Kevin Kline (@kekline) e io di recente abbiamo tenuto un webinar sull'ottimizzazione delle query (beh, uno in una serie, in realtà), e una delle cose che è emersa è la tendenza delle persone a creare qualsiasi indice mancante che SQL Server dice loro sarà una buona cosa™ . Possono conoscere questi indici mancanti da Ottimizzazione guidata motore di database (DTA), le DMV degli indici mancanti o un piano di esecuzione visualizzato in Management Studio o Plan Explorer (che trasmettono semplicemente le informazioni esattamente dalla stessa posizione):
Il problema con la creazione cieca di questo indice è che SQL Server ha deciso che è utile per una query particolare (o una manciata di query), ma ignora completamente e unilateralmente il resto del carico di lavoro. Come tutti sappiamo, gli indici non sono "gratuiti":si pagano per gli indici sia nello storage grezzo che per la manutenzione richiesta sulle operazioni DML. Non ha molto senso, in un carico di lavoro pesante in scrittura, aggiungere un indice che aiuti a rendere una singola query leggermente più efficiente, soprattutto se tale query non viene eseguita frequentemente. In questi casi può essere molto importante comprendere il carico di lavoro complessivo e trovare un buon equilibrio tra l'efficienza delle query e il non pagare troppo in termini di manutenzione dell'indice.
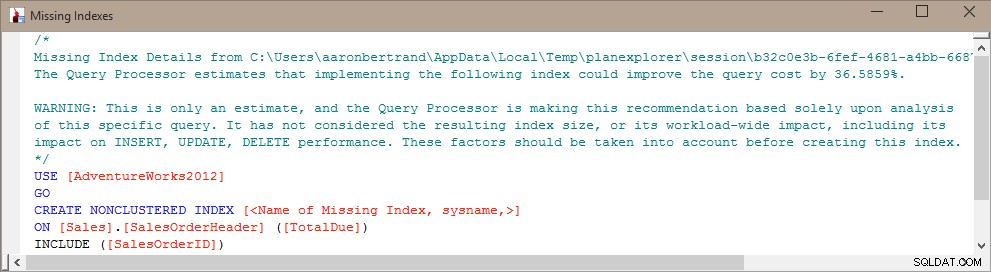
Quindi un'idea che avevo era quella di "mescolare" le informazioni dai DMV dell'indice mancanti, dal DMV delle statistiche sull'utilizzo dell'indice e dalle informazioni sui piani di query, per determinare quale tipo di equilibrio esiste attualmente e come l'aggiunta dell'indice potrebbe andare nel complesso.
Indici mancanti
Innanzitutto, possiamo dare un'occhiata agli indici mancanti attualmente suggeriti da SQL Server:
SELECT d.[object_id], s = OBJECT_SCHEMA_NAME(d.[object_id]), o = OBJECT_NAME(d.[object_id]), d.equality_columns, d.inequality_columns, d.included_columns, s.unique_compiles, s.user_seeks, s.last_user_seek, s.user_scans, s.last_user_scan INTO #candidates FROM sys.dm_db_missing_index_details AS d INNER JOIN sys.dm_db_missing_index_groups AS g ON d.index_handle = g.index_handle INNER JOIN sys.dm_db_missing_index_group_stats AS s ON g.index_group_handle = s.group_handle WHERE d.database_id = DB_ID() AND OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0;
Questo mostra le tabelle e le colonne che sarebbero state utili in un indice, quante compilazioni/ricerche/scansioni sarebbero state utilizzate e quando si è verificato l'ultimo evento di questo tipo per ciascun potenziale indice. Puoi anche includere colonne come s.avg_total_user_cost e s.avg_user_impact se vuoi usare quelle cifre per dare la priorità.
Pianificare le operazioni
Successivamente, diamo un'occhiata alle operazioni utilizzate in tutti i piani che abbiamo memorizzato nella cache rispetto agli oggetti che sono stati identificati dai nostri indici mancanti.
CREATE TABLE #planops
(
o INT,
i INT,
h VARBINARY(64),
uc INT,
Scan_Ops INT,
Seek_Ops INT,
Update_Ops INT
);
DECLARE @sql NVARCHAR(MAX) = N'';
SELECT @sql += N'
UNION ALL SELECT o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
FROM
(
SELECT o = ' + RTRIM([object_id]) + ',
i = ' + RTRIM(index_id) +',
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Scan'''''
+ ' or @LogicalOp = ''''Clustered Index Scan'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Seek_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Seek'''''
+ ' or @LogicalOp = ''''Clustered Index Seek'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Update_Ops = p.query_plan.value(''count(//Update/Object[@Index='''''
+ QUOTENAME(name) + '''''])'', ''int'')
FROM sys.dm_exec_cached_plans AS pl
CROSS APPLY sys.dm_exec_query_plan(pl.plan_handle) AS p
WHERE p.dbid = DB_ID()
AND p.query_plan IS NOT NULL
) AS x
WHERE Scan_Ops + Seek_Ops + Update_Ops > 0'
FROM sys.indexes AS i
WHERE i.index_id > 0
AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = i.[object_id]);
SET @sql = ';WITH xmlnamespaces (DEFAULT '
+ 'N''https://schemas.microsoft.com/sqlserver/2004/07/showplan'')
' + STUFF(@sql, 1, 16, '');
INSERT #planops EXEC sp_executesql @sql; Un amico su dba.SE, Mikael Eriksson, ha suggerito le seguenti due query che, su un sistema più grande, funzioneranno molto meglio della query XML / UNION che ho messo insieme sopra, quindi potresti prima sperimentarle. Il suo commento finale è stato che "non sorprende che abbia scoperto che meno XML è una buona cosa per le prestazioni. :)". In effetti.
-- alternative #1
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
from
(
select o = i.object_id,
i = i.index_id,
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Scan", "Clustered Index Scan")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Seek_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Seek", "Clustered Index Seek")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Update_Ops = p.query_plan.value('count(//Update/Object[@Index = sql:column("i2.name")])', 'int')
from sys.indexes as i
cross apply (select quotename(i.name) as name) as i2
cross apply sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
where exists (select 1 from #candidates as c where c.[object_id] = i.[object_id])
and p.query_plan.exist('//Object[@Index = sql:column("i2.name")]') = 1
and p.[dbid] = db_id()
and i.index_id > 0
) as T
where Scan_Ops + Seek_Ops + Update_Ops > 0;
-- alternative #2
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o = coalesce(T1.o, T2.o),
i = coalesce(T1.i, T2.i),
h = coalesce(T1.h, T2.h),
uc = coalesce(T1.uc, T2.uc),
Scan_Ops = isnull(T1.Scan_Ops, 0),
Seek_Ops = isnull(T1.Seek_Ops, 0),
Update_Ops = isnull(T2.Update_Ops, 0)
from
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Scan_Ops = sum(case when t.LogicalOp in ('Index Scan', 'Clustered Index Scan') then 1 else 0 end),
Seek_Ops = sum(case when t.LogicalOp in ('Index Seek', 'Clustered Index Seek') then 1 else 0 end)
from (
select
r.n.value('@LogicalOp', 'varchar(100)') as LogicalOp,
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//RelOp') as r(n)
cross apply r.n.nodes('*/Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where t.LogicalOp in ('Index Scan', 'Clustered Index Scan', 'Index Seek', 'Clustered Index Seek')
and exists (select 1 from #candidates as c where c.object_id = i.object_id)
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T1
full outer join
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Update_Ops = count(*)
from (
select
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//Update') as r(n)
cross apply r.n.nodes('Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where exists
(
select 1 from #candidates as c where c.[object_id] = i.[object_id]
)
and i.index_id > 0
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T2
on T1.o = T2.o and
T1.i = T2.i and
T1.h = T2.h and
T1.uc = T2.uc;
Ora nel #planops tabella hai un sacco di valori per plan_handle in modo che tu possa andare a indagare su ciascuno dei singoli piani in gioco contro gli oggetti che sono stati identificati come privi di un indice utile. Non lo useremo per questo in questo momento, ma puoi facilmente fare un riferimento incrociato con:
SELECT OBJECT_SCHEMA_NAME(po.o), OBJECT_NAME(po.o), po.uc,po.Scan_Ops,po.Seek_Ops,po.Update_Ops, p.query_plan FROM #planops AS po CROSS APPLY sys.dm_exec_query_plan(po.h) AS p;
Ora puoi fare clic su uno qualsiasi dei piani di output per vedere cosa stanno facendo attualmente contro i tuoi oggetti. Tieni presente che alcuni dei piani verranno ripetuti, poiché un piano può avere più operatori che fanno riferimento a indici diversi sulla stessa tabella.
Statistiche sull'utilizzo dell'indice
Successivamente, diamo un'occhiata alle statistiche sull'utilizzo dell'indice, in modo da poter vedere quanta attività effettiva è attualmente in esecuzione rispetto alle nostre tabelle candidate (e, in particolare, agli aggiornamenti).
SELECT [object_id], index_id, user_seeks, user_scans, user_lookups, user_updates INTO #indexusage FROM sys.dm_db_index_usage_stats AS s WHERE database_id = DB_ID() AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = s.[object_id]);
Non allarmarti se pochi o nessun piano nella cache mostra aggiornamenti per un determinato indice, anche se le statistiche sull'utilizzo dell'indice mostrano che tali indici sono stati aggiornati. Ciò significa solo che i piani di aggiornamento non sono attualmente nella cache, il che potrebbe essere dovuto a una serie di motivi, ad esempio, potrebbe essere un carico di lavoro molto pesante in lettura e sono stati invecchiati, oppure sono tutti single- utilizza e optimize for ad hoc workloads è abilitato.
Mettere tutto insieme
La query seguente ti mostrerà, per ogni indice mancante suggerito, il numero di letture che un indice potrebbe aver aiutato, il numero di scritture e letture che sono state attualmente acquisite rispetto agli indici esistenti, il rapporto tra questi, il numero di piani associati a quell'oggetto e il numero totale di utilizzi conta per quei piani:
;WITH x AS
(
SELECT
c.[object_id],
potential_read_ops = SUM(c.user_seeks + c.user_scans),
[write_ops] = SUM(iu.user_updates),
[read_ops] = SUM(iu.user_scans + iu.user_seeks + iu.user_lookups),
[write:read ratio] = CONVERT(DECIMAL(18,2), SUM(iu.user_updates)*1.0 /
SUM(iu.user_scans + iu.user_seeks + iu.user_lookups)),
current_plan_count = po.h,
current_plan_use_count = po.uc
FROM
#candidates AS c
LEFT OUTER JOIN
#indexusage AS iu
ON c.[object_id] = iu.[object_id]
LEFT OUTER JOIN
(
SELECT o, h = COUNT(h), uc = SUM(uc)
FROM #planops GROUP BY o
) AS po
ON c.[object_id] = po.o
GROUP BY c.[object_id], po.h, po.uc
)
SELECT [object] = QUOTENAME(c.s) + '.' + QUOTENAME(c.o),
c.equality_columns,
c.inequality_columns,
c.included_columns,
x.potential_read_ops,
x.write_ops,
x.read_ops,
x.[write:read ratio],
x.current_plan_count,
x.current_plan_use_count
FROM #candidates AS c
INNER JOIN x
ON c.[object_id] = x.[object_id]
ORDER BY x.[write:read ratio];
Se il tuo rapporto di scrittura:lettura per questi indici è già> 1 (o> 10!), Penso che dia motivo di pausa prima di creare ciecamente un indice che potrebbe solo aumentare questo rapporto. Il numero di potential_read_ops mostrato, tuttavia, potrebbe compensarlo man mano che il numero diventa più grande. Se il potential_read_ops numero è molto piccolo, probabilmente vorrai ignorare del tutto la raccomandazione prima ancora di preoccuparti di esaminare le altre metriche, quindi potresti aggiungere un WHERE clausola per filtrare alcune di queste raccomandazioni.
Un paio di note:
- Queste sono operazioni di lettura e scrittura, non letture e scritture misurate individualmente di 8.000 pagine.
- Il rapporto e i confronti sono in gran parte educativi; potrebbe benissimo essere che 10.000.000 di operazioni di scrittura abbiano interessato tutte una singola riga, mentre 10 operazioni di lettura avrebbero potuto avere un impatto sostanzialmente maggiore. Questo è solo inteso come una linea guida approssimativa e presuppone che le operazioni di lettura e scrittura abbiano più o meno lo stesso peso.
- Puoi anche utilizzare lievi variazioni su alcune di queste query per scoprire, al di fuori degli indici mancanti consigliati da SQL Server, quanti dei tuoi indici attuali sono uno spreco. Ci sono molte idee su questo online, incluso questo post di Paul Randal (@PaulRandal).
Spero che questo dia alcune idee per ottenere maggiori informazioni sul comportamento del tuo sistema prima di decidere di aggiungere un indice che alcuni strumenti ti hanno detto di creare. Avrei potuto creare questa come una query enorme, ma penso che le singole parti ti daranno alcune tane del coniglio su cui indagare, se lo desideri.
Altre note
Puoi anche estenderlo per acquisire le metriche delle dimensioni attuali, la larghezza della tabella e il numero di righe correnti (oltre a eventuali previsioni sulla crescita futura); questo può darti una buona idea di quanto spazio occuperà un nuovo indice, il che può essere un problema a seconda del tuo ambiente. Potrei trattarlo in un prossimo post.
Ovviamente, devi tenere a mente che queste metriche sono utili solo quanto dettato dal tuo tempo di attività. I DMV vengono eliminati dopo un riavvio (e talvolta in altri scenari meno dirompenti), quindi se ritieni che queste informazioni possano essere utili per un periodo di tempo più lungo, potresti prendere in considerazione l'acquisizione di istantanee periodiche.