La replica di MariaDB è una delle soluzioni ad alta disponibilità più popolari per MariaDB e ampiamente utilizzata dalle migliori aziende come Booking.com e Google. È molto facile da configurare, con alcuni compromessi sulla manutenzione continua come aggiornamenti software, modifiche allo schema, modifiche alla topologia, failover e ripristino che sono sempre stati complicati. Tuttavia, con il set di strumenti giusto, dovresti essere in grado di gestire la topologia con facilità. In questo post del blog, esamineremo alcuni suggerimenti per monitorare la replica di MariaDB in modo efficiente utilizzando ClusterControl.
Utilizzo del Visualizzatore topologia
Una configurazione di replica consiste in un numero di ruoli. Un nodo in una configurazione di replica potrebbe essere un:
- Master - Lo scrittore/lettore principale.
- Master di backup:uno slave di sola lettura con replica semi-sincronizzazione, esclusivamente per la ridondanza del master.
- Master intermedio:replica da un master, mentre altri slave replicano da questo nodo.
- Server binlog:raccogli/conserva solo binlog senza fornire dati.
- Slave:replica da un master e comunemente impostato come di sola lettura.
- Slave multi-sorgente:replica da più master.
Ogni ruolo ha le proprie responsabilità e limitazioni ed è necessario comprendere la topologia corretta quando si ha a che fare con i nodi del database. Questo vale anche per l'applicazione, in cui l'applicazione deve scrivere solo sul nodo master in un dato momento. Pertanto, è importante avere una panoramica su quale nodo ricopre quale ruolo, in modo da non rovinare il nostro database.
In ClusterControl, Topology Viewer può fornire una panoramica della topologia di replica e del suo stato, come mostrato nella schermata seguente:
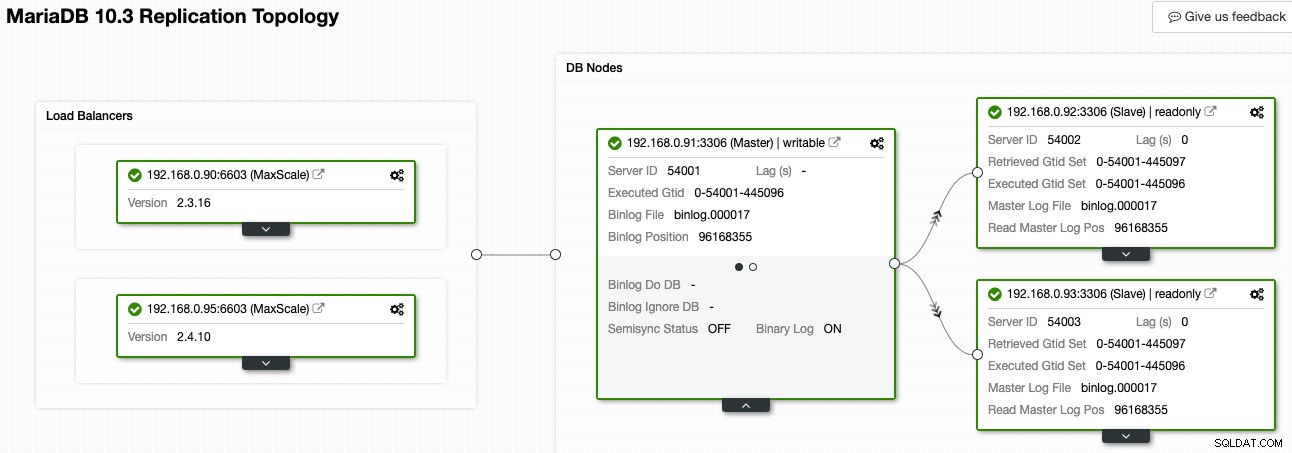
ClusterControl comprende la replica di MariaDB ed è in grado di visualizzare la topologia con il flusso di dati di replica corretto, come rappresentato dalle frecce rivolte ai nodi slave. Possiamo facilmente distinguere quale nodo è il master, gli slave e i sistemi di bilanciamento del carico (MaxScale) nella nostra configurazione di replica. La casella verde indica che tutti i servizi importanti funzionano come previsto con il ruolo assegnato.
Considera lo screenshot seguente in cui alcuni dei nostri nodi stanno riscontrando problemi:
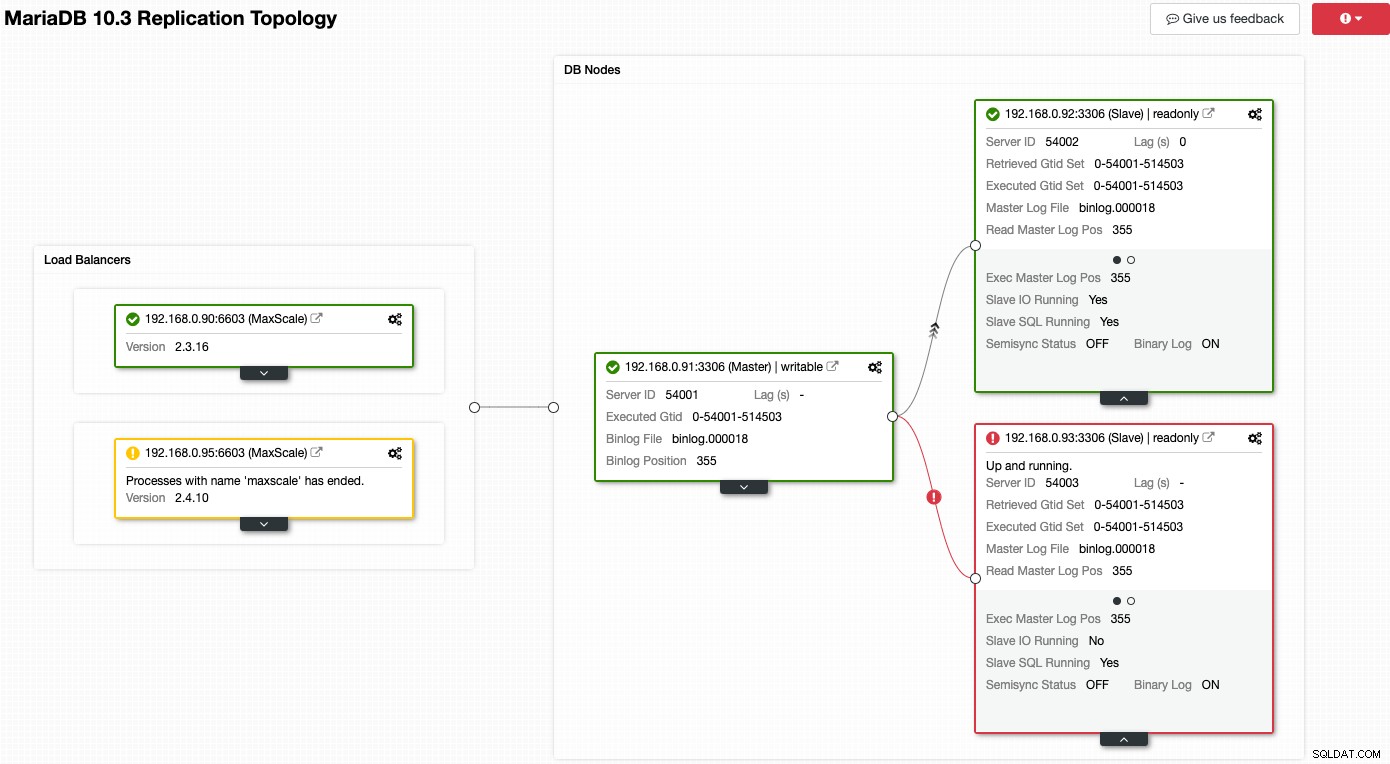
ClusterControl ti dirà immediatamente cosa c'è di sbagliato nella topologia corrente. Uno degli slave (riquadro rosso) mostra "Slave IO in esecuzione" come No, per indicare un problema di connettività da replicare dal master. Mentre la casella gialla mostra che il nostro servizio MaxScale non è in esecuzione. Possiamo anche dire che le versioni di MaxScale non sono identiche per entrambi i nodi. Puoi anche eseguire attività di gestione facendo clic direttamente sull'icona a forma di ingranaggio (in alto a destra su ogni casella) che riduce i rischi di raccogliere un nodo sbagliato.
Ritardo di replica
Questa è la cosa più importante se fai affidamento sulla coerenza della replica dei dati. Il ritardo di replica si verifica quando gli slave non riescono a tenere il passo con gli aggiornamenti in corso sul master. Le modifiche non applicate si accumulano nei registri dei relè degli slave e la versione del database sugli slave diventa sempre più diversa dal master.
In ClusterControl, puoi trovare l'istogramma del ritardo di replica in Panoramica -> Ritardo di replica in cui ClusterControl campiona costantemente il valore Seconds_Behind_Master dall'output "SHOW SLAVE STATUS":
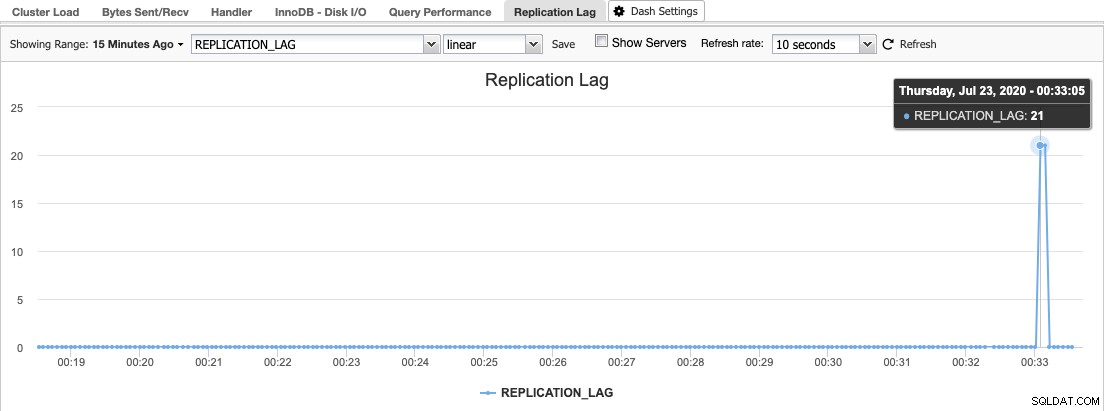
Il ritardo di replica si verifica quando il thread di I/O o il thread SQL non sono in grado di far fronte alle richieste che gli vengono poste. Se il thread di I/O soffre, significa che la connessione di rete tra il master e i suoi slave è lenta o presenta problemi. Potresti considerare di abilitare slave_compressed_protocol per comprimere il traffico di rete o segnalare al tuo amministratore di rete.
Se è il thread SQL, il problema è probabilmente dovuto a query scarsamente ottimizzate che impiegano troppo tempo per l'applicazione dello slave. Potrebbero esserci transazioni di lunga durata o troppa attività di I/O. Anche la mancanza di una chiave primaria nelle tabelle slave quando si utilizza il formato di replica ROW o MIXED è una causa comune di ritardo in questo thread. Verifica che le versioni master e slave delle tabelle abbiano una chiave primaria.
Alcuni altri suggerimenti e trucchi sono trattati in questo post del blog, Come ridurre il ritardo di replica nelle distribuzioni multi-cloud.
Dimensione registro binario/relè
È importante monitorare la dimensione del disco dei log binari e di inoltro perché potrebbe consumare una notevole quantità di spazio di archiviazione su ogni nodo in un cluster di replica. In genere, si imposta la variabile di sistema require_logs_days in modo che scada automaticamente i file di registro binari dopo un determinato numero di giorni, ad esempio, require_logs_days=7. La dimensione dei log binari dipende totalmente dal numero di eventi binari creati (scritture in entrata) e poco sappiamo quanto spazio su disco consumerebbe prima che i log scadano da MariaDB. Tieni presente che se abiliti log_slave_updates sugli slave, la dimensione dei log sarà quasi raddoppiata a causa dell'esistenza di log binari e relay sullo stesso server.
Per ClusterControl, possiamo impostare una soglia di utilizzo dello spazio su disco in ClusterControl -> Impostazioni -> Soglie per ricevere un avviso e notifiche critiche come di seguito:
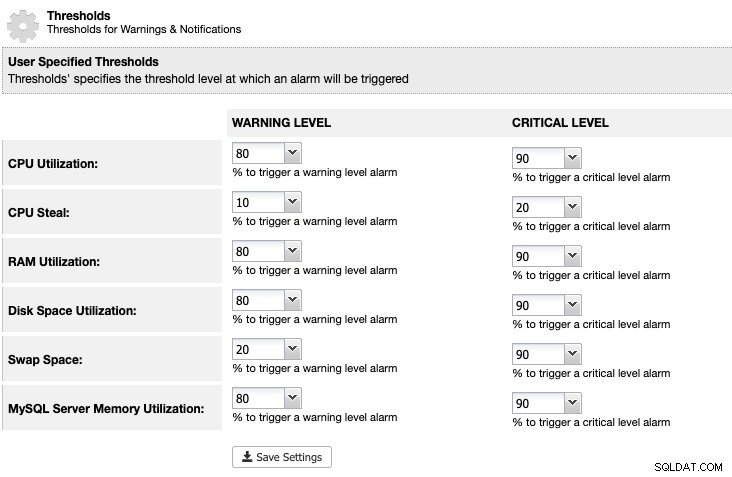
ClusterControl monitora tutto lo spazio su disco relativo ai servizi MariaDB come la posizione dei dati MariaDB directory, la directory dei log binari e anche la partizione di root. Se hai raggiunto la soglia, prendi in considerazione l'eliminazione manuale dei log binari utilizzando il comando PURGE BINARY LOGS, come spiegato e discusso in questo articolo.
Abilita dashboard di monitoraggio
ClusterControl fornisce due opzioni di monitoraggio per campionare i nodi del database:agentless o agent-based. L'impostazione predefinita è agentless quando il campionamento avviene tramite SSH in un meccanismo di solo pull. Il monitoraggio basato su agenti richiede l'esecuzione di un server Prometheus e la configurazione di tutti i nodi monitorati con almeno tre esportatori:
- Esportatore di processo (porta 9011)
- Esportatore di metriche di nodo/sistema (porta 9100)
- Esportatore MySQL/MariaDB (porta 9104)
Per abilitare il dashboard di monitoraggio basato su agente, è necessario accedere a ClusterControl -> Dashboard -> Abilita monitoraggio basato su agente. Una volta abilitato, vedrai una serie di dashboard configurati per la nostra replica MariaDB che ci offre una visione molto migliore della nostra configurazione di replica. Lo screenshot seguente mostra cosa vedresti per il nodo master:
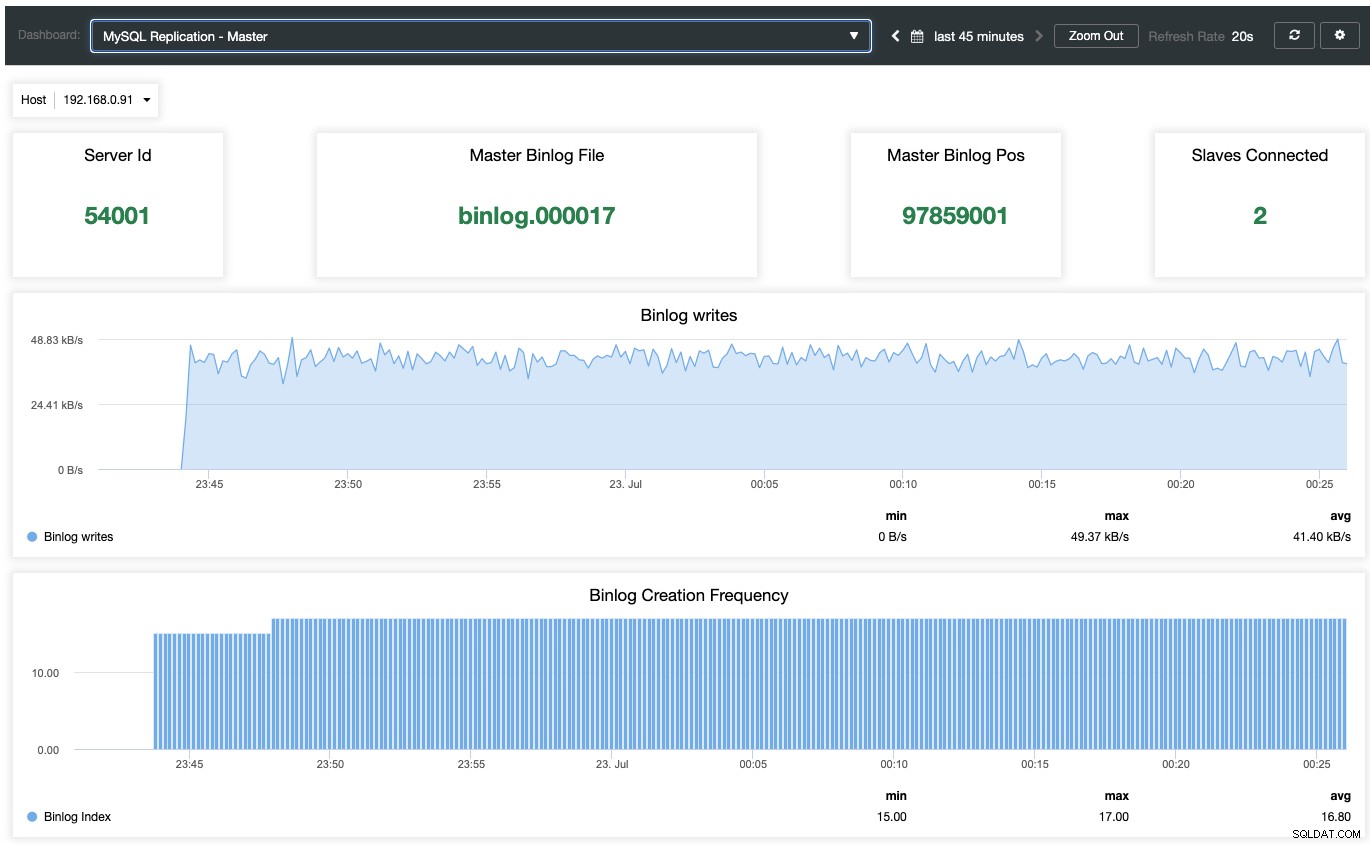
Oltre alle dashboard di monitoraggio standard di MariaDB come generali, cache e metriche InnoDB, tu verrà presentato con un dashboard di replica. Per il nodo master, possiamo ottenere molte informazioni utili riguardanti lo stato del master, il throughput di scrittura e la frequenza di creazione del binlog.
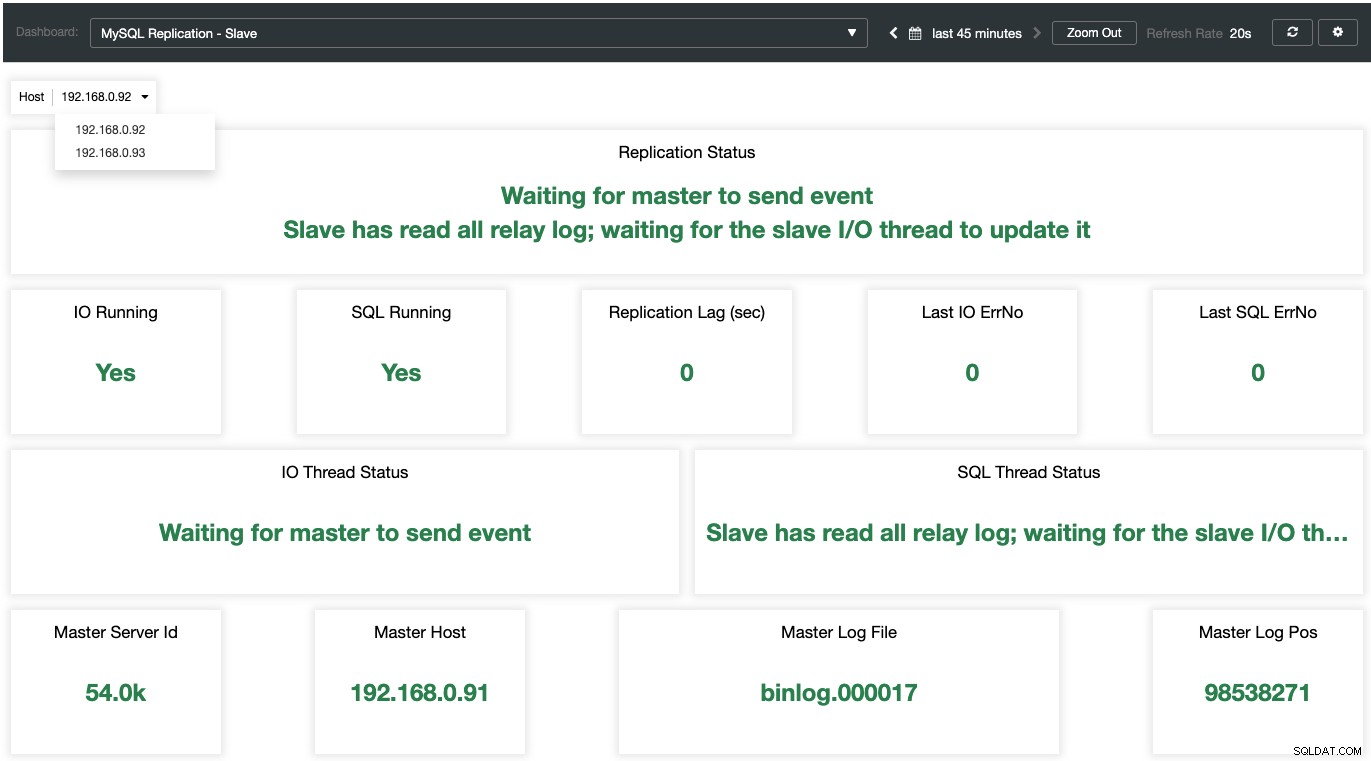
Mentre per gli schiavi, tutti gli stati importanti vengono campionati e riepilogati come nella schermata seguente. se tutto è verde, sei in buone mani:
Comprendere il registro degli errori di MariaDB
MariaDB registra i suoi eventi importanti all'interno del log degli errori, utile per capire cosa stava succedendo con il server, specialmente prima, durante e dopo un cambio di topologia. ClusterControl fornisce una visualizzazione centralizzata dei registri degli errori in ClusterControl -> Registri -> Registri di sistema estraendoli da ogni nodo del database. Fai clic su "Aggiorna registri" per attivare un processo per estrarre i registri più recenti dal server.
I file raccolti sono rappresentati in una struttura ad albero di navigazione e in un'area di testo con evidenziazione della sintassi per una migliore leggibilità:
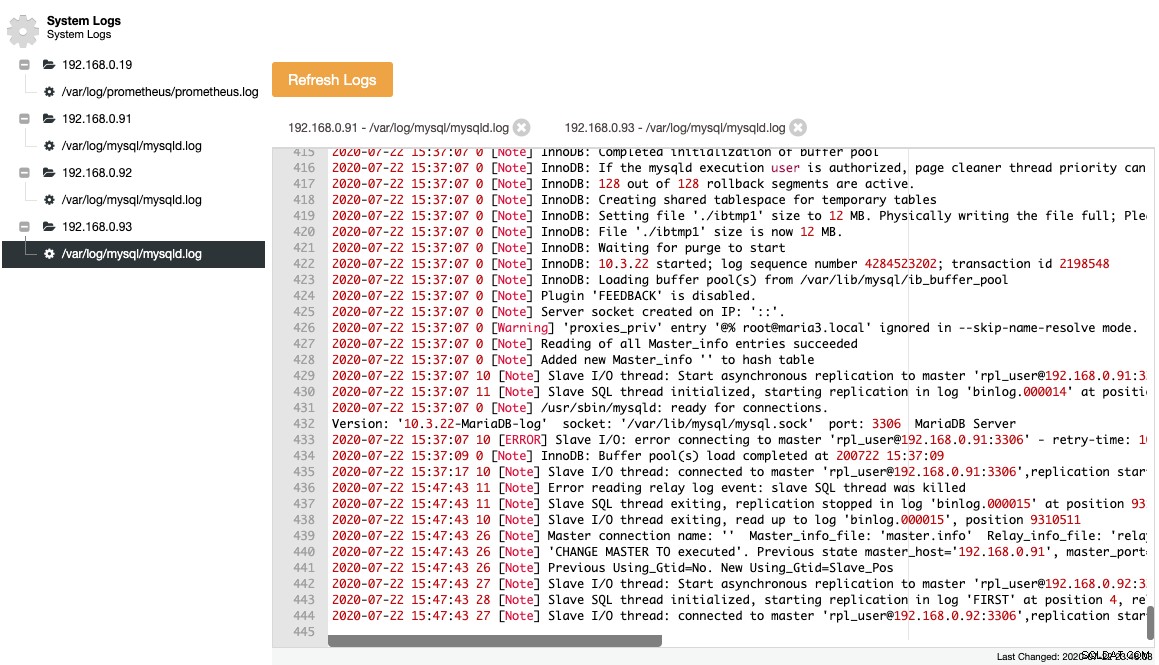
Dallo screenshot sopra, possiamo capire la sequenza di eventi e cosa è successo a questo nodo durante un evento di modifica della topologia. Dalle ultime 12 righe del registro degli errori sopra, lo slave ha avuto un errore una volta connesso al master e l'ultimo file di registro binario e la posizione sono stati registrati nel registro prima che si interrompesse. Quindi è stato eseguito un comando CHANGE MASTER più recente con informazioni GTID, come mostrato nella riga "Precedente Using_Gtid=No. Nuovo Using_Gtid=Slave_Pos" e quindi la replica riprende come volevamo.
Avvisi e notifiche di MariaDB
Il monitoraggio è incompleto senza avvisi e notifiche. Tutti gli eventi e gli allarmi generati da ClusterControl possono essere inviati all'e-mail oa qualsiasi altro strumento di terze parti supportato. Per le notifiche e-mail, è possibile configurare se il tipo di eventi verrà consegnato immediatamente, ignorato o digerito (un rapporto riepilogativo giornaliero):

Per tutti gli eventi di gravità critica, si consiglia di impostare tutto su "Consegna" in modo da ricevere le notifiche il prima possibile. Imposta "Digest" su eventi di avviso in modo da essere a conoscenza dell'integrità e dello stato del cluster.
Puoi integrare i tuoi strumenti di comunicazione e messaggistica preferiti con ClusterControl utilizzando la funzione di gestione delle notifiche in ClusterControl -> Integrazioni -> Notifiche di terze parti. ClusterControl può inviare allarmi ed eventi a PagerDuty, VictorOps, OpsGenie, Slack, Telegram, ServiceNow o qualsiasi webhook registrato dall'utente.
Lo screenshot seguente mostra che tutti gli eventi critici verranno inviati al canale telegramma configurato per il nostro cluster di replica MariaDB 10.3:

ClusterControl supporta anche l'integrazione di chatbot, in cui puoi interagire con il servizio controller tramite il client s9s direttamente dal tuo strumento di messaggistica, come mostrato in questo post del blog, Automate Your Database with CCBot:ClusterControl Hubot Integration.
Conclusione
ClusterControl offre un set completo di strumenti di monitoraggio proattivo per i cluster di database. Utilizzare ClusterControl per monitorare la configurazione della replica di MariaDB perché la maggior parte delle funzionalità di monitoraggio sono disponibili gratuitamente nell'edizione community. Non perderli!