Lo scorso ottobre abbiamo sfidato il pubblico dei nostri PyBites a creare un'app Web per navigare meglio nel feed Daily Python Tip. In questo articolo condividerò ciò che ho costruito e imparato lungo il percorso.
In questo articolo imparerai:
- Come clonare il repository del progetto e configurare l'app.
- Come utilizzare l'API di Twitter tramite il modulo Tweepy per caricare i tweet.
- Come utilizzare SQLAlchemy per archiviare e gestire i dati (suggerimenti e hashtag).
- Come creare una semplice web app con Bottle, un micro web framework simile a Flask.
- Come utilizzare il framework pytest per aggiungere test.
- La guida di How Better Code Hub ha portato a un codice più gestibile.
Se vuoi seguire, leggere il codice in dettaglio (ed eventualmente contribuire), ti suggerisco di eseguire il fork del repository. Iniziamo.
Impostazione progetto
Innanzitutto, Gli spazi dei nomi sono un'ottima idea che suona il clacson quindi facciamo il nostro lavoro in un ambiente virtuale. Usando Anaconda lo creo così:
$ virtualenv -p <path-to-python-to-use> ~/virtualenvs/pytip
Crea un database di produzione e test in Postgres:
$ psql
psql (9.6.5, server 9.6.2)
Type "help" for help.
# create database pytip;
CREATE DATABASE
# create database pytip_test;
CREATE DATABASE
Avremo bisogno delle credenziali per connetterci al database e all'API di Twitter (creare prima una nuova app). Come da best practice, la configurazione deve essere archiviata nell'ambiente, non nel codice. Metti le seguenti variabili env alla fine di ~/virtualenvs/pytip/bin/activate , lo script che gestisce l'attivazione/disattivazione del tuo ambiente virtuale, assicurandosi di aggiornare le variabili per il tuo ambiente:
export DATABASE_URL='postgres://postgres:password@localhost:5432/pytip'
# twitter
export CONSUMER_KEY='xyz'
export CONSUMER_SECRET='xyz'
export ACCESS_TOKEN='xyz'
export ACCESS_SECRET='xyz'
# if deploying it set this to 'heroku'
export APP_LOCATION=local
Nella funzione di disattivazione dello stesso script, li disattivo in modo da mantenere le cose fuori dall'ambito della shell quando si disattiva (lascia) l'ambiente virtuale:
unset DATABASE_URL
unset CONSUMER_KEY
unset CONSUMER_SECRET
unset ACCESS_TOKEN
unset ACCESS_SECRET
unset APP_LOCATION
Ora è un buon momento per attivare l'ambiente virtuale:
$ source ~/virtualenvs/pytip/bin/activate
Clona il repository e, con l'ambiente virtuale abilitato, installa i requisiti:
$ git clone https://github.com/pybites/pytip && cd pytip
$ pip install -r requirements.txt
Successivamente, importiamo la raccolta di tweet con:
$ python tasks/import_tweets.py
Quindi, verifica che le tabelle siano state create e che i tweet siano stati aggiunti:
$ psql
\c pytip
pytip=# \dt
List of relations
Schema | Name | Type | Owner
--------+----------+-------+----------
public | hashtags | table | postgres
public | tips | table | postgres
(2 rows)
pytip=# select count(*) from tips;
count
-------
222
(1 row)
pytip=# select count(*) from hashtags;
count
-------
27
(1 row)
pytip=# \q
Ora eseguiamo i test:
$ pytest
========================== test session starts ==========================
platform darwin -- Python 3.6.2, pytest-3.2.3, py-1.4.34, pluggy-0.4.0
rootdir: realpython/pytip, inifile:
collected 5 items
tests/test_tasks.py .
tests/test_tips.py ....
========================== 5 passed in 0.61 seconds ==========================
E infine esegui l'app Bottle con:
$ python app.py
Vai a https://localhost:8080 e voilà:dovresti vedere i suggerimenti ordinati in base alla popolarità. Cliccando su un link hashtag a sinistra, o usando la casella di ricerca, puoi filtrarli facilmente. Qui vediamo i panda suggerimenti per esempio:
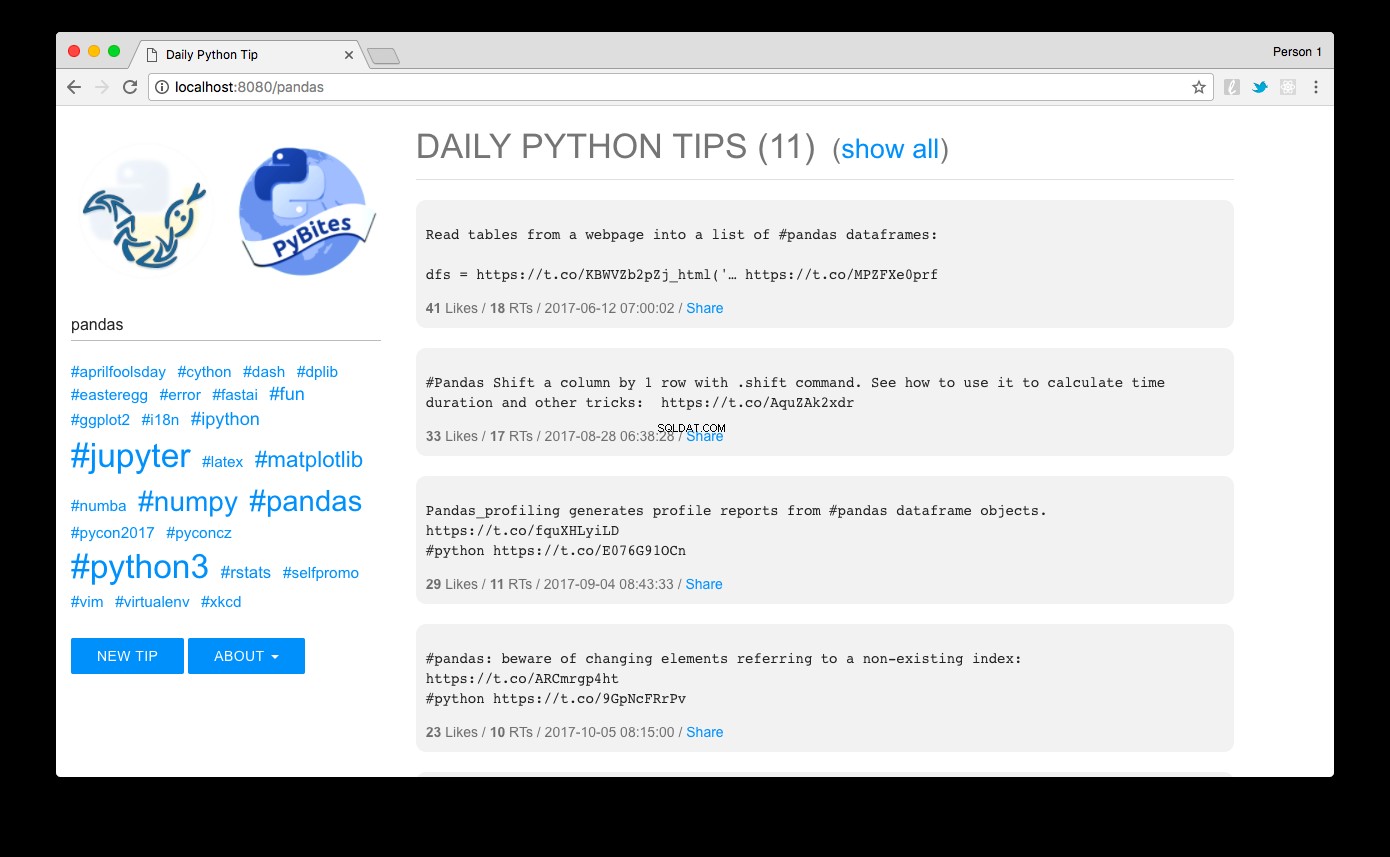
Il design che ho realizzato con MUI, un framework CSS leggero che segue le linee guida di Material Design di Google.
Dettagli di implementazione
Il DB e SQLAlchemy
Ho usato SQLAlchemy per interfacciarmi con il DB per evitare di dover scrivere molto SQL (ridondante).
In suggerimenti/modelli.py , definiamo i nostri modelli - Hashtag e Tip - che SQLAlchemy eseguirà il mapping alle tabelle DB:
from sqlalchemy import Column, Sequence, Integer, String, DateTime
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Hashtag(Base):
__tablename__ = 'hashtags'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
name = Column(String(20))
count = Column(Integer)
def __repr__(self):
return "<Hashtag('%s', '%d')>" % (self.name, self.count)
class Tip(Base):
__tablename__ = 'tips'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
tweetid = Column(String(22))
text = Column(String(300))
created = Column(DateTime)
likes = Column(Integer)
retweets = Column(Integer)
def __repr__(self):
return "<Tip('%d', '%s')>" % (self.id, self.text)
In tips/db.py , importiamo questi modelli e ora è facile lavorare con il DB, ad esempio per interfacciarsi con l'Hashtag modello:
def get_hashtags():
return session.query(Hashtag).order_by(Hashtag.name.asc()).all()
E:
def add_hashtags(hashtags_cnt):
for tag, count in hashtags_cnt.items():
session.add(Hashtag(name=tag, count=count))
session.commit()
Interroga l'API di Twitter
Dobbiamo recuperare i dati da Twitter. Per questo, ho creato tasks/import_tweets.py . L'ho impacchettato in attività perché dovrebbe essere eseguito in un cronjob quotidiano per cercare nuovi suggerimenti e aggiornare le statistiche (numero di Mi piace e retweet) sui tweet esistenti. Per semplicità ho ricreato le tavole giornalmente. Se iniziamo a fare affidamento sulle relazioni FK con altre tabelle, dovremmo assolutamente scegliere le istruzioni di aggiornamento su delete+add.
Abbiamo usato questo script nell'impostazione del progetto. Vediamo cosa fa più nel dettaglio.
Innanzitutto, creiamo un oggetto sessione API che passiamo a tweepy.Cursor. Questa caratteristica dell'API è davvero carina:si occupa dell'impaginazione, iterando nella timeline. Per la quantità di suggerimenti - 222 al momento in cui scrivo questo - è davvero veloce. Il exclude_replies=True e include_rts=False gli argomenti sono convenienti perché vogliamo solo i tweet di Daily Python Tip (non i re-tweet).
L'estrazione degli hashtag dai suggerimenti richiede pochissimo codice.
Innanzitutto, ho definito una regex per un tag:
TAG = re.compile(r'#([a-z0-9]{3,})')
Quindi, ho usato findall per ottenere tutti i tag.
Li ho passati a collections.Counter che restituisce un oggetto simile a dict con i tag come chiavi e conta come valori, ordinati in ordine decrescente per valori (il più comune). Ho escluso il tag Python troppo comune che distorcerebbe i risultati.
def get_hashtag_counter(tips):
blob = ' '.join(t.text.lower() for t in tips)
cnt = Counter(TAG.findall(blob))
if EXCLUDE_PYTHON_HASHTAG:
cnt.pop('python', None)
return cnt
Infine, import_* funzioni in tasks/import_tweets.py esegui l'effettiva importazione dei tweet e degli hashtag, chiamando add_* Metodi DB dei suggerimenti directory/pacchetto.
Crea una semplice app web con Bottle
Con questo lavoro preliminare completato, creare un'app Web è sorprendentemente facile (o non così sorprendente se hai usato Flask prima).
Prima di tutto incontra Bottle:
Bottle è un micro web framework WSGI veloce, semplice e leggero per Python. È distribuito come un modulo di file singolo e non ha dipendenze diverse dalla libreria standard di Python.
Bello. L'app Web risultante comprende <30 LOC e può essere trovata in app.py.
Per questa semplice app, è sufficiente un singolo metodo con un argomento tag opzionale. Simile a Flask, il routing viene gestito con i decoratori. Se chiamato con un tag filtra i suggerimenti sul tag, altrimenti li mostra tutti. Il decoratore di viste definisce il modello da utilizzare. Come Flask (e Django) restituiamo un dict da utilizzare nel modello.
@route('/')
@route('/<tag>')
@view('index')
def index(tag=None):
tag = tag or request.query.get('tag') or None
tags = get_hashtags()
tips = get_tips(tag)
return {'search_tag': tag or '',
'tags': tags,
'tips': tips}
Come da documentazione, per lavorare con i file statici, aggiungi questo snippet in alto, dopo le importazioni:
@route('/static/<filename:path>')
def send_static(filename):
return static_file(filename, root='static')
Infine, vogliamo assicurarci di essere eseguiti solo in modalità debug su localhost, da qui APP_LOCATION env variabile che abbiamo definito in Configurazione progetto:
if os.environ.get('APP_LOCATION') == 'heroku':
run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))
else:
run(host='localhost', port=8080, debug=True, reloader=True)
Modelli di bottiglia
Bottle viene fornito con un motore di modelli integrato veloce, potente e facile da imparare chiamato SimpleTemplate.
Nella sottodirectory views ho definito un header.tpl , index.tpl e footer.tpl . Per il tag cloud, ho usato dei semplici CSS in linea aumentando le dimensioni dei tag in base al conteggio, vedi header.tpl :
% for tag in tags:
<a style="font-size: {{ tag.count/10 + 1 }}em;" href="/{{ tag.name }}">#{{ tag.name }}</a>
% end
In index.tpl esaminiamo i suggerimenti:
% for tip in tips:
<div class='tip'>
<pre>{{ !tip.text }}</pre>
<div class="mui--text-dark-secondary"><strong>{{ tip.likes }}</strong> Likes / <strong>{{ tip.retweets }}</strong> RTs / {{ tip.created }} / <a href="https://twitter.com/python_tip/status/{{ tip.tweetid }}" target="_blank">Share</a></div>
</div>
% end
Se hai familiarità con Flask e Jinja2, questo dovrebbe sembrare molto familiare. Incorporare Python è ancora più semplice, con meno digitazione:(% ... rispetto a {% ... %} ).
Tutti i CSS, le immagini (e JS se lo usiamo) vanno nella sottocartella statica.
E questo è tutto ciò che serve per creare un'app Web di base con Bottle. Una volta definito correttamente il livello dati, è abbastanza semplice.
Aggiungi test con pytest
Ora rendiamo questo progetto un po' più robusto aggiungendo alcuni test. Testare il DB ha richiesto un po' più di scavo nel framework pytest, ma ho finito per usare il decoratore pytest.fixture per configurare e demolire un database con alcuni tweet di prova.
Invece di chiamare l'API di Twitter, ho utilizzato alcuni dati statici forniti in tweets.json .E, invece di usare il DB live, in tips/db.py , controllo se pytest è il chiamante (sys.argv[0] ). In tal caso, utilizzo il DB di prova. Probabilmente lo rifattorizzerò, perché Bottle supporta il lavoro con i file di configurazione.
La parte hashtag è stata più facile da testare (test_get_hashtag_counter ) perché potrei semplicemente aggiungere alcuni hashtag a una stringa multilinea. Nessun dispositivo necessario.
La qualità del codice è importante - Better Code Hub
Better Code Hub ti guida nella scrittura, beh, codice migliore. Prima di scrivere i test il progetto ha ottenuto un punteggio di 7:
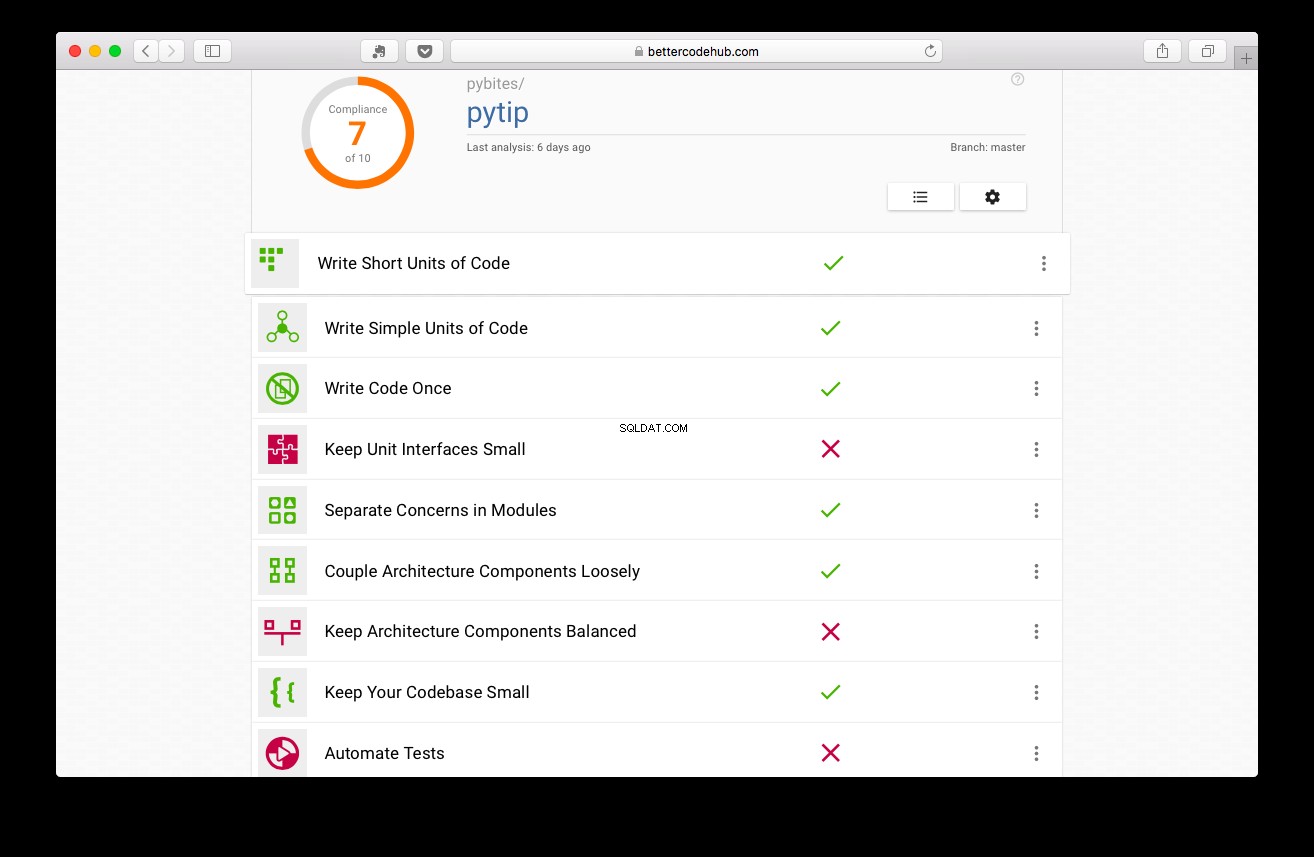
Non male, ma possiamo fare di meglio:
-
L'ho portato a un 9 rendendo il codice più modulare, eliminando la logica del DB da app.py (app Web), inserendola nella cartella/pacchetto suggerimenti (refactoring 1 e 2)
-
Quindi, con i test in atto, il progetto ha ottenuto un punteggio di 10:
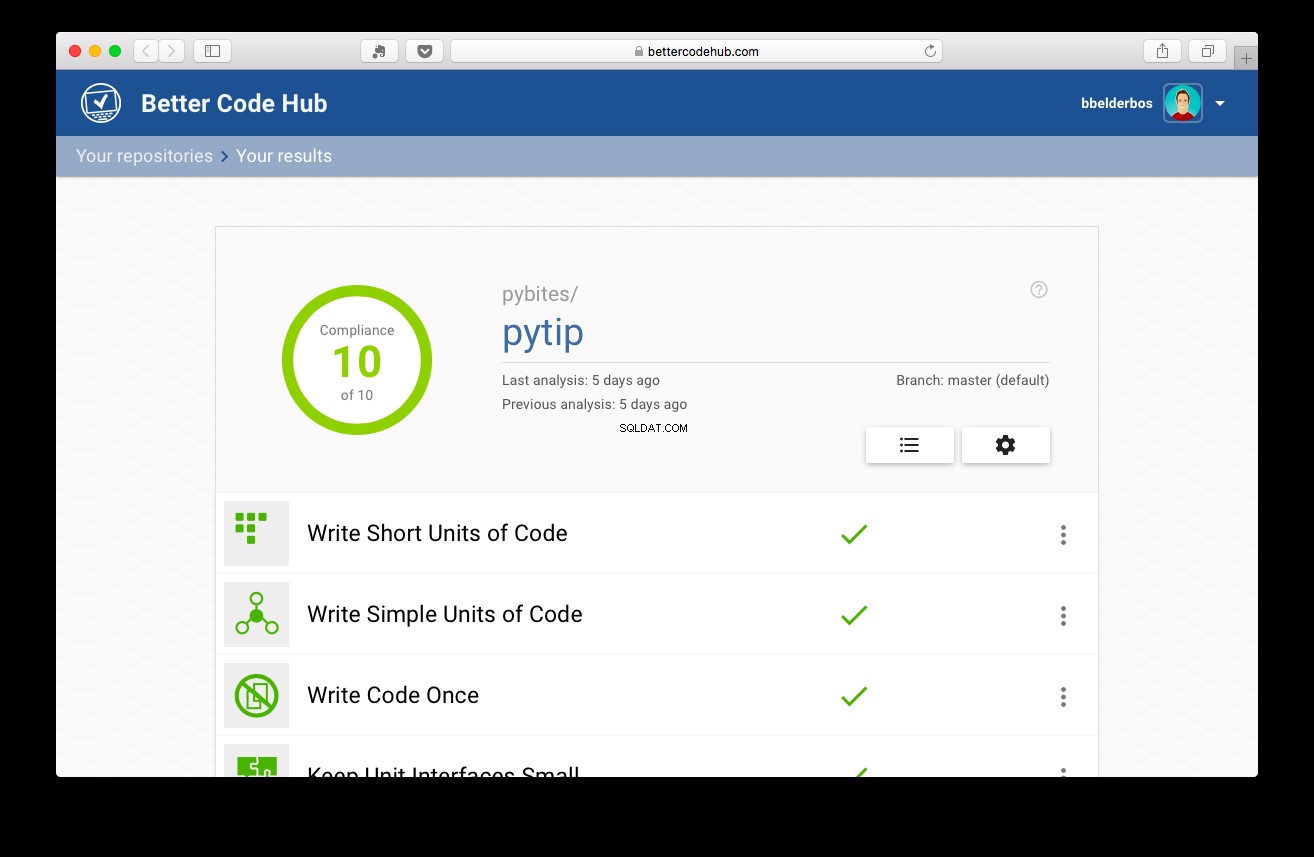
Conclusione e apprendimento
La nostra Sfida del codice n. 40 ha offerto alcune buone pratiche:
- Ho creato un'app utile che può essere espansa (voglio aggiungere un'API).
- Ho usato alcuni moduli interessanti che vale la pena esplorare:Tweepy, SQLAlchemy e Bottle.
- Ho imparato un po' più di pytest perché avevo bisogno di fixture per testare l'interazione con il DB.
- Soprattutto, dovendo rendere testabile il codice, l'app è diventata più modulare che ne ha facilitato la manutenzione. Better Code Hub è stato di grande aiuto in questo processo.
- Ho distribuito l'app su Heroku utilizzando la nostra guida passo passo.
Ti sfidiamo
Il modo migliore per imparare e migliorare le tue abilità di programmazione è esercitarsi. In PyBites abbiamo consolidato questo concetto organizzando le sfide del codice Python. Dai un'occhiata alla nostra collezione in crescita, esegui il fork del repository e inizia a programmare!
Facci sapere se costruisci qualcosa di interessante facendo una Pull Request del tuo lavoro. Abbiamo visto persone davvero impegnarsi in queste sfide, e anche noi.
Buona codifica!