Quando un piano di esecuzione include una scansione di una struttura di indice b-tree, il motore di archiviazione può essere in grado di scegliere tra due strategie di accesso fisico quando il piano viene eseguito:
- Segui la struttura dell'indice b-tree; o,
- individuare le pagine utilizzando le informazioni interne sull'allocazione delle pagine.
Laddove è disponibile una scelta, il motore di archiviazione prende la decisione di runtime su ciascuna esecuzione. La ricompilazione di un piano non necessario per cambiare idea.
La strategia b-tree inizia alla radice dell'albero, scende fino a un bordo estremo del livello foglia (a seconda che la scansione sia avanti o indietro), quindi segue i collegamenti di pagina a livello foglia fino a raggiungere l'altra estremità dell'indice . La strategia di allocazione utilizza le strutture Index Allocation Map (IAM) per individuare le pagine del database allocate all'indice. Ogni pagina IAM associa le allocazioni a un intervallo di 4 GB in un singolo file di database fisico, quindi la scansione delle catene IAM associate a un indice tende ad accedere alle pagine dell'indice nell'ordine dei file fisici (almeno per quanto può dire SQL Server).
Le principali differenze tra le due strategie sono:
- Una scansione b-tree può fornire righe al Query Processor nell'ordine delle chiavi di indice; una scansione basata su IAM non può;
- una scansione b-tree potrebbe non essere in grado di inviare richieste di I/O read-ahead di grandi dimensioni se le pagine dell'indice logicamente contigue non sono anche fisicamente contigue (ad esempio a causa della divisione della pagina nell'indice).
Una scansione b-tree è sempre disponibile per un indice. Le condizioni spesso citate per la disponibilità delle scansioni degli ordini di allocazione sono:
- Il piano di query deve consentire una scansione non ordinata dell'indice;
- l'indice deve avere una dimensione di almeno 64 pagine; e,
- o un
TABLOCKoNOLOCKil suggerimento deve essere specificato.
La prima condizione significa semplicemente che Query Optimizer deve aver contrassegnato la scansione con Ordered:False proprietà. Contrassegnare la scansione Ordered:False significa che i risultati corretti del piano di esecuzione non richiedono la scansione per restituire le righe nell'ordine della chiave di indice (sebbene possa farlo se è conveniente o altrimenti necessario).
La seconda condizione (dimensione) si applica solo a SQL Server 2005 e versioni successive. Riflette il fatto che l'esecuzione di una scansione basata su IAM comporta un certo costo iniziale, quindi è necessario un numero minimo di pagine affinché il potenziale risparmio ripaghi l'investimento iniziale. Le "64 pagine" si riferiscono al valore di data_pages per il IN_ROW_DATA solo unità di allocazione, come riportato in sys.allocation_units.
Ovviamente, può esserci un guadagno da una scansione dell'ordine di allocazione solo se le considerazioni di read-ahead possibilmente più grandi effettivamente entra in gioco, ma SQL Server attualmente non considera questo fattore. In particolare, non tiene conto della quantità di indice attualmente in memoria, né di quanto sia frammentato l'indice.
La terza condizione è probabilmente la descrizione meno completa nell'elenco. I suggerimenti non sono infatti richiesti , sebbene possano essere utilizzati per soddisfare i requisiti reali:i dati devono essere garantiti per non cambiare durante la scansione, o (più controverso) dobbiamo indicare che non ci interessa sui risultati potenzialmente imprecisi, eseguendo la scansione al livello di isolamento non vincolato di lettura.
Anche con questi chiarimenti, l'elenco delle condizioni per una scansione ordinata allocazione non è ancora completo. Ci sono una serie di importanti avvertenze ed eccezioni, di cui parleremo a breve.
Demo
La query seguente utilizza il database di esempio AdventureWorks:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P; Si noti che la tabella Persona contiene 3.869 pagine. Il piano di post-esecuzione (effettivo) è il seguente (mostrato in SQL Sentry Plan Explorer):
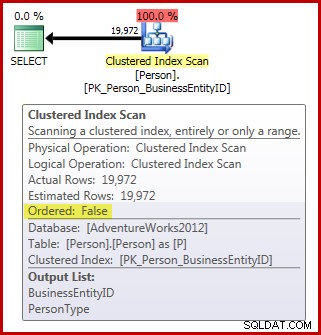
In termini di requisiti di scansione degli ordini di allocazione che abbiamo finora:
- Il piano ha il
Ordered:Falserichiesto proprietà; e, - la tabella ha più di 64 pagine; ma,
- non abbiamo fatto nulla per garantire che i dati non possano cambiare durante la scansione. Supponendo che la nostra sessione utilizzi il read commit predefinito livello di isolamento, la scansione non viene eseguita al lettura non vincolata anche il livello di isolamento.
Di conseguenza, ci aspetteremmo che questa scansione venga eseguita scansionando il b-tree anziché essere guidata da IAM. I risultati della query indicano che questo è probabilmente vero:
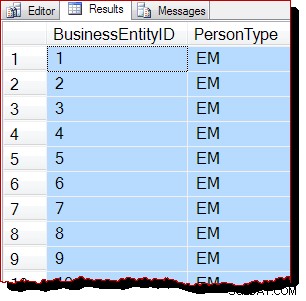
Le righe vengono restituite nell'ordine delle chiavi dell'indice cluster (da BusinessEntityID ). Devo affermare chiaramente che questo ordinamento dei risultati è assolutamente non garantito e su cui non si dovrebbe fare affidamento. I risultati ordinati sono garantiti solo da un appropriato ORDER BY di livello superiore clausola.
Tuttavia, l'ordine di output osservato è una prova circostanziale che la scansione è stata eseguita questa volta seguendo la struttura ad albero b dell'indice cluster. Se sono necessarie ulteriori prove, possiamo allegare un debugger e guardare il percorso del codice che SQL Server sta eseguendo durante la scansione:

Lo stack di chiamate mostra chiaramente la scansione che segue l'albero b.
Aggiunta di un suggerimento per il blocco della tabella
Ora modifichiamo la query per includere un suggerimento per il blocco della tabella:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK); Al livello di isolamento di lettura commit del blocco predefinito, il blocco a livello di tabella condivisa impedisce qualsiasi possibile modifica simultanea ai dati. Con tutte e tre le precondizioni per le scansioni guidate da IAM soddisfatte, ora ci si aspetta che SQL Server utilizzi un'analisi dell'ordine di allocazione. Il piano di esecuzione è lo stesso di prima, quindi non lo ripeterò, ma i risultati della query avranno sicuramente un aspetto diverso:
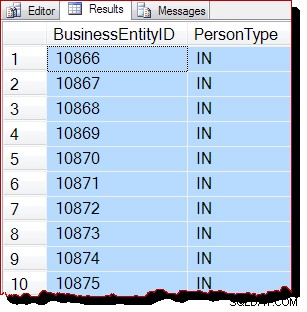
Apparentemente i risultati sono ancora ordinati per BusinessEntityID , ma il punto di partenza (10866) è diverso. In effetti, se scorriamo verso il basso i risultati, incontreremo presto sezioni che sono più ovviamente fuori dall'ordine delle chiavi:
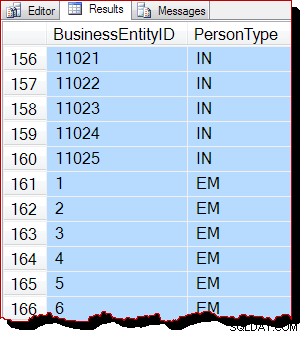
L'ordinamento parziale è dovuto alla scansione dell'ordine di allocazione che elabora un'intera pagina di indice alla volta. I risultati all'interno di una pagina capita di essere restituito ordinato dalla chiave di indice, ma l'ordine delle pagine scansionate è ora diverso. Ancora una volta, dovrei sottolineare che i risultati potrebbero sembrare diversi per te:non c'è garanzia di un ordine di output, anche all'interno di una pagina, senza un ORDER BY di livello superiore sulla query originale.
Per confronto con lo stack di chiamate mostrato in precedenza, questa è una traccia dello stack ottenuta mentre SQL Server elaborava la query con TABLOCK suggerimento:
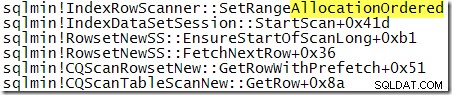
Procedendo un po' più avanti nell'esecuzione:

Chiaramente, SQL Server esegue un'analisi in base all'ordine di allocazione quando viene specificato il blocco della tabella. È un peccato che non vi sia alcuna indicazione in un piano post-esecuzione di quale tipo di scansione sia stata utilizzata in fase di esecuzione. Ricordiamo che il tipo di scansione viene scelto dal motore di archiviazione e può cambiare tra le esecuzioni senza una ricompilazione del piano.
Altri modi per soddisfare la terza condizione
Ho detto prima che per ottenere una scansione basata su IAM, dobbiamo assicurarci che i dati non possano cambiare sotto la scansione mentre è in corso, oppure dobbiamo eseguire la query al livello di isolamento di lettura senza commit. Abbiamo visto che un suggerimento di blocco della tabella per bloccare l'isolamento di read commit è sufficiente per soddisfare il primo di questi requisiti, ed è facile dimostrare che usando un NOLOCK/READUNCOMMITTED hint abilita anche una scansione dell'ordine di allocazione con la query demo.
In effetti ci sono molti modi per soddisfare la terza condizione, tra cui:
- Modificare l'indice per consentire solo i blocchi delle tabelle;
- rendendo il database di sola lettura (quindi è garantito che i dati non cambino); o,
- modificare la sessione livello di isolamento su
READ UNCOMMITTED.
Ci sono, tuttavia, variazioni molto più interessanti su questo tema che significano che dobbiamo modificare le tre condizioni indicate in precedenza...
Livelli di isolamento del controllo delle versioni delle righe
Abilita l'isolamento dello snapshot in lettura (RCSI) nel database AdventureWorks ed esegui il test con TABLOCK suggerimento di nuovo (a leggere l'isolamento commesso):
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT ON
WITH ROLLBACK IMMEDIATE;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
GO
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK);
GO
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT OFF
WITH ROLLBACK IMMEDIATE;
Con RCSI attivo, un ordinato per indice la scansione viene utilizzata con TABLOCK , non la scansione dell'ordine di allocazione che abbiamo visto poco prima. Il motivo è il TABLOCK hint specifica un blocco condiviso a livello di tabella, ma con RCSI abilitato, nessun blocco condiviso sono presi. Senza il blocco della tabella condivisa, non abbiamo soddisfatto il requisito per impedire modifiche simultanee ai dati mentre è in corso la scansione, quindi non è possibile utilizzare una scansione ordinata allocazione.
Tuttavia, è possibile ottenere una scansione ordinata allocazione quando RCSI è abilitato. Un modo è usare un TABLOCKX suggerimento (per un esclusivo a livello di tabella lock) invece di TABLOCK . Potremmo anche conservare il TABLOCK suggerimento e aggiungerne un altro come READCOMMITTEDLOCK o REPEATABLE READ o SERIALIZABLE … e così via. Tutti questi funzionano prevenendo la possibilità di modifiche simultanee prendendo un blocco di tabella condiviso, a costo di perdere i vantaggi di RCSI . Possiamo anche ottenere una scansione dell'ordine di allocazione utilizzando un NOLOCK o READUNCOMMITTED suggerimento, ovviamente.
La situazione in isolamento istantaneo (SI) è molto simile a RCSI e non esplorata in dettaglio per motivi di spazio.
TABLESAMPLE sempre* esegue una scansione dell'ordine di allocazione
Il TABLESAMPLE La clausola è un'interessante eccezione a molte delle cose che abbiamo discusso finora.
Specificando un TABLESAMPLE la clausola sempre* risulta in una scansione dell'ordine di allocazione, anche in RCSI o SI, e anche senza suggerimenti. Per essere chiari, la scansione dell'ordine di allocazione che risulta dall'utilizzo di TABLESAMPLE mantiene la semantica RCSI/SI – la scansione utilizza versioni di riga e la lettura non blocca la scrittura (e viceversa).
Una seconda sorpresa è che TABLESAMPLE esegue sempre* una scansione basata su IAM anche se la tabella ha meno di 64 pagine . Questo ha un senso perché la documentazione almeno suggerisce che il SYSTEM il metodo di campionamento utilizza la struttura IAM (quindi non c'è altra scelta che eseguire una scansione dell'ordine di allocazione):
SISTEMA È un metodo di campionamento dipendente dall'implementazione specificato dagli standard ISO. In SQL Server, questo è l'unico metodo di campionamento disponibile e viene applicato per impostazione predefinita. SYSTEM applica un metodo di campionamento basato sulla pagina in cui viene scelto un insieme casuale di pagine dalla tabella per l'esempio e tutte le righe su quelle pagine vengono restituite come sottoinsieme dell'esempio.
* Si verifica un'eccezione se ROWS o PERCENT specifica nel TABLESAMPLE la clausola funziona per significare il 100% della tabella. Specificando più ROWS di quanto i metadati indicano che sono attualmente nella tabella non funzioneranno neanche. Utilizzo di TABLESAMPLE SYSTEM (100 PERCENT) o equivalente non forzare una scansione dell'ordine di allocazione.
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
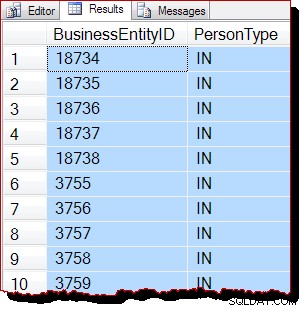
TABLESAMPLE SYSTEM (50 ROWS)
REPEATABLE (12345678)
--WITH (TABLOCK); Risultati:
L'effetto di TOP e SET ROWCOUNT
In breve, nessuno di questi ha alcun effetto sulla decisione di utilizzare o meno una scansione dell'ordine di allocazione. Questo può sembrare sorprendente nei casi in cui è "ovvio" che verranno scansionate meno di 64 pagine.
Ad esempio, le seguenti query utilizzano entrambe una scansione basata su IAM per restituire 5 righe da una scansione:
SELECT TOP (5)
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 5;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 0; I risultati sono gli stessi per entrambi:
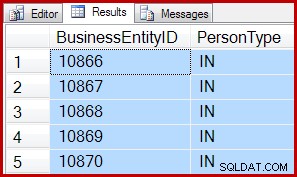
Ciò significa che TOP e SET ROWCOUNT le query potrebbero incorrere nell'overhead di impostare una scansione dell'ordine di allocazione, anche se vengono scansionate meno di 64 pagine. In mitigazione, le query TOP più complesse con predicati selettivi inseriti nella scansione potrebbero comunque trarre vantaggio da una scansione dell'ordine di allocazione. Se la scansione deve elaborare 10.000 pagine per trovare le prime 5 righe corrispondenti, una scansione dell'ordine di allocazione potrebbe comunque essere vincente.
Prevenire tutte* le scansioni degli ordini di allocazione a livello di istanza
Questo non è qualcosa che probabilmente faresti mai intenzionalmente, ma esiste un'impostazione del server che impedirà le scansioni dell'ordine di allocazione per tutte* le query degli utenti in tutti i database.
Per quanto improbabile possa sembrare, l'impostazione in questione è l'opzione di configurazione del server di soglia del cursore, che ha la seguente descrizione nella documentazione in linea:
L'opzione di soglia del cursore specifica il numero di righe nel set di cursori in cui vengono generati i keyset del cursore in modo asincrono. Quando i cursori generano un keyset per un set di risultati, Query Optimizer stima il numero di righe che verranno restituite per quel set di risultati. Se Query Optimizer stima che il numero di righe restituite sia maggiore di questa soglia, il cursore viene generato in modo asincrono, consentendo all'utente di recuperare le righe dal cursore mentre il cursore continua a essere popolato. In caso contrario, il cursore viene generato in modo sincrono e la query attende finché non vengono restituite tutte le righe.
Se la cursor threshold l'opzione è impostata su un valore diverso da –1 (impostazione predefinita), non verranno eseguite scansioni dell'ordine di allocazione per le query degli utenti in qualsiasi database nell'istanza di SQL Server.
In altre parole, se il popolamento asincrono del cursore è abilitato, nessuna scansione guidata da IAM per te.
* L'eccezione è (non-100%) TABLESAMPLE interrogazioni. Anche le query interne generate dal sistema per la creazione e l'aggiornamento delle statistiche continuano a utilizzare scansioni ordinate allocazione.
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
-- WARNING! Disables allocation-order scans instance-wide
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = 5000;
RECONFIGURE WITH OVERRIDE;
GO
-- Would normally result in an allocation-order scan
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (READUNCOMMITTED);
GO
-- Reset to default allocation-order scans
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = -1;
RECONFIGURE WITH OVERRIDE; Risultati (nessuna scansione dell'ordine di allocazione):
Si può solo supporre che la popolazione asincrona del cursore non funzioni bene con le scansioni dell'ordine di allocazione per qualche motivo. È del tutto inaspettato che questa restrizione influisca su tutte le query degli utenti senza cursore pure però. Forse è troppo difficile per SQL Server rilevare se una query è in esecuzione come parte di un cursore API emesso esternamente? Chissà.
Sarebbe bello se questo effetto collaterale fosse ufficialmente documentato da qualche parte, anche se è difficile sapere esattamente dove dovrebbe andare nella documentazione in linea. Mi chiedo quanti sistemi di produzione là fuori non stiano utilizzando le scansioni degli ordini di allocazione per questo motivo? Forse non molti, ma non si sa mai.
Per concludere, ecco un riassunto. Una scansione ordinata allocazione è disponibile se:
- L'opzione del server
cursor thresholdè impostato su –1 (impostazione predefinita); e, - l'operatore di scansione del piano di query ha
Ordered:Falseproprietà; e, - il totale delle pagine_dati del
IN_ROW_DATAle unità di allocazione è almeno 64; e, - o:
- SQL Server ha una garanzia accettabile che le modifiche simultanee sono impossibili; o,
- la scansione è in esecuzione al livello di isolamento di lettura senza commit.
Indipendentemente da tutto quanto sopra, una scansione con un TABLESAMPLE La clausola utilizza sempre scansioni ordinate allocazione (con l'eccezione tecnica annotata nel testo principale).