Post di Dan Holmes, che scrive su sql.dnhlms.com.
La documentazione in linea di SQL Server (BOL), i white paper e molte altre fonti ti mostreranno come e perché potresti voler aggiornare le statistiche su una tabella o un indice. Tuttavia, hai solo un modo per modellare quei valori. Ti mostrerò come creare le statistiche esattamente come desideri entro i limiti dei 200 passaggi disponibili.
Disclaimer :Questo funziona per me perché conosco la mia applicazione, il mio database e il flusso di lavoro regolare del mio utente e i modelli di utilizzo delle applicazioni. Tuttavia, utilizza comandi non documentati e, se utilizzato in modo errato, potrebbe peggiorare notevolmente le prestazioni dell'applicazione.Nella nostra applicazione, l'utente Scheduling legge e scrive regolarmente dati che rappresentano eventi per domani e per i prossimi due giorni. I dati per oggi e per quelli precedenti non vengono utilizzati dall'Utilità di pianificazione. Per prima cosa al mattino, il set di dati per domani inizia a un paio di centinaia di righe ed entro mezzogiorno può essere 1400 e oltre. Il grafico seguente illustrerà i conteggi delle righe. Questi dati sono stati raccolti la mattina di mercoledì 18 novembre 2015. Storicamente, puoi notare che il conteggio delle righe regolari è di circa 1.400, ad eccezione dei giorni del fine settimana e del giorno successivo.
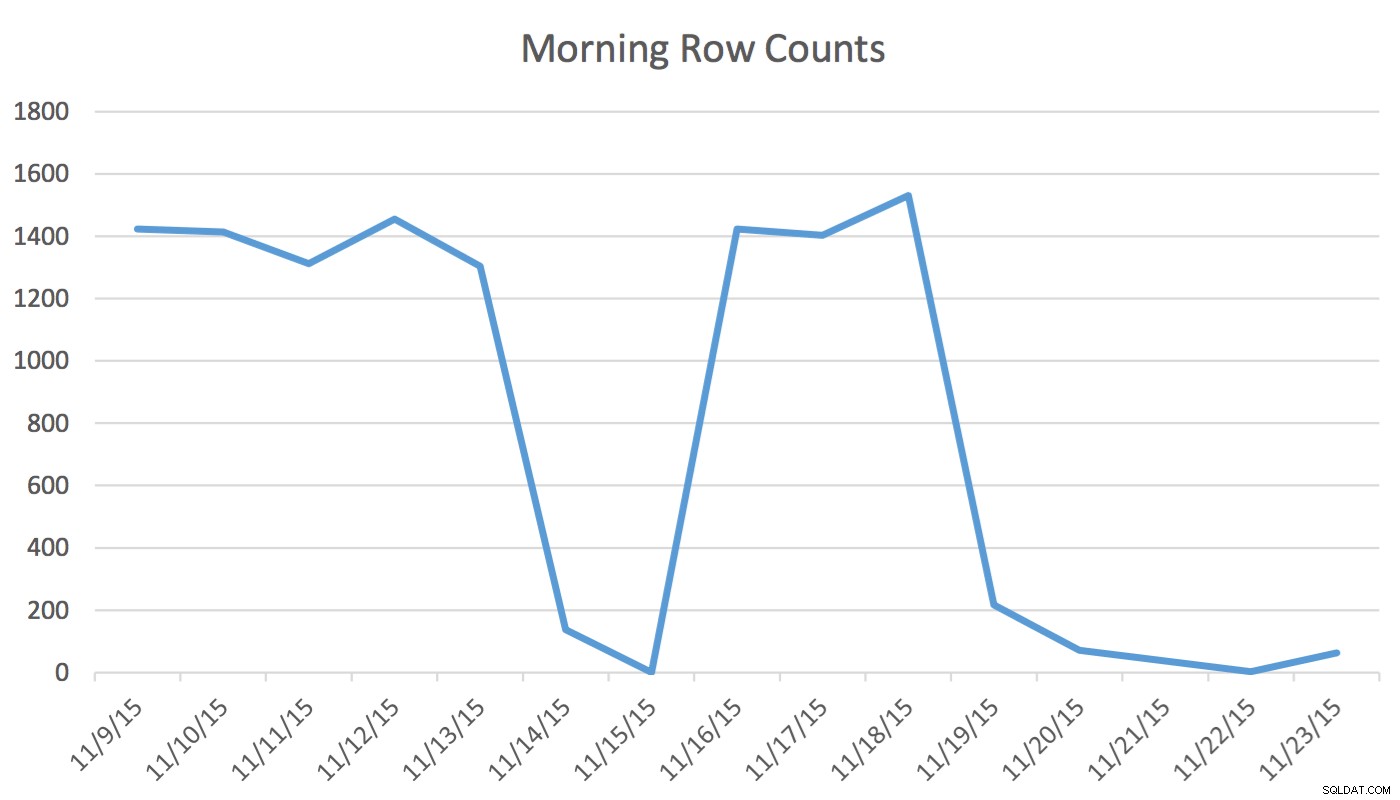
Per lo Scheduler gli unici dati rilevanti sono i prossimi giorni. Quello che sta succedendo oggi e quello che è successo ieri non è rilevante per la sua attività. Quindi come fa questo a causare un problema? Questa tabella ha 2.259.205 righe, il che significa che la modifica dei conteggi delle righe dalla mattina a mezzogiorno non sarà sufficiente per attivare un aggiornamento delle statistiche avviato da SQL Server. Inoltre, un lavoro pianificato manualmente che crea statistiche utilizzando UPDATE STATISTICS popola l'istogramma con un campione di tutti i dati nella tabella ma potrebbe non includere le informazioni rilevanti. Questo delta del conteggio delle righe è sufficiente per modificare il piano. Tuttavia, senza un aggiornamento delle statistiche e un istogramma accurato, il piano non cambierà in meglio poiché i dati cambiano.
Una selezione rilevante dell'istogramma per questa tabella da un backup del 4/11/2015 potrebbe essere simile a questa:
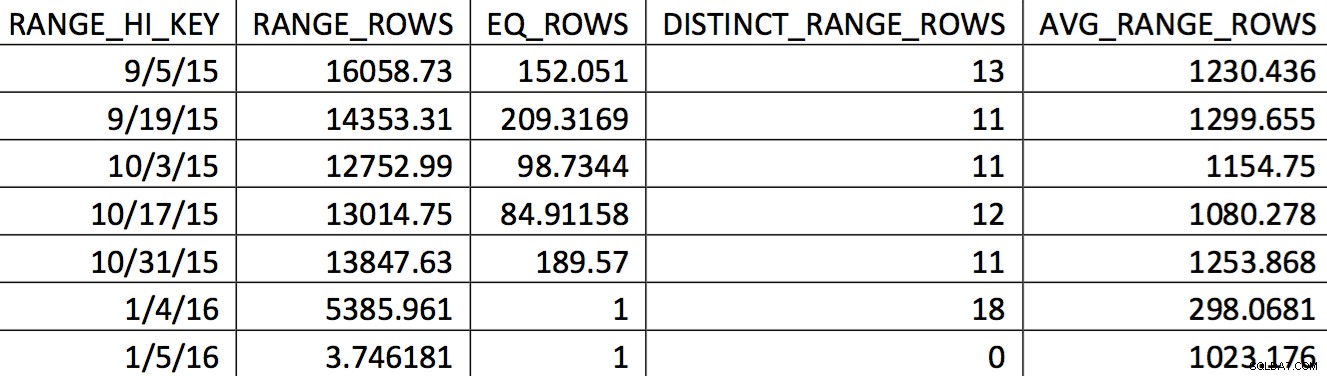
I valori di interesse non si riflettono accuratamente nell'istogramma. Quello che verrebbe utilizzato per la data del 5/11/2015 sarebbe il valore alto 4/1/2016. Sulla base del grafico, questo istogramma non è chiaramente una buona fonte di informazioni per l'ottimizzatore per la data di interesse. Forzare i valori d'uso nell'istogramma non è affidabile, quindi come puoi farlo? Il mio primo tentativo è stato quello di utilizzare ripetutamente WITH SAMPLE opzione di UPDATE STATISTICS e interroga l'istogramma fino a quando i valori di cui avevo bisogno non erano nell'istogramma (uno sforzo dettagliato qui). Alla fine, tale approccio si è rivelato inaffidabile.
Questo istogramma può portare a un piano con questo tipo di comportamento. La sottostima delle righe produce un join del ciclo nidificato e una ricerca dell'indice. Le letture sono successivamente più alte di quanto dovrebbero essere a causa di questa scelta di piano. Ciò avrà anche un effetto sulla durata dell'estratto conto.
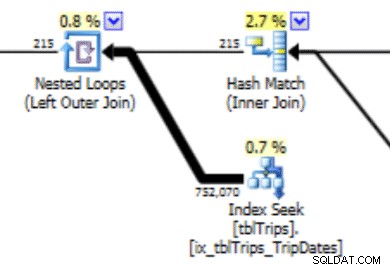
Ciò che funzionerebbe molto meglio è creare i dati esattamente come li desideri, ed ecco come farlo.
Esiste un'opzione non supportata di UPDATE STATISTICS :STATS_STREAM . Viene utilizzato dal supporto clienti Microsoft per esportare e importare le statistiche in modo che possano ottenere una ricreazione di un ottimizzatore senza avere tutti i dati nella tabella. Possiamo usare quella funzione. L'idea è quella di creare una tabella che imiti il DDL della statistica che vogliamo personalizzare. I dati rilevanti vengono aggiunti alla tabella. Le statistiche vengono esportate e importate nella tabella originale.
In questo caso, è una tabella con 200 righe di date non NULL e 1 riga che include i valori NULL. Inoltre, nella tabella è presente un indice che corrisponde all'indice con valori dell'istogramma errati.
Il nome della tabella è tblTripsScheduled . Ha un indice non cluster su (id, TheTripDate) e un indice cluster su TheTripDate . Ci sono poche altre colonne, ma solo quelle coinvolte nell'indice sono importanti.
Crea una tabella (tabella temporanea se vuoi) che imiti la tabella e l'indice. La tabella e l'indice si presentano così:
CREATE TABLE #tbltripsscheduled_cix_tripsscheduled(
id INT NOT NULL
, tripdate DATETIME NOT NULL
, PRIMARY KEY NONCLUSTERED(id, tripdate)
);
CREATE CLUSTERED INDEX thetripdate ON #tbltripsscheduled_cix_tripsscheduled(tripdate);
Successivamente, la tabella deve essere popolata con 200 righe di dati su cui basare le statistiche. Per la mia situazione, è il giorno dei prossimi sessanta giorni. Il passato e oltre i 60 giorni è popolato con una selezione "casuale" di ogni 10 giorni. (Il cnt il valore nel CTE è un valore di debug. Non ha un ruolo nei risultati finali.) L'ordine decrescente per il rn colonna assicura che siano inclusi i 60 giorni e quindi quanto più passato possibile.
DECLARE @date DATETIME = '20151104';
WITH tripdates
AS
(
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE NOT thetripdate BETWEEN @date AND @date
AND thetripdate < DATEADD(DAY, 60, @date) --only look 60 days out GROUP BY thetripdate
HAVING DATEDIFF(DAY, 0, thetripdate) % 10 = 0
UNION ALL
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE thetripdate BETWEEN @date AND DATEADD(DAY, 60, @date)
GROUP BY thetripdate
),
tripdate_top_200
AS
(
SELECT *
FROM
(
SELECT *, ROW_NUMBER() OVER(ORDER BY thetripdate DESC) rn
FROM tripdates
) td
WHERE rn <= 200
)
INSERT #tbltripsscheduled_cix_tripsscheduled (id, tripdate)
SELECT t.tripid, t.thetripdate
FROM tripdate_top_200 tp
INNER JOIN dbo.tbltripsscheduled t ON t.thetripdate = tp.thetripdate;
La nostra tabella è ora popolata con ogni riga che è preziosa per l'utente oggi e una selezione di righe storiche. Se la colonna TheTripdate era nullable, l'inserto avrebbe incluso anche quanto segue:
UNION ALL SELECT id, thetripdate FROM dbo.tbltripsscheduled WHERE thetripdate IS NULL;
Successivamente, aggiorniamo le statistiche sull'indice della nostra tabella temporanea.
UPDATE STATISTICS #tbltrips_IX_tbltrips_tripdates (tripdates) WITH FULLSCAN;
Ora, esporta quelle statistiche in una tabella temporanea. Quel tavolo assomiglia a questo. Corrisponde all'output di DBCC SHOW_STATISTICS WITH HISTOGRAM .
CREATE TABLE #stats_with_stream
(
stream VARBINARY(MAX) NOT NULL
, rows INT NOT NULL
, pages INT NOT NULL
);
DBCC SHOW_STATISTICS ha un'opzione per esportare le statistiche come flusso. È quel flusso che vogliamo. Quel flusso è anche lo stesso flusso di UPDATE STATISTICS utilizza l'opzione di flusso. Per farlo:
INSERT INTO #stats_with_stream --SELECT * FROM #stats_with_stream
EXEC ('DBCC SHOW_STATISTICS (N''tempdb..#tbltripsscheduled_cix_tripsscheduled'', thetripdate)
WITH STATS_STREAM,NO_INFOMSGS'); Il passaggio finale consiste nel creare l'SQL che aggiorni le statistiche della nostra tabella di destinazione, quindi eseguirlo.
DECLARE @sql NVARCHAR(MAX);
SET @sql = (SELECT 'UPDATE STATISTICS tbltripsscheduled(cix_tbltripsscheduled) WITH
STATS_STREAM = 0x' + CAST('' AS XML).value('xs:hexBinary(sql:column("stream"))',
'NVARCHAR(MAX)') FROM #stats_with_stream );
EXEC (@sql); A questo punto, abbiamo sostituito l'istogramma con il nostro personalizzato. Puoi verificare controllando l'istogramma:
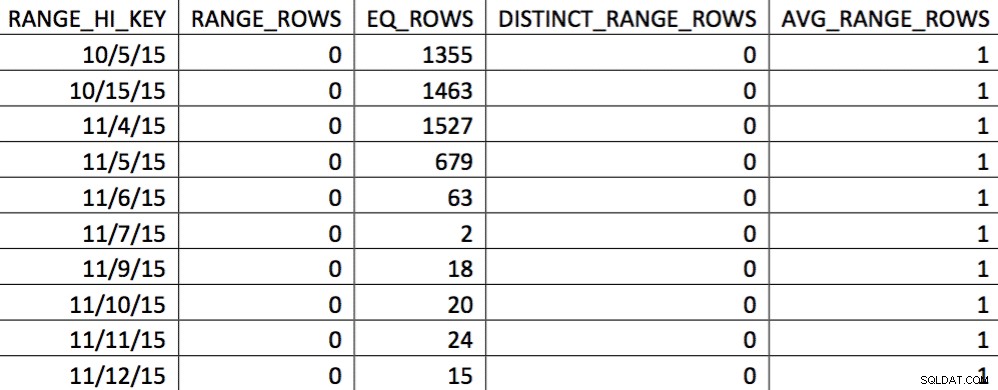
In questa selezione dei dati del 4/11 sono rappresentati tutti i giorni dal 4/11 in poi, e i dati storici sono rappresentati e accurati. Rivisitando la parte del piano di query mostrata in precedenza, puoi vedere che l'ottimizzatore ha fatto una scelta migliore in base alle statistiche corrette:
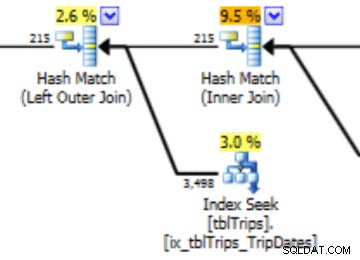
C'è un vantaggio in termini di prestazioni per le statistiche importate. Il costo per calcolare le statistiche è su una tabella "offline". L'unico tempo di inattività per la tabella di produzione è la durata dell'importazione del flusso.
Questo processo utilizza funzionalità non documentate e sembra che potrebbe essere pericoloso, ma ricorda che c'è un facile annullamento:la dichiarazione delle statistiche di aggiornamento. Se qualcosa va storto, le statistiche possono sempre essere aggiornate utilizzando T-SQL standard.
La pianificazione dell'esecuzione regolare di questo codice può aiutare notevolmente l'ottimizzatore a produrre piani migliori, dato un set di dati che cambia oltre il punto critico ma non abbastanza per attivare un aggiornamento delle statistiche.
Quando ho terminato la prima bozza di questo articolo, il conteggio delle righe sulla tabella nel primo grafico è cambiato da 217 a 717. Questa è una variazione del 300%. Questo è sufficiente per modificare il comportamento dell'ottimizzatore ma non sufficiente per attivare un aggiornamento delle statistiche. Questa modifica dei dati avrebbe lasciato un cattivo piano in atto. È con il processo qui descritto che questo problema viene risolto.
Riferimenti:
- AGGIORNAMENTO STATISTICHE (Libri online)
- White paper sulle statistiche di SQL 2008
- Ricerca punto critico