Le UDF scalari sono sempre state un'arma a doppio taglio:sono ottime per gli sviluppatori, che riescono ad astrarre la logica noiosa invece di ripeterla in tutte le loro query, ma sono orribili per le prestazioni di runtime in produzione, perché l'ottimizzatore non lo fa t gestirli bene. In sostanza, ciò che accade è che le esecuzioni UDF vengono mantenute separate dal resto del piano di esecuzione, quindi vengono chiamate una volta per ogni riga e non possono essere ottimizzate in base al numero di righe stimato o effettivo o integrate nel resto del piano.
Poiché, nonostante i nostri migliori sforzi da SQL Server 2000, non siamo in grado di impedire efficacemente l'utilizzo di UDF scalari, non sarebbe fantastico fare in modo che SQL Server li gestisca semplicemente meglio?
SQL Server 2019 introduce una nuova funzionalità denominata Scalar UDF Inlining. Invece di mantenere la funzione separata, è incorporata nel piano generale. Ciò porta a un piano di esecuzione molto migliore e, a sua volta, a prestazioni di runtime migliori.
Ma prima, per illustrare meglio l'origine del problema, iniziamo con una coppia di semplici tabelle di poche righe, in un database in esecuzione su SQL Server 2017 (o su 2019 ma con un livello di compatibilità inferiore):
CREATE DATABASE Whatever; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 140; GO USE Whatever; GO CREATE TABLE dbo.Languages ( LanguageID int PRIMARY KEY, Name sysname ); CREATE TABLE dbo.Employees ( EmployeeID int PRIMARY KEY, LanguageID int NOT NULL FOREIGN KEY REFERENCES dbo.Languages(LanguageID) ); INSERT dbo.Languages(LanguageID, Name) VALUES(1033, N'English'), (45555, N'Klingon'); INSERT dbo.Employees(EmployeeID, LanguageID) SELECT [object_id], CASE ABS([object_id]%2) WHEN 1 THEN 1033 ELSE 45555 END FROM sys.all_objects;
Ora abbiamo una semplice query in cui vogliamo mostrare ogni dipendente e il nome della sua lingua principale. Diciamo che questa query viene utilizzata in molti posti e/o in modi diversi, quindi, invece di creare un join nella query, scriviamo una UDF scalare per astrarre quel join:
CREATE FUNCTION dbo.GetLanguage(@id int) RETURNS sysname AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END
Quindi la nostra query attuale è simile a questa:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
Se osserviamo il piano di esecuzione della query, qualcosa manca stranamente:
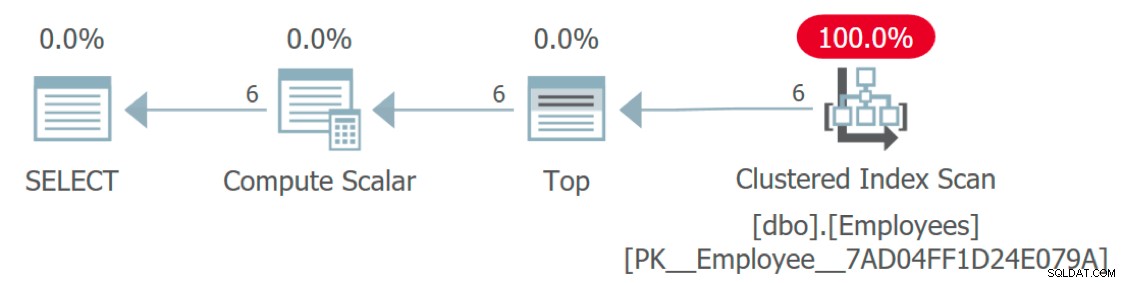 Piano di esecuzione che mostra l'accesso ai dipendenti ma non alle lingue
Piano di esecuzione che mostra l'accesso ai dipendenti ma non alle lingue
Come si accede alla tabella Lingue? Questo piano sembra molto efficiente perché, come la funzione stessa, sta astraendo parte della complessità coinvolta. In effetti, questo piano grafico è identico a una query che assegna semplicemente una costante o una variabile alla Language colonna:
SELECT TOP (6) EmployeeID, Language = N'Sanskrit' FROM dbo.Employees;
Ma se esegui una traccia sulla query originale, vedrai che ci sono effettivamente sei chiamate alla funzione (una per ogni riga) oltre alla query principale, ma questi piani non vengono restituiti da SQL Server.
Puoi anche verificarlo controllando sys.dm_exec_function_stats , ma questa non è una garanzia :
SELECT [function] = OBJECT_NAME([object_id]), execution_count FROM sys.dm_exec_function_stats WHERE object_name(object_id) IS NOT NULL;
function execution_count ----------- --------------- GetLanguage 6
SentryOne Plan Explorer mostrerà le dichiarazioni se generi un piano effettivo dall'interno del prodotto, ma possiamo ottenerle solo dalla traccia e non ci sono ancora piani raccolti o mostrati per le singole chiamate di funzione:
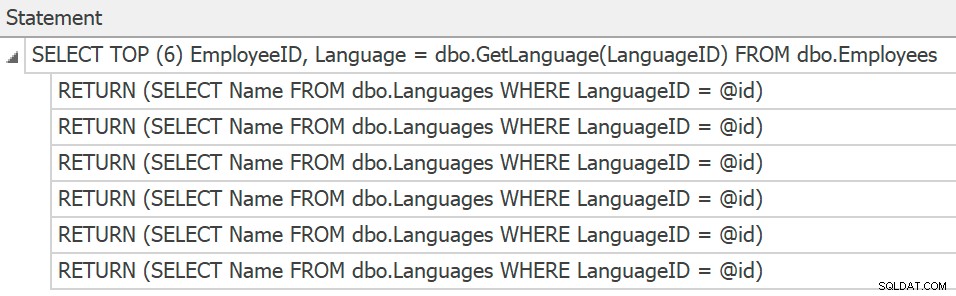 Istruzioni di traccia per chiamate UDF scalari individuali
Istruzioni di traccia per chiamate UDF scalari individuali
Tutto ciò li rende molto difficili da risolvere, perché devi dargli la caccia, anche quando sai già che sono lì. Può anche creare un vero pasticcio di analisi delle prestazioni se stai confrontando due piani in base a cose come i costi stimati, perché non solo gli operatori pertinenti si nascondono dal diagramma fisico, ma anche i costi non sono incorporati da nessuna parte nel piano.
Avanzamento rapido a SQL Server 2019
Dopo tutti questi anni di comportamenti problematici e oscure cause profonde, hanno fatto in modo che alcune funzioni potessero essere ottimizzate nel piano di esecuzione generale. L'integrazione scalare dell'UDF rende visibili gli oggetti a cui accedono per la risoluzione dei problemi *e* consente loro di essere inseriti nella strategia del piano di esecuzione. Ora le stime di cardinalità (basate su statistiche) consentono strategie di join che semplicemente non erano possibili quando la funzione veniva chiamata una volta per ogni riga.
Possiamo utilizzare lo stesso esempio di cui sopra, creare lo stesso set di oggetti su un database di SQL Server 2019 o pulire la cache del piano e aumentare il livello di compatibilità a 150:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 150; GO
Ora, quando eseguiamo di nuovo la nostra query a sei righe:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
Otteniamo un piano che include la tabella Lingue e i costi associati all'accesso:
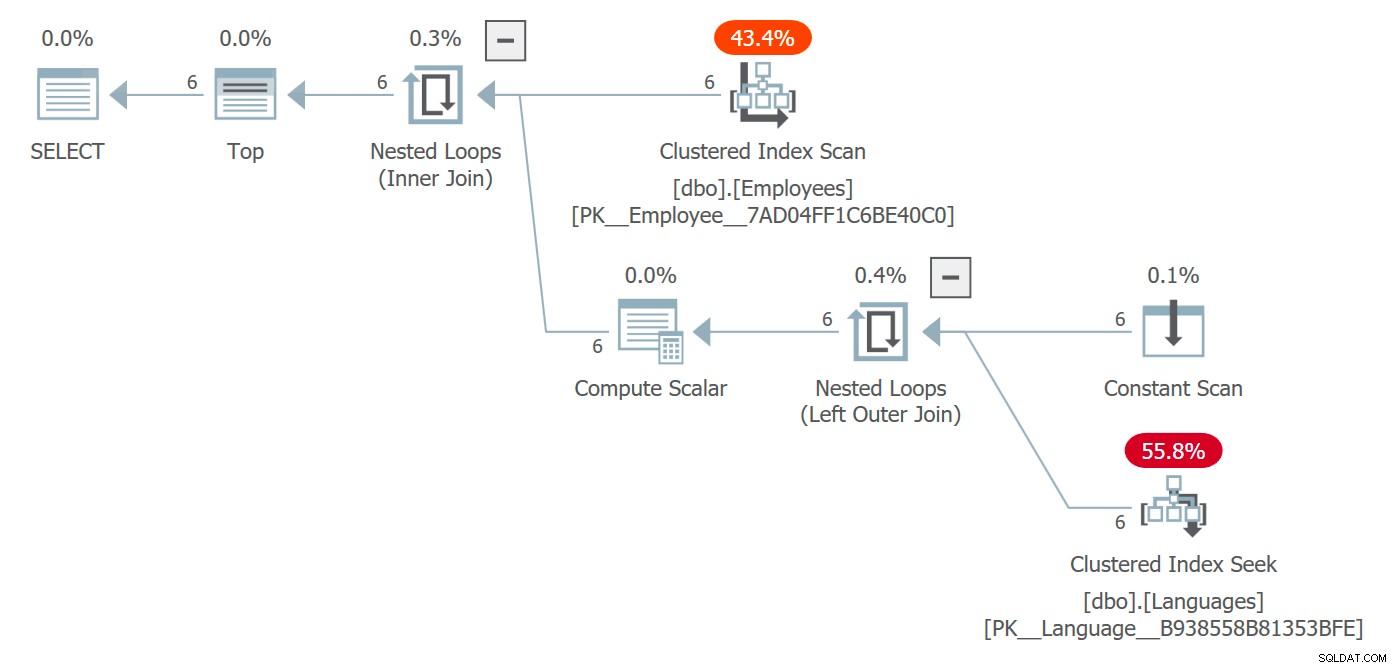 Piano che include l'accesso agli oggetti referenziati all'interno dell'UDF scalare
Piano che include l'accesso agli oggetti referenziati all'interno dell'UDF scalare
Qui l'ottimizzatore ha scelto un join di loop nidificato ma, in circostanze diverse, avrebbe potuto scegliere una strategia di join diversa, contemplato il parallelismo ed essere essenzialmente libero di modificare completamente la forma del piano. È improbabile che tu lo veda in una query che restituisce 6 righe e non rappresenta in alcun modo un problema di prestazioni, ma su scale più ampie potrebbe.
Il piano riflette che la funzione non viene chiamata per riga:mentre la ricerca viene effettivamente eseguita sei volte, puoi vedere che la funzione stessa non viene più visualizzata in sys.dm_exec_function_stats . Uno svantaggio che puoi eliminare è che, se utilizzi questo DMV per determinare se una funzione viene utilizzata attivamente (come spesso facciamo per procedure e indici), non sarà più affidabile.
Avvertenze
Non tutte le funzioni scalari sono inlineabili e, anche quando una funzione *è* inlineabile, non sarà necessariamente inlineabile in ogni scenario. Ciò ha spesso a che fare con la complessità della funzione, la complessità della query coinvolta o la combinazione di entrambe. Puoi controllare se una funzione è inlineabile in sys.sql_modules vista catalogo:
SELECT OBJECT_NAME([object_id]), definition, is_inlineable FROM sys.sql_modules;
E se, per qualsiasi motivo, non vuoi che una determinata funzione (o qualsiasi funzione in un database) sia inline, non devi fare affidamento sul livello di compatibilità del database per controllare quel comportamento. Non mi è mai piaciuto quell'accoppiamento sciolto, che è come cambiare stanza per guardare un programma televisivo diverso invece di cambiare semplicemente canale. Puoi controllarlo a livello di modulo usando l'opzione INLINE:
ALTER FUNCTION dbo.GetLanguage(@id int) RETURNS sysname WITH INLINE = OFF AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END GO
E puoi controllarlo a livello di database, ma separato dal livello di compatibilità:
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF;
Anche se dovresti avere un caso d'uso abbastanza buono per far oscillare quel martello, IMHO.
Conclusione
Ora, non sto suggerendo che tu possa andare e astrarre ogni parte della logica in un UDF scalare e presumere che ora SQL Server si occuperà solo di tutti i casi. Se si dispone di un database con un utilizzo elevato dell'UDF scalare, è necessario scaricare l'ultimo CTP di SQL Server 2019, ripristinare un backup del database lì e controllare il DMV per vedere quante di queste funzioni saranno inline quando sarà il momento. Potrebbe essere un punto importante la prossima volta che stai discutendo per un aggiornamento, dal momento che essenzialmente otterrai tutte quelle prestazioni e il tempo perso per la risoluzione dei problemi.
Nel frattempo, se soffri di prestazioni UDF scalari e non eseguirai l'aggiornamento a SQL Server 2019 a breve, potrebbero esserci altri modi per ridurre i problemi.
Nota:ho scritto e messo in coda questo articolo prima di rendermi conto di aver già pubblicato un altro pezzo altrove.