Secondo Wikipedia, "Un inserto in blocco è un processo o un metodo fornito da un sistema di gestione del database per caricare più righe di dati in una tabella del database". Se modifichiamo questa spiegazione in base all'istruzione BULK INSERT, l'inserimento in blocco consente di importare file di dati esterni in SQL Server. Supponiamo che la nostra organizzazione abbia un file CSV di 1.500.000 righe e vogliamo importare questo file in una tabella particolare in SQL Server, in modo da poter utilizzare facilmente l'istruzione BULK INSERT in SQL Server. Certamente, possiamo trovare diverse metodologie di importazione per gestire questo processo di importazione di file CSV, ad es. possiamo usare bcp (b ulk c opy p programma), Importazione ed esportazione guidata di SQL Server o pacchetto del servizio di integrazione di SQL Server. Tuttavia, l'istruzione BULK INSERT è molto più veloce e affidabile rispetto all'utilizzo di altre metodologie. Un altro vantaggio dell'istruzione di inserimento in blocco è che offre diversi parametri che aiutano a determinare le impostazioni del processo di inserimento in blocco.
Inizialmente, inizieremo un campione molto semplice e poi analizzeremo vari scenari sofisticati.
Preparazione
Prima di iniziare i campioni, abbiamo bisogno di un file CSV di esempio. Pertanto, scaricheremo un file CSV di esempio dal sito Web E per Excel, dove puoi trovare vari file CSV campionati con un numero di riga diverso. Potete trovare il link alla fine dell'articolo. Nei nostri scenari utilizzeremo 1.500.000 record di vendita. Scarica un file zip, quindi decomprimi il file CSV e inseriscilo nell'unità locale.

Importa file CSV nella tabella di SQL Server
Scenario-1:destinazione e file CSV hanno lo stesso numero di colonne
In questo primo scenario, importeremo il file CSV nella tabella di destinazione nella forma più semplice. Ho posizionato il mio file CSV di esempio sull'unità C:e ora creeremo una tabella in cui importeremo i dati dal file CSV.
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
La seguente istruzione BULK INSERT importa il file CSV nella tabella Sales.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
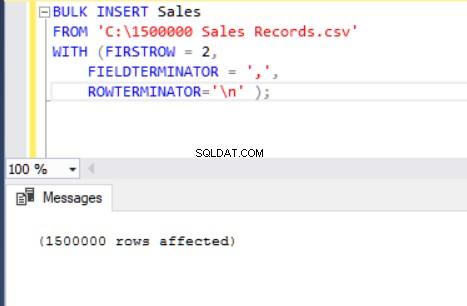
Ora spiegheremo i parametri dell'istruzione di inserimento collettivo sopra.
Il parametro FIRSTROW specifica il punto iniziale dell'istruzione insert. Nell'esempio seguente, vogliamo saltare le intestazioni di colonna, quindi impostiamo questo parametro su 2.

FIELDTERMINATOR definisce il carattere che separa i campi l'uno dall'altro. SQL Server rileva ogni campo in questo modo. ROWTERMINATOR non differisce molto da FIELDTERMINATOR. Definisce il carattere di separazione delle righe. Nel file CSV di esempio, fieldterminator è molto chiaro ed è una virgola (,). Ma come possiamo rilevare un terminatore di campo? Apri il file CSV in Notepad++ e vai su Visualizza->Mostra simbolo->Mostra tutti i documenti, quindi scopri i caratteri CRLF alla fine di ogni campo.
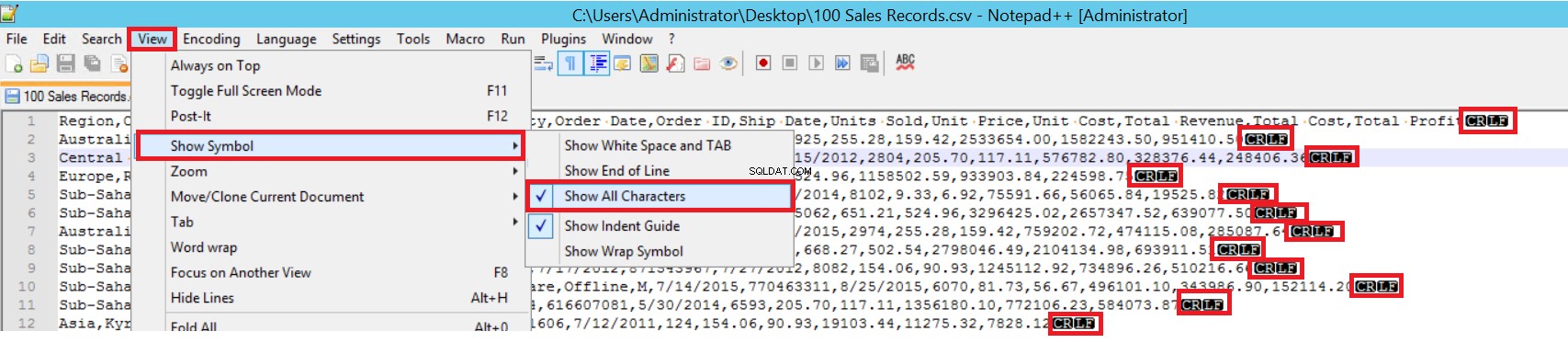
CR =Carriage Return e LF =Line Feed. Sono utilizzati per contrassegnare un'interruzione di riga in un file di testo ed è indicata dal carattere "\n" nell'istruzione di inserimento collettivo.
Un altro metodo per importare un file CSV in una tabella con l'aiuto dell'inserimento in blocco consiste nell'usare il parametro FORMAT. Tieni presente che il parametro FORMAT è disponibile solo in SQL Server 2017 e versioni successive.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
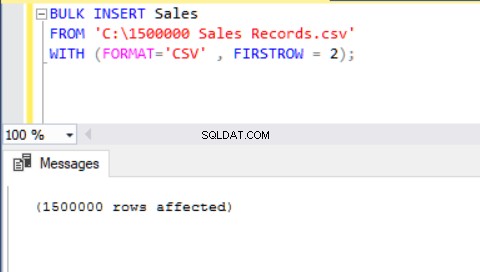
Ora analizzeremo un altro scenario.
Scenario-2:la tabella di destinazione ha più colonne del file CSV
In questo scenario, aggiungeremo una chiave primaria alla tabella Sales e questo caso interromperà i mapping delle colonne di uguaglianza. Ora creeremo la tabella Sales con una chiave primaria, proveremo a importare il file CSV tramite il comando di inserimento collettivo e quindi riceveremo un errore.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
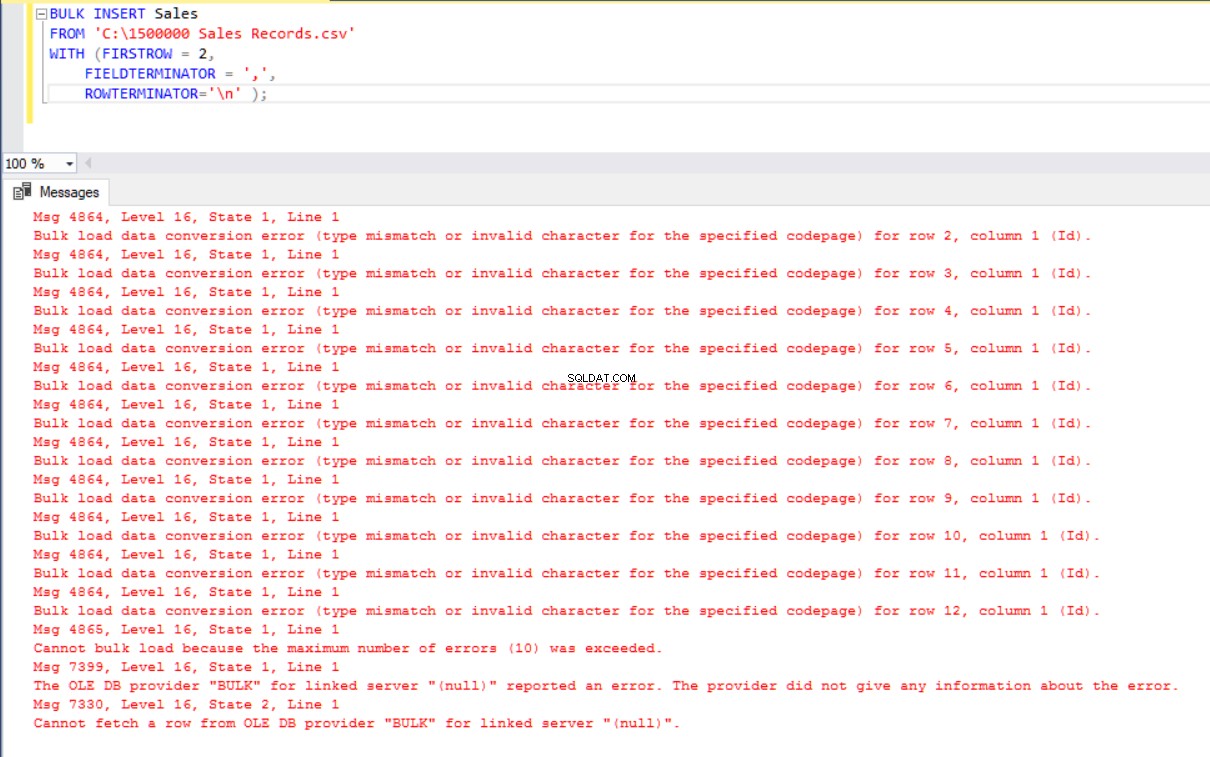
Per ovviare a questo errore, creeremo una vista della tabella Vendite con la mappatura delle colonne nel file CSV e importeremo i dati CSV su questa vista nella tabella Vendite.
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Scenario-3:come separare e caricare file CSV in batch di piccole dimensioni?
SQL Server acquisisce un blocco nella tabella di destinazione durante l'operazione di inserimento in blocco. Per impostazione predefinita, se non si imposta il parametro BATCHSIZE, SQL Server apre una transazione e inserisce tutti i dati CSV in questa transazione. Tuttavia, se si imposta il parametro BATCHSIZE, SQL Server divide i dati CSV in base a questo valore del parametro. Nell'esempio seguente, divideremo tutti i dati CSV in diversi set di 300.000 righe ciascuno. Pertanto i dati verranno importati 5 volte.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 );
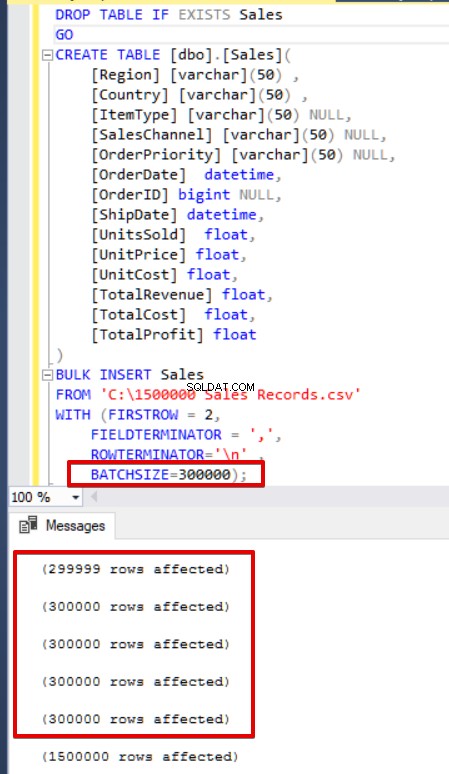
Se l'istruzione di inserimento in blocco non include il parametro della dimensione batch (BATCHSIZE), si verificherà un errore e SQL Server eseguirà il rollback dell'intero processo di inserimento in blocco. Se invece si imposta il parametro della dimensione batch sull'istruzione di inserimento in blocco, SQL Server eseguirà il rollback solo di questa parte divisa in cui si è verificato l'errore. Non esiste un valore ottimale o migliore per questo parametro perché questo valore del parametro può essere modificato in base ai requisiti di sistema del database.
Scenario-4:come annullare il processo di importazione quando viene visualizzato un errore?
In alcuni scenari di copia in blocco, se si verifica un errore, potremmo voler annullare il processo di copia in blocco o continuare il processo. Il parametro MAXERRORS consente di specificare il numero massimo di errori. Se il processo di inserimento in blocco raggiunge questo valore di errore massimo, l'operazione di importazione in blocco verrà annullata e verrà eseguito il rollback. Il valore predefinito per questo parametro è 10.
Nell'esempio seguente, corromperemo intenzionalmente il tipo di dati in 3 righe del file CSV e imposteremo il parametro MAXERRORS su 2. Di conseguenza, l'intera operazione di inserimento in blocco verrà annullata perché il numero di errore supera il parametro di errore massimo.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2);
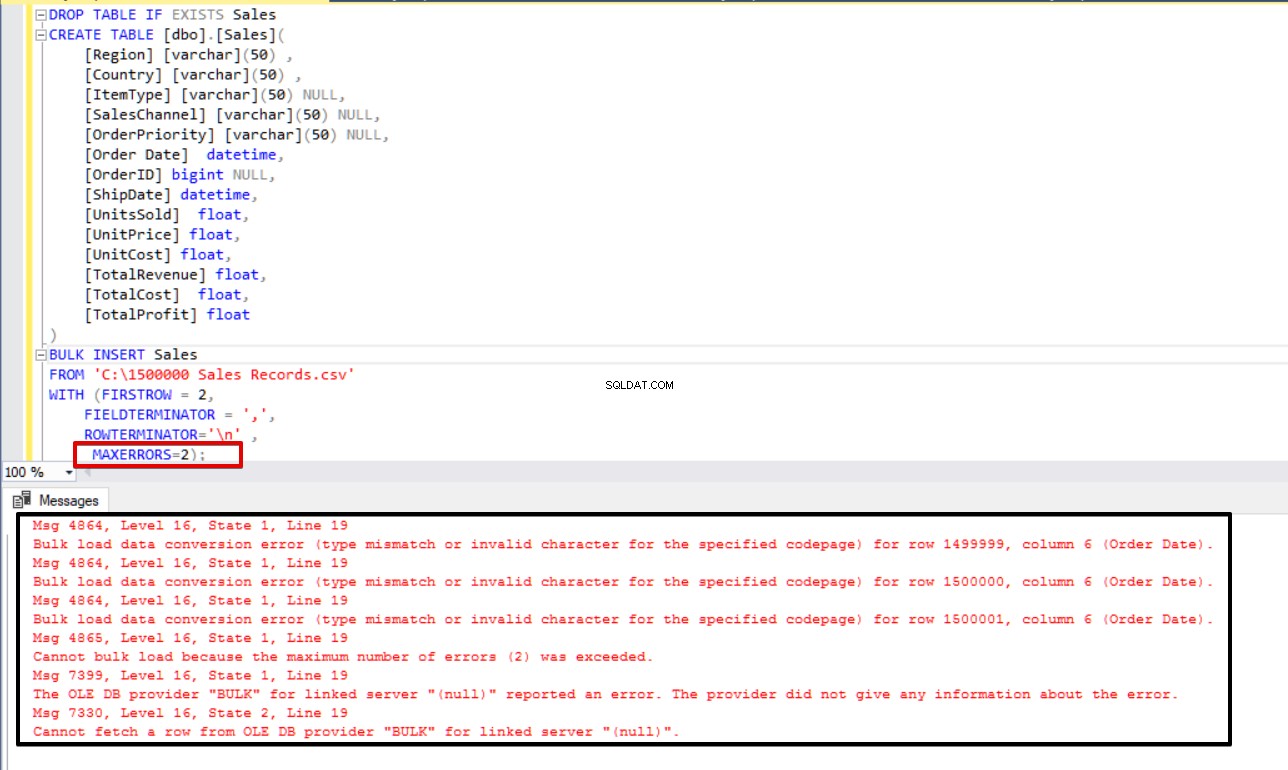
Ora cambieremo il parametro di errore massimo su 4. Di conseguenza, l'istruzione di inserimento collettivo salterà queste righe e inserirà righe strutturate di dati corrette e completerà il processo di inserimento collettivo.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
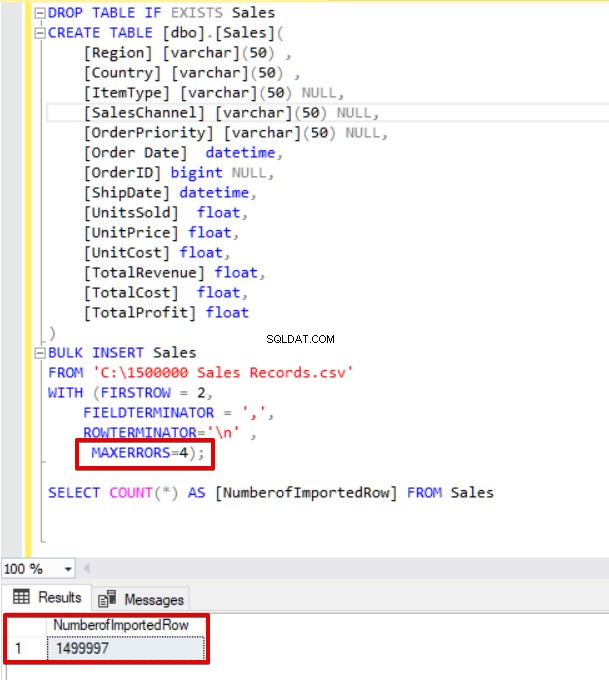
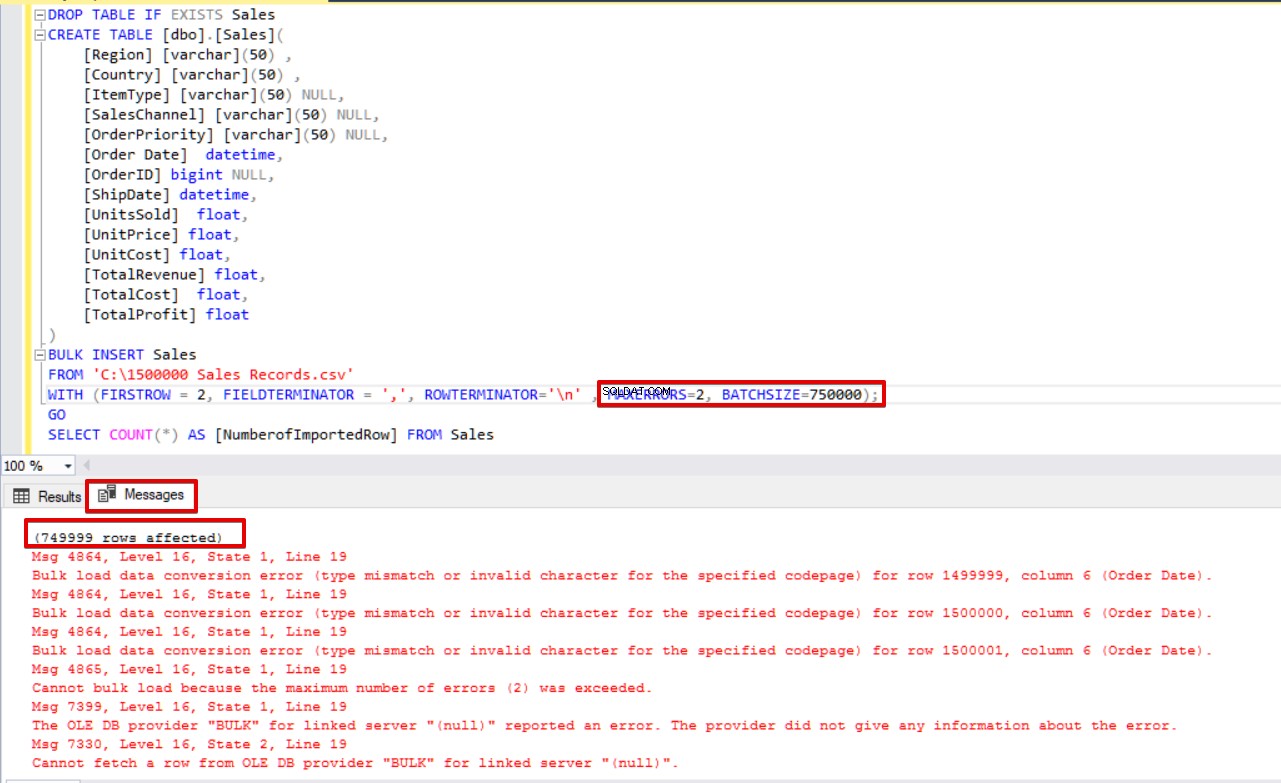
Inoltre, se utilizziamo contemporaneamente sia la dimensione batch che i parametri di errore massimo, il processo di copia in blocco non annullerà l'intera operazione di inserimento, ma annullerà solo la parte divisa.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
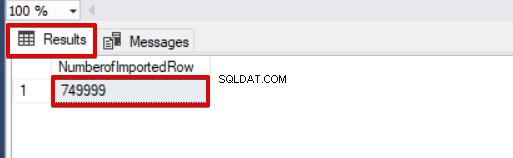
In questa prima parte di questa serie di articoli, abbiamo discusso le basi dell'utilizzo dell'operazione di inserimento in blocco in SQL Server e abbiamo analizzato diversi scenari che sono vicini ai problemi della vita reale.
Inserimento collettivo di SQL Server – Parte 2
Link utili:
Inserto sfuso
E per Excel:file CSV di esempio/set di dati per il test (fino a 1,5 milioni di record)
Scarica Blocco note++
Strumento utile:
dbForge Data Pump:un componente aggiuntivo SSMS per il riempimento di database SQL con dati di origine esterni e la migrazione dei dati tra i sistemi.