Questo articolo esamina alcune funzionalità e limitazioni di Query Optimizer meno note e spiega i motivi delle prestazioni estremamente scarse dell'hash join in un caso specifico.
Dati di esempio
Lo script di creazione dei dati di esempio che segue si basa su una tabella di numeri esistente. Se non si dispone già di uno di questi, è possibile utilizzare lo script seguente per crearne uno in modo efficiente. La tabella risultante conterrà una singola colonna intera con numeri da uno a un milione:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
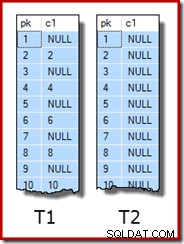
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); I dati del campione stesso sono costituiti da due tabelle, T1 e T2. Entrambi hanno una colonna di chiave primaria intera sequenziale denominata pk e una seconda colonna nullable denominata c1. La tabella T1 ha 600.000 righe in cui le righe pari hanno lo stesso valore per c1 della colonna pk e le righe dispari sono nulle. La tabella c2 ha 32.000 righe in cui la colonna c1 è NULL in ogni riga. Il seguente script crea e popola queste tabelle:
CREATE TABLE dbo.T1
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T1
PRIMARY KEY CLUSTERED (pk)
);
CREATE TABLE dbo.T2
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T2
PRIMARY KEY CLUSTERED (pk)
);
INSERT dbo.T1 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
CASE
WHEN N.n % 2 = 1 THEN NULL
ELSE N.n
END
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 600000;
INSERT dbo.T2 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
NULL
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 32000;
UPDATE STATISTICS dbo.T1 WITH FULLSCAN;
UPDATE STATISTICS dbo.T2 WITH FULLSCAN; Le prime dieci righe di dati di esempio in ogni tabella hanno il seguente aspetto:
Unire i due tavoli
Questo primo test prevede l'unione delle due tabelle sulla colonna c1 (non la colonna pk) e la restituzione del valore pk dalla tabella T1 per le righe che si uniscono:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1;
La query in realtà non restituirà alcuna riga perché la colonna c1 è NULL in tutte le righe della tabella T2, quindi nessuna riga può corrispondere al predicato di uguaglianza di join. Può sembrare una cosa strana da fare, ma sono certo che si basa su una query di produzione reale (molto semplificata per facilità di discussione).
Si noti che questo risultato vuoto non dipende dall'impostazione di ANSI_NULLS, perché controlla solo il modo in cui vengono gestiti i confronti con un valore letterale o una variabile null. Per i confronti di colonne, un predicato di uguaglianza rifiuta sempre i valori null.
Il piano di esecuzione per questa semplice query di join ha alcune caratteristiche interessanti. Esamineremo innanzitutto il piano di pre-esecuzione ("stimato") in SQL Sentry Plan Explorer:
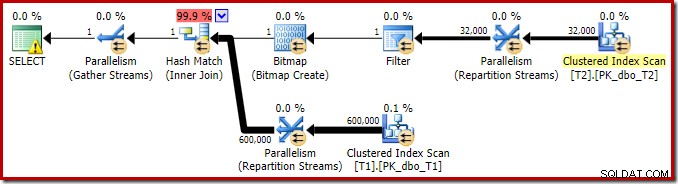
L'avviso sull'icona SELECT si lamenta solo di un indice mancante nella tabella T1 per la colonna c1 (con pk come colonna inclusa). Il suggerimento sull'indice è irrilevante qui.
Il primo vero elemento di interesse in questo piano è il Filtro:
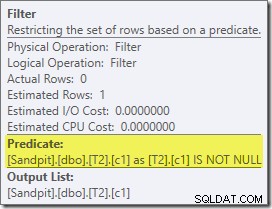
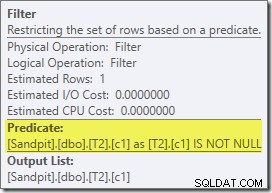
Questo predicato NON È NULL non appare nella query di origine, sebbene sia implicito nel predicato join come accennato in precedenza. È interessante notare che è stato suddiviso come un operatore extra esplicito e posizionato prima dell'operazione di unione. Nota che anche senza il filtro, la query produrrebbe comunque risultati corretti:il join stesso rifiuterebbe comunque i valori null.
Il filtro è curioso anche per altri motivi. Ha un costo stimato esattamente pari a zero (anche se dovrebbe funzionare su 32.000 righe) e non è stato inserito nella scansione dell'indice cluster come predicato residuo. L'ottimizzatore normalmente è piuttosto desideroso di farlo.
Entrambe queste cose sono spiegate dal fatto che questo filtro viene introdotto in una riscrittura post-ottimizzazione. Dopo che Query Optimizer ha completato l'elaborazione basata sui costi, viene considerato un numero relativamente piccolo di riscritture del piano fisso. Uno di questi è responsabile dell'introduzione del filtro.
Possiamo vedere l'output della selezione del piano basata sui costi (prima della riscrittura) utilizzando i flag di traccia non documentati 8607 e il familiare 3604 per indirizzare l'output testuale alla console (scheda messaggi in SSMS):
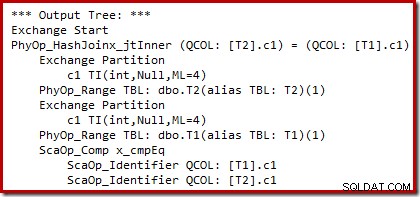
L'albero di output mostra un hash join, due scansioni e alcuni operatori di parallelismo (scambio). Non esiste alcun filtro di rifiuto nullo nella colonna c1 della tabella T2.
La particolare riscrittura post-ottimizzazione esamina esclusivamente l'input di compilazione di un hash join. A seconda della sua valutazione della situazione, può aggiungere un filtro esplicito per rifiutare le righe che sono nulle nella chiave di unione. Anche l'effetto del filtro sul conteggio delle righe stimato viene scritto nel piano di esecuzione, ma poiché l'ottimizzazione basata sui costi è già stata completata, non viene calcolato un costo per il filtro. Nel caso non sia ovvio, calcolare i costi è uno spreco di sforzi se tutte le decisioni basate sui costi sono già state prese.
Il filtro rimane direttamente sull'input di compilazione anziché essere inserito nella scansione dell'indice cluster perché l'attività di ottimizzazione principale è stata completata. Le riscritture successive all'ottimizzazione sono in effetti modifiche dell'ultimo minuto a un piano di esecuzione completato.
Una seconda riscrittura post-ottimizzazione, abbastanza separata, è responsabile dell'operatore Bitmap nel piano finale (potresti aver notato che mancava anche nell'output 8607):
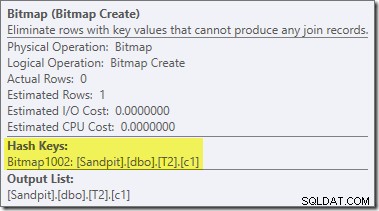
Questo operatore ha anche un costo stimato pari a zero sia per l'I/O che per la CPU. L'altra cosa che lo identifica come un operatore introdotto da un tweak tardivo (piuttosto che durante l'ottimizzazione basata sui costi) è che il suo nome è Bitmap seguito da un numero. Ci sono altri tipi di bitmap introdotti durante l'ottimizzazione basata sui costi, come vedremo più avanti.
Per ora, la cosa importante di questa bitmap è che registra i valori c1 visti durante la fase di compilazione dell'hash join. La bitmap completata viene inviata al lato sonda del join quando l'hash passa dalla fase di compilazione alla fase di analisi. La bitmap viene utilizzata per eseguire la riduzione semi-unione anticipata, eliminando le righe dal lato del probe che non possono eventualmente unirsi. se hai bisogno di maggiori dettagli in merito, consulta il mio precedente articolo sull'argomento.
Il secondo effetto della bitmap può essere visto sulla scansione dell'indice cluster lato sonda:
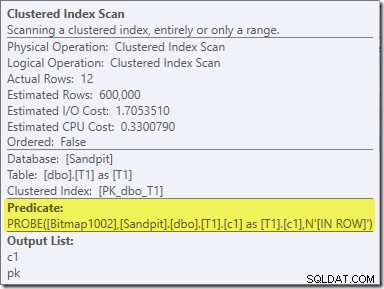
La schermata sopra mostra la bitmap completata che viene controllata come parte della scansione dell'indice cluster sulla tabella T1. Poiché la colonna di origine è un numero intero (funziona anche un bigint), il controllo della bitmap viene inserito completamente nel motore di archiviazione (come indicato dal qualificatore 'INROW') anziché essere controllato dal Query Processor. Più in generale, la bitmap può essere applicata a qualsiasi operatore lato sonda, dallo scambio in giù. Fino a che punto il Query Processor può spingere la bitmap dipende dal tipo di colonna e dalla versione di SQL Server.
Per completare l'analisi delle principali caratteristiche di questo piano di esecuzione, dobbiamo guardare al piano successivo all'esecuzione ("effettivo"):
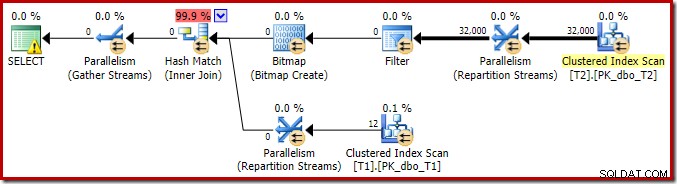
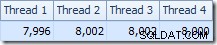
La prima cosa da notare è la distribuzione delle righe tra i thread tra la scansione T2 e lo scambio Repartition Streams immediatamente sopra di esso. Durante un test, ho visto la seguente distribuzione su un sistema con quattro processori logici:
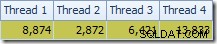
La distribuzione non è particolarmente uniforme, come spesso accade per una scansione parallela su un numero relativamente piccolo di righe, ma almeno tutti i thread hanno ricevuto un po' di lavoro. La distribuzione dei thread tra lo stesso scambio Repartition Streams e il filtro è molto diversa:
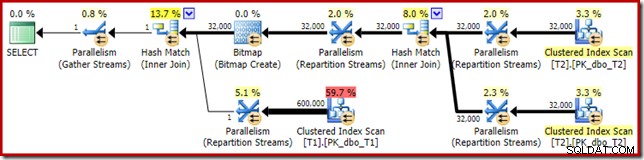
Ciò mostra che tutte le 32.000 righe della tabella T2 sono state elaborate da un singolo thread. Per capire perché, dobbiamo guardare le proprietà dello scambio:

Questo scambio, come quello sul lato sonda dell'hash join, deve garantire che le righe con gli stessi valori di chiave di join finiscano nella stessa istanza dell'hash join. In DOP 4, ci sono quattro hash join, ognuno con la propria tabella hash. Per risultati corretti, le righe build-side e probe-side con le stesse chiavi di join devono arrivare allo stesso hash join; altrimenti potremmo controllare una riga lato sonda rispetto alla tabella hash errata.
In un piano parallelo in modalità riga, SQL Server ottiene questo risultato ripartizionando entrambi gli input usando la stessa funzione hash nelle colonne di join. In questo caso, il join si trova sulla colonna c1, quindi gli input sono distribuiti tra i thread applicando una funzione hash (tipo di partizionamento:hash) alla colonna della chiave di join (c1). Il problema qui è che la colonna c1 contiene un solo valore - null - nella tabella T2, quindi a tutte le 32.000 righe viene assegnato lo stesso valore hash, in modo che tutte finiscano sullo stesso thread.
La buona notizia è che nulla di tutto ciò è davvero importante per questa query. Il filtro di riscrittura post-ottimizzazione elimina tutte le righe prima che molto lavoro venga svolto. Sul mio laptop, la query sopra viene eseguita (non producendo risultati, come previsto) in circa 70 ms .
Unisciti a tre tavoli
Per il secondo test, aggiungiamo un ulteriore join dalla tabella T2 a se stessa sulla sua chiave primaria:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 -- New! ON T3.pk = T2.pk;
Questo non cambia i risultati logici della query, ma cambia il piano di esecuzione:
Come previsto, l'auto-unione della tabella T2 sulla sua chiave primaria non ha effetto sul numero di righe che si qualificano da quella tabella:
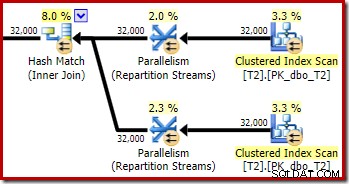
Anche la distribuzione delle righe tra i thread è buona in questa sezione del piano. Per le scansioni, è simile a prima perché la scansione parallela distribuisce le righe ai thread su richiesta. La ripartizione degli scambi si basa su un hash della chiave di unione, che questa volta è la colonna pk. Data la gamma di valori pk diversi, anche la distribuzione del thread risultante è molto uniforme:
Passando alla sezione più interessante del piano stimato, ci sono alcune differenze rispetto al test a due tabelle:

Ancora una volta, lo scambio lato build finisce per indirizzare tutte le righe allo stesso thread perché c1 è la chiave di unione, e quindi la colonna di partizionamento per gli scambi Repartition Streams (ricorda, c1 è nullo per tutte le righe nella tabella T2).
Ci sono altre due importanti differenze in questa sezione del piano rispetto al test precedente. Innanzitutto, non esiste alcun filtro per rimuovere le righe null-c1 dal lato build dell'hash join. La spiegazione di ciò è legata alla seconda differenza:la Bitmap è cambiata, anche se non è evidente dall'immagine sopra:
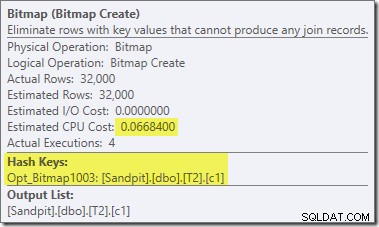
Questa è una Opt_Bitmap, non una Bitmap. La differenza è che questa bitmap è stata introdotta durante l'ottimizzazione basata sui costi, non tramite una riscrittura dell'ultimo minuto. Il meccanismo che considera le bitmap ottimizzate è associato all'elaborazione delle query di unione a stella. La logica star-join richiede almeno tre tabelle unite, quindi questo spiega perché un ottimizzato la bitmap non è stata considerata nell'esempio di join di due tabelle.
Questa bitmap ottimizzata ha un costo della CPU stimato diverso da zero e influisce direttamente sul piano generale scelto dall'ottimizzatore. Il suo effetto sulla stima della cardinalità lato sonda può essere visto nell'operatore Repartition Streams:
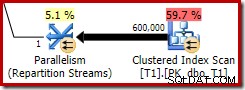
Nota che l'effetto di cardinalità è visibile allo scambio, anche se la bitmap viene infine spinta fino in fondo nel motore di archiviazione ("INROW") proprio come abbiamo visto nel primo test (ma nota ora il riferimento Opt_Bitmap):
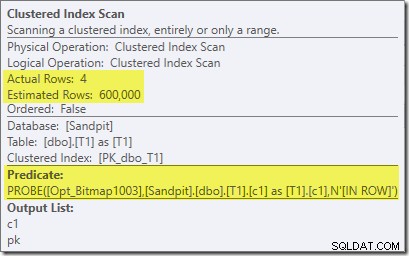
Il piano successivo all'esecuzione ("effettivo") è il seguente:
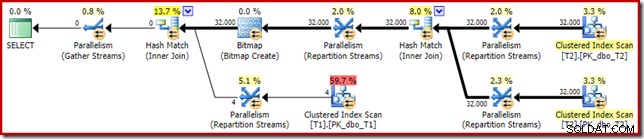
L'efficacia prevista della bitmap ottimizzata significa che la riscrittura post-ottimizzazione separata per il filtro nullo non viene applicata. Personalmente, penso che questo sia un peccato perché l'eliminazione anticipata dei valori null con un filtro annullerebbe la necessità di creare la bitmap, popolare le tabelle hash ed eseguire la scansione ottimizzata della bitmap della tabella T1. Tuttavia, l'ottimizzatore decide diversamente e in questo caso non si può discutere.
Nonostante l'auto-unione aggiuntiva della tabella T2 e il lavoro aggiuntivo associato al filtro mancante, questo piano di esecuzione produce comunque il risultato previsto (nessuna riga) in tempi rapidi. Un'esecuzione tipica sul mio laptop richiede circa 200 ms .
Cambiare il tipo di dati
Per questo terzo test, cambieremo il tipo di dati della colonna c1 in entrambe le tabelle da intero a decimale. Non c'è niente di particolarmente speciale in questa scelta; lo stesso effetto può essere visto con qualsiasi tipo numerico che non sia intero o bigint.
ALTER TABLE dbo.T1 ALTER COLUMN c1 decimal(9,0) NULL; ALTER TABLE dbo.T2 ALTER COLUMN c1 decimal(9,0) NULL; ALTER INDEX PK_dbo_T1 ON dbo.T1 REBUILD WITH (MAXDOP = 1); ALTER INDEX PK_dbo_T2 ON dbo.T2 REBUILD WITH (MAXDOP = 1); UPDATE STATISTICS dbo.T1 WITH FULLSCAN; UPDATE STATISTICS dbo.T2 WITH FULLSCAN;
Riutilizzo della query di join a tre join:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk;
Il piano di esecuzione stimato sembra molto familiare:
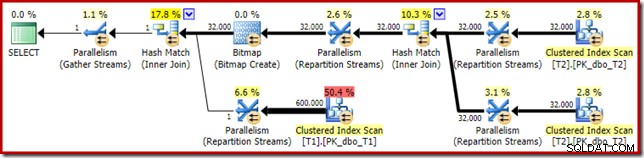
A parte il fatto che la bitmap ottimizzata non può più essere applicata "INROW" dal motore di archiviazione a causa della modifica del tipo di dati, il piano di esecuzione è sostanzialmente identico. L'acquisizione seguente mostra la modifica delle proprietà di scansione:
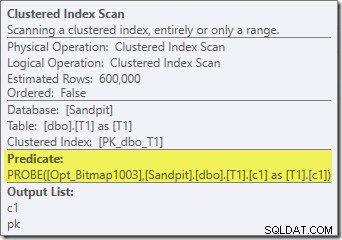
Sfortunatamente, le prestazioni sono influenzate in modo piuttosto drammatico. Questa query non viene eseguita in 70 ms o 200 ms, ma in circa 20 minuti . Nel test che ha prodotto il seguente piano post-esecuzione, il tempo di esecuzione è stato effettivamente di 22 minuti e 29 secondi:

La differenza più ovvia è che la scansione dell'indice cluster sulla tabella T1 restituisce 300.000 righe anche dopo l'applicazione del filtro bitmap ottimizzato. Questo ha un senso, poiché la bitmap è costruita su righe che contengono solo valori null nella colonna c1. La bitmap rimuove le righe non Null dalla scansione T1, lasciando solo le 300.000 righe con valori Null per c1. Ricorda, metà delle righe in T1 sono nulle.
Anche così, sembra strano che l'unione di 32.000 righe con 300.000 righe richieda più di 20 minuti. Nel caso ti stavi chiedendo, un core della CPU è stato ancorato al 100% per l'intera esecuzione. La spiegazione di queste scarse prestazioni e dell'utilizzo estremo delle risorse si basa su alcune idee che abbiamo esplorato in precedenza:
Sappiamo già, ad esempio, che nonostante le icone di esecuzione parallela, tutte le righe di T2 finiscono sullo stesso thread. Come promemoria, l'hash join parallelo in modalità riga richiede il ripartizionamento sulle colonne di join (c1). Tutte le righe di T2 hanno lo stesso valore – null – nella colonna c1, quindi tutte le righe finiscono sullo stesso thread. Allo stesso modo, anche tutte le righe di T1 che passano il filtro bitmap hanno null nella colonna c1, quindi anche ripartizioni nello stesso thread. Questo spiega perché un singolo core fa tutto il lavoro.
Potrebbe comunque sembrare irragionevole che l'hash che unisce 32.000 righe con 300.000 righe richieda 20 minuti, soprattutto perché le colonne di join su entrambi i lati sono nulle e non si uniranno comunque. Per capirlo, dobbiamo pensare a come funziona questo hash join.
L'input di compilazione (le 32.000 righe) crea una tabella hash utilizzando la colonna di join, c1. Poiché ogni riga del lato build contiene lo stesso valore (null) per la colonna di join c1, ciò significa che tutte le 32.000 righe finiscono nello stesso bucket di hash. Quando l'hash join passa al rilevamento delle corrispondenze, anche ogni riga del lato sonda con una colonna c1 nulla esegue l'hashing nello stesso bucket. L'hash join deve quindi controllare tutte le 32.000 voci in quel bucket per trovare una corrispondenza.
Il controllo delle 300.000 righe di sonda comporta 32.000 confronti effettuati 300.000 volte. Questo è il caso peggiore per un hash join:tutte le righe laterali costruiscono hash sullo stesso bucket, risultando in quello che è essenzialmente un prodotto cartesiano. Questo spiega il lungo tempo di esecuzione e l'utilizzo costante del processore al 100% poiché l'hash segue la lunga catena del bucket di hash.
Queste scarse prestazioni aiutano a spiegare perché esiste la riscrittura post-ottimizzazione per eliminare i valori null sull'input di compilazione in un hash join. È un peccato che il filtro non sia stato applicato in questo caso.
Soluzioni alternative
L'ottimizzatore sceglie questa forma del piano perché stima erroneamente che la bitmap ottimizzata filtrerà tutte le righe dalla tabella T1. Sebbene questa stima sia mostrata in Repartition Streams invece che in Clustered Index Scan, questa è ancora la base della decisione. Ricordiamo qui di nuovo la sezione pertinente del piano di pre-esecuzione:
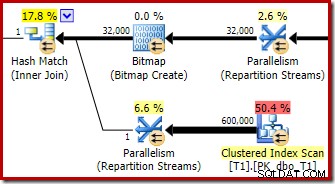
Se questa fosse una stima corretta, l'elaborazione dell'hash join non richiederebbe molto tempo. È un peccato che la stima della selettività per la bitmap ottimizzata sia così errata quando il tipo di dati non è un semplice intero o bigint. Sembra che una bitmap costruita su una chiave intera o bigint sia anche in grado di filtrare le righe nulle che non possono unirsi. Se questo è davvero il caso, questo è uno dei motivi principali per preferire colonne intere o bigint join.
Le soluzioni alternative che seguono si basano in gran parte sull'idea di eliminare le bitmap ottimizzate problematiche.
Esecuzione seriale
Un modo per evitare che vengano prese in considerazione bitmap ottimizzate consiste nel richiedere un piano non parallelo. Gli operatori Bitmap in modalità riga (ottimizzati o meno) sono visibili solo nei piani paralleli:
SELECT T1.pk
FROM
(
dbo.T2 AS T2
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
)
JOIN dbo.T1 AS T1
ON T1.c1 = T2.c1
OPTION (MAXDOP 1, FORCE ORDER); Tale query viene espressa utilizzando una sintassi leggermente diversa con un suggerimento FORCE ORDER per generare una forma del piano più facilmente confrontabile con i precedenti piani paralleli. La caratteristica essenziale è il suggerimento MAXDOP 1.
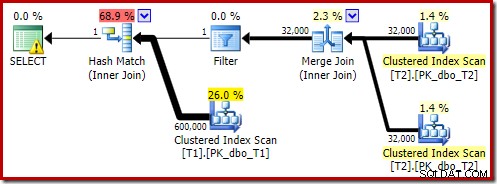
Il piano stimato mostra il ripristino del filtro di riscrittura post-ottimizzazione:
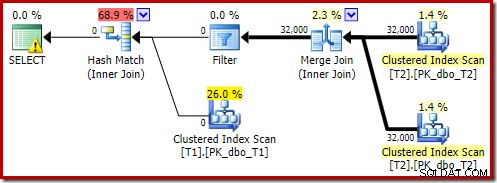
La versione post-esecuzione del piano mostra che filtra tutte le righe dall'input di compilazione, il che significa che la scansione laterale del probe può essere saltata del tutto:
Come ci si aspetterebbe, questa versione della query viene eseguita molto rapidamente, circa 20 ms in media per me. Possiamo ottenere un effetto simile senza l'hint FORCE ORDER e la riscrittura della query:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (MAXDOP 1);
L'ottimizzatore sceglie in questo caso una forma del piano diversa, con il filtro posizionato direttamente sopra la scansione di T2:
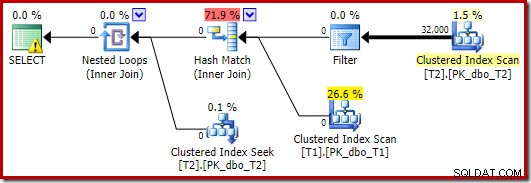
Questo viene eseguito ancora più velocemente, in circa 10 ms, come ci si aspetterebbe. Naturalmente, questa non sarebbe una buona scelta se il numero di righe presenti (e unibili) fosse molto maggiore.
Disattivazione delle bitmap ottimizzate
Non esiste alcun suggerimento per la query per disattivare le bitmap ottimizzate, ma possiamo ottenere lo stesso effetto utilizzando un paio di flag di traccia non documentati. Come sempre, questo è solo per il valore dell'interesse; non vorresti mai usarli in un sistema o in un'applicazione reale:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYTRACEON 7497, QUERYTRACEON 7498);
Il piano di esecuzione risultante è:
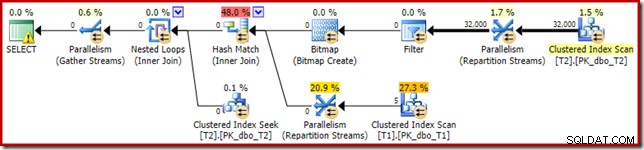
La bitmap esiste una bitmap di riscrittura post-ottimizzazione, non una bitmap ottimizzata:
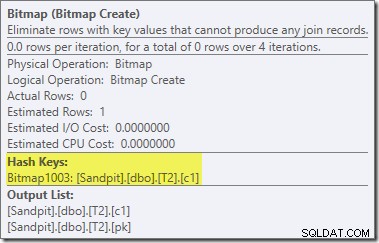
Nota le stime di costo zero e il nome Bitmap (piuttosto che Opt_Bitmap). senza una bitmap ottimizzata per distorcere le stime dei costi, viene attivata la riscrittura post-ottimizzazione per includere un filtro di rifiuto nullo. Questo piano di esecuzione dura circa 70 ms .
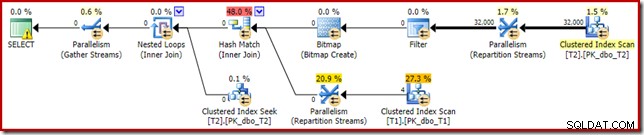
Lo stesso piano di esecuzione (con Filtro e Bitmap non ottimizzato) può essere prodotto anche disabilitando la regola dell'ottimizzatore responsabile della generazione di piani bitmap di join a stella (di nuovo, rigorosamente non documentati e non per l'uso nel mondo reale):
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYRULEOFF StarJoinToHashJoinsWithBitmap);
Incluso un filtro esplicito
Questa è l'opzione più semplice, ma si potrebbe pensare di farlo solo se consapevoli delle questioni discusse finora. Ora che sappiamo che dobbiamo eliminare i null da T2.c1, possiamo aggiungerlo direttamente alla query:
SELECT T1.pk
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.c1 = T1.c1
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
WHERE
T2.c1 IS NOT NULL; -- New! Il piano di esecuzione stimato risultante forse non è proprio quello che ti aspetteresti:
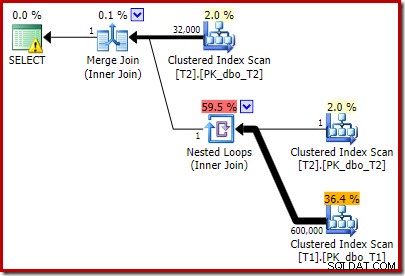
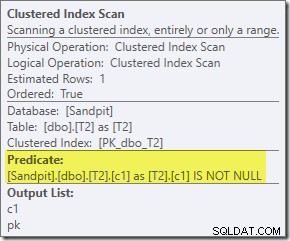
Il predicato aggiuntivo che abbiamo aggiunto è stato inserito nella scansione dell'indice cluster centrale di T2:
Il piano post-esecuzione è:
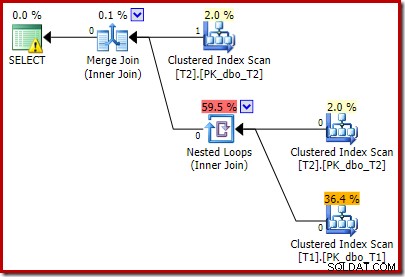
Si noti che Merge Join si chiude dopo aver letto una riga dal suo input superiore, quindi non riesce a trovare una riga sull'input inferiore, a causa dell'effetto del predicato che abbiamo aggiunto. La scansione dell'indice cluster della tabella T1 non viene mai eseguita, perché il join Nested Loops non ottiene mai una riga sul suo input di guida. Questo modulo di query finale viene eseguito in uno o due millisecondi.
Pensieri finali
Questo articolo ha coperto una discreta quantità di terreno per esplorare alcuni comportamenti meno noti di Query Optimizer e spiegare i motivi delle prestazioni estremamente scarse dell'hash join in un caso specifico.
Potrebbe essere allettante chiedersi perché l'ottimizzatore non aggiunge regolarmente filtri di rifiuto nullo prima dei join di uguaglianza. Si può solo supporre che ciò non sarebbe vantaggioso in casi abbastanza comuni. La maggior parte dei join non dovrebbe incontrare molti rifiuti null =null e l'aggiunta di predicati di routine potrebbe rapidamente diventare controproducente, in particolare se sono presenti molte colonne di join. Per la maggior parte dei join, rifiutare i valori null all'interno dell'operatore di join è probabilmente un'opzione migliore (dal punto di vista del modello di costo) rispetto all'introduzione di un filtro esplicito.
Sembra che ci sia uno sforzo per impedire che i casi peggiori si manifestino attraverso la riscrittura post-ottimizzazione progettata per rifiutare le righe di join null prima che raggiungano l'input di compilazione di un hash join. Sembra che esista una sfortunata interazione tra l'effetto di filtri bitmap ottimizzati e l'applicazione di questa riscrittura. È anche un peccato che quando si verifica questo problema di prestazioni, è molto difficile diagnosticare dal solo piano di esecuzione.
Per ora, l'opzione migliore sembra essere consapevole di questo potenziale problema di prestazioni con gli hash join su colonne nullable e aggiungere predicati espliciti di rifiuto nullo (con un commento!) Per garantire che venga prodotto un piano di esecuzione efficiente, se necessario. L'utilizzo di un suggerimento MAXDOP 1 può anche rivelare un piano alternativo con il filtro rivelatore presente.
Come regola generale, le query che si uniscono su colonne di tipo intero e cercano dati esistenti tendono a adattarsi al modello di ottimizzazione e alle capacità del motore di esecuzione piuttosto che alle alternative.
Ringraziamenti
Voglio ringraziare SQL_Sasquatch (@sqL_handLe) per il suo permesso di rispondere al suo articolo originale con un'analisi tecnica. I dati di esempio utilizzati qui sono ampiamente basati su quell'articolo.
Voglio anche ringraziare Rob Farley (blog | twitter) per le nostre discussioni tecniche nel corso degli anni, e in particolare una a gennaio 2015 in cui abbiamo discusso le implicazioni di predicati di rifiuto nullo extra per gli equi-join. Rob ha scritto diverse volte su argomenti correlati, anche in Inverse Predicates:guarda in entrambe le direzioni prima di attraversare.