Il tipo di dati stringa è uno dei tipi di dati più significativi in qualsiasi linguaggio di programmazione. Difficilmente puoi scrivere un programma utile senza di esso. Tuttavia, molti sviluppatori non conoscono alcuni aspetti di questo tipo. Consideriamo quindi questi aspetti.
Rappresentazione di stringhe in memoria
In .Net, le stringhe si trovano in base alla regola BSTR (Stringa di base o stringa binaria). Questo metodo di rappresentazione dei dati di stringa viene utilizzato in COM (la parola "base" deriva dal linguaggio di programmazione Visual Basic in cui era inizialmente utilizzata). Come sappiamo, PWSZ (Pointer to Wide-character String, Zero-terminated) viene utilizzato in C/C++ per la rappresentazione di stringhe. Con tale posizione in memoria, un null terminato si trova alla fine di una stringa. Questo terminatore permette di determinare la fine della stringa. La lunghezza della stringa in PWSZ è limitata solo da un volume di spazio libero.
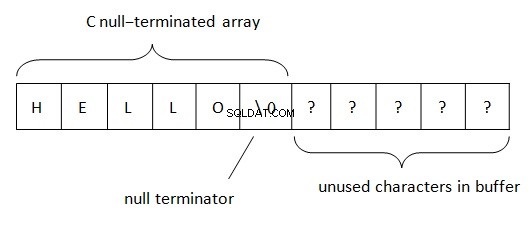
In BSTR, la situazione è leggermente diversa.
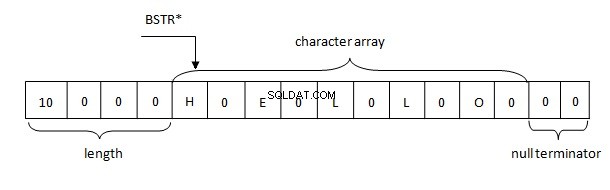
Gli aspetti di base della rappresentazione della stringa BSTR in memoria sono i seguenti:
- La lunghezza della stringa è limitata da un certo numero. In PWSZ, la lunghezza della stringa è limitata dalla disponibilità di memoria libera.
- La stringa BSTR punta sempre al primo carattere nel buffer. PWSZ può puntare a qualsiasi carattere nel buffer.
- In BSTR, simile a PWSZ, il carattere null si trova sempre alla fine. In BSTR, il carattere null è un carattere valido e può essere trovato ovunque nella stringa.
- Poiché il terminatore null si trova alla fine, BSTR è compatibile con PWSZ, ma non viceversa.
Pertanto, le stringhe in .NET sono rappresentate in memoria secondo la regola BSTR. Il buffer contiene una lunghezza di stringa di 4 byte seguita da caratteri di due byte di una stringa nel formato UTF-16, che, a sua volta, è seguita da due byte nulli (\u0000).
L'uso di questa implementazione ha molti vantaggi:la lunghezza della stringa non deve essere ricalcolata poiché è memorizzata nell'intestazione, una stringa può contenere caratteri nulli ovunque. E la cosa più importante è che l'indirizzo di una stringa (appuntata) può essere facilmente passato al codice nativo dove WCHAR* è previsto.
Quanta memoria occupa un oggetto stringa?
Ho riscontrato articoli che affermano che la dimensione dell'oggetto stringa è uguale a size=20 + (lunghezza/2)*4, ma questa formula non è del tutto corretta.
Per cominciare, una stringa è un tipo di collegamento, quindi i primi quattro byte contengono SyncBlockIndex e i successivi quattro byte contengono il puntatore del tipo.
Misura della corda =4 + 4 + …
Come ho detto sopra, la lunghezza della stringa è memorizzata nel buffer. È un campo di tipo int, quindi dobbiamo aggiungere altri 4 byte.
Misura della corda =4 + 4 + 4 + …
Per passare rapidamente una stringa al codice nativo (senza copiarla), il terminatore null si trova alla fine di ogni stringa che occupa 2 byte. Pertanto,
Dimensione della corda =4 + 4 + 4 + 2 + …
L'unica cosa rimasta è ricordare che ogni carattere in una stringa è nella codifica UTF-16 e occupa anche 2 byte. Pertanto:
Misura della corda =4 + 4 + 4 + 2 + 2 * lunghezza =14 + 2 * lunghezza
Ancora una cosa e abbiamo finito. La memoria allocata dal gestore di memoria in CLR è multiplo di 4 byte (4, 8, 12, 16, 20, 24, …). Quindi, se la lunghezza della stringa richiede 34 byte in totale, verranno allocati 36 byte. Dobbiamo arrotondare il nostro valore al numero più grande più vicino che è multiplo di quattro. Per questo, abbiamo bisogno di:
Dimensione stringa =4 * ((14 + 2 * lunghezza + 3) / 4) (divisione intera)
Il problema delle versioni :fino a .NET v4, c'era un ulteriore m_arrayLength campo del tipo int nella classe String che ha richiesto 4 byte. Questo campo è una lunghezza reale del buffer allocato per una stringa, incluso il terminatore null, ovvero è lunghezza + 1. In .NET 4.0, questo campo è stato eliminato dalla classe. Di conseguenza, un oggetto di tipo stringa occupa 4 byte in meno.
La dimensione di una stringa vuota senza m_arrayLength campo (cioè in .Net 4.0 e versioni successive) è uguale a =4 + 4 + 4 + 2 =14 byte, e con questo campo (cioè inferiore a .Net 4.0), la sua dimensione è uguale a =4 + 4 + 4 + 4 + 2 =18 byte. Se arrotondiamo a 4 byte, la dimensione sarà rispettivamente di 16 e 20 byte.
Aspetti stringa
Quindi, abbiamo considerato la rappresentazione delle stringhe e la dimensione che occupano in memoria. Ora parliamo delle loro peculiarità.
Gli aspetti di base delle stringhe in .NET sono i seguenti:
- Le stringhe sono tipi di riferimento.
- Le stringhe sono immutabili. Una volta creata, una stringa non può essere modificata (con mezzi equi). Ogni chiamata del metodo di questa classe restituisce una nuova stringa, mentre la stringa precedente diventa una preda del Garbage Collector.
- Le stringhe ridefiniscono il metodo Object.Equals. Di conseguenza, il metodo confronta i valori dei caratteri nelle stringhe, non i valori dei collegamenti.
Consideriamo ogni punto in dettaglio.
Le stringhe sono tipi di riferimento
Le stringhe sono veri e propri tipi di riferimento. Cioè, si trovano sempre nell'heap. Molti di noi li confondono con i tipi di valore, poiché ti comporti allo stesso modo. Ad esempio, sono immutabili e il loro confronto viene eseguito per valore, non per riferimenti, ma dobbiamo tenere presente che si tratta di un tipo di riferimento.
Le stringhe sono immutabili
- Le stringhe sono immutabili per uno scopo. L'immutabilità delle stringhe ha una serie di vantaggi:
- Il tipo di stringa è thread-safe, poiché nessun singolo thread può modificare il contenuto di una stringa.
- L'uso di stringhe immutabili porta a una diminuzione del carico di memoria, poiché non è necessario memorizzare 2 istanze della stessa stringa. Di conseguenza, viene utilizzata meno memoria e il confronto viene eseguito più velocemente, poiché vengono confrontati solo i riferimenti. In .NET, questo meccanismo è chiamato string interne (pool di stringhe). Ne parleremo un po' più tardi.
- Quando si passa un parametro immutabile a un metodo, possiamo smettere di preoccuparci che venga modificato (se non è stato passato come ref o out, ovviamente).
Le strutture dati possono essere suddivise in due tipi:effimere e persistenti. Le strutture dati effimere memorizzano solo le loro ultime versioni. Le strutture dati persistenti salvano tutte le versioni precedenti durante la modifica. Questi ultimi sono, infatti, immutabili, poiché le loro operazioni non modificano la struttura in loco. Invece, restituiscono una nuova struttura basata su quella precedente.
Dato che le stringhe sono immutabili, potrebbero essere persistenti, ma non lo sono. Le stringhe sono effimere in .Net.
Per fare un confronto, prendiamo le stringhe Java. Sono immutabili, come in .NET, ma sono anche persistenti. L'implementazione della classe String in Java è la seguente:
public final class String
{
private final char value[];
private final int offset;
private final int count;
private int hash;
.....
}
Oltre a 8 byte nell'intestazione dell'oggetto, inclusi un riferimento al tipo e un riferimento a un oggetto di sincronizzazione, le stringhe contengono i seguenti campi:
- Un riferimento a un array di caratteri;
- Un indice del primo carattere della stringa nell'array char (offset dall'inizio)
- Il numero di caratteri nella stringa;
- Il codice hash calcolato dopo aver chiamato per la prima volta HashCode() metodo.
Le stringhe in Java richiedono più memoria rispetto a .NET, poiché contengono campi aggiuntivi che consentono loro di essere persistenti. A causa della persistenza, l'esecuzione di String.substring() metodo in Java richiede O(1) , poiché non richiede la copia di stringhe come in .NET, dove l'esecuzione di questo metodo richiede O(n) .
Implementazione del metodo String.substring() in Java:
public String substring(int beginIndex, int endIndex)
{
if (beginIndex < 0) throw new StringIndexOutOfBoundsException(beginIndex); if (endIndex > count)
throw new StringIndexOutOfBoundsException(endIndex);
if (beginIndex > endIndex)
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
return ((beginIndex == 0) && (endIndex == count)) ? this : new String(offset + beginIndex, endIndex - beginIndex, value);
}
public String(int offset, int count, char value[])
{
this.value = value;
this.offset = offset;
this.count = count;
} Tuttavia, se una stringa di origine è sufficientemente grande e la sottostringa di ritaglio è lunga diversi caratteri, l'intero array di caratteri della stringa iniziale sarà sospeso in memoria fino a quando non vi sarà un riferimento alla sottostringa. Oppure, se si serializza la sottostringa ricevuta con mezzi standard e la si passa sulla rete, l'intero array originale verrà serializzato e il numero di byte passati sulla rete sarà elevato. Pertanto, al posto del codice
s =ss.sottostringa(3)
è possibile utilizzare il seguente codice:
s =new String(ss.substring(3)),
Questo codice non memorizzerà il riferimento alla matrice di caratteri della stringa di origine. Invece, copierà solo la parte effettivamente utilizzata dell'array. A proposito, se chiamiamo questo costruttore su una stringa la cui lunghezza è uguale alla lunghezza dell'array di caratteri, la copia non avrà luogo. Verrà invece utilizzato il riferimento all'array originale.
Come si è scoperto, l'implementazione del tipo di stringa è stata modificata nell'ultima versione di Java. Ora, non ci sono campi di offset e lunghezza nella classe. Il nuovo hash32 (con diverso algoritmo di hashing) è stato invece introdotto. Ciò significa che le stringhe non sono più persistenti. Ora, la String.substring il metodo creerà una nuova stringa ogni volta.
String ridefinisce Onbject.Equals
La classe string ridefinisce il metodo Object.Equals. Di conseguenza, il confronto avviene, ma non per riferimento, ma per valore. Suppongo che gli sviluppatori siano grati ai creatori della classe String per aver ridefinito l'operatore ==, poiché il codice che utilizza ==per il confronto delle stringhe sembra più profondo della chiamata al metodo.
if (s1 == s2)
Rispetto a
if (s1.Equals(s2))
A proposito, in Java, l'operatore ==confronta per riferimento. Se hai bisogno di confrontare le stringhe per carattere, dobbiamo usare il metodo string.equals().
Tirocinio a corda
Infine, consideriamo il tirocinio delle stringhe. Diamo un'occhiata a un semplice esempio:un codice che inverte una stringa.
var s = "Strings are immutuble";
int length = s.Length;
for (int i = 0; i < length / 2; i++)
{
var c = s[i];
s[i] = s[length - i - 1];
s[length - i - 1] = c;
} Ovviamente, questo codice non può essere compilato. Il compilatore genererà errori per queste stringhe, poiché tentiamo di modificare il contenuto della stringa. Qualsiasi metodo della classe String restituisce una nuova istanza della stringa, invece della sua modifica del contenuto.
La stringa può essere modificata, ma dovremo utilizzare il codice non sicuro. Consideriamo il seguente esempio:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
} Dopo l'esecuzione di questo codice, elbatummi era sgnirtS verrà scritto nella stringa, come previsto. La mutabilità delle stringhe porta a un caso stravagante relativo all'internamento delle stringhe.
Tirocinio a corda è un meccanismo in cui letterali simili sono rappresentati in memoria come un singolo oggetto.
In breve, il punto dell'internamento delle stringhe è il seguente:esiste una singola tabella interna con hash all'interno di un processo (non all'interno di un dominio dell'applicazione), in cui le stringhe sono le sue chiavi e i valori sono i riferimenti ad esse. Durante la compilazione JIT, le stringhe letterali vengono inserite in una tabella in sequenza (ogni stringa in una tabella può essere trovata solo una volta). Durante l'esecuzione, da questa tabella vengono assegnati riferimenti a stringhe letterali. Durante l'esecuzione, possiamo inserire una stringa nella tabella interna con String.Intern metodo. Inoltre, possiamo verificare la disponibilità di una stringa nella tabella interna utilizzando String.IsInterned metodo.
var s1 = "habrahabr"; var s2 = "habrahabr"; var s3 = "habra" + "habr"; Console.WriteLine(object.ReferenceEquals(s1, s2));//true Console.WriteLine(object.ReferenceEquals(s1, s3));//true
Nota che solo le stringhe letterali sono interne per impostazione predefinita. Poiché la tabella interna con hash viene utilizzata per l'implementazione interna, la ricerca in questa tabella viene eseguita durante la compilazione JIT. Questo processo richiede del tempo. Quindi, se tutte le stringhe vengono internate, ridurrà l'ottimizzazione a zero. Durante la compilazione nel codice IL, il compilatore concatena tutte le stringhe letterali, poiché non è necessario memorizzarle in parti. Pertanto, la seconda uguaglianza restituisce vero .
Ora, torniamo al nostro caso. Considera il seguente codice:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
}
Console.WriteLine("Strings are immutable"); Sembra che tutto sia abbastanza ovvio e il codice dovrebbe restituire Le stringhe sono immutabili . Tuttavia, non è così! Il codice restituisce elbatummi era sgnirtS . Succede proprio per via dello stage. Quando modifichiamo le stringhe, ne modifichiamo il contenuto e, poiché è letterale, viene internato e rappresentato da una singola istanza della stringa.
Possiamo abbandonare il tirocinio di stringhe se applichiamo il CompilationRelaxationsAttribute attribuire all'assemblea. Questo attributo controlla l'accuratezza del codice creato dal compilatore JIT dell'ambiente CLR. Il costruttore di questo attributo accetta CompilationRelaxations enumerazione, che attualmente include solo CompilationRelaxations.NoStringInterning . Di conseguenza, l'assieme viene contrassegnato come quello che non richiede tirocinio.
A proposito, questo attributo non viene elaborato in .NET Framework v1.0. Ecco perché era impossibile disabilitare lo stage. A partire dalla versione 2, il mscorlib assembly è contrassegnato con questo attributo. Quindi, risulta che le stringhe in .NET possono essere modificate con il codice non sicuro.
E se ci dimentichiamo di non sicuro?
A quanto pare, possiamo modificare il contenuto della stringa senza il codice non sicuro. Invece, possiamo usare il meccanismo di riflessione. Questo trucco ha avuto successo in .NET fino alla versione 2.0. Successivamente, gli sviluppatori della classe String ci hanno privato di questa opportunità. In .NET 2.0, la classe String ha due metodi interni:SetChar per il controllo dei limiti e InternalSetCharNoBoundsCheck che non fa limiti di controllo. Questi metodi impostano il carattere specificato in base a un determinato indice. L'implementazione dei metodi si presenta nel modo seguente:
internal unsafe void SetChar(int index, char value)
{
if ((uint)index >= (uint)this.Length)
throw new ArgumentOutOfRangeException("index", Environment.GetResourceString("ArgumentOutOfRange_Index"));
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
}
internal unsafe void InternalSetCharNoBoundsCheck (int index, char value)
{
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
} Pertanto, possiamo modificare il contenuto della stringa senza codice non sicuro con l'aiuto del seguente codice:
var s = "Strings are immutable";
int length = s.Length;
var method = typeof(string).GetMethod("InternalSetCharNoBoundsCheck", BindingFlags.Instance | BindingFlags.NonPublic);
for (int i = 0; i < length / 2; i++)
{
var temp = s[i];
method.Invoke(s, new object[] { i, s[length - i - 1] });
method.Invoke(s, new object[] { length - i - 1, temp });
}
Console.WriteLine("Strings are immutable");
Come previsto, il codice restituisce elbatummi era sgnirtS .
Il problema delle versioni :in diverse versioni di .NET Framework, string.Empty può essere integrato o meno. Consideriamo il seguente codice:
string str1 = String.Empty;
StringBuilder sb = new StringBuilder().Append(String.Empty);
string str2 = String.Intern(sb.ToString());
if (object.ReferenceEquals(str1, str2))
Console.WriteLine("Equal");
else
Console.WriteLine("Not Equal"); In .NET Framework 1.0, .NET Framework 1.1 e .NET Framework 3.5 con il Service Pack 1 (SP1), str1 e str2 non sono uguali. Attualmente, string.Empty non è internato.
Aspetti della performance
C'è un effetto collaterale negativo dello stage. Il fatto è che il riferimento a un oggetto interno String memorizzato da CLR può essere salvato anche dopo la fine del lavoro dell'applicazione e anche dopo la fine del lavoro del dominio dell'applicazione. Pertanto, è meglio omettere l'uso di stringhe letterali grandi. Se è ancora richiesto, lo stage deve essere disabilitato applicando le CompilationRelaxations attributo all'assieme.