Sebbene SQL Server su Linux abbia rubato quasi tutti i titoli dei giornali su v.Next, ci sono altri interessanti progressi in arrivo nella prossima versione della nostra piattaforma di database preferita. Sul fronte T-SQL, abbiamo finalmente un modo integrato per eseguire la concatenazione di stringhe raggruppate:STRING_AGG() .
Supponiamo di avere la seguente semplice struttura a tabella:
CREATE TABLE dbo.Objects
(
[object_id] int,
[object_name] nvarchar(261),
CONSTRAINT PK_Objects PRIMARY KEY([object_id])
);
CREATE TABLE dbo.Columns
(
[object_id] int NOT NULL
FOREIGN KEY REFERENCES dbo.Objects([object_id]),
column_name sysname,
CONSTRAINT PK_Columns PRIMARY KEY ([object_id],column_name)
);
Per i test delle prestazioni, lo compileremo utilizzando sys.all_objects e sys.all_columns . Ma prima per una semplice dimostrazione, aggiungiamo le seguenti righe:
INSERT dbo.Objects([object_id],[object_name])
VALUES(1,N'Employees'),(2,N'Orders');
INSERT dbo.Columns([object_id],column_name)
VALUES(1,N'EmployeeID'),(1,N'CurrentStatus'),
(2,N'OrderID'),(2,N'OrderDate'),(2,N'CustomerID'); Se i forum sono indicativi, è un requisito molto comune restituire una riga per ogni oggetto, insieme a un elenco di nomi di colonna separati da virgole. (Estrailo a qualsiasi tipo di entità modelli in questo modo:nomi di prodotti associati a un ordine, nomi di parti coinvolti nell'assemblaggio di un prodotto, subordinati che riferiscono a un manager, ecc.) Quindi, ad esempio, con i dati di cui sopra avremmo vuoi un output come questo:
object columns --------- ---------------------------- Employees EmployeeID,CurrentStatus Orders OrderID,OrderDate,CustomerID
Il modo in cui lo faremmo nelle versioni attuali di SQL Server è probabilmente usare FOR XML PATH , come ho dimostrato di essere il più efficiente al di fuori di CLR in questo post precedente. In questo esempio, sarebbe simile a questo:
SELECT [object] = o.[object_name],
[columns] = STUFF(
(SELECT N',' + c.column_name
FROM dbo.Columns AS c
WHERE c.[object_id] = o.[object_id]
FOR XML PATH, TYPE
).value(N'.[1]',N'nvarchar(max)'),1,1,N'')
FROM dbo.Objects AS o; Com'era prevedibile, otteniamo lo stesso output mostrato sopra. In SQL Server v.Next, saremo in grado di esprimerlo in modo più semplice:
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];
Ancora una volta, questo produce esattamente lo stesso output. E siamo stati in grado di farlo con una funzione nativa, evitando sia il costoso FOR XML PATH impalcatura e STUFF() funzione utilizzata per rimuovere la prima virgola (questo avviene automaticamente).
E l'ordine?
Uno dei problemi con molte delle soluzioni kludge alla concatenazione di gruppi è che l'ordinamento dell'elenco separato da virgole dovrebbe essere considerato arbitrario e non deterministico.
Per il XML PATH soluzione, ho dimostrato in un altro post precedente che l'aggiunta di un ORDER BY è banale e garantito. Quindi, in questo esempio, potremmo ordinare l'elenco delle colonne in base al nome della colonna in ordine alfabetico invece di lasciarlo a SQL Server per ordinare (o meno):
SELECT [object] = [object_name],
[columns] = STUFF(
(SELECT N',' +c.column_name
FROM dbo.Columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY c.column_name -- only change
FOR XML PATH, TYPE
).value(N'.[1]',N'nvarchar(max)'),1,1,N'')
FROM dbo.Objects AS o; Uscita:
object columns --------- ---------------------------- Employees CurrentStatus,EmployeeID Order CustomerID,OrderDate,OrderID
CTP 1.1 aggiunge WITHIN GROUP a STRING_AGG() , quindi usando il nuovo approccio, possiamo dire:
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
WITHIN GROUP (ORDER BY c.column_name) -- only change
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];
Ora otteniamo gli stessi risultati. Nota che, proprio come un normale ORDER BY clausola, puoi aggiungere più colonne o espressioni di ordinamento all'interno di WITHIN GROUP () .
Va bene, già prestazioni!
Utilizzando processori quad-core da 2,6 GHz, 8 GB di memoria e SQL Server CTP1.1 (14.0.100.187), ho creato un nuovo database, ricreato queste tabelle e aggiunto righe da sys.all_objects e sys.all_columns . Mi sono assicurato di includere solo oggetti che avevano almeno una colonna:
INSERT dbo.Objects([object_id], [object_name]) -- 656 rows
SELECT [object_id], QUOTENAME(s.name) + N'.' + QUOTENAME(o.name)
FROM sys.all_objects AS o
INNER JOIN sys.schemas AS s
ON o.[schema_id] = s.[schema_id]
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns
WHERE [object_id] = o.[object_id]
);
INSERT dbo.Columns([object_id], column_name) -- 8,085 rows
SELECT [object_id], name
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.Objects
WHERE [object_id] = c.[object_id]
); Sul mio sistema, questo ha prodotto 656 oggetti e 8.085 colonne (il tuo sistema potrebbe produrre numeri leggermente diversi).
I piani
Innanzitutto, confrontiamo i piani e le schede I/O tabella per le nostre due query non ordinate, utilizzando Plan Explorer. Ecco le metriche generali di runtime:
 Metriche di runtime per XML PATH (in alto) e STRING_AGG() (in basso)
Metriche di runtime per XML PATH (in alto) e STRING_AGG() (in basso)
Il piano grafico e l'I/O della tabella da FOR XML PATH domanda:
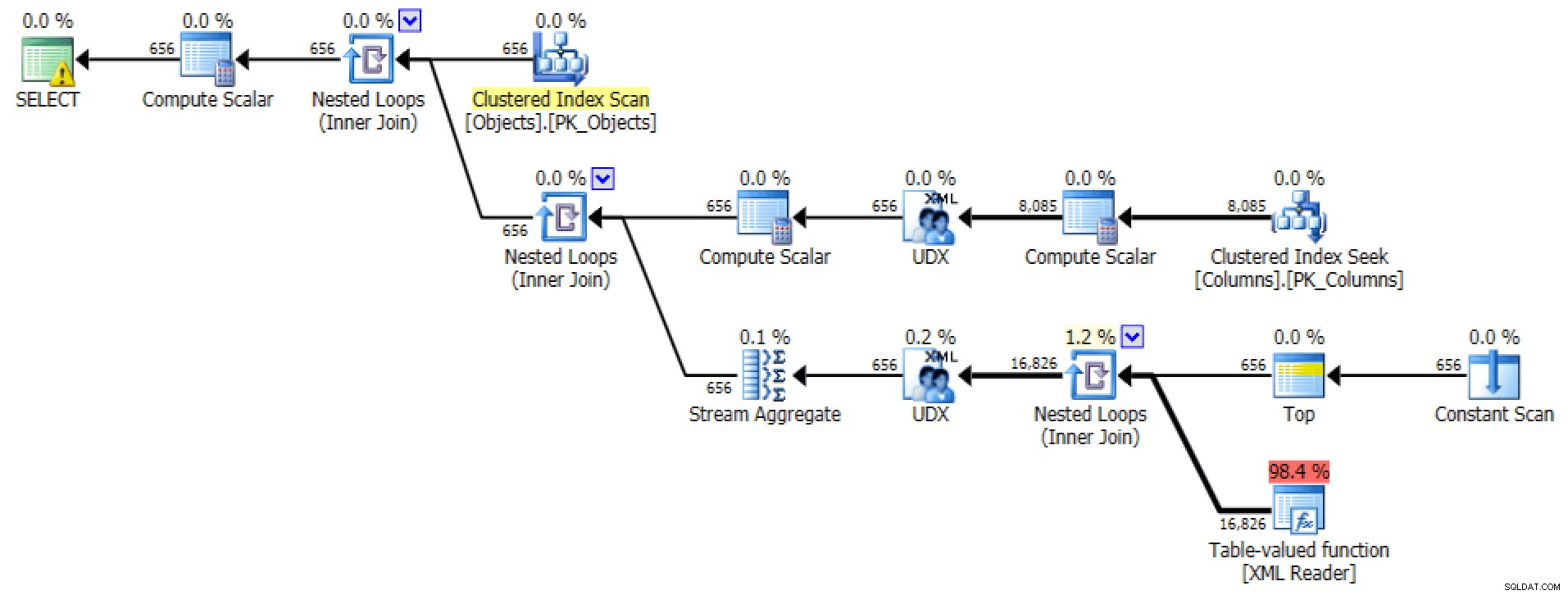
 I/O del piano e della tabella per XML PATH, nessun ordine
I/O del piano e della tabella per XML PATH, nessun ordine
E dal STRING_AGG versione:
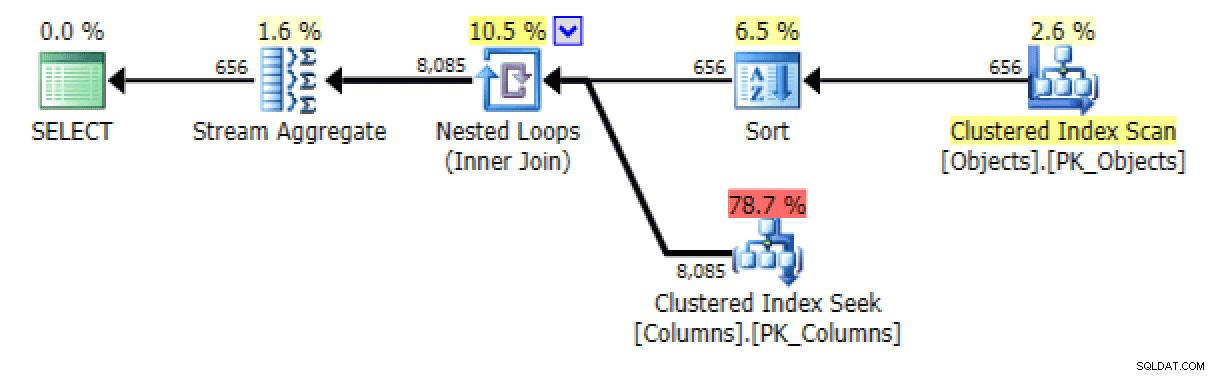
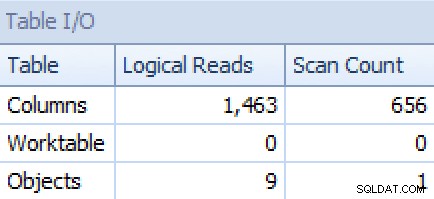 I/O del piano e della tabella per STRING_AGG, nessun ordine
I/O del piano e della tabella per STRING_AGG, nessun ordine
Per quest'ultimo, la ricerca dell'indice cluster mi sembra un po' preoccupante. Questo sembrava un buon caso per testare il FORCESCAN usato di rado suggerimento (e no, questo non aiuterebbe certamente il FOR XML PATH domanda):
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c WITH (FORCESCAN) -- added hint
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name]; Ora il piano e la scheda Table I/O sembrano molto molto meglio, almeno a prima vista:
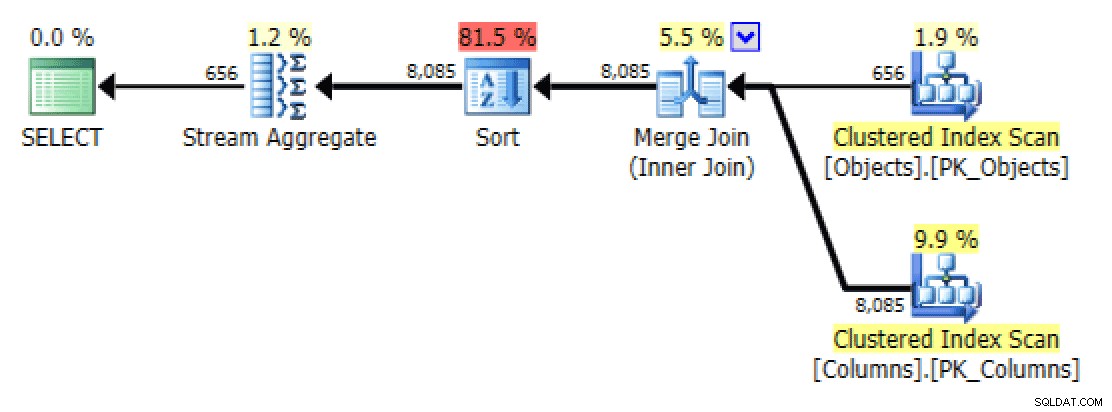
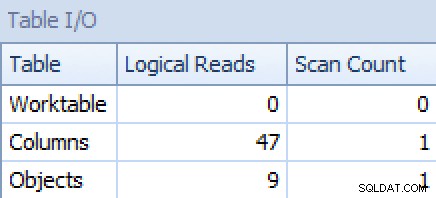 I/O del piano e della tabella per STRING_AGG(), nessun ordinamento, con FORCESCAN
I/O del piano e della tabella per STRING_AGG(), nessun ordinamento, con FORCESCAN
Le versioni ordinate delle query generano all'incirca gli stessi piani. Per il FOR XML PATH versione, viene aggiunto un ordinamento:
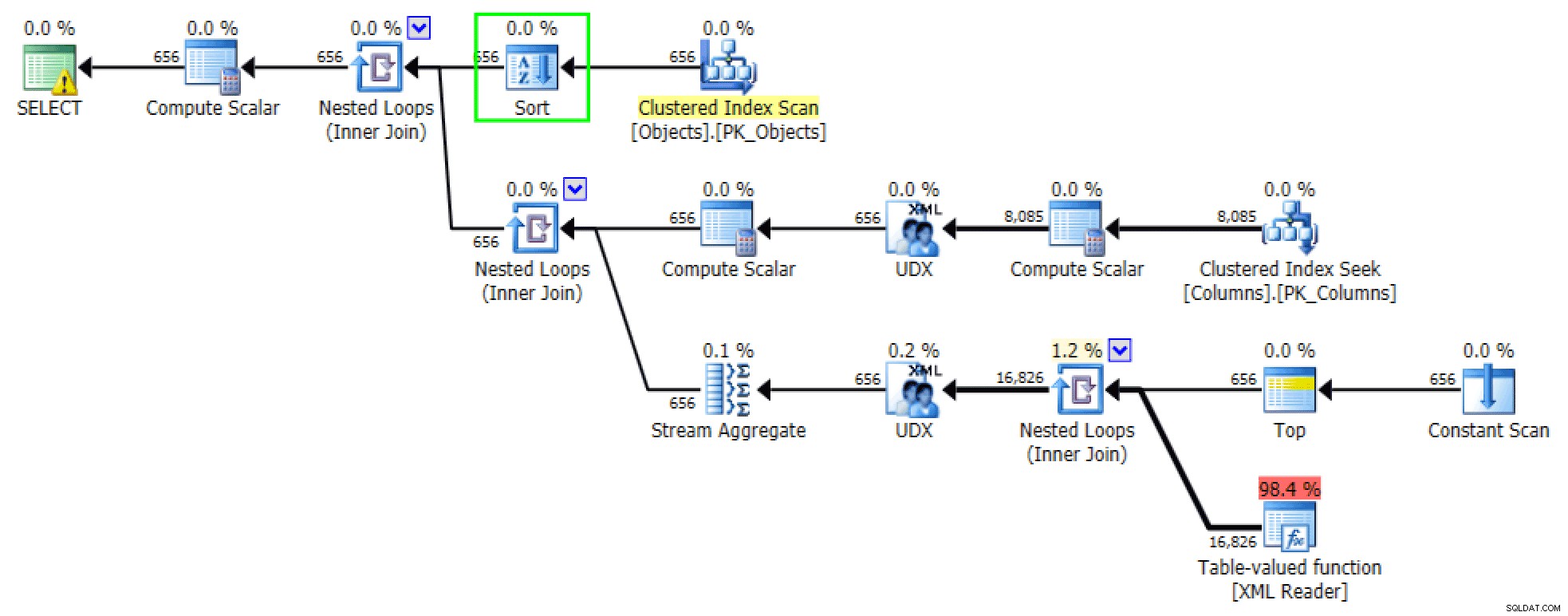 Aggiunto l'ordinamento nella versione FOR XML PATH
Aggiunto l'ordinamento nella versione FOR XML PATH
Per STRING_AGG() , in questo caso viene scelta una scansione, anche senza il FORCESCAN suggerimento e non è richiesta alcuna operazione di ordinamento aggiuntiva, quindi il piano sembra identico a FORCESCAN versione.
Su larga scala
L'esame di un piano e delle metriche di runtime una tantum potrebbe darci un'idea se STRING_AGG() funziona meglio dell'esistente FOR XML PATH soluzione, ma un test più ampio potrebbe avere più senso. Cosa succede quando eseguiamo la concatenazione raggruppata 5.000 volte?
SELECT SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, unordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c WITH (FORCESCAN) ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, unordered, forcescan] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] = o.[object_id] FOR XML PATH, TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'') FROM dbo.Objects AS o; GO 5000 SELECT [for xml path, unordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') WITHIN GROUP (ORDER BY c.column_name) FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, ordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] = o.[object_id] ORDER BY c.column_name FOR XML PATH, TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'') FROM dbo.Objects AS o ORDER BY o.[object_name]; GO 5000 SELECT [for xml path, ordered] = SYSDATETIME();
Dopo aver eseguito questo script cinque volte, ho calcolato la media dei numeri di durata ed ecco i risultati:
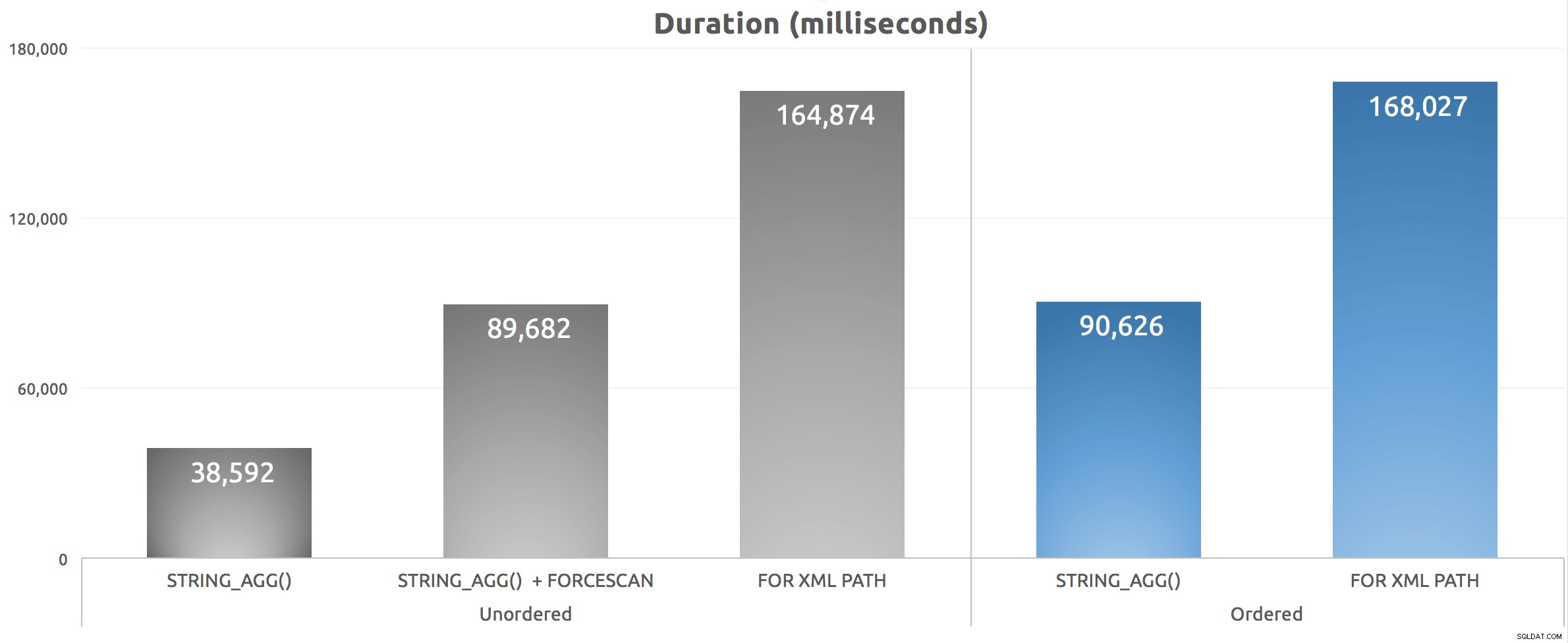 Durata (millisecondi) per vari approcci di concatenazione di gruppi
Durata (millisecondi) per vari approcci di concatenazione di gruppi
Possiamo vedere che il nostro FORCESCAN hint ha davvero peggiorato le cose:mentre abbiamo spostato il costo lontano dalla ricerca di indici raggruppati, l'ordinamento era in realtà molto peggiore, anche se i costi stimati li consideravano relativamente equivalenti. Ancora più importante, possiamo vedere che STRING_AGG() offre un vantaggio in termini di prestazioni, indipendentemente dal fatto che le stringhe concatenate debbano essere ordinate o meno in un modo specifico. Come con STRING_SPLIT() , che ho esaminato a marzo, sono piuttosto impressionato dal fatto che questa funzione si ridimensiona bene prima della "v1".
Ho in programma ulteriori test, magari per un post futuro:
- Quando tutti i dati provengono da un'unica tabella, con e senza un indice che supporta l'ordinamento
- Test di prestazioni simili su Linux
Nel frattempo, se hai casi d'uso specifici per la concatenazione di gruppi, condividili di seguito (o inviami un'e-mail a abertrand@sentryone.com). Sono sempre aperto ad assicurarmi che i miei test siano il più possibile reali.