Secondo Wikipedia, l'inserimento in blocco è un processo o un metodo fornito da un sistema di gestione del database per caricare più righe di dati in una tabella del database. Se aggiustiamo questa spiegazione all'istruzione BULK INSERT, l'inserimento in blocco consente di importare file di dati esterni in SQL Server.
Si supponga che la nostra organizzazione abbia un file CSV di 1.500.000 righe e che vogliamo importarlo in una tabella particolare in SQL Server per usare l'istruzione BULK INSERT in SQL Server. Possiamo trovare diversi metodi per gestire questo compito. Potrebbe utilizzare BCP (b ulk c opy p programma), Importazione ed esportazione guidata di SQL Server o pacchetto del servizio di integrazione di SQL Server. Tuttavia, l'istruzione BULK INSERT è molto più veloce e potente. Un altro vantaggio è che offre diversi parametri che aiutano a determinare le impostazioni del processo di inserimento in blocco.
Iniziamo con un campione di base. Quindi passeremo attraverso scenari più sofisticati.
Preparazione
Prima di tutto, abbiamo bisogno di un file CSV di esempio. Scarichiamo un file CSV di esempio dal sito Web E for Excel (una raccolta di file CSV campionati con un numero di riga diverso). Qui utilizzeremo 1.500.000 record di vendita.
Scarica un file zip, decomprimilo per ottenere un file CSV e inseriscilo nell'unità locale.
Importa file CSV nella tabella di SQL Server
Importiamo il nostro file CSV nella tabella di destinazione nella forma più semplice. Ho inserito il mio file CSV di esempio sull'unità C:. Ora creiamo una tabella in cui importare i dati del file CSV:
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
La seguente istruzione BULK INSERT importa il file CSV nella tabella Sales:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Probabilmente hai notato i parametri specifici dell'istruzione di inserimento collettivo sopra. Chiariamoli:
- PRIMA specifica il punto iniziale dell'istruzione insert. Nell'esempio seguente, vogliamo saltare le intestazioni di colonna, quindi impostiamo questo parametro su 2.

- FIELDTERMINATOR definisce il carattere che separa i campi l'uno dall'altro. SQL Server rileva ogni campo in questo modo.
- ROWTERMINATOR non differisce molto da FIELDTERMINATOR. Definisce il carattere di separazione delle righe.
Nel file CSV di esempio, FIELDTERMINATOR è molto chiaro ed è una virgola (,). Per rilevare questo parametro, apri il file CSV in Notepad++ e vai a Visualizza -> Mostra simbolo -> Mostra tutti i charter. I caratteri CRLF sono alla fine di ogni campo.
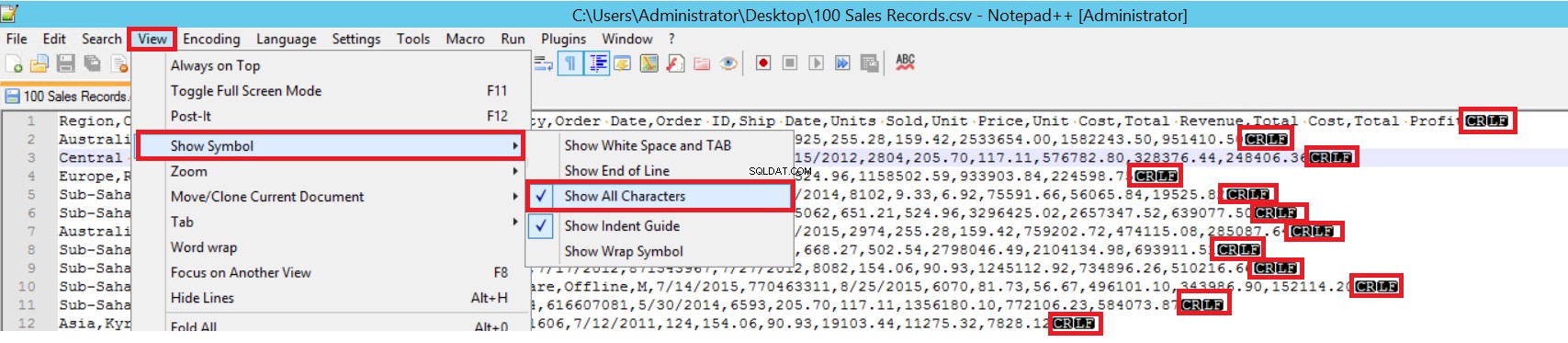
CR =Carriage Return e LF =Line Feed. Vengono utilizzati per contrassegnare un'interruzione di riga in un file di testo. L'indicatore è "\n" nell'istruzione di inserimento collettivo.
Un altro modo per importare un file CSV in una tabella con inserimento in blocco consiste nell'usare il parametro FORMAT. Tieni presente che questo parametro è disponibile solo in SQL Server 2017 e versioni successive.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
Quello era lo scenario più semplice in cui la tabella di destinazione e il file CSV hanno un numero uguale di colonne. Tuttavia, nel caso in cui la tabella di destinazione abbia più colonne, il file CSV è tipico. Consideriamolo.
Aggiungiamo una chiave primaria alla tabella Sales per interrompere le mappature delle colonne di uguaglianza. Creiamo la tabella Sales con una chiave primaria e importiamo il file CSV tramite il comando bulk insert.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Ma produce un errore:
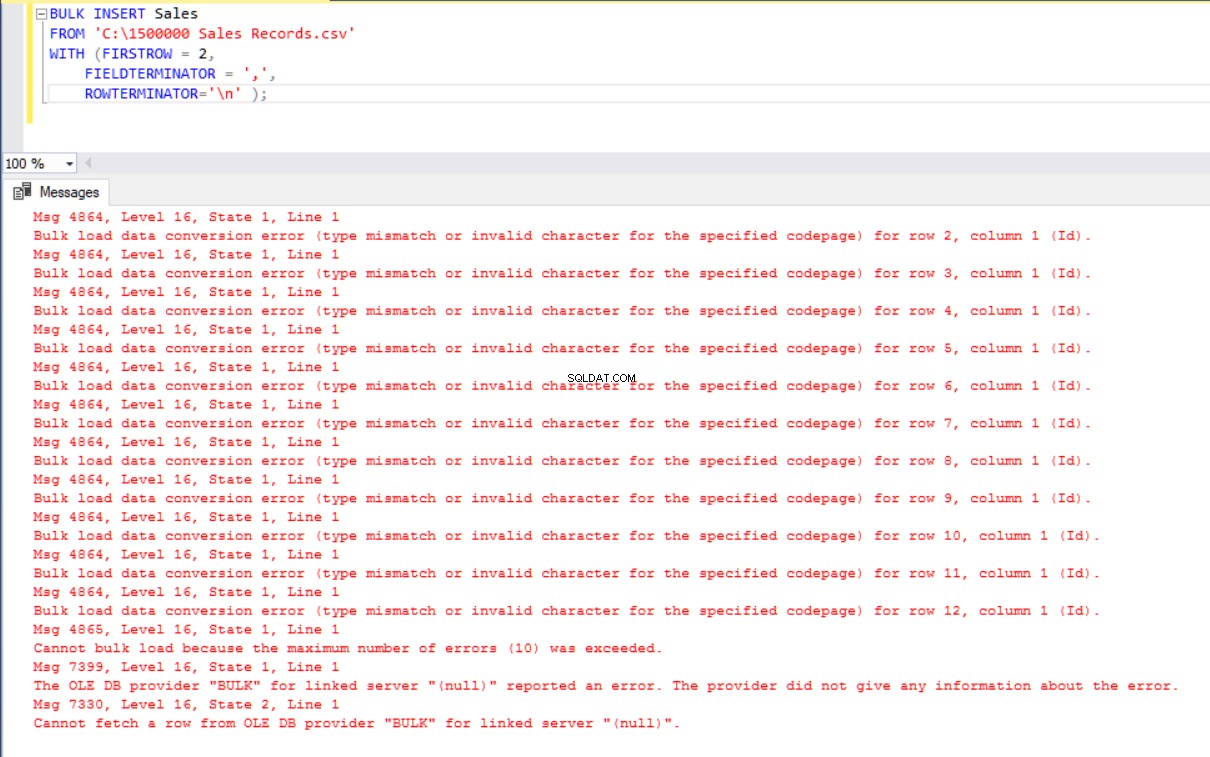
Per ovviare all'errore, creiamo una vista della tabella Sales con la mappatura delle colonne al file CSV. Quindi importiamo i dati CSV su questa vista nella tabella Vendite:
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Separa e carica un file CSV di grandi dimensioni in un batch di piccole dimensioni
SQL Server acquisisce un blocco nella tabella di destinazione durante l'operazione di inserimento in blocco. Per impostazione predefinita, se non si imposta il parametro BATCHSIZE, SQL Server apre una transazione e vi inserisce tutti i dati CSV. Con questo parametro, SQL Server divide i dati CSV in base al valore del parametro.
Dividiamo tutti i dati CSV in diversi set di 300.000 righe ciascuno.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 ); I dati verranno importati cinque volte in parti.
- Se l'istruzione di inserimento in blocco non include il parametro BATCHSIZE, si verificherà un errore e SQL Server eseguirà il rollback dell'intero processo di inserimento in blocco.
- Con questo parametro impostato sull'istruzione di inserimento in blocco, SQL Server esegue il rollback solo della parte in cui si è verificato l'errore.
Non esiste un valore ottimale o migliore per questo parametro perché il suo valore può cambiare in base ai requisiti di sistema del database.
Imposta il comportamento in caso di errori
Se si verifica un errore in alcuni scenari di copia in blocco, potremmo annullare il processo di copia in blocco o continuarlo. Il parametro MAXERRORS consente di specificare il numero massimo di errori. Se il processo di inserimento in blocco raggiunge questo valore di errore massimo, annulla l'operazione di importazione in blocco ed esegue il rollback. Il valore predefinito per questo parametro è 10.
Ad esempio, abbiamo tipi di dati danneggiati in 3 righe del file CSV. Il parametro MAXERRORS è impostato su 2.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2); L'intera operazione di inserimento in blocco verrà annullata perché sono presenti più errori del valore del parametro MAXERRORS.
Se modifichiamo il parametro MAXERRORS su 4, l'istruzione di inserimento collettivo salterà queste righe con errori e inserirà righe strutturate di dati corretti. Il processo di inserimento collettivo sarà completo.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
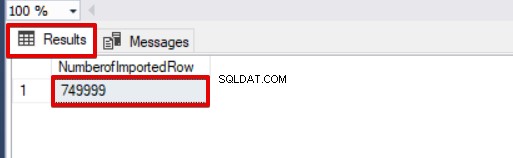
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Se utilizziamo contemporaneamente BATCHSIZE e MAXERRORS, il processo di copia in blocco non annullerà l'intera operazione di inserimento. Cancellerà solo la parte divisa.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Dai un'occhiata all'immagine qui sotto che mostra il risultato dell'esecuzione dello script:
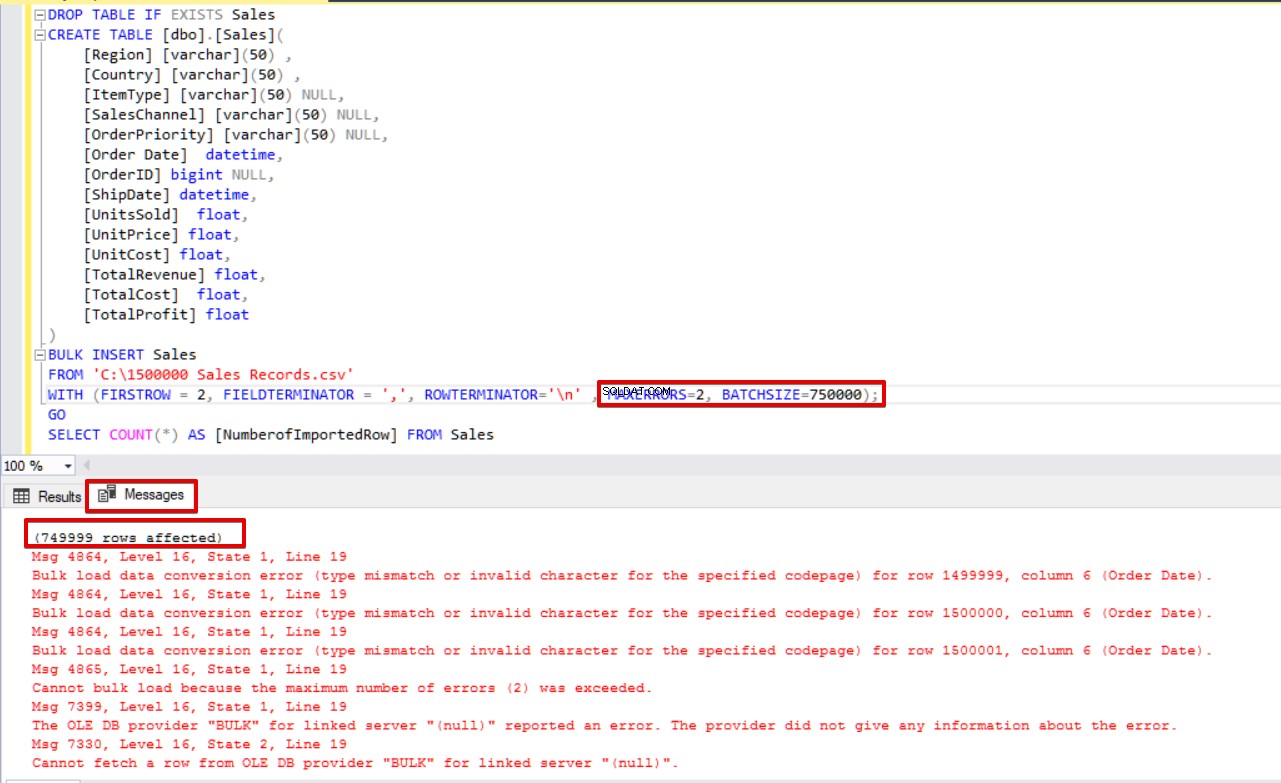
Altre opzioni del processo di inserimento collettivo
FIRE_TRIGGERS:abilita i trigger nella tabella di destinazione durante l'operazione di inserimento in blocco
Per impostazione predefinita, durante il processo di inserimento in blocco, i trigger di inserimento specificati nella tabella di destinazione non vengono attivati. Tuttavia, in alcune situazioni, potremmo voler abilitarli.
La soluzione sta utilizzando l'opzione FIRE_TRIGGERS nelle istruzioni di inserimento in blocco. Ma tieni presente che può influenzare e ridurre le prestazioni dell'operazione di inserimento in blocco. È perché trigger/trigger possono eseguire operazioni separate nel database.
All'inizio, non impostiamo il parametro FIRE_TRIGGERS e il processo di inserimento in blocco non attiverà il trigger di inserimento. Vedi lo script T-SQL di seguito:
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
DROP TABLE IF EXISTS SalesLog
CREATE TABLE SalesLog (OrderIDLog bigint)
GO
CREATE TRIGGER OrderLogIns ON Sales
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO SalesLog
SELECT OrderId from inserted
end
GO
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
SELECT Count(*) FROM SalesLogQuando questo script viene eseguito, il trigger di inserimento non si attiva perché l'opzione FIRE_TRIGGERS non è impostata.
Ora aggiungiamo l'opzione FIRE_TRIGGERS all'istruzione di inserimento collettivo:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n',
FIRE_TRIGGERS);
GO
SELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog 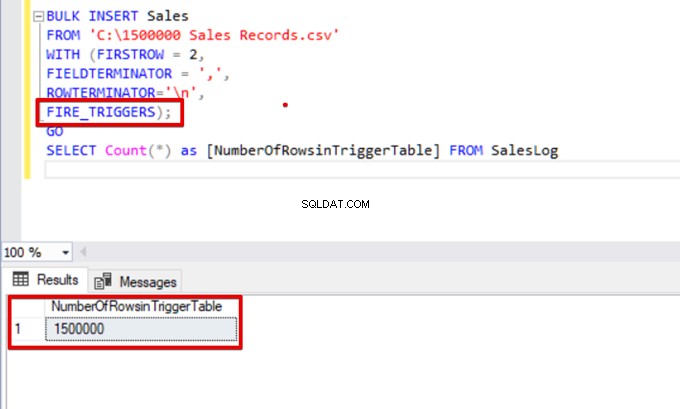
CHECK_CONSTRAINTS:abilita un vincolo di controllo durante l'operazione di inserimento in blocco
I vincoli di controllo ci consentono di imporre l'integrità dei dati nelle tabelle di SQL Server. Lo scopo del vincolo è controllare i valori inseriti, aggiornati o cancellati in base alla loro regolazione sintattica. Ad esempio, il vincolo NOT NULL prevede che il valore NULL non possa modificare una colonna specificata.
Qui, ci concentriamo sui vincoli e sulle interazioni di inserimento collettivo. Per impostazione predefinita, durante il processo di inserimento in blocco, qualsiasi vincolo di controllo e chiave esterna viene ignorato. Ma ci sono alcune eccezioni.
Secondo Microsoft, “i vincoli UNIQUE e PRIMARY KEY vengono sempre applicati. Durante l'importazione in una colonna di caratteri per la quale è definito il vincolo NOT NULL, BULK INSERT inserisce una stringa vuota quando non è presente alcun valore nel file di testo."
Nel seguente script T-SQL, aggiungiamo un vincolo di controllo alla colonna OrderDate, che controlla la data dell'ordine maggiore di 01.01.2016.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_Check
CHECK(OrderDate >'20160101')
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
GO
SELECT COUNT(*) AS [UnChekedData] FROM
Sales WHERE OrderDate <'20160101'Di conseguenza, il processo di inserimento in blocco ignora il controllo del vincolo di controllo. Tuttavia, SQL Server indica il vincolo di controllo come non attendibile:
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'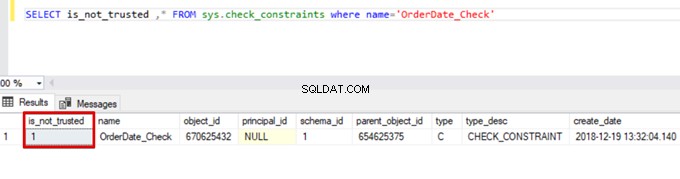
Questo valore indica che qualcuno ha inserito o aggiornato alcuni dati in questa colonna ignorando il vincolo di controllo. Allo stesso tempo, questa colonna può contenere dati incoerenti relativi a tale vincolo.
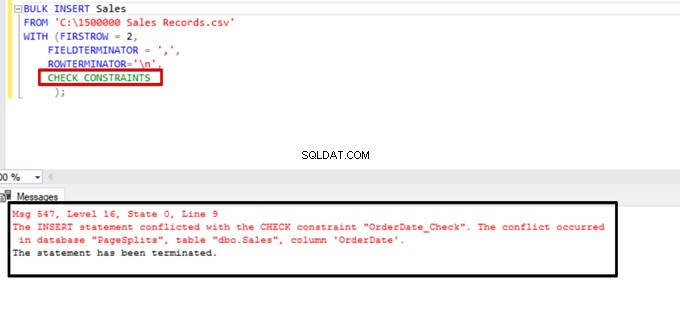
Prova a eseguire l'istruzione di inserimento in blocco con l'opzione CHECK_CONSTRAINTS. Il risultato è semplice:il controllo del vincolo restituisce un errore a causa di dati non corretti.
TABLOCK:aumenta le prestazioni in più inserimenti in blocco in un'unica tabella di destinazione
Lo scopo principale del meccanismo di blocco in SQL Server è proteggere e garantire l'integrità dei dati. Nell'articolo Concetto principale dell'articolo sul blocco di SQL Server è possibile trovare dettagli sul meccanismo di blocco.
Ci concentreremo sui dettagli di blocco del processo di inserimento collettivo.
Se si esegue l'istruzione di inserimento in blocco senza l'opzione TABLELOCK, acquisisce il blocco di righe o tabelle in base alla gerarchia di blocco. Ma in alcuni casi, potremmo voler eseguire più processi di inserimento in blocco su una tabella di destinazione e quindi ridurre il tempo dell'operazione.
Innanzitutto, eseguiamo contemporaneamente due istruzioni di inserimento in blocco e analizziamo il comportamento del meccanismo di blocco. Aprire due finestre di query in SQL Server Management Studio ed eseguire contemporaneamente le seguenti istruzioni di inserimento in blocco.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);Esegui la seguente query DMV (Dynamic Management View):aiuta a monitorare lo stato del processo di inserimento in blocco:
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply
sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle)
where text like '%BULK INSERT Sales%' and session_id <>@@SPID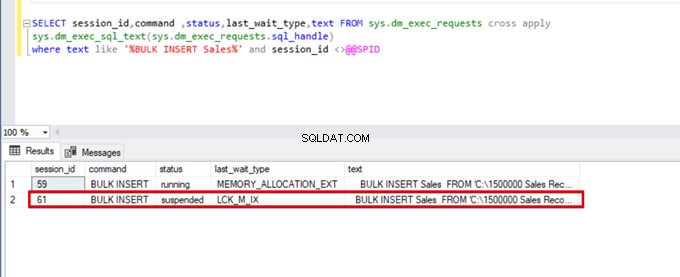
Come puoi vedere nell'immagine sopra, sessione 61, lo stato del processo di inserimento in blocco è sospeso a causa del blocco. Se verifichiamo il problema, la sessione 59 blocca la tabella di destinazione dell'inserimento in blocco. Quindi, la sessione 61 attende il rilascio di questo blocco per continuare il processo di inserimento in blocco.
Ora aggiungiamo l'opzione TABLOCK alle istruzioni di inserimento in blocco ed eseguiamo le query.
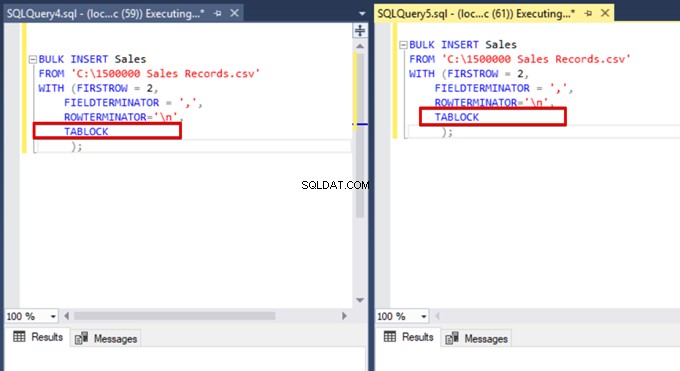
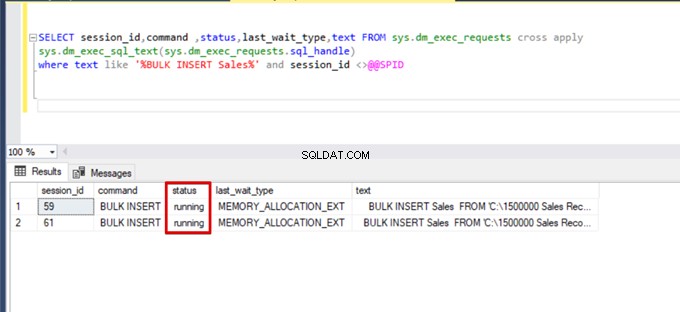
Quando si esegue nuovamente la query di monitoraggio DMV, non è possibile visualizzare alcun processo di inserimento in blocco sospeso perché SQL Server utilizza un particolare tipo di blocco denominato blocco aggiornamento in blocco (BU). Questo tipo di blocco consente di elaborare più operazioni di inserimento in blocco sulla stessa tabella contemporaneamente. Questa opzione riduce anche il tempo totale del processo di inserimento collettivo.
Quando eseguiamo la seguente query durante il processo di inserimento in blocco, possiamo monitorare i dettagli di blocco e i tipi di blocco:
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()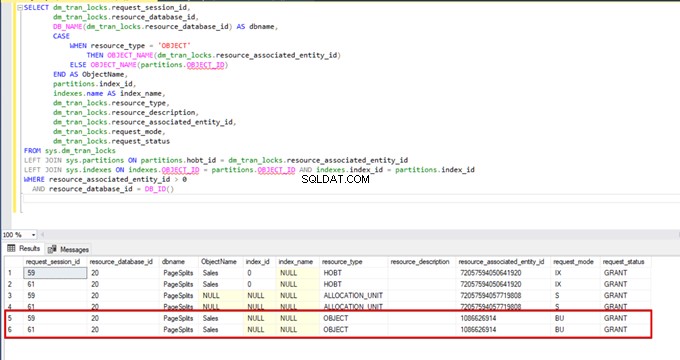
Conclusione
L'articolo corrente ha esplorato tutti i dettagli dell'operazione di inserimento in blocco in SQL Server. In particolare, abbiamo menzionato il comando BULK INSERT e le sue impostazioni e opzioni. Inoltre, abbiamo analizzato vari scenari vicini ai problemi della vita reale.
Strumento utile:
dbForge Data Pump:un componente aggiuntivo SSMS per il riempimento di database SQL con dati di origine esterni e la migrazione dei dati tra i sistemi.