La scorsa settimana ho fatto un paio di rapidi confronti delle prestazioni, mettendo a confronto il nuovo STRING_AGG() funzione contro il tradizionale FOR XML PATH approccio che uso da secoli. Ho testato sia l'ordine non definito/arbitrario che l'ordine esplicito e STRING_AGG() ha vinto in entrambi i casi:
- SQL Server v.Next:Prestazioni STRING_AGG(), parte 1
Per quei test, ho tralasciato diverse cose (non tutte intenzionalmente):
- Mikael Eriksson e Grzegorz Łyp hanno entrambi fatto notare che non stavo usando il
FOR XML PATHpiù efficiente in assoluto. costruire (e per essere chiari, non l'ho mai fatto). - Non ho eseguito alcun test su Linux; solo su Windows. Non mi aspetto che quelli siano molto diversi, ma dal momento che Grzegorz ha visto durate molto diverse, vale la pena indagare ulteriormente.
- Ho anche testato solo quando l'output sarebbe una stringa finita, non LOB, che credo sia il caso d'uso più comune (non credo che le persone concateneranno comunemente ogni riga di una tabella in una singola virgola separata string, ma questo è il motivo per cui nel mio post precedente ho chiesto i tuoi casi d'uso).
- Per i test di ordinazione, non ho creato un indice che potesse essere utile (o provato qualcosa in cui tutti i dati provenissero da un'unica tabella).
In questo post tratterò un paio di questi elementi, ma non tutti.
PER PERCORSO XML
Stavo usando quanto segue:
... FOR XML PATH, TYPE).value(N'.[1]', ...
Dopo questo commento di Mikael, ho aggiornato il mio codice per utilizzare invece questo costrutto leggermente diverso:
... FOR XML PATH(''), TYPE).value(N'text()[1]', ... Linux vs Windows
Inizialmente, mi ero preoccupato solo di eseguire test su Windows:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. Developer Edition (64-bit) on Windows Server 2016 Datacenter 6.3(Build 14393: ) (Hypervisor)
Ma Grzegorz ha affermato che lui (e presumibilmente molti altri) aveva accesso solo alla versione Linux di CTP 1.1. Quindi ho aggiunto Linux alla mia matrice di test:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. on Linux (Ubuntu 16.04.1 LTS)
Alcune osservazioni interessanti ma del tutto tangenziali:
@@VERSIONnon mostra l'edizione in questa build, maSERVERPROPERTY('Edition')restituisce laDeveloper Edition (64-bit)prevista .- In base ai tempi di compilazione codificati nei binari, le versioni Windows e Linux sembrano ora essere compilate contemporaneamente e dalla stessa fonte. O questa è stata una pazza coincidenza.
Test non ordinati
Ho iniziato testando l'output ordinato arbitrariamente (dove non esiste un ordinamento esplicitamente definito per i valori concatenati). Dopo Grzegorz, ho utilizzato WideWorldImporters (Standard), ma ho eseguito un join tra Sales.Orders e Sales.OrderLines . Il requisito fittizio qui è quello di produrre un elenco di tutti gli ordini e, insieme a ciascun ordine, un elenco separato da virgole di ogni StockItemID .
Da StockItemID è un numero intero, possiamo usare un varchar definito , il che significa che la stringa può essere di 8000 caratteri prima di doverci preoccupare della necessità di MAX. Poiché un int può avere una lunghezza massima di 11 (in realtà 10, se non firmato), più una virgola, ciò significa che un ordine dovrebbe supportare circa 8.000/12 (666) articoli in stock nello scenario peggiore (ad es. tutti i valori StockItemID hanno 11 cifre). Nel nostro caso, l'ID più lungo è di 3 cifre, quindi fino a quando i dati non vengono aggiunti, avremmo effettivamente bisogno di 8.000/4 (2.000) articoli di scorta univoci in un singolo ordine per giustificare MAX. Nel nostro caso, ci sono solo 227 articoli in stock in totale, quindi MAX non è necessario, ma dovresti tenerlo d'occhio. Se una stringa così grande è possibile nel tuo scenario, dovrai usare varchar(max) invece del valore predefinito (STRING_AGG() restituisce nvarchar(max) , ma tronca a 8.000 byte a meno che non sia input è un tipo MAX).
Le query iniziali (per mostrare l'output di esempio e osservare le durate per singole esecuzioni):
SET STATISTICS TIME ON;
GO
SELECT o.OrderID, StockItemIDs = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT o.OrderID,
StockItemIDs = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Sample output:
OrderID StockItemIDs
======= ============
1 67
2 50,10
3 114
4 206,130,50
5 128,121,155
Important SET STATISTICS TIME metrics (SQL Server Execution Times):
Windows:
STRING_AGG: CPU time = 217 ms, elapsed time = 405 ms.
FOR XML PATH: CPU time = 1954 ms, elapsed time = 2097 ms.
Linux:
STRING_AGG: CPU time = 627 ms, elapsed time = 472 ms.
FOR XML PATH: CPU time = 2188 ms, elapsed time = 2223 ms.
*/
Ho ignorato completamente l'analisi e la compilazione dei dati temporali, poiché erano sempre esattamente zero o abbastanza vicini da essere irrilevanti. C'erano piccole variazioni nei tempi di esecuzione per ogni esecuzione, ma non molto:i commenti sopra riflettono il tipico delta in runtime (STRING_AGG sembrava trarre un piccolo vantaggio dal parallelismo lì, ma solo su Linux, mentre FOR XML PATH non su nessuna delle due piattaforme). Entrambe le macchine avevano un unico socket, CPU quad-core allocata, 8 GB di memoria, configurazione pronta all'uso e nessun'altra attività.
Quindi ho voluto testare su larga scala (semplicemente una singola sessione che esegue la stessa query 500 volte). Non volevo restituire tutto l'output, come nella query precedente, 500 volte, poiché ciò avrebbe sopraffatto SSMS e, si spera, non rappresenti comunque scenari di query del mondo reale. Quindi ho assegnato l'output alle variabili e ho appena misurato il tempo complessivo per ogni batch:
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID, @x = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID,
@x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Ho eseguito quei test tre volte e la differenza era profonda, quasi un ordine di grandezza. Ecco la durata media dei tre test:
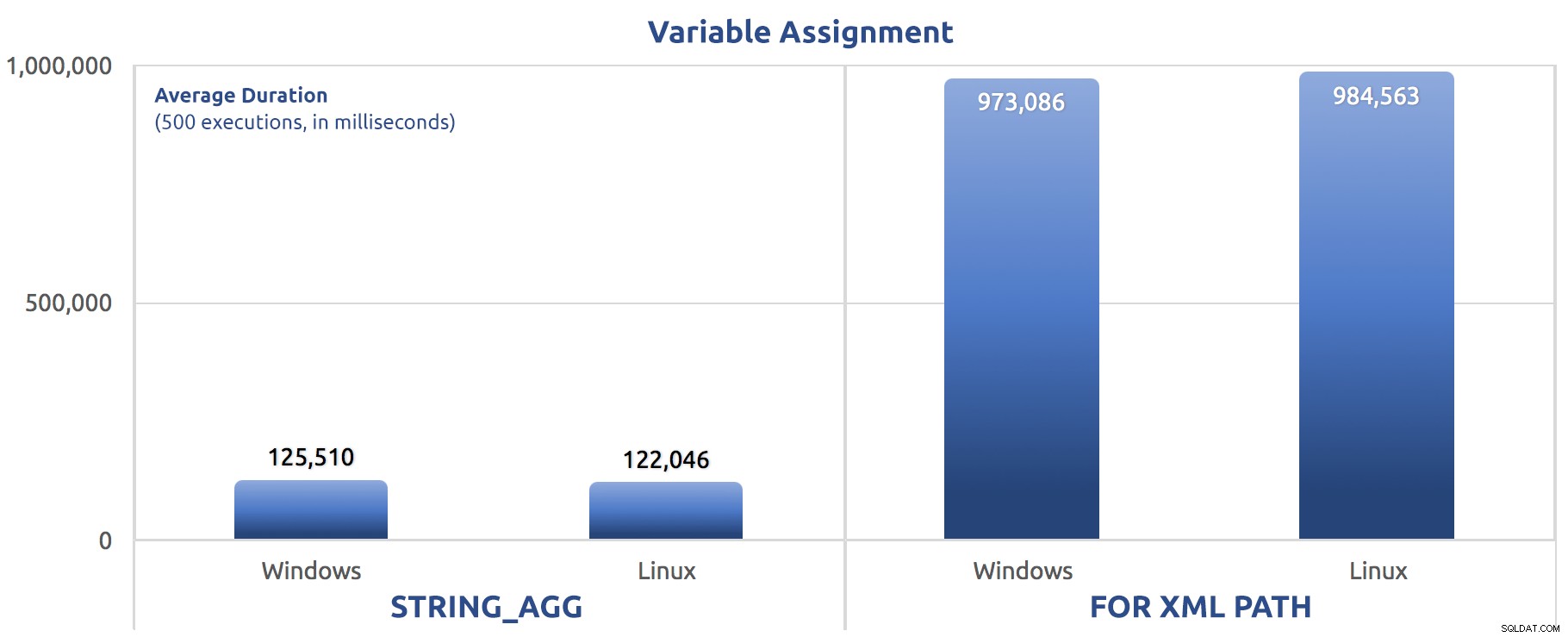 Durata media, in millisecondi, per 500 esecuzioni di assegnazione variabile
Durata media, in millisecondi, per 500 esecuzioni di assegnazione variabile
Ho testato anche una varietà di altre cose in questo modo, principalmente per assicurarmi di coprire i tipi di test che Grzegorz stava eseguendo (senza la parte LOB).
- Selezione solo della lunghezza dell'output
- Ottenere la lunghezza massima dell'output (di una riga arbitraria)
- Selezionare tutto l'output in una nuova tabella
Selezione solo della lunghezza dell'output
Questo codice esegue semplicemente ogni ordine, concatena tutti i valori StockItemID e quindi restituisce solo la lunghezza.
SET STATISTICS TIME ON;
GO
SELECT LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 142 ms, elapsed time = 351 ms.
FOR XML PATH: CPU time = 1984 ms, elapsed time = 2120 ms.
Linux:
STRING_AGG: CPU time = 310 ms, elapsed time = 191 ms.
FOR XML PATH: CPU time = 2149 ms, elapsed time = 2167 ms.
*/ Per la versione in batch, ancora una volta, ho usato l'assegnazione di variabili, piuttosto che provare a restituire molti set di risultati a SSMS. L'assegnazione della variabile finirebbe su una riga arbitraria, ma ciò richiede comunque scansioni complete, perché la riga arbitraria non viene selezionata prima.
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Metriche di performance di 500 esecuzioni:
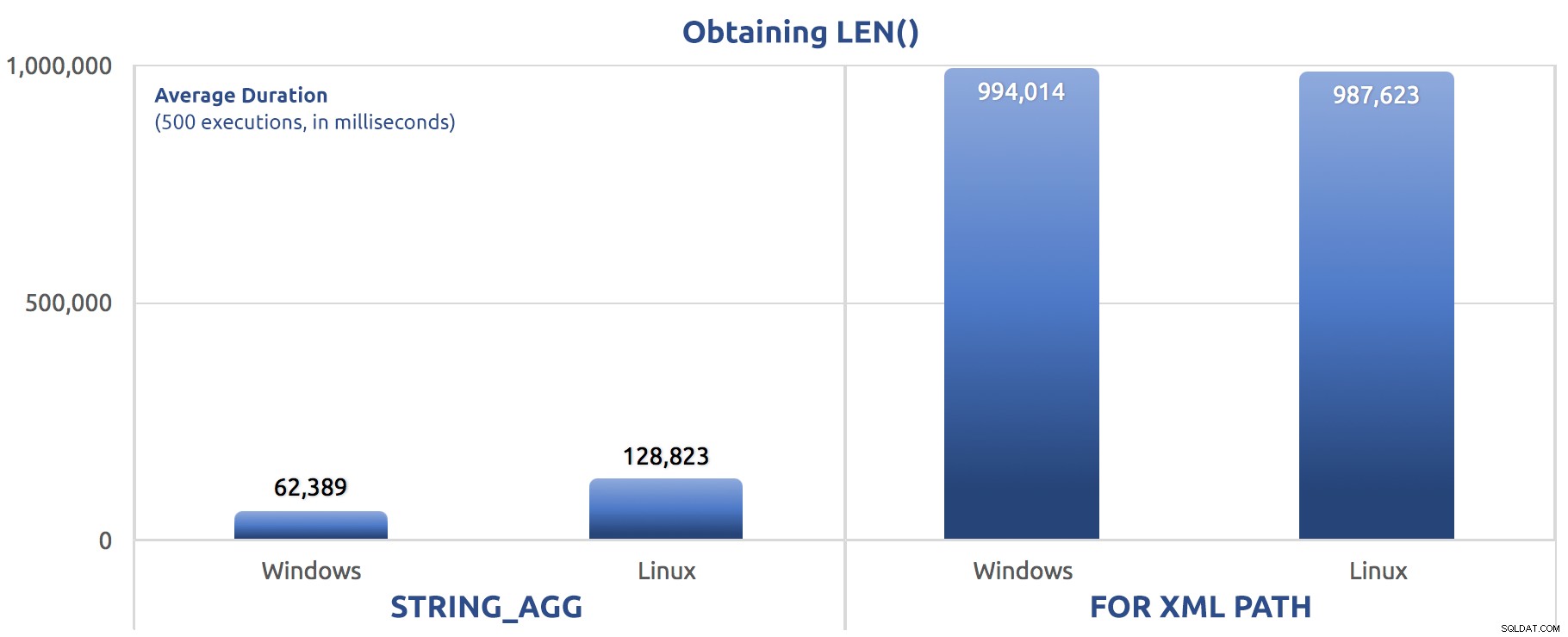 500 esecuzioni di assegnazione di LEN() a una variabile
500 esecuzioni di assegnazione di LEN() a una variabile
Di nuovo, vediamo FOR XML PATH è molto più lento, sia su Windows che su Linux.
Selezione della lunghezza massima dell'uscita
Una leggera variazione rispetto al test precedente, questo recupera solo il massimo lunghezza dell'output concatenato:
SET STATISTICS TIME ON;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STUFF(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 188 ms, elapsed time = 48 ms.
FOR XML PATH: CPU time = 1891 ms, elapsed time = 907 ms.
Linux:
STRING_AGG: CPU time = 270 ms, elapsed time = 83 ms.
FOR XML PATH: CPU time = 2725 ms, elapsed time = 1205 ms.
*/ E su larga scala, assegniamo di nuovo quell'output a una variabile:
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STUFF
(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime(); Risultati delle prestazioni, per 500 esecuzioni, in media su tre esecuzioni:
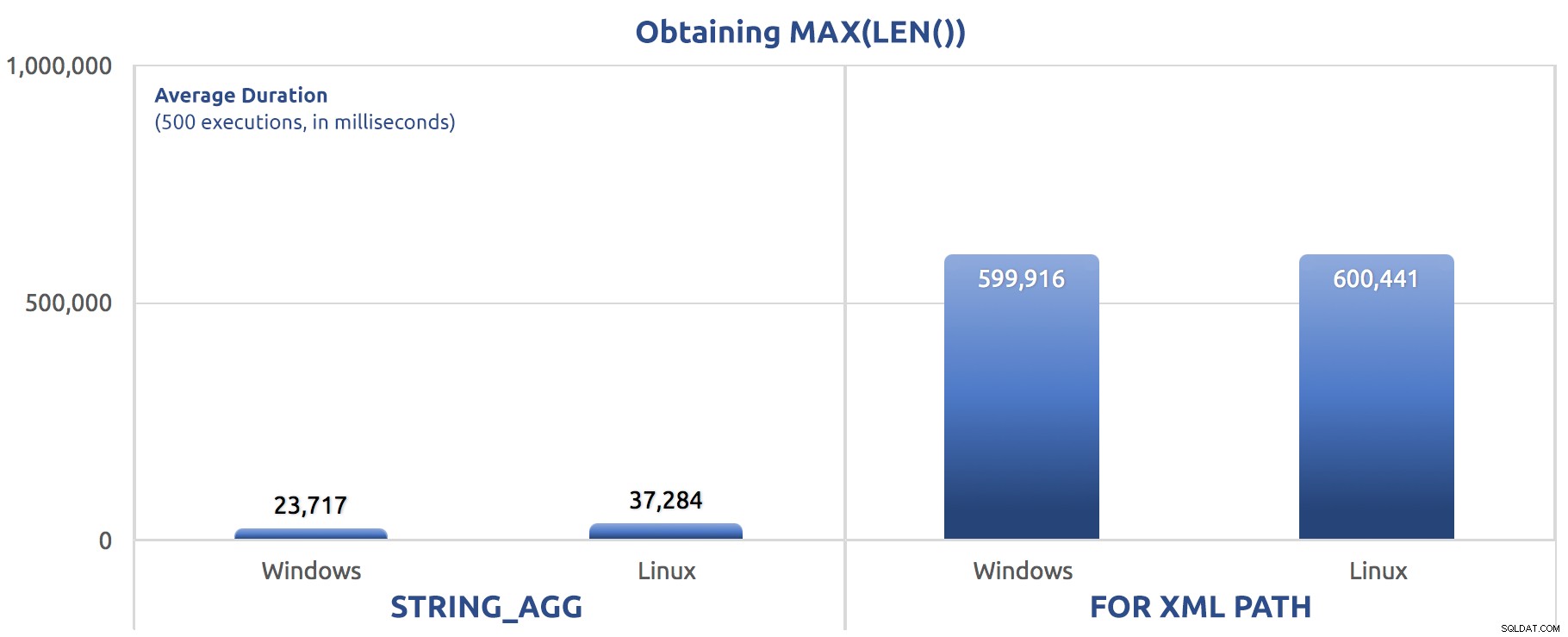 500 esecuzioni di assegnazione di MAX(LEN()) a una variabile
500 esecuzioni di assegnazione di MAX(LEN()) a una variabile
Potresti iniziare a notare uno schema in questi test:FOR XML PATH è sempre un cane, anche con i miglioramenti prestazionali suggeriti nel mio post precedente.
SELEZIONA IN
Volevo vedere se il metodo di concatenazione ha avuto un impatto sulla scrittura i dati tornano su disco, come nel caso di altri scenari:
SET NOCOUNT ON;
GO
SET STATISTICS TIME ON;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_AGG;
SELECT o.OrderID, x = STRING_AGG(ol.StockItemID, ',')
INTO dbo.HoldingTank_AGG
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_XML;
SELECT o.OrderID, x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
INTO dbo.HoldingTank_XML
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 218 ms, elapsed time = 90 ms.
FOR XML PATH: CPU time = 4202 ms, elapsed time = 1520 ms.
Linux:
STRING_AGG: CPU time = 277 ms, elapsed time = 108 ms.
FOR XML PATH: CPU time = 4308 ms, elapsed time = 1583 ms.
*/
In questo caso vediamo che forse SELECT INTO è stato in grado di sfruttare un po' di parallelismo, ma vediamo ancora FOR XML PATH lotta, con tempi di esecuzione un ordine di grandezza più lunghi di STRING_AGG .
La versione in batch ha appena sostituito i comandi SET STATISTICS con SELECT sysdatetime(); e aggiunto lo stesso GO 500 dopo i due lotti principali come per le prove precedenti. Ecco come è andata a finire (di nuovo, dimmi se l'hai già sentito prima):
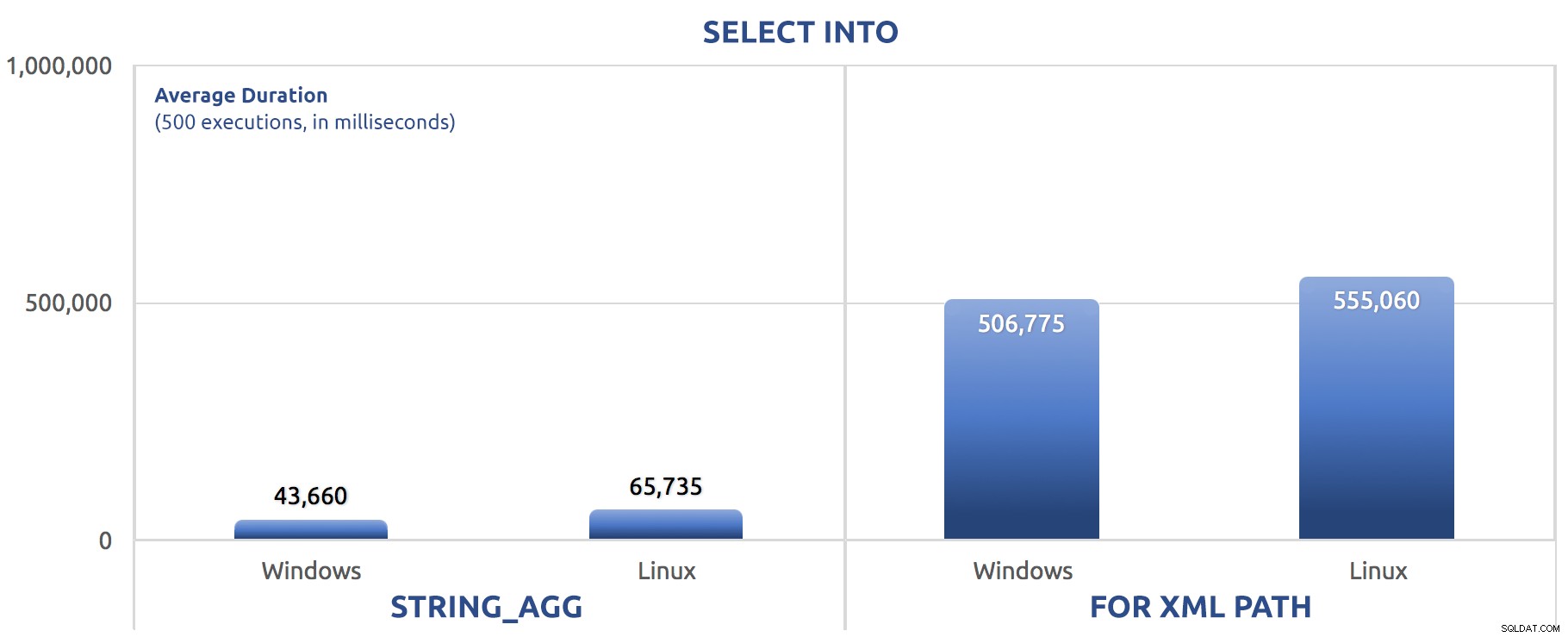 500 esecuzioni di SELECT INTO
500 esecuzioni di SELECT INTO
Test ordinati
Ho eseguito gli stessi test utilizzando la sintassi ordinata, ad esempio:
... STRING_AGG(ol.StockItemID, ',')
WITHIN GROUP (ORDER BY ol.StockItemID) ...
... WHERE ol.OrderID = o.OrderID
ORDER BY ol.StockItemID
FOR XML PATH('') ... Ciò ha avuto un impatto minimo su qualsiasi cosa:lo stesso set di quattro banchi di prova ha mostrato parametri e modelli quasi identici su tutta la linea.
Sarò curioso di vedere se questo è diverso quando l'output concatenato è in non-LOB o dove la concatenazione deve ordinare le stringhe (con o senza un indice di supporto).
Conclusione
Per stringhe non LOB , mi è chiaro che STRING_AGG ha un vantaggio in termini di prestazioni definitivo rispetto a FOR XML PATH , sia su Windows che su Linux. Nota che, per evitare il requisito di varchar(max) o nvarchar(max) , non ho usato nulla di simile ai test eseguiti da Grzegorz, il che avrebbe significato semplicemente concatenare tutti i valori di una colonna, su un'intera tabella, in un'unica stringa. Nel mio prossimo post, darò un'occhiata al caso d'uso in cui l'output della stringa concatenata potrebbe essere fattibilmente maggiore di 8.000 byte e quindi dovrebbero essere utilizzati tipi e conversioni LOB.