Nei nostri blog precedenti, abbiamo giustificato il motivo per cui hai bisogno di un failover del database e abbiamo spiegato come funziona un meccanismo di failover. Lo condivido nel caso in cui tu abbia domande sul motivo per cui dovresti impostare un meccanismo di failover per il tuo database MySQL. Se lo fai, leggi i nostri precedenti post sul blog.
Come impostare il failover automatico
Il vantaggio dell'utilizzo di MySQL o MariaDB per la gestione automatica del failover è che sono disponibili strumenti che è possibile utilizzare e implementare nel proprio ambiente. Da quelli open source alle soluzioni di livello aziendale. La maggior parte degli strumenti non sono solo in grado di eseguire il failover, ma ci sono altre funzionalità come il passaggio, il monitoraggio e le funzionalità avanzate che possono offrire maggiori capacità di gestione per il cluster di database MySQL. Di seguito, esamineremo quelli più comuni che puoi utilizzare.
Utilizzo di MHA (Master High Availability)
Abbiamo affrontato questo argomento con MHA con i suoi problemi più comuni e come risolverli. Abbiamo anche confrontato MHA con MRM o con MaxScale.
La configurazione con MHA per l'alta disponibilità potrebbe non essere facile, ma è efficiente da usare e flessibile poiché ci sono parametri regolabili che puoi definire per personalizzare il tuo failover. MHA è stato testato e utilizzato. Ma con l'avanzare della tecnologia, MHA è rimasta indietro perché non supporta GTID per MariaDB e non ha inviato alcun aggiornamento negli ultimi 2 o 3 anni.
Eseguendo lo script masterha_manager,
masterha_manager --conf=/etc/app1.cnfDove un esempio /etc/app1.cnf apparirà come segue,
[server default]
user=cmon
password=pass
ssh_user=root
# working directory on the manager
manager_workdir=/var/log/masterha/app1
# working directory on MySQL servers
remote_workdir=/var/log/masterha/app1
[server1]
hostname=node1
candidate_master=1
[server2]
hostname=node2
candidate_master=1
[server3]
hostname=node3
no_master=1Parametri come no_master e candidate_master devono essere cruciali quando imposti la whitelist dei nodi desiderati come master di destinazione e nodi che non desideri siano master.
Una volta impostato, sei pronto per avere il failover per il tuo database MySQL nel caso in cui si verifichi un errore sul primario o sul master. Lo script masterha_manager gestisce il failover (automatico o manuale), prende decisioni su quando e dove eseguire il failover e gestisce il ripristino dello slave durante la promozione del master candidato per l'applicazione dei log di inoltro differenziali. Se il database master si interrompe, MHA Manager si coordinerà con l'agente del nodo MHA poiché applica i log di inoltro differenziali agli slave che non hanno gli ultimi eventi binlog dal master.
Controlla cosa fa l'agente MHA Node e i relativi script coinvolti. Fondamentalmente, è lo script che MHA Manager invocherà quando si verifica il failover. Aspetterà il suo mandato da MHA Manager mentre cerca l'ultimo slave che contiene gli eventi binlog e copia gli eventi mancanti dallo slave usando scp e li applica a se stesso. Come accennato, applica i registri di inoltro, elimina i registri di inoltro o salva i registri binari.
Se vuoi saperne di più sui parametri sintonizzabili e su come personalizzare la gestione del failover, dai un'occhiata alla pagina wiki dei parametri per MHA.
Utilizzo dell'orchestrazione
Orchestrator è uno strumento di gestione della replica e della disponibilità elevata di MySQL e MariaDB. È rilasciato da Shlomi Noach secondo i termini della licenza Apache, versione 2.0. Questo è un software open source e gestisce il failover automatico, ma ci sono tantissime cose che puoi personalizzare o fare per gestire il tuo database MySQL/MariaDB oltre al ripristino o al failover automatico.
L'installazione di Orchestrator può essere semplice o immediata. Dopo aver scaricato i pacchetti specifici richiesti per il tuo ambiente di destinazione, sei pronto per registrare il tuo cluster e nodi per essere monitorato da Orchestrator. Fornisce un'interfaccia utente per la quale è molto facile da gestire, ma ha molti parametri regolabili o set di comandi che puoi utilizzare per ottenere la gestione del failover.
Riteniamo che tu abbia finalmente configurato e registrato il cluster aggiungendo il nostro nodo primario o master può essere fatto con il comando seguente,
$ orchestrator -c discover -i pupnode21:3306
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: pupnode21
2021-01-07 12:32:31 DEBUG Cache hostname resolve pupnode21 as pupnode21
2021-01-07 12:32:31 DEBUG Connected to orchestrator backend: orchestrator:example@sqldat.com(127.0.0.1:3306)/orchestrator?timeout=1s
2021-01-07 12:32:31 DEBUG Orchestrator pool SetMaxOpenConns: 128
2021-01-07 12:32:31 DEBUG Initializing orchestrator
2021-01-07 12:32:31 INFO Connecting to backend 127.0.0.1:3306: maxConnections: 128, maxIdleConns: 32
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.222
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.222 as 192.168.40.222
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.223
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.223 as 192.168.40.223
pupnode21:3306Ora abbiamo aggiunto il nostro cluster.
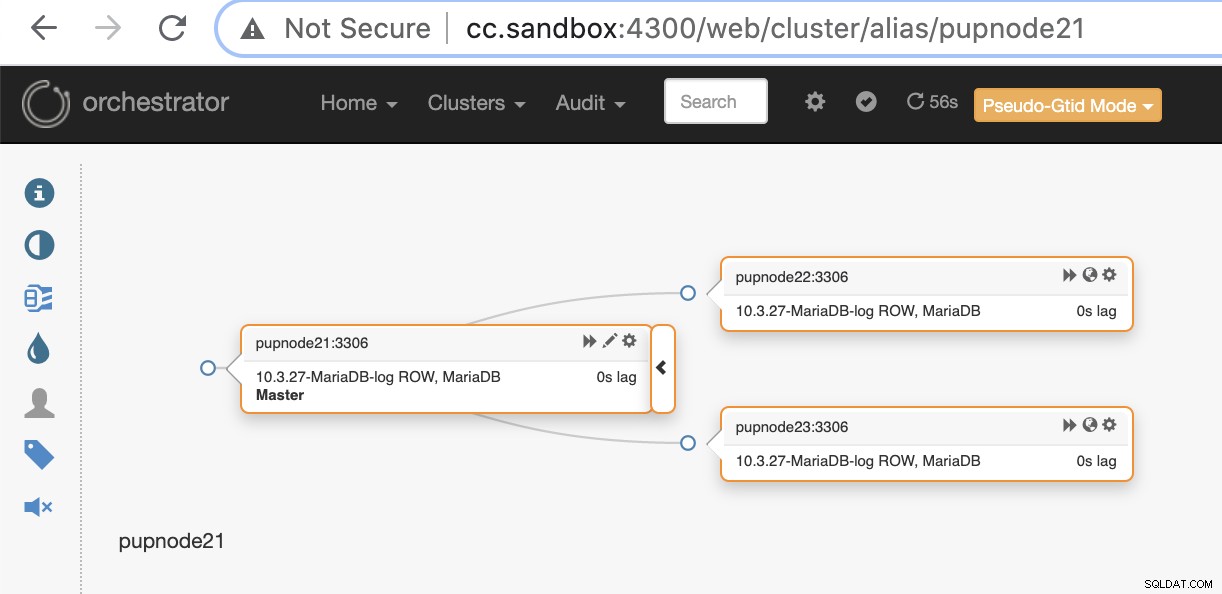
Se un nodo primario si guasta (guasto hardware o si è verificato un arresto anomalo), Orchestrator lo farà rileva e trova il nodo più avanzato da promuovere come nodo principale o principale.
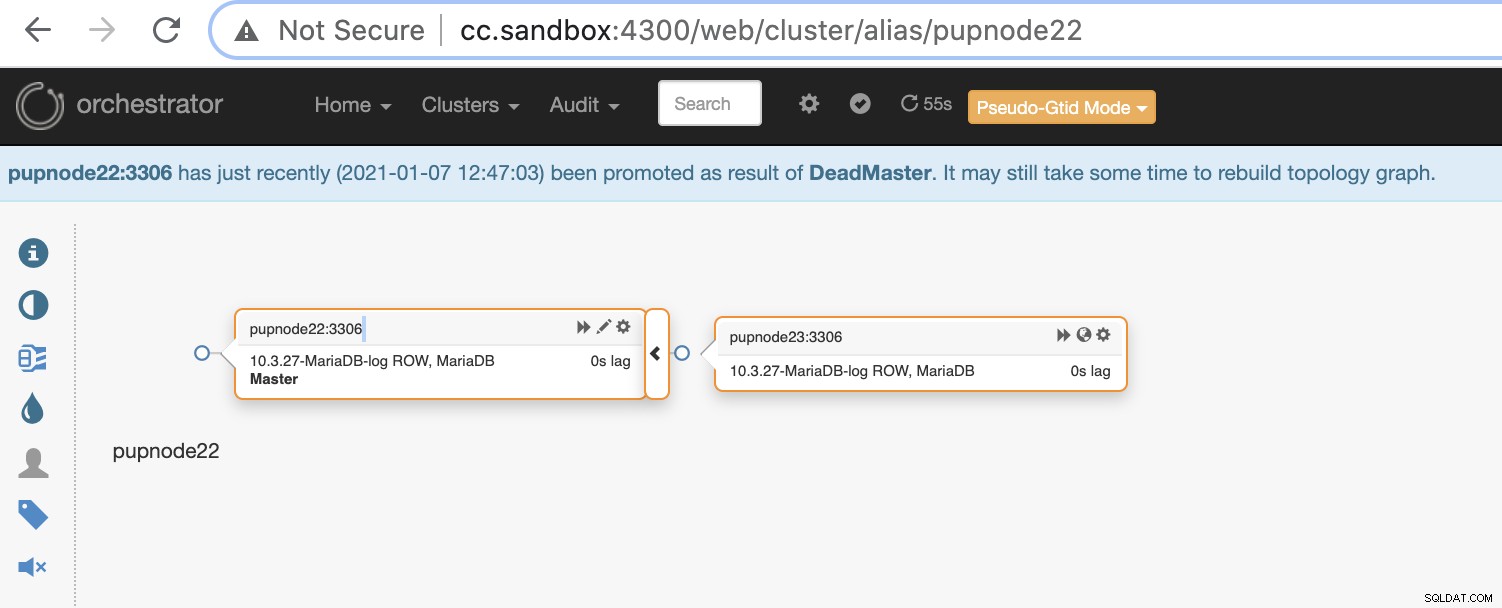
Ora abbiamo due nodi rimasti nel cluster mentre il primario è inattivo .
$ orchestrator-client -c topology -i pupnode21:3306
pupnode21:3306 [unknown,invalid,10.3.27-MariaDB-log,rw,ROW,>>,downtimed]
$ orchestrator-client -c topology -i pupnode22:3306
pupnode22:3306 [0s,ok,10.3.27-MariaDB-log,rw,ROW,>>]
+ pupnode23:3306 [0s,ok,10.3.27-MariaDB-log,ro,ROW,>>,GTID]Utilizzo di MaxScale
MariaDB MaxScale è stato supportato come bilanciatore del carico del database. Nel corso degli anni MaxScale è cresciuto e maturato, ampliandosi con diverse funzionalità avanzate e che include il failover automatico. Da quando è stato rilasciato MariaDB MaxScale 2.2, introduce diverse nuove funzionalità, inclusa la gestione del failover del cluster di replica. Puoi leggere il nostro blog precedente sul meccanismo di failover MaxScale.
L'uso di MaxScale è sotto BSL sebbene il software sia disponibile gratuitamente ma richieda almeno di acquistare il servizio con MariaDB. Potrebbe non essere adatto, ma nel caso in cui tu abbia acquisito i servizi aziendali MariaDB, questo può essere un grande vantaggio se hai bisogno della gestione del failover e delle sue altre funzionalità.
L'installazione di MaxScale è facile, ma impostare la configurazione richiesta e definirne i parametri non lo è, e richiede la conoscenza del software. Puoi fare riferimento alla loro guida alla configurazione.
Per un'implementazione rapida e veloce, puoi utilizzare ClusterControl per installare MaxScale nel tuo ambiente MySQL/MariaDB esistente.
Una volta installato, l'impostazione del database Moodle può essere eseguita puntando l'host all'IP MaxScale o al nome host e alla porta di lettura-scrittura. Ad esempio,
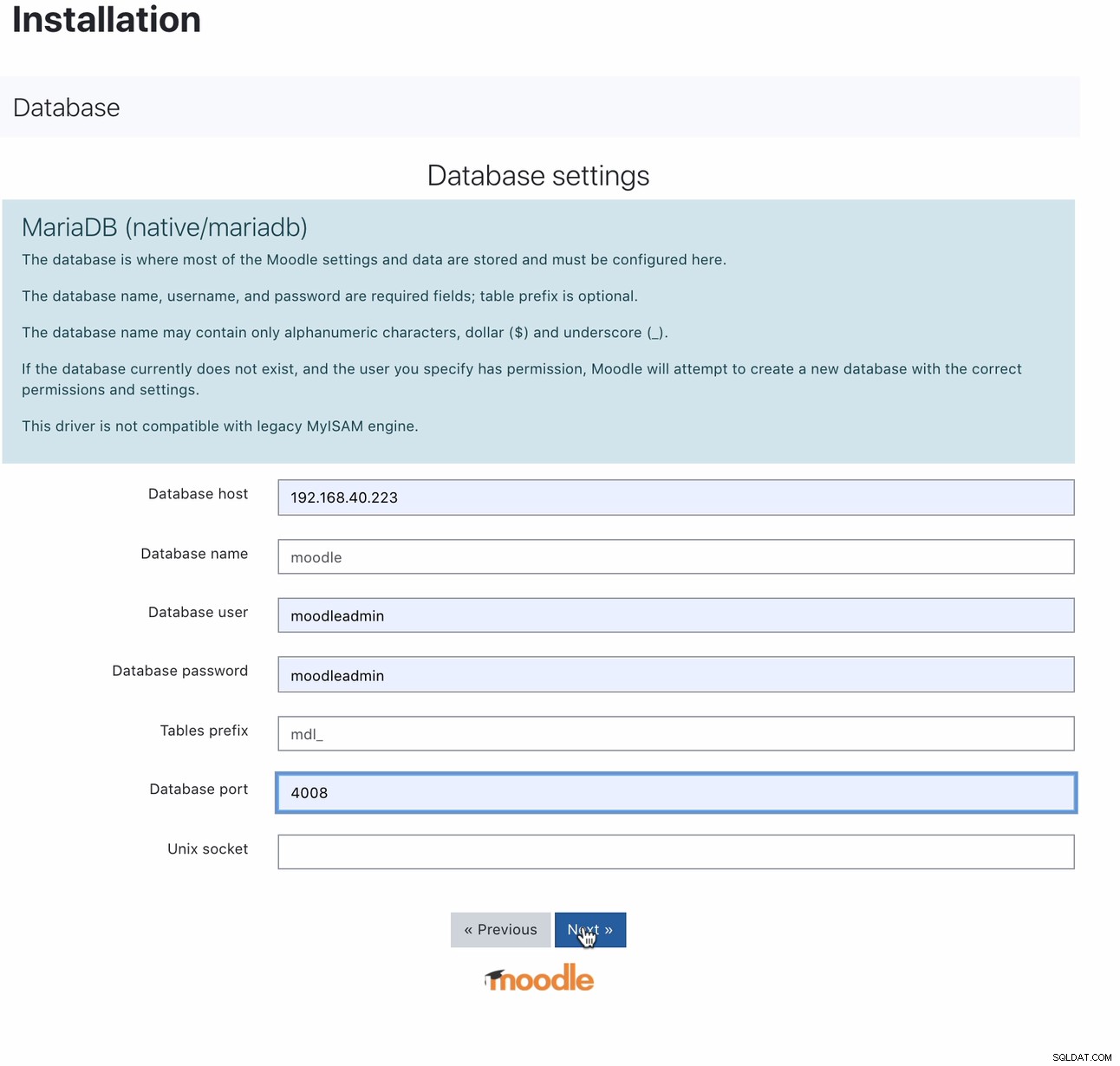
Per quale porta 4008 è la tua lettura e scrittura per il tuo listener di servizio. Ad esempio, ecco la seguente configurazione del servizio e del listener per il mio MaxScale.
$ cat maxscale.cnf.d/rw-listener.cnf
[rw-listener]
type=listener
protocol=mariadbclient
service=rw-service
address=0.0.0.0
port=4008
authenticator=MySQLAuth
$ cat maxscale.cnf.d/rw-service.cnf
[rw-service]
type=service
servers=DB_123,DB_122,DB_124
router=readwritesplit
user=maxscale_adm
password=42BBD2A4DC1BF9BE05C41A71DEEBDB70
max_slave_connections=100%
max_sescmd_history=15000000
causal_reads=true
causal_reads_timeout=10
transaction_replay=true
transaction_replay_max_size=32Mi
delayed_retry=true
master_reconnection=true
max_connections=0
connection_timeout=0
use_sql_variables_in=master
master_accept_reads=true
disable_sescmd_history=falseDurante la configurazione del monitor, non dimenticare di abilitare il failover automatico o anche di abilitare il rejoin automatico se si desidera che il master precedente non riesca a rientrare automaticamente quando si torna online. Va così,
$ egrep -r 'auto|^\[' maxscale.cnf.d/replication_monitor.cnf
[replication_monitor]
auto_failover=true
auto_rejoin=1Tieni presente che le variabili che ho indicato non sono pensate per l'uso in produzione ma solo per questo post sul blog e per scopi di test. La cosa buona con MaxScale, una volta che il primario o il master va giù, MaxScale è abbastanza intelligente da promuovere il candidato ideale o migliore per assumere il ruolo di master. Quindi, non è necessario modificare l'IP e la porta poiché abbiamo utilizzato l'host/IP del nostro nodo MaxScale e la sua porta come endpoint una volta che il master è inattivo. Ad esempio,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Il nodo DB_123 che punta a 192.168.40.221 è il master corrente. La terminazione del nodo DB_123 attiverà MaxScale per eseguire un failover e apparirà così,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Down │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Mentre il nostro database Moodle è ancora attivo e funzionante poiché il nostro MaxScale punta all'ultimo master che è stato promosso.
$ mysql -hmaxscale.local.domain -umoodleuser -pmoodlepassword -P4008
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 9
Server version: 10.3.27-MariaDB-log MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> select @@hostname;
+------------+
| @@hostname |
+------------+
| 192.168.40.222 |
+------------+
1 row in set (0.001 sec)Utilizzo di ClusterControl
ClusterControl può essere scaricato gratuitamente e offre licenze per Community, Advance ed Enterprise. Il failover automatico è disponibile solo su Advance ed Enterprise. Il failover automatico è coperto dalla nostra funzione di ripristino automatico che tenta di ripristinare un cluster o un nodo guasto. Se desideri maggiori dettagli su come eseguire questa operazione, consulta il nostro post precedente Come ClusterControl esegue il ripristino automatico del database e il failover. Offre parametri sintonizzabili che sono molto convenienti e facili da usare. Si prega di leggere il nostro post precedente anche su Come automatizzare il failover del database con ClusterControl.
La gestione del failover automatico per il database Moodle deve almeno richiedere un IP virtuale (VIP) come endpoint per il client dell'applicazione Moodle che interfaccia il back-end del database. Per fare ciò, puoi distribuire Keepalived con HAProxy (o ProxySQL, a seconda della scelta del sistema di bilanciamento del carico) sopra di esso. In questo caso, l'endpoint del tuo database Moodle punterà all'IP virtuale, che è fondamentalmente assegnato da Keepalived dopo averlo distribuito, come ti abbiamo mostrato in precedenza durante l'impostazione di MaxScale. Puoi anche controllare questo blog su come farlo.
Come accennato in precedenza, sono disponibili parametri sintonizzabili che puoi semplicemente impostare tramite il tuo /etc/cmon.d/cmon_
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replica_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- Replica_post_failover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
ClusterControl è molto flessibile durante la gestione del failover in modo da poter eseguire alcune attività pre-failover o post-failover.
Conclusione
Ci sono altre ottime scelte quando si imposta e si gestisce automaticamente il failover per il database MySQL per Moodle. Dipende dal tuo budget e da cosa probabilmente devi spendere soldi. L'uso di quelli open source richiede esperienza e richiede più test per familiarizzare poiché non c'è supporto che puoi eseguire quando hai bisogno di aiuto diverso dalla comunità. Con le soluzioni aziendali, ha un prezzo ma offre supporto e facilità poiché il lavoro che richiede tempo può essere ridotto. Tieni presente che se il failover viene utilizzato in modo errato, può comportare danni al database se non gestito e gestito correttamente. Concentrati su ciò che è più importante e su come sei capace delle soluzioni che stai utilizzando per gestire il failover del tuo database Moodle.