L'anno scorso ho presentato una soluzione per simulare i secondari leggibili del gruppo di disponibilità senza investire nell'edizione Enterprise. Non per impedire alle persone di acquistare Enterprise Edition, poiché ci sono molti vantaggi al di fuori delle AG, ma soprattutto per coloro che non hanno alcuna possibilità di avere Enterprise Edition in primo luogo:
- Secondari leggibili con un budget
Cerco di essere un instancabile sostenitore del cliente della Standard Edition; è quasi uno scherzo in corso che sicuramente, dato il numero di funzionalità che ottiene in ogni nuova versione, quell'edizione nel suo insieme è sul percorso di ritiro. Nelle riunioni private con Microsoft ho spinto per l'inclusione di funzionalità anche nell'edizione standard, in particolare con funzionalità molto più vantaggiose per le piccole imprese rispetto a quelle con budget hardware illimitato.
I clienti dell'edizione Enterprise godono dei vantaggi in termini di gestibilità e prestazioni offerti dal partizionamento delle tabelle, ma questa funzionalità non è disponibile nell'edizione standard. Di recente mi è venuta l'idea che esiste un modo per ottenere almeno alcuni dei vantaggi del partizionamento su qualsiasi edizione e non implica viste partizionate. Questo non vuol dire che le viste partizionate non siano un'opzione praticabile che vale la pena considerare; questi sono descritti bene da altri, tra cui Daniel Hutmacher (Viste partizionate sul partizionamento delle tabelle) e Kimberly Tripp (Tabelle partizionate v. Viste partizionate:perché sono ancora in circolazione?). La mia idea è solo un po' più semplice da implementare.
Il tuo nuovo eroe:indici filtrati
Ora, lo so, questa caratteristica è una parola di quattro lettere per alcuni; prima di andare oltre, dovresti essere felicemente a tuo agio con gli indici filtrati, o almeno consapevole dei loro limiti. Alcune letture per darti un giusto equilibrio prima che tenti di venderti su di loro:
- Parlo di diverse carenze in In che modo gli indici filtrati potrebbero essere una funzione più potente e sottolineo molti elementi Connect per farti votare;
- Paul White (@SQL_Kiwi) parla dei problemi di ottimizzazione in Limitazioni dell'ottimizzatore con indici filtrati e anche in Un effetto collaterale imprevisto dell'aggiunta di un indice filtrato; e,
- Jes Borland (@grrl_geek) ci dice cosa puoi (e non puoi) fare con gli indici filtrati.
Leggi tutti quelli? E sei ancora qui? Ottimo.
Il TL; DR di questo è che puoi utilizzare indici filtrati per mantenere tutti i tuoi "dati caldi" in una struttura fisica separata e anche su hardware sottostante separato (potresti avere un'unità SSD o PCIe veloce disponibile, ma può ' t reggere l'intero tavolo).
Un rapido esempio
Esistono molti casi d'uso in cui una parte dei dati viene interrogata molto più frequentemente del resto:pensa a un negozio al dettaglio che gestisce gli ordini, a una panetteria che programma le consegne di torte nuziali o a uno stadio di calcio che misura le presenze e i dati sulle concessioni. In questi casi, la maggior parte o tutta l'attività di query quotidiana riguarda dati "correnti".
Manteniamolo semplice; creeremo un database con una tabella Ordini molto ristretta:
CREATE DATABASE PoorManPartition; GO USE PoorManPartition; GO CREATE TABLE dbo.Orders ( OrderID INT IDENTITY(1,1) PRIMARY KEY, OrderDate DATE NOT NULL DEFAULT SYSUTCDATETIME(), OrderTotal DECIMAL(8,2) --, ...other columns... );
Ora, supponiamo che tu abbia abbastanza spazio sul tuo storage veloce per conservare un mese di dati (con molto margine per tenere conto della stagionalità e della crescita futura). Possiamo aggiungere un nuovo filegroup e posizionare un file di dati sull'unità veloce.
ALTER DATABASE PoorManPartition ADD FILEGROUP HotData; GO ALTER DATABASE PoorManPartition ADD FILE ( Name = N'HotData', FileName = N'Z:\folder\HotData.mdf', Size = 100MB, FileGrowth = 25MB ) TO FILEGROUP HotData;
Ora creiamo un indice filtrato sul nostro filegroup HotData, in cui il filtro include tutto dall'inizio di novembre 2015 e le colonne comuni coinvolte nelle query basate sul tempo sono nella chiave o nell'elenco di inclusione:
CREATE INDEX FilteredIndex
ON dbo.Orders(OrderDate)
INCLUDE(OrderTotal)
WHERE OrderDate >= '20151101'
AND OrderDate < '20151201'
ON HotData; Possiamo inserire alcune righe e controllare il piano di esecuzione per essere sicuri che le query coperte possano, infatti, utilizzare l'indice:
INSERT dbo.Orders(OrderDate) VALUES('20151001'),('20151103'),('20151127');
GO
SELECT index_id, rows
FROM sys.partitions
WHERE object_id = OBJECT_ID(N'dbo.Orders');
/*
Results:
index_id rows
-------- ----
1 3
2 2
*/
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151102'
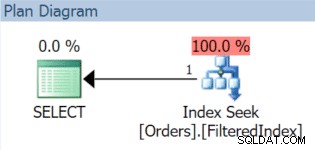
AND OrderDate < '20151106'; Il piano di esecuzione risultante, in effetti, utilizza l'indice filtrato (anche se il predicato del filtro nella query non corrisponde esattamente alla definizione dell'indice):
Ora arriva il 1° dicembre ed è tempo di scambiare i nostri dati di novembre e sostituirli con quelli di dicembre. Possiamo semplicemente ricreare l'indice filtrato con un nuovo predicato di filtro e utilizzare il DROP_EXISTING opzione:
CREATE INDEX FilteredIndex
ON dbo.Orders(OrderDate)
INCLUDE(OrderTotal)
WHERE OrderDate >= '20151201'
AND OrderDate < '20160101'
WITH (DROP_EXISTING = ON)
ON HotData; Ora possiamo aggiungere qualche riga in più, controllare le statistiche della partizione ed eseguire la nostra query precedente e una nuova per controllare gli indici utilizzati:
INSERT dbo.Orders(OrderDate) VALUES('20151202'),('20151205');
GO
SELECT index_id, rows
FROM sys.partitions
WHERE object_id = OBJECT_ID(N'dbo.Orders');
/*
Results:
index_id rows
-------- ----
1 5
2 2
*/
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151102'
AND OrderDate < '20151106';
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151202'
AND OrderDate < '20151204'; In questo caso otteniamo una scansione dell'indice cluster con la query di novembre:
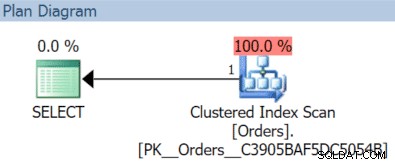
(Ma sarebbe diverso se avessimo un indice separato e non filtrato con OrderDate come chiave.)
E non lo mostrerò più, ma con la query di dicembre otteniamo la stessa ricerca di indice filtrata di prima.
Puoi anche mantenere più indici, uno per il mese in corso, uno per il mese precedente e così via, e puoi semplicemente gestirli separatamente (il 1° dicembre devi semplicemente eliminare l'indice da ottobre e lasciare da solo quello di novembre, ad esempio) . Potresti anche mantenere più indici di intervalli di tempo più o meno lunghi (settimana corrente e precedente, trimestre corrente e precedente), ecc. La soluzione è piuttosto flessibile.
A causa delle limitazioni degli indici filtrati, non proverò a spingerlo come una soluzione perfetta, né come sostituto completo per il partizionamento delle tabelle o le viste partizionate. La sostituzione di una partizione, ad esempio, è un'operazione sui metadati, mentre si ricrea un indice con DROP_EXISTING può avere molte registrazioni (e poiché non sei su Enterprise Edition, non può essere eseguito online). Potresti anche scoprire che le viste partizionate sono più veloci:c'è più lavoro per mantenere tabelle fisiche separate e i vincoli che rendono possibile la vista partizionata, ma in alcuni casi il vantaggio in termini di prestazioni delle query potrebbe essere migliore.
Automazione
L'atto di ricreare l'indice può essere automatizzato abbastanza facilmente, utilizzando un semplice lavoro che fa qualcosa del genere una volta al mese (o qualunque sia la dimensione della finestra "calda"):
DECLARE @sql NVARCHAR(MAX), @dt DATE = DATEADD(DAY, 1-DAY(GETDATE()), GETDATE()); SET @sql = N'CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate >= ''' + CONVERT(CHAR(8), @dt, 112) + N''' WITH (DROP_EXISTING = ON) ON HotData;'; EXEC PoorManPartition.sys.sp_executesql @sql;
Potresti anche creare più indici con mesi di anticipo, proprio come creare partizioni future in anticipo:dopotutto, gli indici futuri non occuperanno spazio finché non ci saranno dati rilevanti per i loro predicati. E puoi semplicemente eliminare gli indici che stavano segmentando i dati più vecchi che ora vuoi che diventino freddi.
Con il senno di poi
Dopo aver finito questo articolo, ovviamente, mi sono imbattuto in un altro dei post di Kimberly Tripp, che dovresti leggere prima di procedere con qualsiasi cosa sto sostenendo qui (e che avevo letto prima di iniziare):
- Che ne dici di indici filtrati invece di partizionamento?
Per molteplici ragioni, Kimberly è molto più favorevole alle viste partizionate per implementare qualcosa di simile al partizionamento in Standard Edition; tuttavia, per alcuni scenari, l'uso di indici filtrati mi intriga ancora abbastanza per continuare la mia sperimentazione. Una delle aree in cui gli indici filtrati possono essere utili è quando i tuoi dati "caldi" hanno più criteri, non solo suddivisi per data, ma anche per altri attributi (forse vuoi query rapide su tutti gli ordini di questo mese che sono per un livello specifico del cliente o superiore a un determinato importo in dollari).
Prossimo...
In un post futuro, giocherò con questo concetto su un sistema di fascia alta, con un volume e un carico di lavoro reali. Voglio scoprire le differenze di prestazioni tra questa soluzione, un indice di copertura non filtrato, una vista partizionata e una tabella partizionata. All'interno di una macchina virtuale su un laptop con solo SSD disponibili probabilmente non produrrebbe test su larga scala realistici o equi.