Nell'articolo precedente ho spiegato come installare Ubuntu 18.04 e SQL Server 2019 sulle macchine virtuali. Ora, prima di procedere oltre, esaminiamo la configurazione.
Abbiamo creato tre macchine virtuali e i dettagli sono i seguenti:
| Nome host | Indirizzo IP | Ruolo |
| LinuxSQL01 | 192.168.0.140 | Replica primaria |
| LinuxSQL02 | 192.168.0.141 | Replica secondaria sincrona |
| LinuxSQL03 | 192.168.0.142 | Replica secondaria asincrona |
Aggiorna il file host.
Nella configurazione non utilizziamo un server di dominio. Pertanto, per risolvere il nome host, dobbiamo aggiungere una voce nel file host.
Il file host si trova su /etc directory. Esegui il comando seguente per modificare il file:
example@sqldat.com:/# vim /etc/hostsNel file host, inserisci i nomi host e gli indirizzi IP di tutte le macchine virtuali:
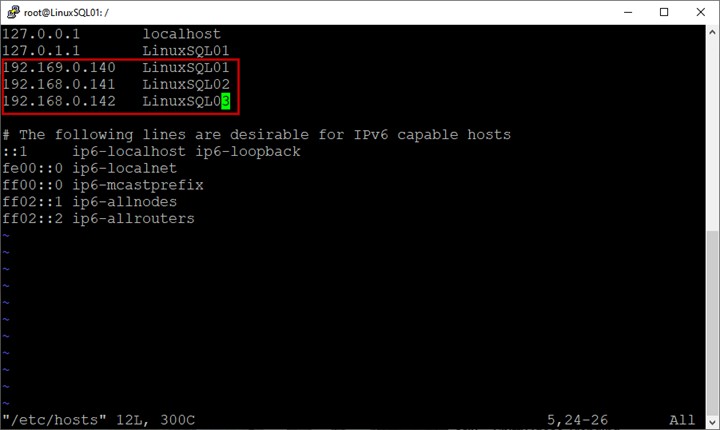
Salva il file host.
Esegui gli stessi passaggi su tutte le macchine virtuali.
Abilita i gruppi di disponibilità AlwaysOn di SQL Server
Prima di distribuire AlwaysOn, è necessario abilitare la funzionalità di disponibilità elevata in SQL Server.
In Windows Server 2016, questa opzione può essere abilitata dal gestore di configurazione di SQL Server, ma nella piattaforma Linux dobbiamo farlo con un comando bash.
Connettiti a LinuxSQL01 usando Putty ed esegui il comando seguente:
example@sqldat.com:~# sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1Riavvia i servizi di SQL Server:
example@sqldat.com:~# service mssql-server restartEsegui i passaggi precedenti su tutte le macchine virtuali.
Crea i certificati per l'autenticazione
A differenza di AlwaysOn sul server Windows, la distribuzione Linux non richiede un controller di dominio. Per l'autenticazione e la comunicazione tra repliche primarie e secondarie, utilizza il certificato.
Lo script seguente crea un certificato e una chiave master. Quindi esegue il backup del certificato e lo protegge con una password.
Collegati a LinuxSQL01 ed esegui il seguente script:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'abcd!1234';
CREATE CERTIFICATE AG_Auth_Cert WITH SUBJECT = 'dbm';
BACKUP CERTIFICATE AG_Auth_Cert
TO FILE = '/var/opt/mssql/data/ AG_Auth_Cert_backup.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/ AG_Auth_Cert_backup.pvk',
ENCRYPTION BY PASSWORD = 'abcd!1234'
);
Una volta ottenuti il certificato e la chiave master creati, li copiamo in repliche secondarie (LinuxSQL02 e LinuxSQL03) eseguendo il comando seguente.
Assicurati che la chiave master e la posizione del certificato siano gli stessi su tutte le repliche e disponga dell'autorizzazione di lettura-scrittura.
/*Copy certificate and the key to LinuxSQL02*/
scp /var/opt/mssql/data/AG_Auth_Cert_backup.cer example@sqldat.com:/var/opt/mssql/data/
scp /var/opt/mssql/data/AG_Auth_Cert_backup.pvk example@sqldat.com:/var/opt/mssql/data/
/*Copy certificate and the key to LinuxSQL03*/
scp /var/opt/mssql/data/AG_Auth_Cert_backup.cer example@sqldat.com:/var/opt/mssql/data/
scp /var/opt/mssql/data/AG_Auth_Cert_backup.pvk example@sqldat.com:/var/opt/mssql/data/
Eseguire il comando seguente sui nodi secondari per concedere l'autorizzazione di lettura-scrittura sul certificato e sulla chiave privata:
/*Grant read-write permission on certificate and key to example@sqldat.com*/
example@sqldat.com:~# chmod 777 /var/opt/mssql/data/AG_Auth_Cert_backup.pvk
example@sqldat.com:~# chmod 777 /var/opt/mssql/data/AG_Auth_Cert_backup.cer
/*Grant read-write permission on certificate and key to example@sqldat.com*/
example@sqldat.com:~# chmod 777 /var/opt/mssql/data/AG_Auth_Cert_backup.pvk
example@sqldat.com:~# chmod 777 /var/opt/mssql/data/AG_Auth_Cert_backup.cer
Una volta assegnata l'autorizzazione, creiamo il certificato e la chiave principale utilizzando il backup del certificato e della chiave principale creato su LinuxSQL01.
Per farlo, esegui il seguente comando su entrambe le repliche secondarie:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'abcd!1234';
CREATE CERTIFICATE AG_Auth_Cert
FROM FILE = '/var/opt/mssql/data/AG_Auth_Cert_backup.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/AG_Auth_Cert_backup.pvk',
DECRYPTION BY PASSWORD = 'abcd!1234'
);
Dopo aver creato il certificato e la chiave master, configureremo i punti di mirroring del database.
Crea gli endpoint di mirroring
Per comunicare tra le repliche primarie e secondarie, SQL Server utilizza gli endpoint di mirroring.
Un endpoint di mirroring utilizza il protocollo TCP/IP per inviare e ricevere messaggi dalle repliche primarie e secondarie ed è in ascolto su una porta TCP/IP univoca.
Eseguire lo script seguente per creare un endpoint sui nodi primari e secondari:
/*Run this script on LinuxSQL01*/
CREATE ENDPOINT [AG_LinuxSQL01]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE AG_Auth_Cert,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [AG_LinuxSQL01] STATE = STARTED;
/*Run this script on LinuxSQL02*/
CREATE ENDPOINT [AG_LinuxSQL02]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE AG_Auth_Cert,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [AG_LinuxSQL02] STATE = STARTED;
/*Run this script on LinuxSQL03*/
CREATE ENDPOINT [AG_LinuxSQL03]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE AG_Auth_Cert,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [AG_LinuxSQL03] STATE = STARTED;
Una volta creati i punti di mirroring, creiamo un gruppo di disponibilità.
Crea gruppo di disponibilità
Configureremo AlwaysON utilizzando SQL Server Management Studio.
Innanzitutto, avvialo e connettiti all'istanza LinuxSQL01 utilizzando sa credenziali. Una volta connesso all'istanza di SQL Server, fai clic con il pulsante destro del mouse su Always On High Availability e seleziona Procedura guidata nuovo gruppo di disponibilità .
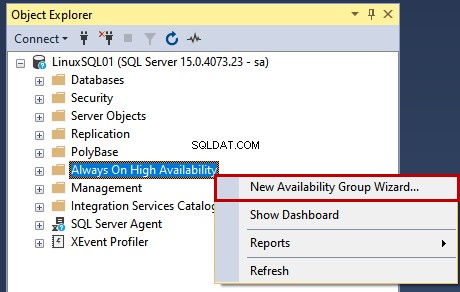
La Procedura guidata del gruppo di disponibilità inizia.
1. Introduzione
In una Introduzione schermata, vedere l'elenco delle attività che verranno eseguite dalla procedura guidata del gruppo di disponibilità. Fare clic su Avanti.
2. Specificare l'opzione del gruppo di disponibilità
Nella schermata Specifica l'opzione del gruppo di disponibilità, fornisci il nome del gruppo di disponibilità desiderato e scegli ESTERNO dal tipo di cluster menu a tendina.
Inoltre, metti un segno di spunta per Rilevamento dell'integrità a livello di database casella di controllo. Abilita la sessione evento estesa per la disponibilità della salute del gruppo.
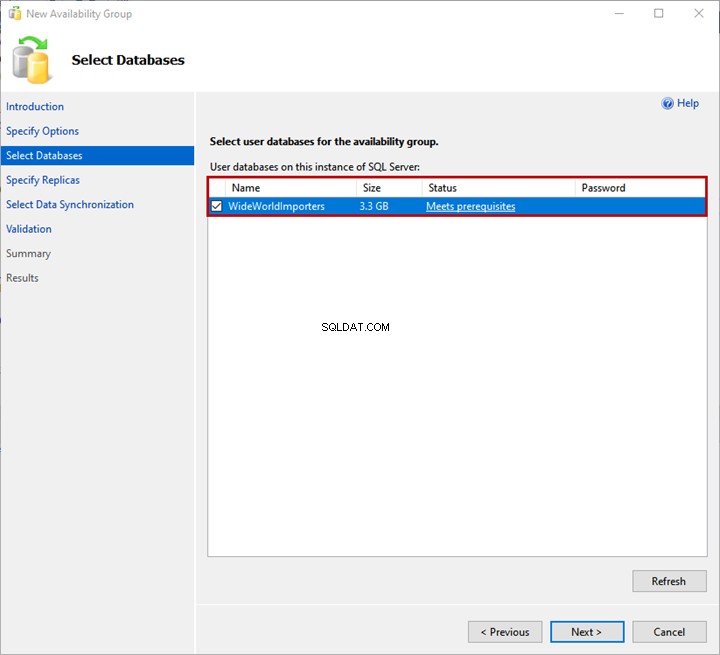
3. Seleziona database
Puoi scegliere il database da aggiungere al gruppo di disponibilità in Seleziona database schermo. Nota:il database deve soddisfare i seguenti prerequisiti:
- Il database deve essere nel modello di ripristino COMPLETO.
- È necessario creare un backup COMPLETO del database.
Ho ripristinato un backup di WideWorldImportors database sulla replica primaria. Il database è COMPLETO modello di ripristino ed è stato generato un backup completo.
Seleziona WideWorldImportors database dall'elenco e fare clic su Avanti .
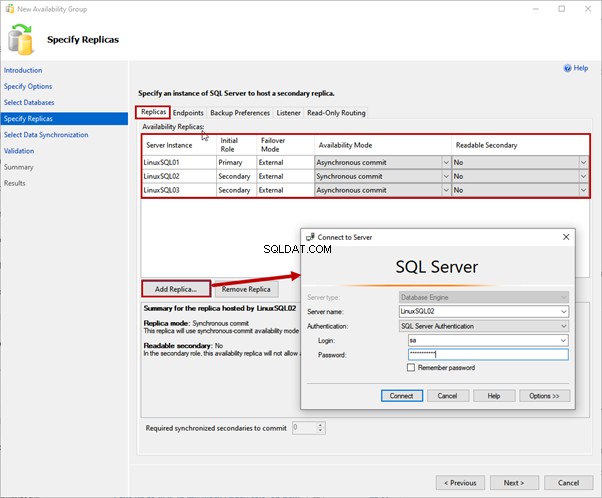
4. Specifica le repliche
In Specifica repliche schermo, abbiamo diverse schede per configurare diverse opzioni. Esaminiamoli tutti.
Scheda Repliche
Qui specifichiamo le repliche primarie e secondarie, la modalità di disponibilità e le modalità di failover.
Usiamo LinuxSQL01 come replica primaria. LinuxSQL02 e LinuxSQL03 sono una replica secondaria.
La modalità di disponibilità per LinuxSQL02 sarà Commit sincrono e per LinuxSQL03 sarà Commit asincrono .
Per aggiungere la replica, fai clic su Aggiungi replica . Quindi, su Connetti al server finestra di dialogo, specificare il nome del server ei dettagli di accesso SQL per connettersi all'istanza:
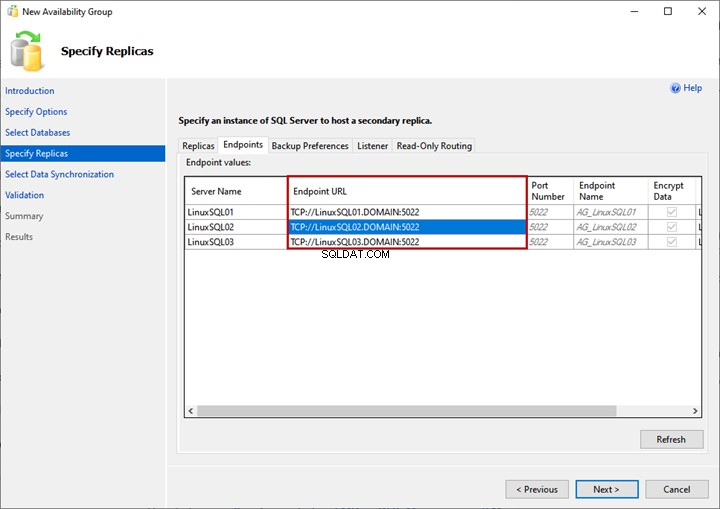
Scheda Endpoint
Qui possiamo visualizzare l'elenco delle repliche e dei relativi endpoint di mirroring con i numeri di porta e i nomi corrispondenti:
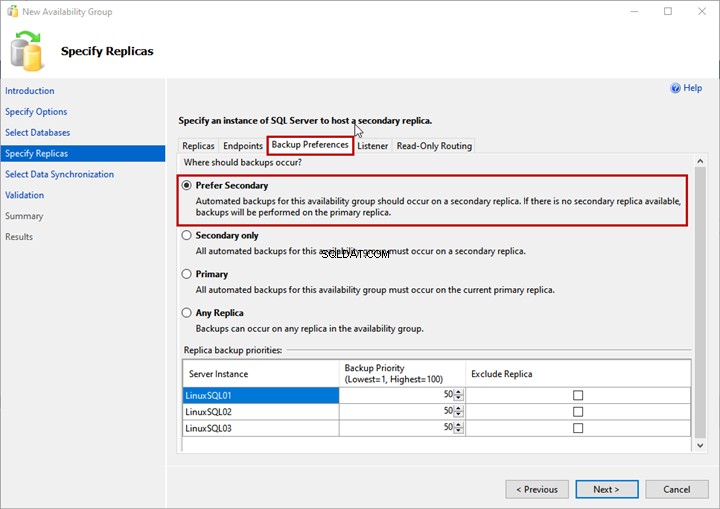
Preferenze di backup
Qui specifichi la replica che desideri utilizzare per generare il backup. Questa opzione è utile quando vuoi scaricare il processo di backup del database SQL all'interno del gruppo di disponibilità.
Puoi scegliere una delle seguenti opzioni:
- Preferisci secondario:il backup verrà generato sulla replica secondaria. Se la replica secondaria non è disponibile, il backup verrà generato sulla replica primaria.
- Solo secondario:tutti i backup verranno generati sulla replica secondaria.
- Principale:i backup verranno generati sulla replica primaria.
- Qualsiasi replica:il backup verrà generato da qualsiasi replica.
Utilizzeremo il Preferisci secondario opzione:
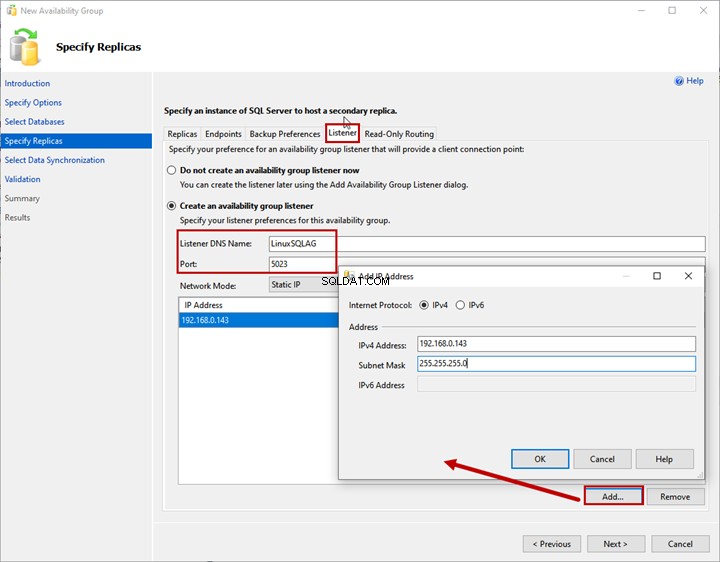
Ascoltatore
Il listener del gruppo di disponibilità è un nome virtuale utilizzato da un'applicazione per connettere i database del gruppo di disponibilità. Specifica il nome DNS del listener e la relativa porta in Nome DNS del listener e Porta caselle di testo.
Seleziona IP statico dalla Modalità di rete menu a tendina.
Per aggiungere l'indirizzo IP per il listener del gruppo di disponibilità, fai clic su Aggiungi >InserisciIndirizzo IP e Subnet Mask .
Routing di sola lettura
Qui puoi fornire l'URL di routing di sola lettura e Elenco di instradamento di sola lettura per repliche primarie e secondarie.
Non configureremo il routing di sola lettura nella nostra dimostrazione. Pertanto, fare clic su Avanti. Per ulteriori informazioni sul routing di sola lettura, puoi fare riferimento a Routing di sola lettura per un Always On.
Ora, torniamo al processo principale su cui lavoriamo.
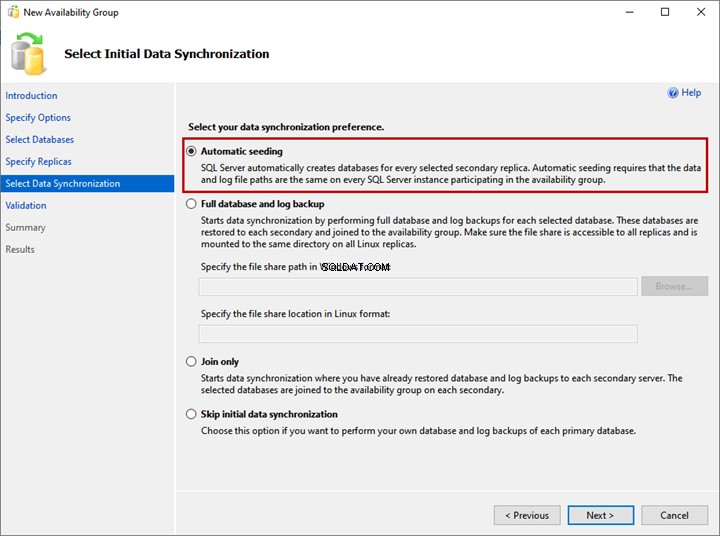
5. Seleziona Sincronizzazione dati iniziale
In Seleziona Sincronizzazione dati iniziale schermo, impostare le preferenze per la sincronizzazione iniziale dei dati. I dettagli di ciascuna opzione sono forniti nella schermata della procedura guidata e puoi sceglierne una qualsiasi:
- Semina automatica.
- Backup completo del database e del registro.
- Solo iscriviti.
- Salta la sincronizzazione dei dati iniziale.
Non ho creato WideWorldImportors database su replica LinuxSQL02 e LinuxSQL03, selezionando il Seeding automatico opzione. Creerà il database su entrambe le repliche e avvierà la sincronizzazione dei dati. Fare clic su Avanti.
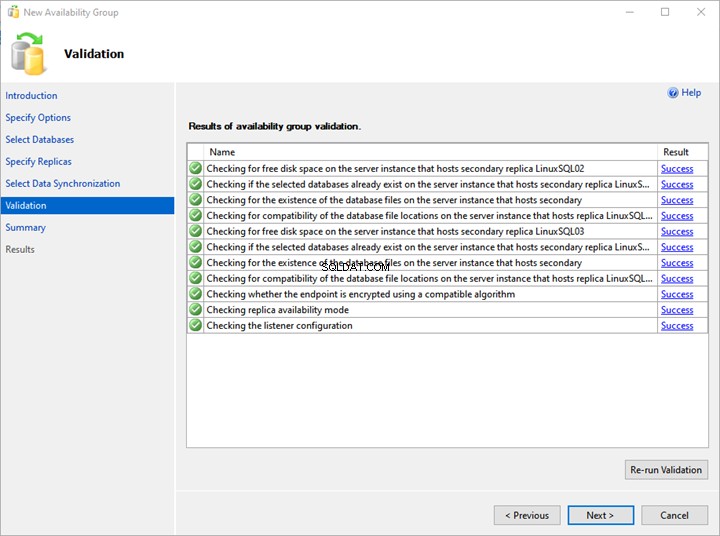
6. Convalida e riepilogo
Sulla Convalida schermata, la procedura guidata convalida tutte le configurazioni.
Per distribuire correttamente il gruppo di disponibilità Always On, è necessario che tutte le convalide siano riuscite. Se c'è qualche errore, devi risolverlo.
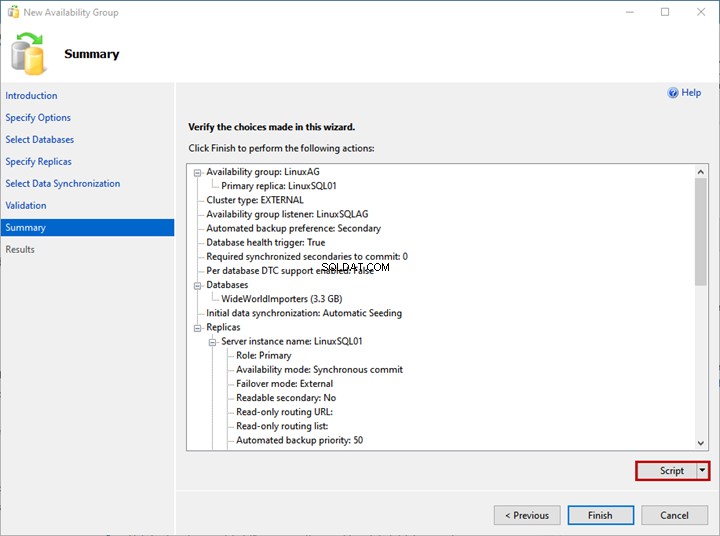
Nel Riepilogo schermata, puoi vedere l'elenco delle configurazioni scelte per distribuire il gruppo di disponibilità.
Rivedi i dettagli ancora una volta e fai clic su Fine – avvia il processo di distribuzione.
Se desideri generare lo script del processo di distribuzione, fai clic su Script .
Come vediamo, viene avviato il processo di distribuzione di AlwaysOn. Una volta completato correttamente, fai clic su Chiudi per uscire dalla procedura guidata.
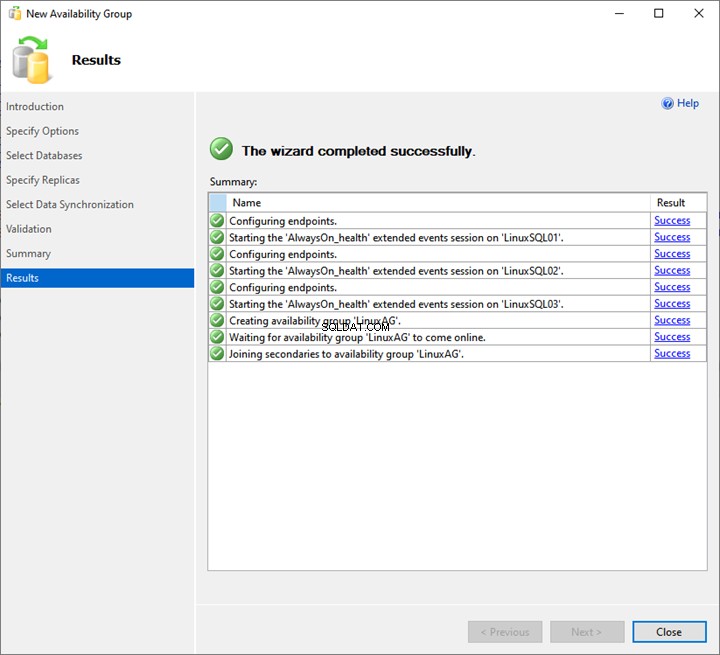
Pertanto, la distribuzione del gruppo di disponibilità AlwaysOn su SQL Server 2019 è completata.
Riepilogo
Questo articolo ci aiuta a comprendere il processo di distribuzione dettagliato del gruppo di disponibilità AlwaysOn di SQL Server su Linux.
Il prossimo articolo spiegherà come configurare il listener del gruppo di disponibilità ed eseguire il failover manuale usando SQL Server Management Studio. Resta sintonizzato!