Questo post fornisce nuove informazioni sui presupposti per il carico di massa registrato minimo quando si utilizza INSERT...SELECT in tabelle indicizzate .
La struttura interna che abilita questi casi è denominata FastLoadContext . Può essere attivato da SQL Server 2008 a 2014 compreso utilizzando il flag di traccia documentato 610. Da SQL Server 2016 in poi, FastLoadContext è abilitato per impostazione predefinita; il flag di traccia non è richiesto.
Senza FastLoadContext , gli unici inserti di indice che possono essere minimamente registrati sono quelli in un vuoto indice cluster senza indici secondari, come illustrato nella seconda parte di questa serie. La registrazione minima le condizioni per le tabelle heap non indicizzate sono state trattate nella prima parte.
Per ulteriori informazioni, consulta la Guida al caricamento delle prestazioni dei dati e il Team Tiger note sulle modifiche al comportamento per SQL Server 2016.
Contesto di caricamento rapido
Come rapido promemoria, il RowsetBulk facility (trattato nelle parti 1 e 2) abilita la registrazione minima carico di massa per:
- Heap vuoto e non vuoto tabelle con:
- Blocco del tavolo; e
- Nessun indice secondario.
- Tabelle raggruppate vuote , con:
- Blocco del tavolo; e
- Nessun indice secondario; e
DMLRequestSort=truenell'Inserimento indice cluster operatore.
Il FastLoadContext code path aggiunge il supporto per registrazione minima e simultanei carico di massa su:
- Vuoto e non vuoto raggruppato b-indici ad albero.
- Vuoto e non vuoto non cluster b-tree indici gestiti da un dedicato Inserimento indice operatore del piano.
Il FastLoadContext richiede anche DMLRequestSort=true in ogni caso sull'operatore del piano corrispondente.
Potresti aver notato una sovrapposizione tra RowsetBulk e FastLoadContext per tabelle in cluster vuote senza indici secondari. Un TABLOCK il suggerimento è non richiesto con FastLoadContext , ma non è obbligatorio essere assente o. Di conseguenza, un opportuno inserto con TABLOCK può ancora essere idoneo per registrazione minima tramite FastLoadContext se fallisce il RowsetBulk dettagliato test.
FastLoadContext può essere disabilitato su SQL Server 2016 utilizzando il flag di traccia documentato 692. L'evento esteso del canale di debug fastloadcontext_enabled può essere utilizzato per monitorare FastLoadContext utilizzo per partizione di indice (set di righe). Questo evento non si attiva per RowsetBulk carichi.
Registrazione mista
Un singolo INSERT...SELECT istruzione utilizzando FastLoadContext può registrarsi completamente alcune righe durante la registrazione minima altri.
Le righe vengono inserite una alla volta dall'Inserimento indice operatore e completamente registrato nei seguenti casi:
- Tutte le righe sono state aggiunte alla prima pagina dell'indice, se l'indice era vuoto all'inizio dell'operazione.
- Righe aggiunte a esistenti pagine di indice.
- Righe spostate tra le pagine con una divisione di pagina.
In caso contrario, le righe del flusso di inserimento ordinato vengono aggiunte a una pagina nuova di zecca utilizzando un file ottimizzato e registrato minimamente percorso del codice. Una volta scritte quante più righe possibili nella nuova pagina, questa viene collegata direttamente alla struttura dell'indice di destinazione esistente.
La pagina appena aggiunta non necessariamente essere pieno (anche se ovviamente questo è il caso ideale) perché SQL Server deve fare attenzione a non aggiungere righe alla nuova pagina che appartengono logicamente a un esistente pagina indice. La nuova pagina verrà "cucita" nell'indice come un'unità, quindi non possiamo avere righe sulla nuova pagina che appartengono ad un'altra pagina. Questo è principalmente un problema quando si aggiungono righe all'interno l'intervallo di chiavi dell'indice esistente, anziché prima dell'inizio o dopo la fine dell'intervallo di chiavi dell'indice esistente.
È ancora possibile per aggiungere nuove pagine all'interno l'intervallo di chiavi di indice esistente, ma le nuove righe devono essere ordinate più in alto della chiave più alta nella precedente pagina indice esistente e ordina a un valore inferiore alla chiave più bassa nel seguente pagina di indice esistente. Per avere maggiori possibilità di ottenere una registrazione minima in queste circostanze, assicurarsi che le righe inserite non si sovrappongano il più possibile alle righe esistenti.
Condizioni DMLRequestSort
Ricorda che FastLoadContext può essere attivato solo se DMLRequestSort è impostato su vero per il corrispondente Inserimento indice operatore nel piano di esecuzione.
Esistono due percorsi di codice principali che possono impostare DMLRequestSort a vero per inserti di indice. In entrambi i percorsi restituendo vero è sufficiente.
1. FOptimizeInsert
Il sqllang!CUpdUtil::FOptimizeInsert il codice richiede:
- Più di 250 righe stimato da inserire; e
- Più di 2 pagine stimato inserire la dimensione dei dati; e
- L'indice di destinazione deve avere meno di 3 pagine foglia .
Queste condizioni sono le stesse di RowsetBulk su un indice cluster vuoto, con un requisito aggiuntivo per non più di due pagine a livello di foglia dell'indice. Nota attentamente che questo si riferisce alla dimensione dell'indice esistente prima dell'inserto, non la dimensione stimata dei dati da aggiungere.
Lo script seguente è una modifica della demo utilizzata nelle parti precedenti di questa serie. Mostra registrazione minima quando prima vengono compilate meno di tre pagine di indice il test INSERT...SELECT corre. Lo schema della tabella di test è tale che 130 righe possono rientrare in una singola pagina da 8 KB quando il controllo delle versioni delle righe è disattivato per il database. Il moltiplicatore nel primo TOP La clausola può essere modificata per determinare il numero di pagine di indice esistenti prima il test INSERT...SELECT viene eseguito:
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (3 * 130) -- Change the 3 here
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (269)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
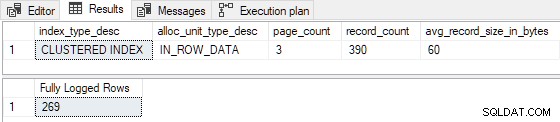
GO Quando l'indice cluster è precaricato con 3 pagine , l'inserto di prova è completamente registrato (record di dettaglio del registro delle transazioni omesso per brevità):
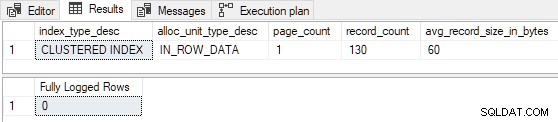
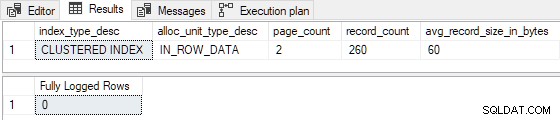
Quando la tabella è precaricata con solo 1 o 2 pagine , l'inserto di prova è registrato minimamente :
Quando la tabella non è precaricata con qualsiasi pagina, il test equivale a eseguire la demo della tabella in cluster vuota della seconda parte, ma senza il TABLOCK suggerimento:
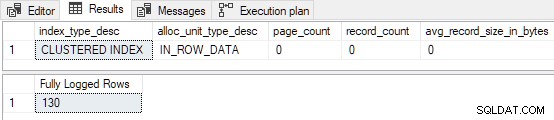
Le prime 130 righe sono completamente registrate . Questo perché l'indice era vuoto prima di iniziare e 130 righe si adattano alla prima pagina. Ricorda, la prima pagina è sempre completamente registrata quando FastLoadContext è utilizzato e l'indice era vuoto in precedenza. Le restanti 139 righe vengono inserite con registrazione minima .
Se un TABLOCK viene aggiunto un suggerimento all'inserto, tutte le pagine vengono registrati minimamente (incluso il primo) poiché il carico dell'indice cluster vuoto ora si qualifica per il RowsetBulk meccanismo (a costo di prendere un Sch-M serratura).
2. FDemandRigheSortedForPerformance
Se il FOptimizeInsert i test falliscono, DMLRequestSort potrebbe essere ancora impostato su true da una seconda serie di test in sqllang!CUpdUtil::FDemandRowsSortedForPerformance codice. Queste condizioni sono un po' più complesse, quindi sarà utile definire alcuni parametri:
P– numero di pagine a livello di foglia esistenti nell'indice di destinazione .I– stimato numero di righe da inserire.R=P/I(pagine di destinazione per riga inserita).T– numero di partizioni di destinazione (1 per non partizionate).
La logica per determinare il valore di DMLRequestSort è quindi:
- Se
P <= 16restituisce falso , altrimenti :- Se
R < 8:- Se
P > 524restituisce vero , altrimenti falso .
- Se
- Se
R >= 8:- Se
T > 1eI > 250restituisce vero , altrimenti falso .
- Se
- Se
I test precedenti vengono valutati dal Query Processor durante la compilazione del piano. Esiste una condizione finale valutato dal codice del motore di archiviazione (IndexDataSetSession::WakeUpInternal ) al momento dell'esecuzione:
DMLRequestSortè attualmente vero; eI >= 100.
Successivamente suddivideremo tutta questa logica in parti gestibili.
Più di 16 pagine target esistenti
Il primo test P <= 16 significa che gli indici con meno di 17 pagine foglia esistenti non si qualificheranno per FastLoadContext tramite questo percorso di codice. Per essere assolutamente chiari su questo punto, P è il numero di pagine a livello di foglia nell'indice di destinazione prima il INSERT...SELECT viene eseguito.
Per dimostrare questa parte della logica, precaricheremo la tabella cluster di test con 16 pagine di dati. Questo ha due effetti importanti (ricorda che entrambi i percorsi del codice devono restituire false per finire con un falso valore per DMLRequestSort ):
- Assicura che il precedente
FOptimizeInsertil test non riesce , perché la terza condizione non è soddisfatta (P < 3). - Il
P <= 16condizione inFDemandRowsSortedForPerformanceinoltre non essere soddisfatto.
Ci aspettiamo quindi FastLoadContext non essere abilitato. Lo script demo modificato è:
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (16 * 130) -- 16 pages
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (269)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)'; Tutte le 269 righe sono completamente registrate come previsto:
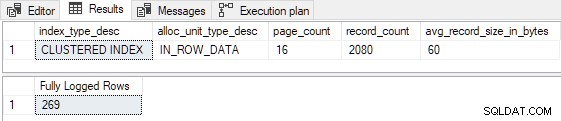
Tieni presente che, indipendentemente dall'impostazione del numero di nuove righe da inserire, lo script sopra mai produrre registrazione minima a causa del P <= 16 test (e P < 3 prova in FOptimizeInsert ).
Se scegli di eseguire tu stesso la demo con un numero maggiore di righe, commenta la sezione che mostra i singoli record del registro delle transazioni, altrimenti aspetterai molto tempo e SSMS potrebbe bloccarsi. (Ad essere onesti, potrebbe farlo comunque, ma perché aumentare il rischio.)
Rapporto pagine per riga inserita
Se sono presenti 17 o più pagine foglia nell'indice esistente, il precedente P <= 16 il test non fallirà. La prossima sezione della logica si occupa del rapporto tra pagine esistenti a righe appena inserite . Anche questo deve passare per ottenere una registrazione minima . Ricordiamo che le condizioni rilevanti sono:
- Rapporto
R=P/I. - Se
R < 8:- Se
P > 524restituisce vero , altrimenti falso .
- Se
Dobbiamo anche ricordare il test finale del motore di archiviazione per almeno 100 righe:
I >= 100.
Riorganizzando un po' queste condizioni, tutte di quanto segue deve essere vero:
P > 524(pagine indice esistenti)I >= 100(righe inserite stimate)P / I < 8(rapportoR)
Esistono diversi modi per soddisfare queste tre condizioni contemporaneamente. Scegliamo i valori minimi possibili per P (525) e I (100) dando una R valore di (525 / 100) =5,25. Questo soddisfa il (R < 8 test), quindi ci aspettiamo che questa combinazione determini una registrazione minima :
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (525 * 130) -- 525 pages
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (100)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
Il INSERT...SELECT di 100 righe è effettivamente registrato minimamente :
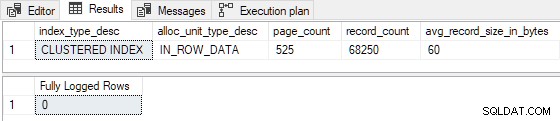
Riducendo la stima righe inserite a 99 (interrompendo I >= 100 ), e/o riducendo il numero di pagine di indice esistenti a 524 (rompendo P > 524 ) comporta una registrazione completa . Potremmo anche apportare modifiche tali che R non è più inferiore a 8 per produrre registrazione completa . Ad esempio, impostando P = 1000 e I = 125 restituisce R = 8 , con i seguenti risultati:
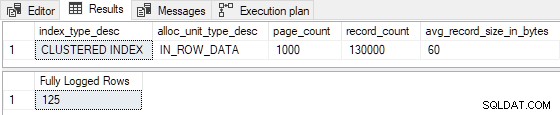
Le 125 righe inserite sono state completamente registrate come previsto. (Ciò non è dovuto alla registrazione completa della prima pagina, poiché l'indice non era vuoto in precedenza.)
Rapporto pagina per indici partizionati
Se tutti i test precedenti falliscono, quello rimanente richiede R >= 8 e può solo essere soddisfatto quando il numero di partizioni (T ) è maggiore di 1 e ce ne sono più di 250 stimate righe inserite (I ). Richiamo:
- Se
R >= 8:- Se
T > 1eI > 250restituisce vero , altrimenti falso .
- Se
Una sottigliezza:per partizionato index, la regola che dice che tutte le righe della prima pagina sono completamente registrate (per un indice inizialmente vuoto) si applica per partizione . Per un oggetto con 15.000 partizioni, ciò significa 15.000 "prime" pagine completamente registrate.
Riepilogo e pensieri finali
Le formule e l'ordine di valutazione descritti nel corpo si basano sull'ispezione del codice tramite un debugger. Sono stati presentati in una forma che rappresenta da vicino i tempi e l'ordine utilizzati nel codice reale.
È possibile riordinare e semplificare un po' queste condizioni, per produrre un riepilogo più conciso dei requisiti pratici per la registrazione minima quando si inserisce in un b-tree usando INSERT...SELECT . Le espressioni raffinate di seguito utilizzano i tre parametri seguenti:
P=numero di esistenti pagine di indice a livello di foglia.I=stimato numero di righe da inserire.S=stimato inserisci la dimensione dei dati in pagine da 8 KB.
Caricamento collettivo del set di righe
- Utilizza
sqlmin!RowsetBulk. - Richiede un vuoto target dell'indice cluster con
TABLOCK(o equivalente). - Richiede
DMLRequestSort = truenell'Inserimento indice cluster operatore. DMLRequestSortè impostatotrueseI > 250eS > 2.- Tutte le righe inserite sono minimamente registrate .
- Un
Sch-Mlock impedisce l'accesso simultaneo alla tabella.
Contesto di caricamento rapido
- Utilizza
sqlmin!FastLoadContext. - Abilita registrazione minima inserisce negli indici b-tree:
- In cluster o non in cluster.
- Con o senza blocco del tavolo.
- Indice di destinazione vuoto o meno.
- Richiede
DMLRequestSort = truenell'Inserimento indice associato operatore del piano. - Solo righe scritte su nuove pagine vengono caricati in blocco e registrati minimamente .
- La prima pagina di un indice vuoto precedentemente la partizione è sempre completamente registrata .
- Minimo assoluto di
I >= 100. - Richiede il flag di traccia 610 prima di SQL Server 2016.
- Disponibile per impostazione predefinita da SQL Server 2016 (flag di traccia 692 disabilitato).
DMLRequestSort è impostato true per:
- Qualsiasi indice (partizionato o meno) se:
I > 250eP < 3eS > 2; oI >= 100eP > 524eP < I * 8
Per solo indici partizionati (con> 1 partizione), DMLRequestSort è anche impostato true se:
I > 250eP > 16eP >= I * 8
Ci sono alcuni casi interessanti derivanti da quei FastLoadContext condizioni:
- Tutti inserisce in un non partizionato indice con tra 3 e 524 (incluso) le pagine foglia esistenti verranno registrate completamente indipendentemente dal numero e dalla dimensione totale delle righe aggiunte. Ciò influenzerà in modo più evidente gli inserti di grandi dimensioni su tabelle piccole (ma non vuote).
- Tutti inserisce in un partizionato indice compreso tra 3 e 16 le pagine esistenti saranno completamente registrate .
- Inserti grandi a grandi non partizionati gli indici potrebbero non essere registrati minimamente a causa della disuguaglianza
P < I * 8. QuandoPè grande, una stima corrispondentemente grande numero di righe inserite (I) è obbligatorio. Ad esempio, un indice con 8 milioni di pagine non può supportare registrazione minima quando si inseriscono 1 milione di righe o meno.
Indici non cluster
Le stesse considerazioni e calcoli applicati agli indici cluster nelle demo si applicano a non cluster anche gli indici b-tree, purché l'indice sia gestito da un operatore di piano dedicato (un ampio o per indice Piano). Indici non cluster gestiti da un operatore di tabella di base (ad es. Inserimento indice cluster ) non sono idonei per FastLoadContext .
Tieni presente che i parametri della formula devono essere rivalutati per ogni non cluster operatore di indice:dimensione della riga calcolata, numero di pagine di indice esistenti e stima della cardinalità.
Osservazioni generali
Fai attenzione alle stime di cardinalità bassa in Inserisci indice operatore, poiché influiranno su I e S parametri. Se una soglia non viene raggiunta a causa di un errore di stima della cardinalità, l'inserimento sarà completamente registrato .
Ricorda che DMLRequestSort è memorizzato nella cache con il piano — non viene valutato ad ogni esecuzione di un piano riutilizzato. Questo può introdurre una forma del noto problema di sensibilità ai parametri (noto anche come "sniffing dei parametri").
Il valore di P (pagine foglia indice) non è aggiornato all'inizio di ogni affermazione. L'implementazione corrente memorizza nella cache il valore per l'intero batch . Questo può avere effetti collaterali imprevisti. Ad esempio, un TRUNCATE TABLE nello stesso batch come INSERT...SELECT non ripristinerà P a zero per i calcoli descritti in questo articolo:continueranno a utilizzare il valore di pretroncamento e una ricompilazione non sarà di aiuto. Una soluzione alternativa consiste nell'inviare modifiche di grandi dimensioni in batch separati.
Traccia flag
È possibile forzare FDemandRowsSortedForPerformance per restituire vero impostando non documentato e non supportato flag di traccia 2332, come ho scritto in Ottimizzazione delle query T-SQL che modificano i dati. Quando TF 2332 è attivo, il numero di righe stimate da inserire deve essere ancora almeno 100 . TF 2332 influisce sulla registrazione minima decisione per FastLoadContext solo (è efficace per heap partizionati fino a DMLRequestSort è interessato, ma non ha alcun effetto sull'heap stesso, poiché FastLoadContext si applica solo agli indici).
Un ampio/per-indice la forma del piano per la manutenzione dell'indice non cluster può essere forzata per le tabelle rowstore utilizzando il flag di traccia 8790 (non ufficialmente documentato, ma menzionato in un articolo della Knowledge Base e nel mio articolo collegato a TF2332 appena sopra).
Lettura correlata
Tutto di Sunil Agarwal dal team di SQL Server:
- Cosa sono le ottimizzazioni per l'importazione in blocco?
- Ottimizzazioni dell'importazione in blocco (registrazione minima)
- Modifiche alla registrazione minime in SQL Server 2008
- Modifiche minime alla registrazione in SQL Server 2008 (parte 2)
- Modifiche minime alla registrazione in SQL Server 2008 (parte 3)