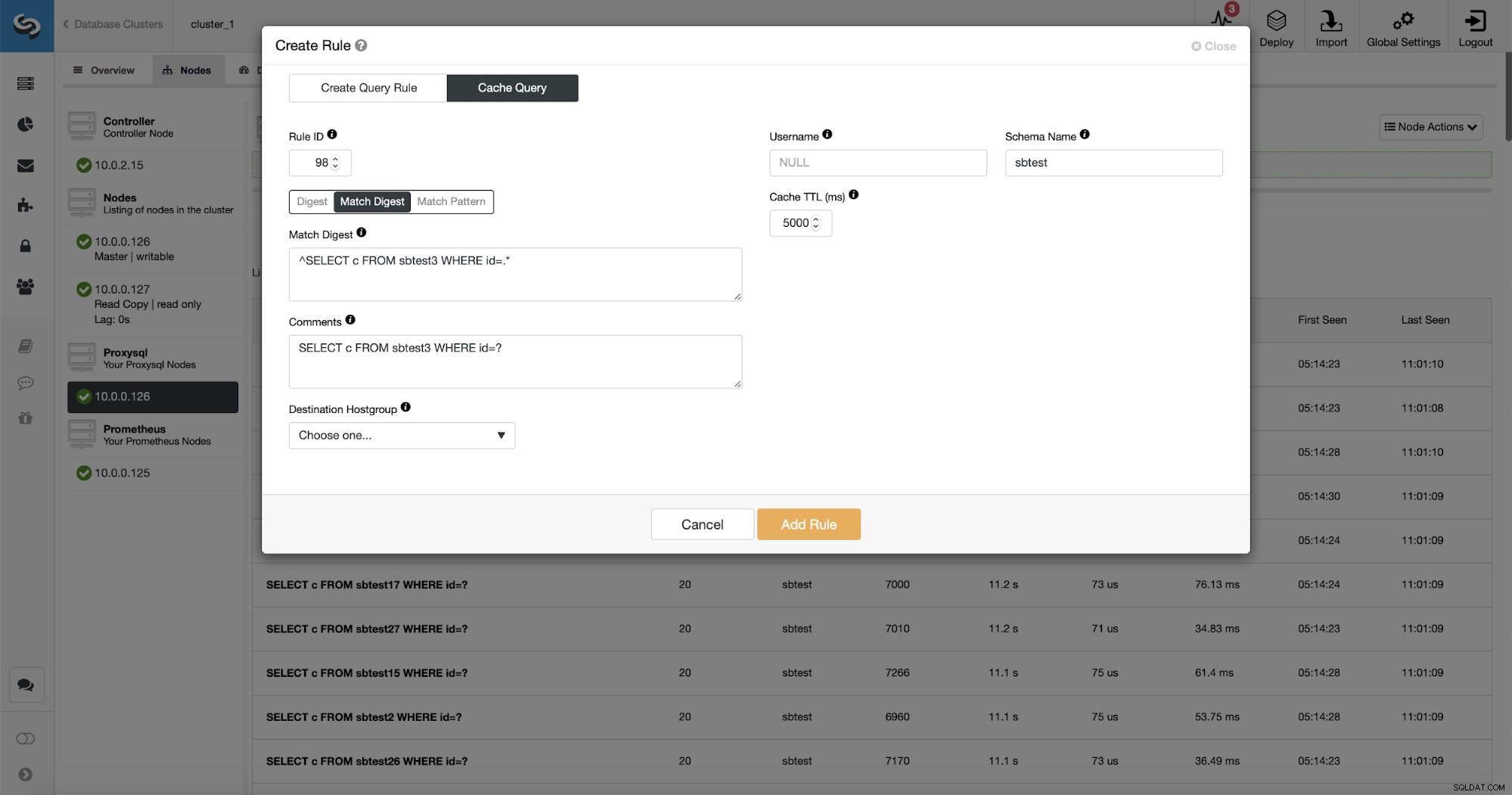
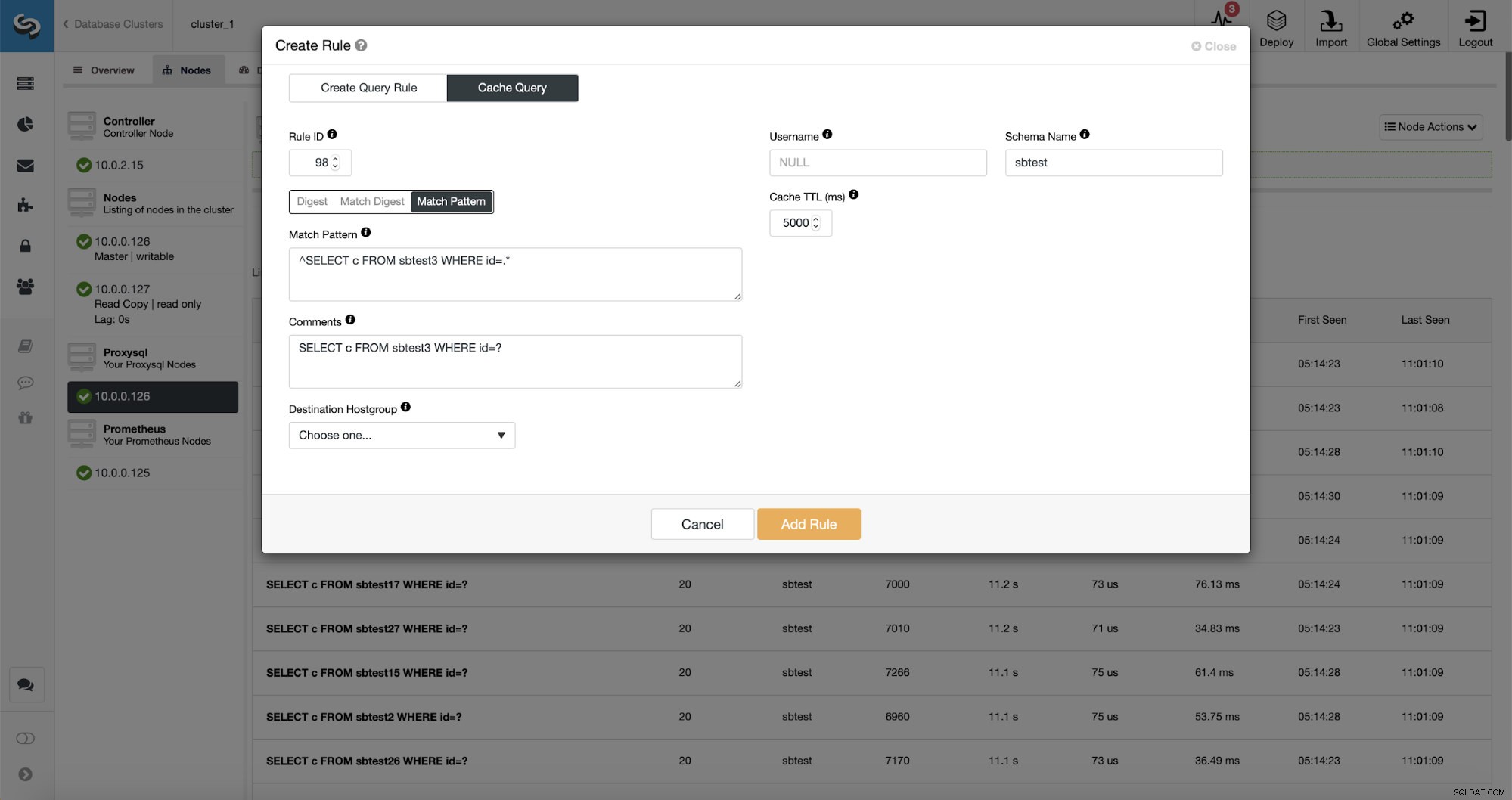
Come puoi vedere, alcuni dati come Rule IP, Cache TTL o Schema Name sono già riempiti. ClusterControl riempirà anche i dati in base al meccanismo di corrispondenza che hai deciso di utilizzare. Possiamo facilmente utilizzare l'hash per un determinato tipo di query oppure possiamo usare Match Digest o Match Pattern se desideriamo mettere a punto l'espressione regolare (ad esempio facendo lo stesso che abbiamo fatto prima ed estendendo l'espressione regolare in modo che corrisponda a tutti i tabelle nello schema sbtest).
Questo è tutto ciò di cui hai bisogno per creare facilmente regole della cache delle query in ProxySQL. Scarica ClusterControl per provarlo oggi stesso.