Un problema di prestazioni che vedo spesso è quando gli utenti devono abbinare parte di una stringa a una query come la seguente:
... WHERE SomeColumn LIKE N'%SomePortion%';
Con un carattere jolly iniziale, questo predicato è "non SARGable" – solo un modo elegante per dire che non riusciamo a trovare le righe pertinenti usando una ricerca rispetto a un indice su SomeColumn .
Una soluzione su cui siamo un po' agitati è la ricerca full-text; tuttavia, questa è una soluzione complessa e richiede che il modello di ricerca sia composto da parole complete, non utilizzi parole di arresto e così via. Questo può aiutare se stiamo cercando righe in cui una descrizione contiene la parola "soft" (o altri derivati come "softer" o "softly"), ma non aiuta quando stiamo cercando stringhe che potrebbero essere contenute all'interno di parole (o che non sono affatto parole, come tutte le SKU di prodotto che contengono "X45-B" o tutte le targhe che contengono la sequenza "7RA").
E se SQL Server sapesse in qualche modo tutte le possibili porzioni di una stringa? Il mio processo di pensiero è sulla falsariga di trigram / trigraph in PostgreSQL. Il concetto di base è che il motore ha la capacità di eseguire ricerche in stile punto sulle sottostringhe, il che significa che non devi scansionare l'intera tabella e analizzare ogni valore completo.
L'esempio specifico che usano è la parola cat . Oltre alla parola intera, può essere suddivisa in porzioni:c , ca e at (tralasciano at e t per definizione – nessuna sottostringa finale può essere più corta di due caratteri). In SQL Server, non è necessario che sia così complesso; abbiamo davvero bisogno solo di metà del trigramma – se pensiamo di costruire una struttura dati che contenga tutte le sottostringhe di cat , abbiamo solo bisogno di questi valori:
Non abbiamo bisogno di c o ca , perché chiunque cerchi LIKE '%ca%' potrebbe facilmente trovare il valore 1 usando LIKE 'ca%' invece. Allo stesso modo, chiunque cerchi LIKE '%at%' o LIKE '%a%' potrebbe utilizzare un carattere jolly finale solo rispetto a questi tre valori e trovare quello che corrisponde (ad es. LIKE 'at%' troverà il valore 2 e LIKE 'a%' troverà anche il valore 2, senza dover trovare quelle sottostringhe all'interno del valore 1, da dove verrebbe il vero dolore).
Quindi, dato che SQL Server non ha nulla di simile integrato, come possiamo generare un tale trigramma?
Una tabella dei frammenti separata
Smetterò di fare riferimento a "trigramma" qui perché questo non è veramente analogo a quella funzione in PostgreSQL. In sostanza, quello che faremo è costruire una tabella separata con tutti i "frammenti" della stringa originale. (Quindi nel cat ad esempio, ci sarebbe una nuova tabella con queste tre righe e LIKE '%pattern%' le ricerche verrebbero indirizzate a quella nuova tabella come LIKE 'pattern%' predicati.)
Prima di iniziare a mostrare come funzionerebbe la mia soluzione proposta, vorrei essere assolutamente chiaro che questa soluzione non dovrebbe essere utilizzata in ogni singolo caso in cui LIKE '%wildcard%' le ricerche sono lente. A causa del modo in cui "esploderemo" i dati di origine in frammenti, è probabile che la praticità sia limitata a stringhe più piccole, come indirizzi o nomi, rispetto a stringhe più grandi, come descrizioni di prodotti o abstract di sessioni.
Un esempio più pratico di cat è guardare il Sales.Customer tabella nel database di esempio WideWorldImporters. Ha righe di indirizzo (entrambe nvarchar(60) ), con le preziose informazioni sull'indirizzo nella colonna DeliveryAddressLine2 (per ragioni sconosciute). Qualcuno potrebbe cercare chiunque viva in una strada chiamata Hudecova , quindi eseguiranno una ricerca come questa:
SELECT CustomerID, DeliveryAddressLine2
FROM Sales.Customers
WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
/* This returns two rows:
CustomerID DeliveryAddressLine2
---------- ----------------------
61 1695 Hudecova Avenue
181 1846 Hudecova Crescent
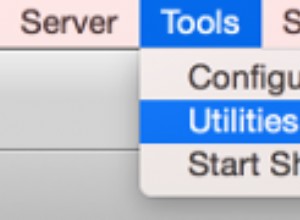
*/ Come prevedibile, SQL Server deve eseguire un'analisi per individuare queste due righe. Che dovrebbe essere semplice; tuttavia, a causa della complessità della tabella, questa query banale produce un piano di esecuzione molto disordinato (la scansione è evidenziata e ha un avviso per I/O residuo):
candeggina. Per semplificare le nostre vite e per assicurarci di non inseguire un mucchio di false piste, creiamo una nuova tabella con un sottoinsieme di colonne e per iniziare inseriamo le stesse due righe dall'alto:
CREATE TABLE Sales.CustomersCopy ( CustomerID int IDENTITY(1,1) CONSTRAINT PK_CustomersCopy PRIMARY KEY, CustomerName nvarchar(100) NOT NULL, DeliveryAddressLine1 nvarchar(60) NOT NULL, DeliveryAddressLine2 nvarchar(60) ); GO INSERT Sales.CustomersCopy ( CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 ) SELECT CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 FROM Sales.Customers WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
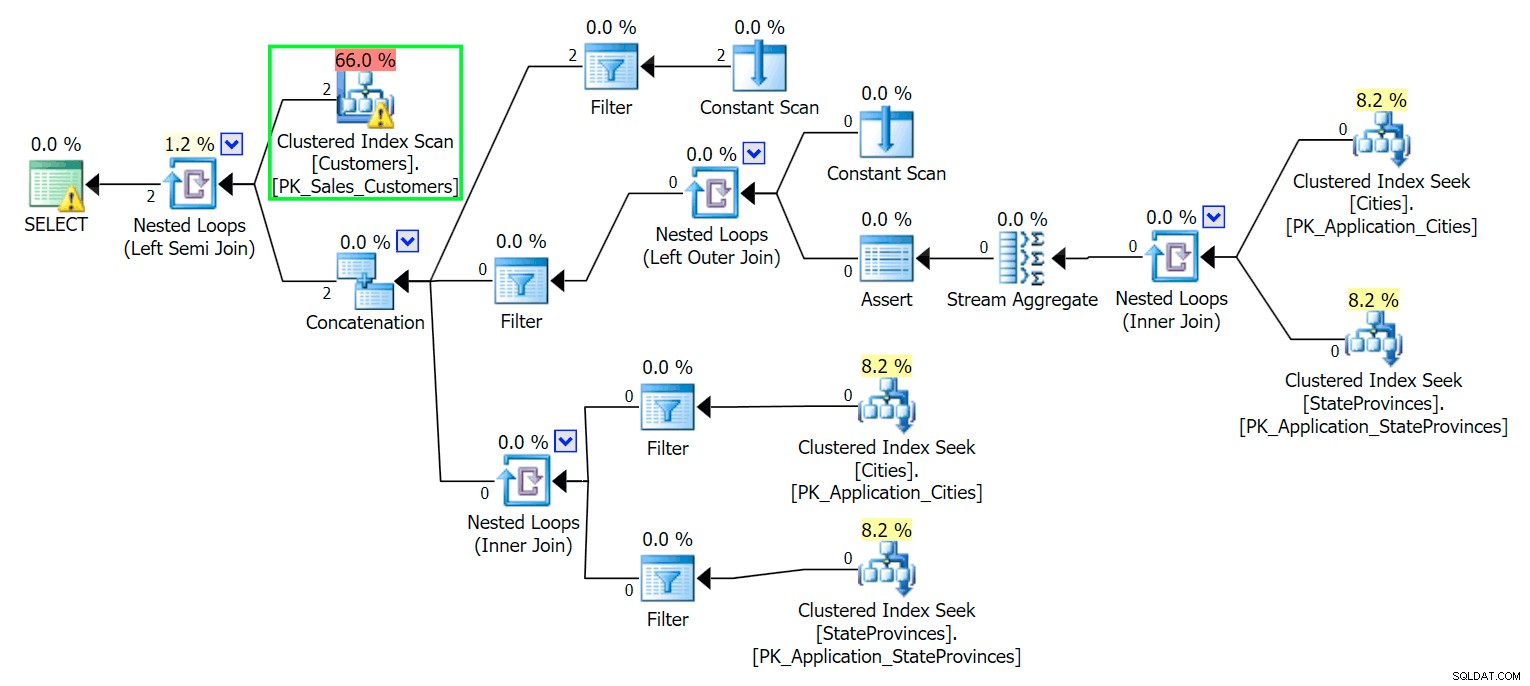
Ora, se eseguiamo la stessa query eseguita sulla tabella principale, otteniamo qualcosa di molto più ragionevole da considerare come punto di partenza. Questa sarà comunque una scansione, qualunque cosa facciamo, se aggiungiamo un indice con DeliveryAddressLine2 come colonna chiave principale, molto probabilmente otterremo una scansione dell'indice, con una ricerca della chiave a seconda che l'indice copra le colonne nella query. Così com'è, otteniamo una scansione dell'indice cluster:
Quindi, creiamo una funzione che "esploderà" questi valori di indirizzo in frammenti. Ci aspetteremmo 1846 Hudecova Crescent , ad esempio, per avere il seguente insieme di frammenti:
- 1846 Mezzaluna di Hudecova
- 846 Mezzaluna di Hudecova
- 46 Mezzaluna di Hudecova
- 6 Mezzaluna di Hudecova
- Mezzaluna di Hudecova
- Mezzaluna Hudecova
- udecova Crescent
- Decova Crescent
- ecova Crescent
- Cova Crescent
- Ova a mezzaluna
- va Crescente
- una mezzaluna
- Mezzaluna
- Mezzaluna
- riscendente
- escendente
- profumo
- centesimi
- ent
- nt
- t
È abbastanza banale scrivere una funzione che produca questo output:abbiamo solo bisogno di un CTE ricorsivo che può essere utilizzato per scorrere ogni carattere per tutta la lunghezza dell'input:
CREATE FUNCTION dbo.CreateStringFragments( @input nvarchar(60) )
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
WITH x(x) AS
(
SELECT 1 UNION ALL SELECT x+1 FROM x WHERE x < (LEN(@input))
)
SELECT Fragment = SUBSTRING(@input, x, LEN(@input)) FROM x
);
GO
SELECT Fragment FROM dbo.CreateStringFragments(N'1846 Hudecova Crescent');
-- same output as above bulleted list Ora creiamo una tabella che memorizzerà tutti i frammenti di indirizzo e a quale Cliente appartengono:
CREATE TABLE Sales.CustomerAddressFragments ( CustomerID int NOT NULL, Fragment nvarchar(60) NOT NULL, CONSTRAINT FK_Customers FOREIGN KEY(CustomerID) REFERENCES Sales.CustomersCopy(CustomerID) ); CREATE CLUSTERED INDEX s_cat ON Sales.CustomerAddressFragments(Fragment, CustomerID);
Quindi possiamo popolarlo in questo modo:
INSERT Sales.CustomerAddressFragments(CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f;
Per i nostri due valori, questo inserisce 42 righe (un indirizzo ha 20 caratteri e l'altro ha 22). Ora la nostra domanda diventa:
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
INNER JOIN Sales.CustomerAddressFragments AS f
ON f.CustomerID = c.CustomerID
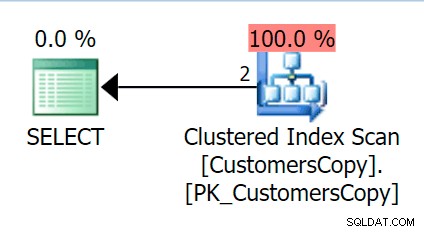
AND f.Fragment LIKE N'Hudecova%'; Ecco un piano molto più carino:due indici cluster *seeks* e un loop nidificato si uniscono:
Possiamo farlo anche in un altro modo, usando EXISTS :
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
WHERE EXISTS
(
SELECT 1 FROM Sales.CustomerAddressFragments
WHERE CustomerID = c.CustomerID
AND Fragment LIKE N'Hudecova%'
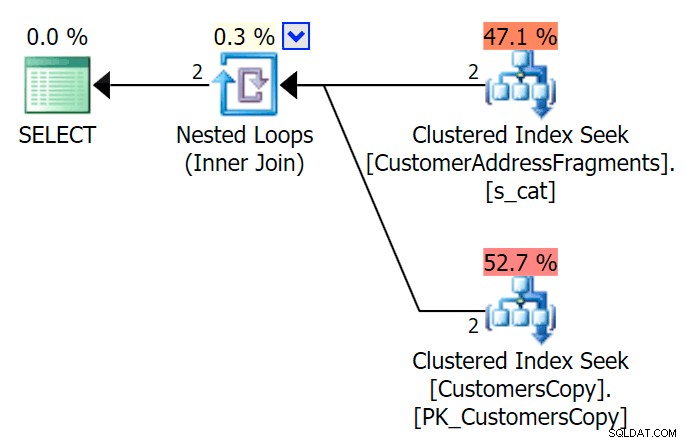
); Ecco quel piano, che in apparenza sembra essere più costoso:sceglie di scansionare la tabella CustomersCopy. Vedremo tra breve perché questo è l'approccio di query migliore:
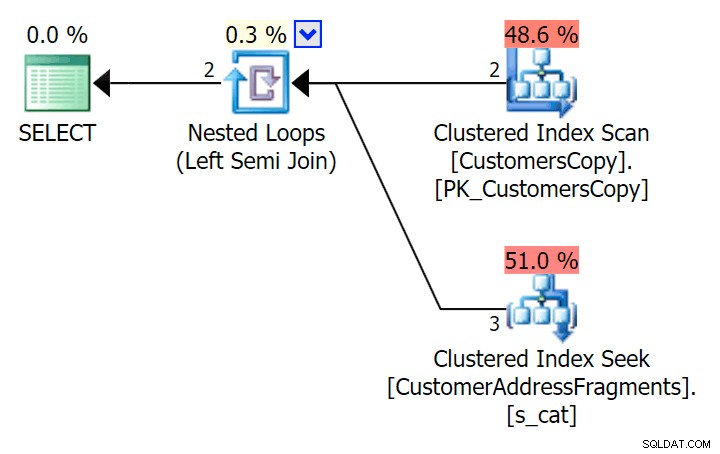
Ora, su questo enorme set di dati di 42 righe, le differenze osservate in termini di durata e I/O sono così minuscole da essere irrilevanti (e infatti, con queste dimensioni ridotte, la scansione rispetto alla tabella di base sembra più economica in termini di I/O O rispetto agli altri due piani che utilizzano la tabella dei frammenti):

E se dovessimo popolare queste tabelle con molti più dati? La mia copia di Sales.Customers ha 663 righe, quindi se incrociamo quello contro se stesso, arriveremmo da qualche parte vicino a 440.000 righe. Quindi uniamo solo 400K e generiamo una tabella molto più grande:
TRUNCATE TABLE Sales.CustomerAddressFragments; DELETE Sales.CustomersCopy; DBCC FREEPROCCACHE WITH NO_INFOMSGS; INSERT Sales.CustomersCopy WITH (TABLOCKX) (CustomerName, DeliveryAddressLine1, DeliveryAddressLine2) SELECT TOP (400000) c1.CustomerName, c1.DeliveryAddressLine1, c2.DeliveryAddressLine2 FROM Sales.Customers c1 CROSS JOIN Sales.Customers c2 ORDER BY NEWID(); -- fun for distribution -- this will take a bit longer - on my system, ~4 minutes -- probably because I didn't bother to pre-expand files INSERT Sales.CustomerAddressFragments WITH (TABLOCKX) (CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f; -- repeated for compressed version of the table -- 7.25 million rows, 278MB (79MB compressed; saving those tests for another day)
Ora per confrontare le prestazioni e i piani di esecuzione dati una varietà di possibili parametri di ricerca, ho testato le tre query precedenti con questi predicati:
| Query | Predicati | ||||
|---|---|---|---|---|---|
| DOVE DeliveryLineAddress2 MI PIACE … | N'%Hudecova%' | N'%cova%' | N'%ova%' | N'%va%' | |
| UNISCI... DOVE Frammento COME... | N'Hudecova%' | N'cova%' | N'ova%' | N'va%' | |
| DOVE ESISTE (… DOVE Frammento COME …) | |||||
Man mano che rimuoviamo le lettere dal modello di ricerca, mi aspetto di vedere più righe di output e forse strategie diverse scelte dall'ottimizzatore. Vediamo come è andata per ogni pattern:
Hudecova%
Per questo modello, la scansione era sempre la stessa per la condizione LIKE; tuttavia, con più dati, il costo è molto più alto. Le ricerche nella tabella dei frammenti ripagano davvero con questo conteggio di righe (1.206), anche con stime davvero basse. Il piano EXISTS aggiunge un ordinamento distinto, che ti aspetteresti di aggiungere al costo, anche se in questo caso finisce per fare meno letture:

 Pianifica la JOIN alla tabella dei frammenti
Pianifica la JOIN alla tabella dei frammenti 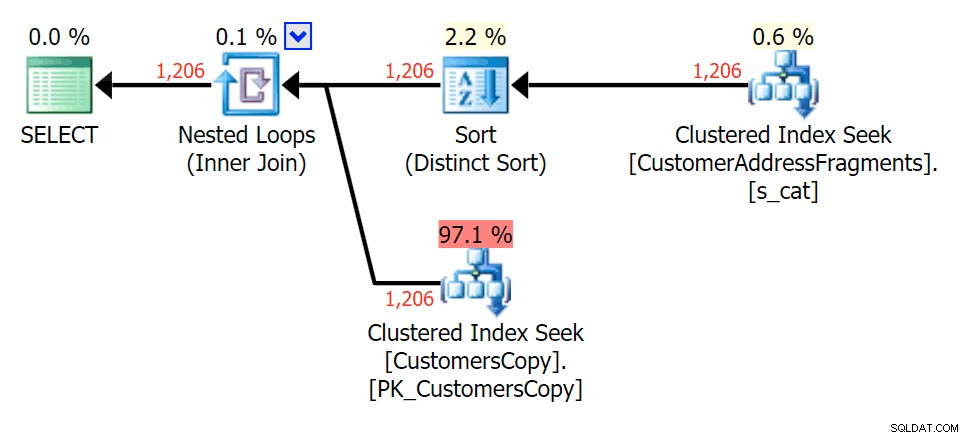 Pianifica per EXISTS rispetto alla tabella dei frammenti
Pianifica per EXISTS rispetto alla tabella dei frammenti cova%
Mentre togliamo alcune lettere dal nostro predicato, vediamo le letture in realtà un po' più alte rispetto alla scansione dell'indice cluster originale e ora oltre -stimare le righe. Tuttavia, la nostra durata rimane significativamente inferiore con entrambe le query sui frammenti; la differenza questa volta è più sottile:entrambi hanno dei tipi (solo EXISTS è distinto):

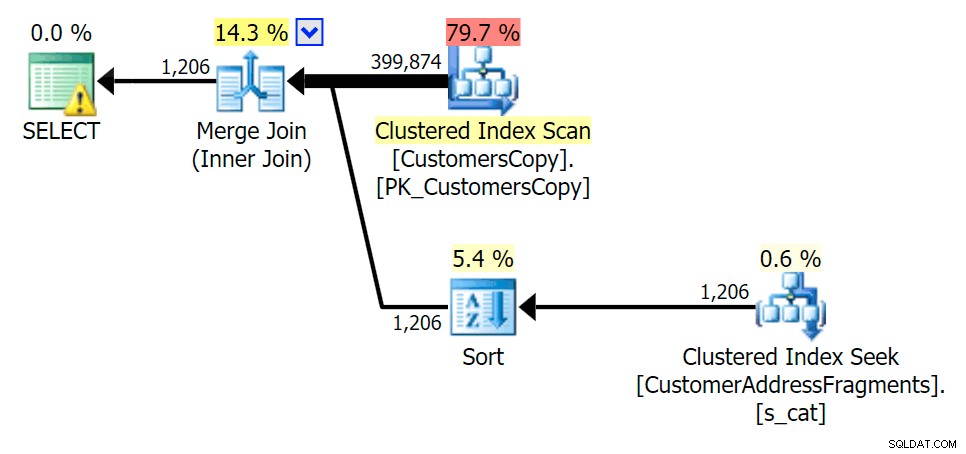 Pianifica la JOIN alla tabella dei frammenti
Pianifica la JOIN alla tabella dei frammenti 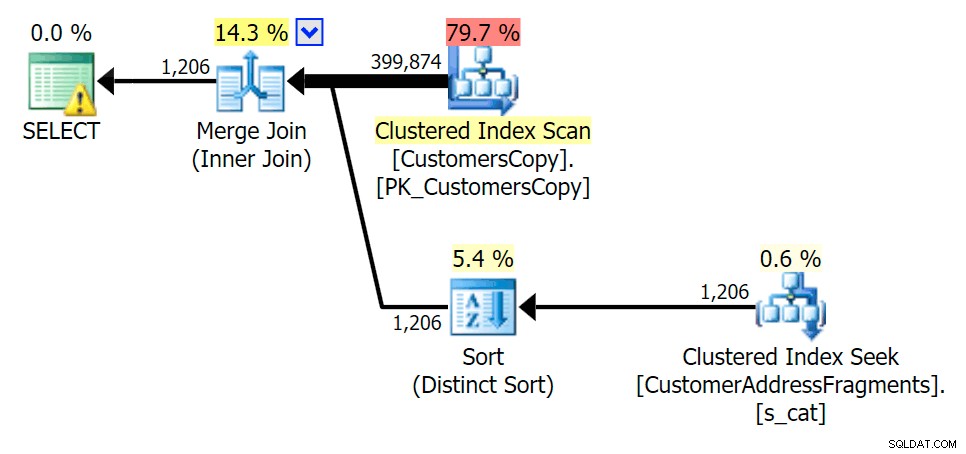 Pianifica per EXISTS rispetto alla tabella dei frammenti
Pianifica per EXISTS rispetto alla tabella dei frammenti ova%
La rimozione di una lettera aggiuntiva non è cambiata molto; anche se vale la pena notare quanto saltano qui le righe stimate ed effettive, il che significa che questo potrebbe essere un modello di sottostringa comune. La query LIKE originale è ancora un po' più lenta delle query sui frammenti.

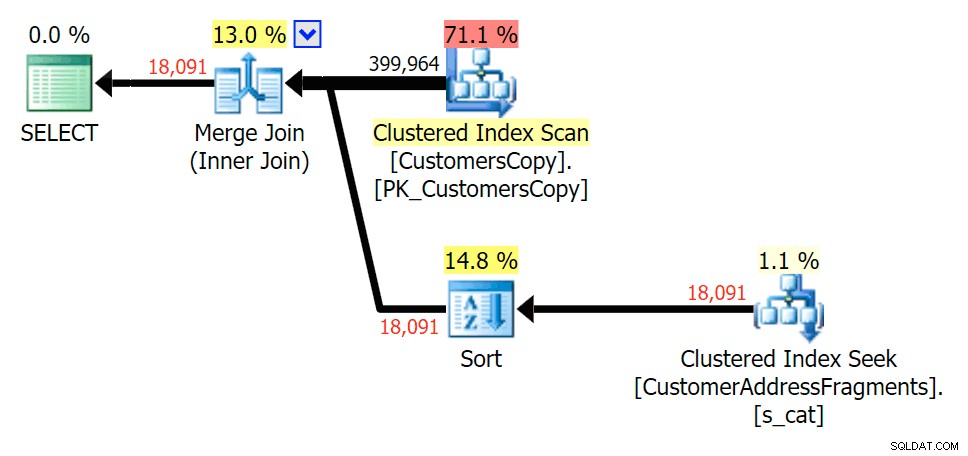 Pianifica la JOIN alla tabella dei frammenti
Pianifica la JOIN alla tabella dei frammenti 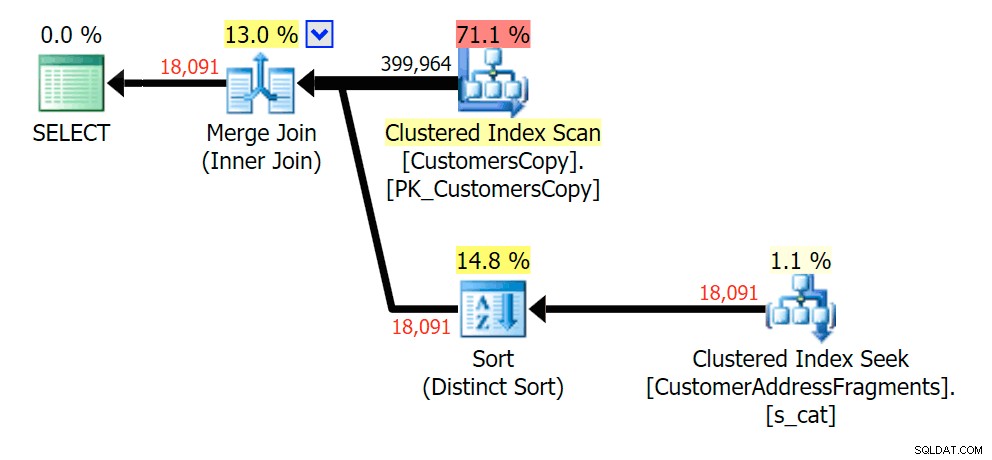 Pianifica per EXISTS rispetto alla tabella dei frammenti
Pianifica per EXISTS rispetto alla tabella dei frammenti va%
Fino a due lettere, questo introduce la nostra prima discrepanza. Nota che JOIN produce di più righe rispetto alla query originale o EXISTS. Perché dovrebbe essere?

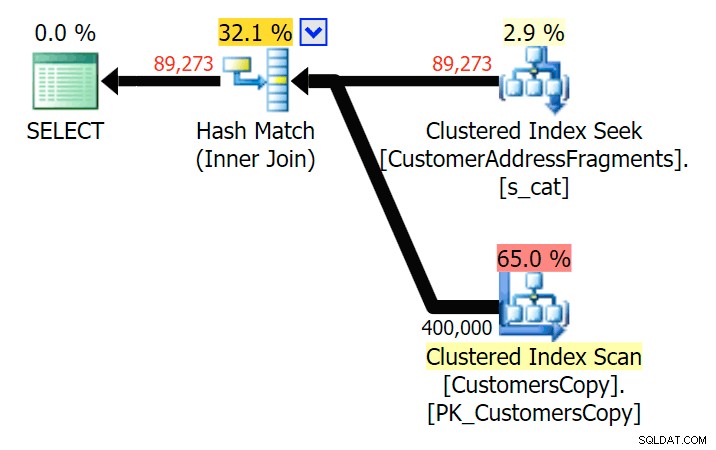 Pianifica la JOIN alla tabella dei frammenti
Pianifica la JOIN alla tabella dei frammenti 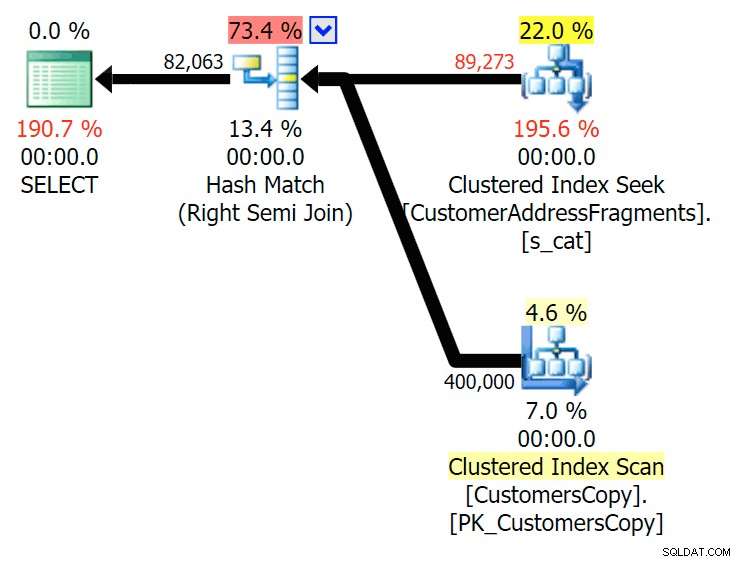 Pianifica per EXISTS rispetto alla tabella dei frammenti Non dobbiamo guardare lontano. Ricorda che c'è un frammento che inizia da ogni carattere successivo nell'indirizzo originale, che significa qualcosa come
Pianifica per EXISTS rispetto alla tabella dei frammenti Non dobbiamo guardare lontano. Ricorda che c'è un frammento che inizia da ogni carattere successivo nell'indirizzo originale, che significa qualcosa come 899 Valentova Road avrà due righe nella tabella dei frammenti che iniziano con va (a parte la distinzione tra maiuscole e minuscole). Quindi corrisponderai su entrambi Fragment = N'Valentova Road' e Fragment = N'va Road' . Ti risparmio la ricerca e fornisco un solo esempio tra tanti: SELECT TOP (2) c.CustomerID, c.DeliveryAddressLine2, f.Fragment FROM Sales.CustomersCopy AS c INNER JOIN Sales.CustomerAddressFragments AS f ON c.CustomerID = f.CustomerID WHERE f.Fragment LIKE N'va%' AND c.DeliveryAddressLine2 = N'899 Valentova Road' AND f.CustomerID = 351; /* CustomerID DeliveryAddressLine2 Fragment ---------- -------------------- -------------- 351 899 Valentova Road va Road 351 899 Valentova Road Valentova Road */
Questo spiega facilmente perché JOIN produce più righe; se vuoi far corrispondere l'output della query LIKE originale, dovresti usare EXISTS. Il fatto che i risultati corretti di solito possano essere ottenuti anche in un modo meno dispendioso in termini di risorse è solo un bonus. (Sarei nervoso se le persone scegliessero JOIN se questa fosse l'opzione ripetutamente più efficiente:dovresti sempre privilegiare i risultati corretti piuttosto che preoccuparti delle prestazioni.)
Riepilogo
È chiaro che in questo caso specifico, con una colonna di indirizzo di nvarchar(60) e una lunghezza massima di 26 caratteri:suddividere ogni indirizzo in frammenti può portare un po' di sollievo alle ricerche altrimenti costose di "caratteri jolly principali". Il guadagno migliore sembra verificarsi quando il modello di ricerca è più ampio e, di conseguenza, più unico. Ho anche dimostrato perché EXISTS è migliore in scenari in cui sono possibili più corrispondenze:con un JOIN, otterrai un output ridondante a meno che tu non aggiunga una logica "più grande n per gruppo".
Avvertenze
Sarò il primo ad ammettere che questa soluzione è imperfetta, incompleta e non completamente definita:
- Dovrai mantenere la tabella dei frammenti sincronizzata con la tabella di base utilizzando i trigger:il più semplice sarebbe per gli inserimenti e gli aggiornamenti, eliminare tutte le righe per quei clienti e reinserirle, e per le eliminazioni ovviamente rimuovere le righe dai frammenti tavolo.
- Come accennato, questa soluzione ha funzionato meglio per questa dimensione di dati specifica e potrebbe non funzionare così bene per altre lunghezze di stringa. Sarebbe giustificato ulteriori test per garantire che sia appropriato per le dimensioni della colonna, la lunghezza del valore medio e la lunghezza tipica del parametro di ricerca.
- Dato che avremo molte copie di frammenti come "Crescent" e "Street" (non importa tutti i nomi di strade e numeri civici uguali o simili), potremmo ulteriormente normalizzarlo memorizzando ogni frammento univoco in una tabella dei frammenti, e poi ancora un altro tavolo che funge da tavolo di giunzione molti-a-molti. Sarebbe molto più complicato da configurare e non sono sicuro che ci sarebbe molto da guadagnare.
- Non ho ancora studiato a fondo la compressione della pagina, sembra che, almeno in teoria, questo potrebbe fornire qualche vantaggio. Ho anche la sensazione che l'implementazione di un columnstore possa essere utile anche in alcuni casi.
Comunque, detto questo, volevo solo condividerla come idea in via di sviluppo e sollecitare qualsiasi feedback sulla sua praticità per casi d'uso specifici. Posso approfondire i dettagli per un post futuro se puoi farmi sapere quali aspetti di questa soluzione ti interessano.