Nella parte 1 di questa serie, hai utilizzato Flask e Connexion per creare un'API REST che fornisce operazioni CRUD a una semplice struttura in memoria chiamata PEOPLE . Questo ha funzionato per dimostrare come il modulo Connexion ti aiuta a creare una bella API REST insieme alla documentazione interattiva.
Come alcuni hanno notato nei commenti per la Parte 1, le PEOPLE la struttura viene reinizializzata ogni volta che si riavvia l'applicazione. In questo articolo imparerai come memorizzare le PEOPLE struttura e le azioni fornite dall'API a un database che utilizza SQLAlchemy e Marshmallow.
SQLAlchemy fornisce un Object Relational Model (ORM), che archivia gli oggetti Python in una rappresentazione del database dei dati dell'oggetto. Ciò può aiutarti a continuare a pensare in modo Pythonico e a non preoccuparti di come i dati dell'oggetto verranno rappresentati in un database.
Marshmallow fornisce funzionalità per serializzare e deserializzare gli oggetti Python mentre fluiscono da e verso la nostra API REST basata su JSON. Marshmallow converte le istanze della classe Python in oggetti che possono essere convertiti in JSON.
Puoi trovare il codice Python per questo articolo qui.
Bonus gratuito: Fai clic qui per scaricare una copia della guida "Esempi di API REST" e ottenere un'introduzione pratica ai principi di Python + API REST con esempi utilizzabili.
A chi è rivolto questo articolo
Se ti è piaciuta la parte 1 di questa serie, questo articolo espande ulteriormente la tua cintura degli attrezzi. Utilizzerai SQLAlchemy per accedere a un database in un modo più Pythonico rispetto al semplice SQL. Utilizzerai inoltre Marshmallow per serializzare e deserializzare i dati gestiti dall'API REST. Per fare ciò, utilizzerai le funzionalità di base della programmazione orientata agli oggetti disponibili in Python.
Utilizzerai anche SQLAlchemy per creare un database e interagire con esso. Ciò è necessario per far funzionare l'API REST con PEOPLE dati utilizzati nella Parte 1.
L'applicazione Web presentata nella Parte 1 avrà i suoi file HTML e JavaScript modificati in modi minori per supportare anche le modifiche. Puoi rivedere la versione finale del codice della Parte 1 qui.
Ulteriori dipendenze
Prima di iniziare a creare questa nuova funzionalità, dovrai aggiornare virtualenv che hai creato per eseguire il codice della Parte 1 o crearne uno nuovo per questo progetto. Il modo più semplice per farlo dopo aver attivato virtualenv è eseguire questo comando:
$ pip install Flask-SQLAlchemy flask-marshmallow marshmallow-sqlalchemy marshmallow
Questo aggiunge più funzionalità al tuo virtualenv:
-
Flask-SQLAlchemyaggiunge SQLAlchemy, insieme ad alcuni collegamenti a Flask, consentendo ai programmi di accedere ai database. -
flask-marshmallowaggiunge le parti Flask di Marshmallow, che consente ai programmi di convertire oggetti Python in e da strutture serializzabili. -
marshmallow-sqlalchemyaggiunge alcuni hook Marshmallow in SQLAlchemy per consentire ai programmi di serializzare e deserializzare oggetti Python generati da SQLAlchemy. -
marshmallowaggiunge la maggior parte delle funzionalità Marshmallow.
Dati delle persone
Come accennato in precedenza, il PEOPLE la struttura dei dati nell'articolo precedente è un dizionario Python in memoria. In quel dizionario, hai usato il cognome della persona come chiave di ricerca. La struttura dei dati era simile a questa nel codice:
# Data to serve with our API
PEOPLE = {
"Farrell": {
"fname": "Doug",
"lname": "Farrell",
"timestamp": get_timestamp()
},
"Brockman": {
"fname": "Kent",
"lname": "Brockman",
"timestamp": get_timestamp()
},
"Easter": {
"fname": "Bunny",
"lname": "Easter",
"timestamp": get_timestamp()
}
}
Le modifiche che apporterai al programma sposteranno tutti i dati in una tabella del database. Ciò significa che i dati verranno salvati sul tuo disco e esisteranno tra le esecuzioni di server.py programma.
Poiché il cognome era la chiave del dizionario, il codice limitava la modifica del cognome di una persona:solo il nome poteva essere modificato. Inoltre, il passaggio a un database ti consentirà di modificare il cognome poiché non verrà più utilizzato come chiave di ricerca per una persona.
Concettualmente, una tabella di database può essere considerata come un array bidimensionale in cui le righe sono record e le colonne sono campi in quei record.
Le tabelle di database in genere hanno un valore intero con incremento automatico come chiave di ricerca per le righe. Questa è chiamata chiave primaria. Ogni record nella tabella avrà una chiave primaria il cui valore è univoco nell'intera tabella. Avere una chiave primaria indipendente dai dati memorizzati nella tabella ti libera di modificare qualsiasi altro campo nella riga.
Nota:
La chiave primaria a incremento automatico significa che il database si occupa di:
- Incremento del campo chiave primaria più grande esistente ogni volta che viene inserito un nuovo record nella tabella
- Utilizzando quel valore come chiave primaria per i dati appena inseriti
Ciò garantisce una chiave primaria univoca man mano che la tabella cresce.
Seguirai una convenzione del database di nominare la tabella come singolare, quindi la tabella sarà chiamata person . Tradurre le nostre PEOPLE struttura sopra in una tabella di database denominata person ti dà questo:
| ID_persona | nome | fname | marcatura temporale |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Pasqua | Coniglietto | 2018-08-08 21:16:01.886834 |
Ogni colonna della tabella ha un nome di campo come segue:
person_id: campo chiave primaria per ogni personalname: cognome della personafname: nome della personatimestamp: timestamp associato alle azioni di inserimento/aggiornamento
Interazione con il database
Utilizzerai SQLite come motore di database per archiviare le PEOPLE dati. SQLite è il database più diffuso al mondo e viene fornito con Python gratuitamente. È veloce, esegue tutto il suo lavoro utilizzando i file ed è adatto a moltissimi progetti. È un RDBMS (Relational Database Management System) completo che include SQL, il linguaggio di molti sistemi di database.
Per il momento, immagina la person la tabella esiste già in un database SQLite. Se hai avuto esperienza con RDBMS, probabilmente conosci SQL, il linguaggio di query strutturato utilizzato dalla maggior parte degli RDBMS per interagire con il database.
A differenza dei linguaggi di programmazione come Python, SQL non definisce come per ottenere i dati:descrive cosa i dati sono desiderati, lasciando il come fino al motore di database.
Una query SQL che ottiene tutti i dati nella nostra person la tabella, ordinata per cognome, avrebbe questo aspetto:
SELECT * FROM person ORDER BY 'lname';
Questa query dice al motore di database di ottenere tutti i campi dalla tabella person e di ordinarli nell'ordine crescente predefinito utilizzando lname campo.
Se dovessi eseguire questa query su un database SQLite contenente la person tabella, i risultati sarebbero un insieme di record contenenti tutte le righe della tabella, con ogni riga contenente i dati di tutti i campi che compongono una riga. Di seguito è riportato un esempio che utilizza lo strumento a riga di comando SQLite che esegue la query precedente sulla person tabella del database:
sqlite> SELECT * FROM person ORDER BY lname;
2|Brockman|Kent|2018-08-08 21:16:01.888444
3|Easter|Bunny|2018-08-08 21:16:01.889060
1|Farrell|Doug|2018-08-08 21:16:01.886834
L'output sopra è un elenco di tutte le righe nella person tabella del database con caratteri pipe ('|') che separa i campi nella riga, a scopo di visualizzazione da SQLite.
Python è completamente in grado di interfacciarsi con molti motori di database ed eseguire la query SQL sopra. I risultati molto probabilmente sarebbero un elenco di tuple. L'elenco esterno contiene tutti i record nella person tavolo. Ogni singola tupla interna conterrebbe tutti i dati che rappresentano ogni campo definito per una riga di tabella.
Ottenere i dati in questo modo non è molto Pythonic. L'elenco dei record va bene, ma ogni singolo record è solo una tupla di dati. Spetta al programma conoscere l'indice di ogni campo per recuperare un campo particolare. Il codice Python seguente usa SQLite per dimostrare come eseguire la query precedente e visualizzare i dati:
1import sqlite3
2
3conn = sqlite3.connect('people.db')
4cur = conn.cursor()
5cur.execute('SELECT * FROM person ORDER BY lname')
6people = cur.fetchall()
7for person in people:
8 print(f'{person[2]} {person[1]}')
Il programma sopra fa quanto segue:
-
Riga 1 importa
sqlite3modulo. -
Riga 3 crea una connessione al file di database.
-
Riga 4 crea un cursore dalla connessione.
-
Riga 5 usa il cursore per eseguire un
SQLquery espressa come stringa. -
Riga 6 ottiene tutti i record restituiti da
SQLinterroga e li assegna allepeoplevariabile. -
Linea 7 e 8 scorrere le
peopleelenca la variabile e stampa il nome e il cognome di ogni persona.
Le people variabile da Riga 6 sopra sarebbe simile a questo in Python:
people = [
(2, 'Brockman', 'Kent', '2018-08-08 21:16:01.888444'),
(3, 'Easter', 'Bunny', '2018-08-08 21:16:01.889060'),
(1, 'Farrell', 'Doug', '2018-08-08 21:16:01.886834')
]
L'output del programma sopra è simile al seguente:
Kent Brockman
Bunny Easter
Doug Farrell
Nel programma sopra, devi sapere che il nome di una persona è all'indice 2 e il cognome di una persona è nell'indice 1 . Peggio ancora, la struttura interna di person deve anche essere noto ogni volta che si passa la variabile di iterazione person come parametro per una funzione o metodo.
Sarebbe molto meglio se quello che hai ricevuto per person era un oggetto Python, dove ciascuno dei campi è un attributo dell'oggetto. Questa è una delle cose che fa SQLAlchemy.
Tavolini Bobby
Nel programma sopra, l'istruzione SQL è una semplice stringa passata direttamente al database per l'esecuzione. In questo caso, non è un problema perché l'SQL è una stringa letterale completamente sotto il controllo del programma. Tuttavia, il caso d'uso per l'API REST prenderà l'input dell'utente dall'applicazione Web e lo utilizzerà per creare query SQL. Questo può aprire la tua applicazione per attaccare.
Ricorderai dalla Parte 1 che l'API REST per ottenere una singola person dal PEOPLE i dati erano così:
GET /api/people/{lname}
Ciò significa che la tua API si aspetta una variabile, lname , nel percorso dell'endpoint URL, che utilizza per trovare una singola person . La modifica del codice Python SQLite dall'alto per farlo assomiglierebbe a questo:
1lname = 'Farrell'
2cur.execute('SELECT * FROM person WHERE lname = \'{}\''.format(lname))
Il frammento di codice precedente esegue le seguenti operazioni:
-
Riga 1 imposta il
lnamevariabile in'Farrell'. Questo proverrebbe dal percorso dell'endpoint dell'URL dell'API REST. -
Riga 2 usa la formattazione della stringa Python per creare una stringa SQL ed eseguirla.
Per semplificare le cose, il codice sopra imposta lname variabile a una costante, ma in realtà proverrebbe dal percorso dell'endpoint dell'URL dell'API e potrebbe essere qualsiasi cosa fornita dall'utente. L'SQL generato dalla formattazione della stringa è simile a questo:
SELECT * FROM person WHERE lname = 'Farrell'
Quando questo SQL viene eseguito dal database, ricerca la person tabella per un record in cui il cognome è uguale a 'Farrell' . Questo è ciò che si intende, ma qualsiasi programma che accetta l'input dell'utente è aperto anche agli utenti malintenzionati. Nel programma sopra, dove lname variabile è impostata dall'input fornito dall'utente, questo apre il tuo programma a quello che viene chiamato un attacco SQL injection. Questo è ciò che è affettuosamente conosciuto come Little Bobby Tables:
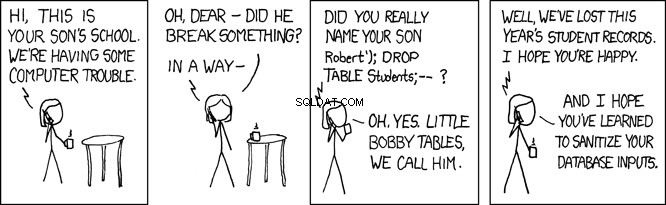
Ad esempio, immagina un utente malintenzionato che abbia chiamato la tua API REST in questo modo:
GET /api/people/Farrell');DROP TABLE person;
La richiesta API REST sopra imposta lname variabile in 'Farrell');DROP TABLE person;' , che nel codice sopra genererebbe questa istruzione SQL:
SELECT * FROM person WHERE lname = 'Farrell');DROP TABLE person;
L'istruzione SQL di cui sopra è valida e, quando eseguita dal database, troverà un record in cui lname corrisponde a 'Farrell' . Quindi, troverà il carattere delimitatore dell'istruzione SQL ; e andrà avanti e farà cadere l'intero tavolo. Questo essenzialmente rovinerebbe la tua applicazione.
Puoi proteggere il tuo programma sanificando tutti i dati che ricevi dagli utenti della tua applicazione. Disinfettare i dati in questo contesto significa fare in modo che il tuo programma esamini i dati forniti dall'utente e assicurati che non contengano nulla di pericoloso per il programma. Questo può essere difficile da fare correttamente e dovrebbe essere fatto ovunque i dati dell'utente interagiscano con il database.
C'è un altro modo molto più semplice:usare SQLAlchemy. Sanificherà i dati utente per te prima di creare istruzioni SQL. È un altro grande vantaggio e motivo per utilizzare SQLAlchemy quando si lavora con i database.
Modellazione dei dati con SQLAlchemy
SQLAlchemy è un grande progetto e fornisce molte funzionalità per lavorare con i database usando Python. Una delle cose che fornisce è un ORM, o Object Relational Mapper, e questo è ciò che utilizzerai per creare e lavorare con la person tabella del database. Ciò ti consente di mappare una riga di campi dalla tabella del database a un oggetto Python.
La programmazione orientata agli oggetti consente di collegare i dati insieme al comportamento, le funzioni che operano su quei dati. Creando classi SQLAlchemy, puoi connettere i campi dalle righe della tabella del database al comportamento, consentendoti di interagire con i dati. Ecco la definizione della classe SQLAlchemy per i dati in person tabella del database:
class Person(db.Model):
__tablename__ = 'person'
person_id = db.Column(db.Integer,
primary_key=True)
lname = db.Column(db.String)
fname = db.Column(db.String)
timestamp = db.Column(db.DateTime,
default=datetime.utcnow,
onupdate=datetime.utcnow)
La classe Person eredita da db.Model , a cui arriverai quando inizierai a creare il codice del programma. Per ora, significa che stai ereditando da una classe base chiamata Model , fornendo attributi e funzionalità comuni a tutte le classi da esso derivate.
Il resto delle definizioni sono attributi a livello di classe definiti come segue:
-
__tablename__ = 'person'collega la definizione della classe allapersontabella del database. -
person_id = db.Column(db.Integer, primary_key=True)crea una colonna del database contenente un numero intero che funge da chiave primaria per la tabella. Questo dice anche al database cheperson_idsarà un valore intero a incremento automatico. -
lname = db.Column(db.String)crea il campo del cognome, una colonna del database contenente un valore stringa. -
fname = db.Column(db.String)crea il campo del nome, una colonna del database contenente un valore stringa. -
timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)crea un campo timestamp, una colonna del database contenente un valore di data/ora. Ildefault=datetime.utcnowparametro imposta il valore predefinito del timestamp sull'attualeutcnowvalore quando viene creato un record. Ilonupdate=datetime.utcnowil parametro aggiorna il timestamp con l'attualeutcnowvalore quando il record viene aggiornato.
Nota:timestamp UTC
Ti starai chiedendo perché il timestamp nella classe sopra è predefinito ed è aggiornato da datetime.utcnow() metodo, che restituisce un UTC, o Coordinated Universal Time. Questo è un modo per standardizzare la fonte del tuo timestamp.
La sorgente, o tempo zero, è una linea che corre da nord a sud dal polo nord della Terra al polo sud attraverso il Regno Unito. Questo è il fuso orario zero da cui tutti gli altri fusi orari sono sfalsati. Usando questa come fonte di tempo zero, i tuoi timestamp sono offset da questo punto di riferimento standard.
Se si accede all'applicazione da fusi orari diversi, è possibile eseguire calcoli di data/ora. Tutto ciò di cui hai bisogno è un timestamp UTC e il fuso orario di destinazione.
Se dovessi utilizzare i fusi orari locali come origine del timestamp, non potresti eseguire calcoli di data/ora senza informazioni sui fusi orari locali scostati dall'ora zero. Senza le informazioni sull'origine del timestamp, non potresti eseguire alcun confronto di data/ora o matematica.
Lavorare con un timestamp basato su UTC è un buon standard da seguire. Ecco un sito di toolkit con cui lavorare e comprenderli meglio.
Dove stai andando con questa Person definizione di classe? L'obiettivo finale è essere in grado di eseguire una query utilizzando SQLAlchemy e recuperare un elenco di istanze della Person classe. Ad esempio, diamo un'occhiata alla precedente istruzione SQL:
SELECT * FROM people ORDER BY lname;
Mostra lo stesso piccolo programma di esempio dall'alto, ma ora usando SQLAlchemy:
1from models import Person
2
3people = Person.query.order_by(Person.lname).all()
4for person in people:
5 print(f'{person.fname} {person.lname}')
Ignorando la riga 1 per il momento, quello che vuoi è tutta la person record ordinati in ordine crescente per lname campo. Cosa ottieni dalle istruzioni SQLAlchemy Person.query.order_by(Person.lname).all() è un elenco di Person oggetti per tutti i record nella person tabella del database in questo ordine. Nel programma sopra, le people variabile contiene l'elenco di Person oggetti.
Il programma scorre sulle people variabile, prendendo ogni person a sua volta e stampando il nome e il cognome della persona dal database. Nota che il programma non deve utilizzare gli indici per ottenere il fname o lname valori:utilizza gli attributi definiti sulla Person oggetto.
L'uso di SQLAlchemy ti consente di pensare in termini di oggetti con comportamento piuttosto che in SQL grezzo . Ciò diventa ancora più vantaggioso quando le tabelle del database diventano più grandi e le interazioni più complesse.
Serializzare/Deserializzare dati modellati
Lavorare con i dati modellati SQLAlchemy all'interno dei tuoi programmi è molto conveniente. È particolarmente comodo nei programmi che manipolano i dati, magari facendo calcoli o usandoli per creare presentazioni sullo schermo. La tua applicazione è un'API REST che fornisce essenzialmente operazioni CRUD sui dati e, in quanto tale, non esegue molte manipolazioni dei dati.
L'API REST funziona con i dati JSON e qui puoi riscontrare un problema con il modello SQLAlchemy. Poiché i dati restituiti da SQLAlchemy sono istanze della classe Python, Connexion non può serializzare queste istanze della classe in dati formattati JSON. Ricorda dalla parte 1 che Connexion è lo strumento che hai utilizzato per progettare e configurare l'API REST utilizzando un file YAML e connettere i metodi Python ad esso.
In questo contesto, serializzare significa convertire oggetti Python, che possono contenere altri oggetti Python e tipi di dati complessi, in strutture di dati più semplici che possono essere analizzate in tipi di dati JSON, che sono elencati qui:
string: un tipo di stringanumber: numeri supportati da Python (interi, float, long)object: un oggetto JSON, che è più o meno equivalente a un dizionario Pythonarray: più o meno equivalente a una Python Listboolean: rappresentato in JSON cometrueofalse, ma in Python comeTrueoFalsenull: essenzialmente unNonein Python
Ad esempio, la tua Person la classe contiene un timestamp, che è un Python DateTime . Non esiste una definizione di data/ora in JSON, quindi il timestamp deve essere convertito in una stringa per poter esistere in una struttura JSON.
La tua Person class è abbastanza semplice, quindi ottenere gli attributi dei dati da esso e creare manualmente un dizionario da restituire dai nostri endpoint URL REST non sarebbe molto difficile. In un'applicazione più complessa con molti modelli SQLAlchemy più grandi, questo non sarebbe il caso. Una soluzione migliore è utilizzare un modulo chiamato Marshmallow per fare il lavoro per te.
Marshmallow ti aiuta a creare uno PersonSchema classe, che è come la Person di SQLAlchemy classe che abbiamo creato. Qui invece, invece di mappare le tabelle del database e i nomi dei campi alla classe e ai suoi attributi, il PersonSchema class definisce come gli attributi di una classe verranno convertiti in formati compatibili con JSON. Ecco la definizione della classe Marshmallow per i dati nella nostra person tabella:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
La classe PersonSchema eredita da ma.ModelSchema , a cui arriverai quando inizierai a creare il codice del programma. Per ora, questo significa PersonSchema sta ereditando da una classe base Marshmallow chiamata ModelSchema , fornendo attributi e funzionalità comuni a tutte le classi da esso derivate.
Il resto della definizione è la seguente:
-
class Metadefinisce una classe denominataMetaall'interno della tua classe IlModelSchemaclasse che ilPersonSchemala classe eredita da cerca questoMetainterno classe e lo usa per trovare il modello SQLAlchemyPersone ildb.session. Ecco come Marshmallow trova gli attributi nellaPersonclass e il tipo di quegli attributi in modo che sappia come serializzarli/deserializzarli. -
modelindica alla classe quale modello SQLAlchemy utilizzare per serializzare/deserializzare i dati da e verso. -
db.sessionindica alla classe quale sessione di database utilizzare per esaminare e determinare i tipi di dati degli attributi.
Dove stai andando con questa definizione di classe? Vuoi essere in grado di serializzare un'istanza di una Person classe in dati JSON e per deserializzare i dati JSON e creare una Person istanze di classe da esso.
Crea il database inizializzato
SQLAlchemy gestisce molte delle interazioni specifiche per determinati database e ti consente di concentrarti sui modelli di dati e su come usarli.
Ora che creerai effettivamente un database, come accennato in precedenza, utilizzerai SQLite. Lo stai facendo per un paio di motivi. Viene fornito con Python e non deve essere installato come modulo separato. Salva tutte le informazioni del database in un unico file ed è quindi facile da configurare e utilizzare.
L'installazione di un server di database separato come MySQL o PostgreSQL funzionerebbe correttamente, ma richiederebbe l'installazione di tali sistemi e la loro messa in funzione, il che va oltre lo scopo di questo articolo.
Poiché SQLAlchemy gestisce il database, in molti modi non importa quale sia il database sottostante.
Creerai un nuovo programma di utilità chiamato build_database.py per creare e inizializzare SQLite people.db file di database contenente la tua person tabella del database. Lungo la strada, creerai due moduli Python, config.py e models.py , che verrà utilizzato da build_database.py e il server.py modificato dalla parte 1.
Ecco dove puoi trovare il codice sorgente per i moduli che stai per creare, che sono presentati qui:
-
config.pyottiene i moduli necessari importati nel programma e configurati. Ciò include Flask, Connexion, SQLAlchemy e Marshmallow. Perché sarà utilizzato da entrambibuild_database.pyeserver.py, alcune parti della configurazione si applicheranno solo aserver.pyapplicazione. -
models.pyè il modulo in cui creerai laPersonSQLAlchemy ePersonSchemaDefinizioni di classe Marshmallow descritte sopra. Questo modulo dipende daconfig.pyper alcuni degli oggetti lì creati e configurati.
Modulo di configurazione
Il config.py modulo, come suggerisce il nome, è dove vengono create e inizializzate tutte le informazioni di configurazione. Useremo questo modulo sia per il nostro build_database.py file di programma e il prossimo aggiornamento server.py file dall'articolo Parte 1. Ciò significa che configureremo Flask, Connexion, SQLAlchemy e Marshmallow qui.
Anche se build_database.py il programma non utilizza Flask, Connexion o Marshmallow, utilizza SQLAlchemy per creare la nostra connessione al database SQLite. Ecco il codice per config.py modulo:
1import os
2import connexion
3from flask_sqlalchemy import SQLAlchemy
4from flask_marshmallow import Marshmallow
5
6basedir = os.path.abspath(os.path.dirname(__file__))
7
8# Create the Connexion application instance
9connex_app = connexion.App(__name__, specification_dir=basedir)
10
11# Get the underlying Flask app instance
12app = connex_app.app
13
14# Configure the SQLAlchemy part of the app instance
15app.config['SQLALCHEMY_ECHO'] = True
16app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////' + os.path.join(basedir, 'people.db')
17app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
18
19# Create the SQLAlchemy db instance
20db = SQLAlchemy(app)
21
22# Initialize Marshmallow
23ma = Marshmallow(app)
Ecco cosa sta facendo il codice sopra:
-
Righe 2 – 4 importa Connexion come hai fatto in
server.pyprogramma dalla Parte 1. Importa ancheSQLAlchemydallaflask_sqlalchemymodulo. Questo dà al tuo programma l'accesso al database. Infine, importaMarshmallowdalflask_marshamllowmodulo. -
Riga 6 crea la variabile
basedirche punta alla directory in cui è in esecuzione il programma. -
Riga 9 usa il
basedirvariabile per creare l'istanza dell'app Connexion e assegnarle il percorso aswagger.ymlfile. -
Riga 12 crea una variabile
app, che è l'istanza Flask inizializzata da Connexion. -
Righe 15 utilizza l'
appvariabile per configurare i valori utilizzati da SQLAlchemy. Per prima cosa impostaSQLALCHEMY_ECHOaTrue. Ciò fa sì che SQLAlchemy echeggi le istruzioni SQL che esegue sulla console. Questo è molto utile per eseguire il debug dei problemi durante la creazione di programmi di database. Impostalo suFalseper ambienti di produzione. -
Riga 16 imposta
SQLALCHEMY_DATABASE_URIasqlite:////' + os.path.join(basedir, 'people.db'). Questo dice a SQLAlchemy di usare SQLite come database e un file chiamatopeople.dbnella directory corrente come file di database. Motori di database diversi, come MySQL e PostgreSQL, avrannoSQLALCHEMY_DATABASE_URIdiversi stringhe per configurarli. -
Riga 17 imposta
SQLALCHEMY_TRACK_MODIFICATIONSaFalse, disattivando il sistema di eventi SQLAlchemy, che è attivo per impostazione predefinita. Il sistema di eventi genera eventi utili nei programmi basati su eventi, ma aggiunge un sovraccarico significativo. Poiché non stai creando un programma basato su eventi, disattiva questa funzione. -
Riga 19 crea il
dbvariabile chiamandoSQLAlchemy(app). Questo inizializza SQLAlchemy passando l'appinformazioni di configurazione appena impostate. Ildbvariabile è ciò che viene importato inbuild_database.pyprogramma per dargli accesso a SQLAlchemy e al database. Servirà allo stesso scopo nelserver.pyprogramma epeople.pymodulo. -
Riga 23 crea il
mavariabile chiamandoMarshmallow(app). Questo inizializza Marshmallow e gli consente di esaminare i componenti SQLAlchemy collegati all'app. Questo è il motivo per cui Marshmallow viene inizializzato dopo SQLAlchemy.
Modulo Modelli
Il models.py il modulo viene creato per fornire la Person e PersonSchema classi esattamente come descritto nelle sezioni precedenti sulla modellazione e serializzazione dei dati. Ecco il codice per quel modulo:
1from datetime import datetime
2from config import db, ma
3
4class Person(db.Model):
5 __tablename__ = 'person'
6 person_id = db.Column(db.Integer, primary_key=True)
7 lname = db.Column(db.String(32), index=True)
8 fname = db.Column(db.String(32))
9 timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
10
11class PersonSchema(ma.ModelSchema):
12 class Meta:
13 model = Person
14 sqla_session = db.session
Ecco cosa sta facendo il codice sopra:
-
Riga 1 importa il
datetimeoggetto dadatetimemodulo fornito con Python. Questo ti dà un modo per creare un timestamp nellaPersonclasse. -
Riga 2 importa il
dbemavariabili di istanza definite inconfig.pymodulo. Ciò fornisce al modulo l'accesso agli attributi e ai metodi di SQLAlchemy allegati adbvariabile e gli attributi e i metodi Marshmallow allegati amavariabile. -
Righe 4 – 9 definire la
Personclass come discusso nella sezione sulla modellazione dei dati sopra, ma ora sai dove si trova ildb.Modelda cui la classe eredita origins. Questo dà laPersonle caratteristiche di classe SQLAlchemy, come una connessione al database e l'accesso alle sue tabelle. -
Righe 11 – 14 definire lo
PersonSchemaclass as was discussed in the data serialzation section above. This class inherits fromma.ModelSchemaand gives thePersonSchemaclass Marshmallow features, like introspecting thePersonclass to help serialize/deserialize instances of that class.
Creating the Database
You’ve seen how database tables can be mapped to SQLAlchemy classes. Now use what you’ve learned to create the database and populate it with data. You’re going to build a small utility program to create and build the database with the People data. Here’s the build_database.py program:
1import os
2from config import db
3from models import Person
4
5# Data to initialize database with
6PEOPLE = [
7 {'fname': 'Doug', 'lname': 'Farrell'},
8 {'fname': 'Kent', 'lname': 'Brockman'},
9 {'fname': 'Bunny','lname': 'Easter'}
10]
11
12# Delete database file if it exists currently
13if os.path.exists('people.db'):
14 os.remove('people.db')
15
16# Create the database
17db.create_all()
18
19# Iterate over the PEOPLE structure and populate the database
20for person in PEOPLE:
21 p = Person(lname=person['lname'], fname=person['fname'])
22 db.session.add(p)
23
24db.session.commit()
Here’s what the above code is doing:
-
Line 2 imports the
dbinstance from theconfig.pymodule. -
Line 3 imports the
Personclass definition from themodels.pymodule. -
Lines 6 – 10 create the
PEOPLEdata structure, which is a list of dictionaries containing your data. The structure has been condensed to save presentation space. -
Lines 13 &14 perform some simple housekeeping to delete the
people.dbfile, if it exists. This file is where the SQLite database is maintained. If you ever have to re-initialize the database to get a clean start, this makes sure you’re starting from scratch when you build the database. -
Line 17 creates the database with the
db.create_all()call. This creates the database by using thedbinstance imported from theconfigmodulo. Thedbinstance is our connection to the database. -
Lines 20 – 22 iterate over the
PEOPLElist and use the dictionaries within to instantiate aPersonclass. After it is instantiated, you call thedb.session.add(p)funzione. This uses the database connection instancedbto access thesessionoggetto. The session is what manages the database actions, which are recorded in the session. In this case, you are executing theadd(p)method to add the newPersoninstance to thesessionoggetto. -
Line 24 calls
db.session.commit()to actually save all the person objects created to the database.
Nota: At Line 22, no data has been added to the database. Everything is being saved within the session oggetto. Only when you execute the db.session.commit() call at Line 24 does the session interact with the database and commit the actions to it.
In SQLAlchemy, the session is an important object. It acts as the conduit between the database and the SQLAlchemy Python objects created in a program. The session helps maintain the consistency between data in the program and the same data as it exists in the database. It saves all database actions and will update the underlying database accordingly by both explicit and implicit actions taken by the program.
Now you’re ready to run the build_database.py program to create and initialize the new database. You do so with the following command, with your Python virtual environment active:
python build_database.py
When the program runs, it will print SQLAlchemy log messages to the console. These are the result of setting SQLALCHEMY_ECHO to True in the config.py file. Much of what’s being logged by SQLAlchemy is the SQL commands it’s generating to create and build the people.db SQLite database file. Here’s an example of what’s printed out when the program is run:
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("person")
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine
CREATE TABLE person (
person_id INTEGER NOT NULL,
lname VARCHAR,
fname VARCHAR,
timestamp DATETIME,
PRIMARY KEY (person_id)
)
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,975 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,980 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine ('Farrell', 'Doug', '2018-09-12 02:20:29.983143')
2018-09-11 22:20:29,984 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Brockman', 'Kent', '2018-09-12 02:20:29.984821')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Easter', 'Bunny', '2018-09-12 02:20:29.985462')
2018-09-11 22:20:29,986 INFO sqlalchemy.engine.base.Engine COMMIT
Using the Database
Once the database has been created, you can modify the existing code from Part 1 to make use of it. All of the modifications necessary are due to creating the person_id primary key value in our database as the unique identifier rather than the lname value.
Update the REST API
None of the changes are very dramatic, and you’ll start by re-defining the REST API. The list below shows the API definition from Part 1 but is updated to use the person_id variable in the URL path:
| Action | HTTP Verb | URL Path | Descrizione |
|---|---|---|---|
| Create | POST | /api/people | Defines a unique URL to create a new person |
| Read | GET | /api/people | Defines a unique URL to read a collection of people |
| Read | GET | /api/people/{person_id} | Defines a unique URL to read a particular person by person_id |
| Update | PUT | /api/people/{person_id} | Defines a unique URL to update an existing person by person_id |
| Delete | DELETE | /api/orders/{person_id} | Defines a unique URL to delete an existing person by person_id |
Where the URL definitions required an lname value, they now require the person_id (primary key) for the person record in the people tavolo. This allows you to remove the code in the previous app that artificially restricted users from editing a person’s last name.
In order for you to implement these changes, the swagger.yml file from Part 1 will have to be edited. For the most part, any lname parameter value will be changed to person_id , and person_id will be added to the POST and PUT responses. You can check out the updated swagger.yml file.
Update the REST API Handlers
With the swagger.yml file updated to support the use of the person_id identifier, you’ll also need to update the handlers in the people.py file to support these changes. In the same way that the swagger.yml file was updated, you need to change the people.py file to use the person_id value rather than lname .
Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people :
1from flask import (
2 make_response,
3 abort,
4)
5from config import db
6from models import (
7 Person,
8 PersonSchema,
9)
10
11def read_all():
12 """
13 This function responds to a request for /api/people
14 with the complete lists of people
15
16 :return: json string of list of people
17 """
18 # Create the list of people from our data
19 people = Person.query \
20 .order_by(Person.lname) \
21 .all()
22
23 # Serialize the data for the response
24 person_schema = PersonSchema(many=True)
25 return person_schema.dump(people).data
Here’s what the above code is doing:
-
Lines 1 – 9 import some Flask modules to create the REST API responses, as well as importing the
dbinstance from theconfig.pymodulo. In addition, it imports the SQLAlchemyPersonand MarshmallowPersonSchemaclasses to access thepersondatabase table and serialize the results. -
Line 11 starts the definition of
read_all()that responds to the REST API URL endpointGET /api/peopleand returns all the records in thepersondatabase table sorted in ascending order by last name. -
Lines 19 – 22 tell SQLAlchemy to query the
persondatabase table for all the records, sort them in ascending order (the default sorting order), and return a list ofPersonPython objects as the variablepeople. -
Line 24 is where the Marshmallow
PersonSchemaclass definition becomes valuable. You create an instance of thePersonSchema, passing it the parametermany=True. This tellsPersonSchemato expect an interable to serialize, which is what thepeoplevariable is. -
Line 25 uses the
PersonSchemainstance variable (person_schema), calling itsdump()method with thepeoplelist. The result is an object having adataattribute, an object containing apeoplelist that can be converted to JSON. This is returned and converted by Connexion to JSON as the response to the REST API call.
Nota: The people list variable created on Line 24 above can’t be returned directly because Connexion won’t know how to convert the timestamp field into JSON. Returning the list of people without processing it with Marshmallow results in a long error traceback and finally this Exception:
TypeError: Object of type Person is not JSON serializable
Here’s another part of the person.py module that makes a request for a single person from the person database. Here, read_one(person_id) function receives a person_id from the REST URL path, indicating the user is looking for a specific person. Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people/{person_id} :
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: ID of person to find
7 :return: person matching ID
8 """
9 # Get the person requested
10 person = Person.query \
11 .filter(Person.person_id == person_id) \
12 .one_or_none()
13
14 # Did we find a person?
15 if person is not None:
16
17 # Serialize the data for the response
18 person_schema = PersonSchema()
19 return person_schema.dump(person).data
20
21 # Otherwise, nope, didn't find that person
22 else:
23 abort(404, 'Person not found for Id: {person_id}'.format(person_id=person_id))
Here’s what the above code is doing:
-
Lines 10 – 12 use the
person_idparameter in a SQLAlchemy query using thefiltermethod of the query object to search for a person with aperson_idattribute matching the passed-inperson_id. Rather than using theall()query method, use theone_or_none()method to get one person, or returnNoneif no match is found. -
Line 15 determines whether a
personwas found or not. -
Line 17 shows that, if
personwas notNone(a matchingpersonwas found), then serializing the data is a little different. You don’t pass themany=Trueparameter to the creation of thePersonSchema()esempio. Instead, you passmany=Falsebecause only a single object is passed in to serialize. -
Line 18 is where the
dumpmethod ofperson_schemais called, and thedataattribute of the resulting object is returned. -
Line 23 shows that, if
personwasNone(a matching person wasn’t found), then the Flaskabort()method is called to return an error.
Another modification to person.py is creating a new person in the database. This gives you an opportunity to use the Marshmallow PersonSchema to deserialize a JSON structure sent with the HTTP request to create a SQLAlchemy Person oggetto. Here’s part of the updated person.py module showing the handler for the REST URL endpoint POST /api/people :
1def create(person):
2 """
3 This function creates a new person in the people structure
4 based on the passed-in person data
5
6 :param person: person to create in people structure
7 :return: 201 on success, 406 on person exists
8 """
9 fname = person.get('fname')
10 lname = person.get('lname')
11
12 existing_person = Person.query \
13 .filter(Person.fname == fname) \
14 .filter(Person.lname == lname) \
15 .one_or_none()
16
17 # Can we insert this person?
18 if existing_person is None:
19
20 # Create a person instance using the schema and the passed-in person
21 schema = PersonSchema()
22 new_person = schema.load(person, session=db.session).data
23
24 # Add the person to the database
25 db.session.add(new_person)
26 db.session.commit()
27
28 # Serialize and return the newly created person in the response
29 return schema.dump(new_person).data, 201
30
31 # Otherwise, nope, person exists already
32 else:
33 abort(409, f'Person {fname} {lname} exists already')
Here’s what the above code is doing:
-
Line 9 &10 set the
fnameandlnamevariables based on thePersondata structure sent as thePOSTbody of the HTTP request. -
Lines 12 – 15 use the SQLAlchemy
Personclass to query the database for the existence of a person with the samefnameandlnameas the passed-inperson. -
Line 18 addresses whether
existing_personisNone. (existing_personwas not found.) -
Line 21 creates a
PersonSchema()instance calledschema. -
Line 22 uses the
schemavariable to load the data contained in thepersonparameter variable and create a new SQLAlchemyPersoninstance variable callednew_person. -
Line 25 adds the
new_personinstance to thedb.session. -
Line 26 commits the
new_personinstance to the database, which also assigns it a new primary key value (based on the auto-incrementing integer) and a UTC-based timestamp. -
Line 33 shows that, if
existing_personis notNone(a matching person was found), then the Flaskabort()method is called to return an error.
Update the Swagger UI
With the above changes in place, your REST API is now functional. The changes you’ve made are also reflected in an updated swagger UI interface and can be interacted with in the same manner. Below is a screenshot of the updated swagger UI opened to the GET /people/{person_id} section. This section of the UI gets a single person from the database and looks like this:
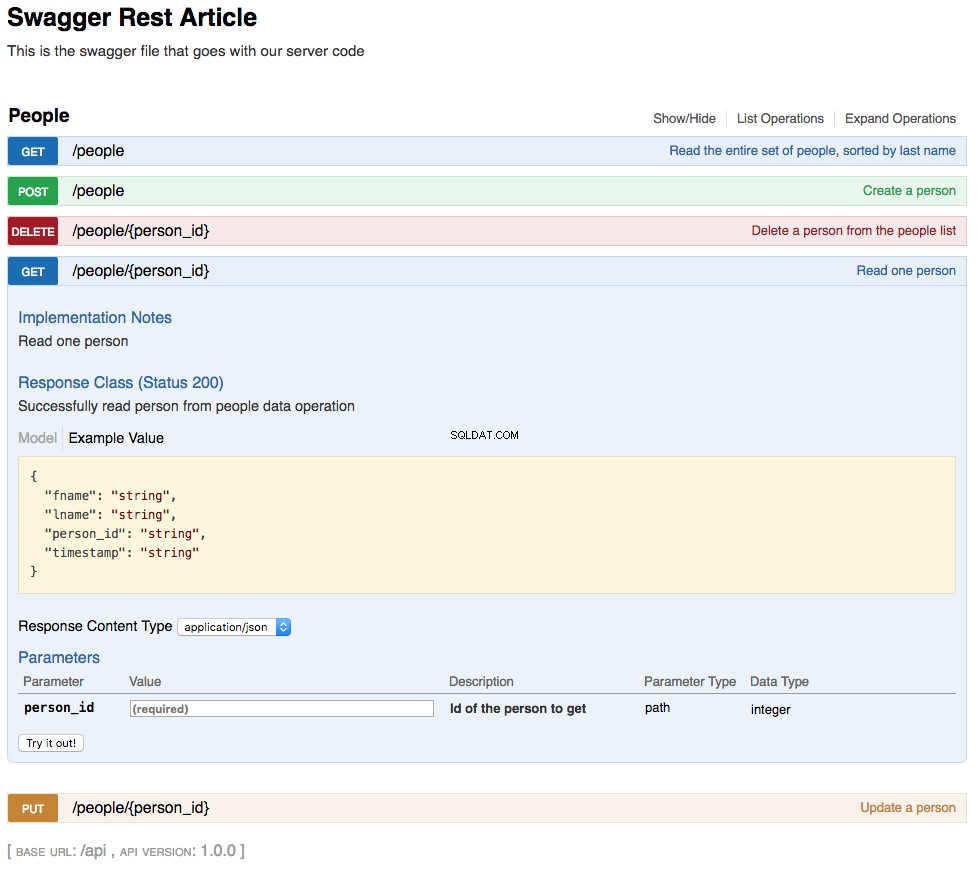
As shown in the above screenshot, the path parameter lname has been replaced by person_id , which is the primary key for a person in the REST API. The changes to the UI are a combined result of changing the swagger.yml file and the code changes made to support that.
Update the Web Application
The REST API is running, and CRUD operations are being persisted to the database. So that it is possible to view the demonstration web application, the JavaScript code has to be updated.
The updates are again related to using person_id instead of lname as the primary key for person data. In addition, the person_id is attached to the rows of the display table as HTML data attributes named data-person-id , so the value can be retrieved and used by the JavaScript code.
This article focused on the database and making your REST API use it, which is why there’s just a link to the updated JavaScript source and not much discussion of what it does.
Example Code
All of the example code for this article is available here. There’s one version of the code containing all the files, including the build_database.py utility program and the server.py modified example program from Part 1.
Conclusione
Congratulations, you’ve covered a lot of new material in this article and added useful tools to your arsenal!
You’ve learned how to save Python objects to a database using SQLAlchemy. You’ve also learned how to use Marshmallow to serialize and deserialize SQLAlchemy objects and use them with a JSON REST API. The things you’ve learned have certainly been a step up in complexity from the simple REST API of Part 1, but that step has given you two very powerful tools to use when creating more complex applications.
SQLAlchemy and Marshmallow are amazing tools in their own right. Using them together gives you a great leg up to create your own web applications backed by a database.
In Part 3 of this series, you’ll focus on the R part of RDBMS :relationships, which provide even more power when you are using a database.