Questa è la terza di una serie in cinque parti che approfondisce il modo in cui inizia l'esecuzione dei piani paralleli in modalità riga di SQL Server. La parte 1 ha inizializzato il contesto di esecuzione zero per l'attività padre e la parte 2 ha creato l'albero di scansione della query. Ora siamo pronti per avviare la scansione delle query, eseguire alcune fase iniziali elaborazione e avviare le prime attività parallele aggiuntive.
Avvio scansione query
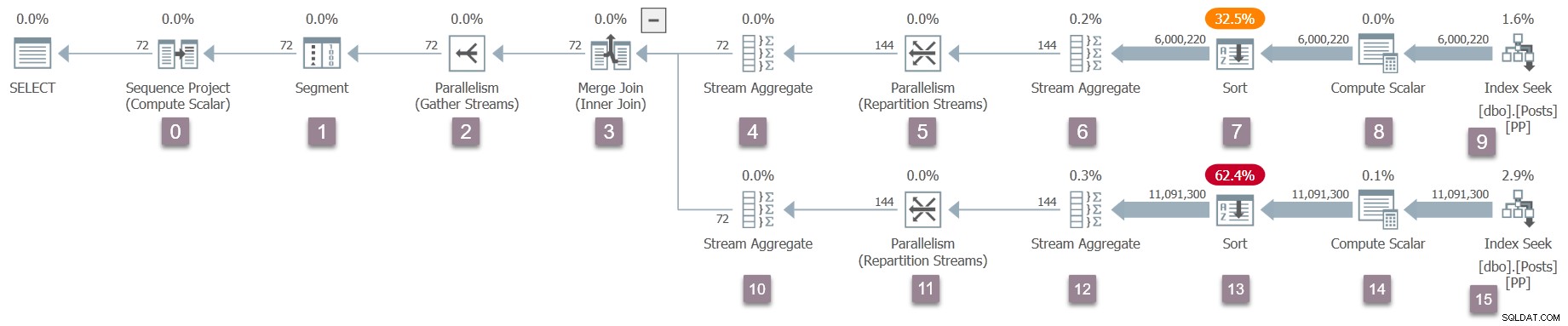
Ricorda che solo l'attività principale esiste in questo momento, e gli scambi (operatori di parallelismo) hanno solo un lato consumista. Tuttavia, questo è sufficiente per avviare l'esecuzione della query, sul thread di lavoro dell'attività padre. Il Query Processor inizia l'esecuzione avviando il processo di scansione della query tramite una chiamata a CQueryScan::StartupQuery . Un promemoria del piano (clicca per ingrandire):
Questo è il primo punto del processo finora che un piano di esecuzione in volo è disponibile (da SQL Server 2016 SP1 in poi) in sys.dm_exec_query_statistics_xml . Non c'è nulla di particolarmente interessante da vedere in un piano del genere a questo punto, perché tutti i contatori transitori sono zero, ma il piano è almeno disponibile . Non vi è alcun indizio che le attività parallele non siano ancora state create o che gli scambi manchino di un lato produttore. Il piano sembra "normale" sotto tutti gli aspetti.
Rami del piano parallelo
Trattandosi di un piano parallelo, sarà utile mostrarlo suddiviso in rami. Questi sono ombreggiati di seguito ed etichettati come rami da A a D:
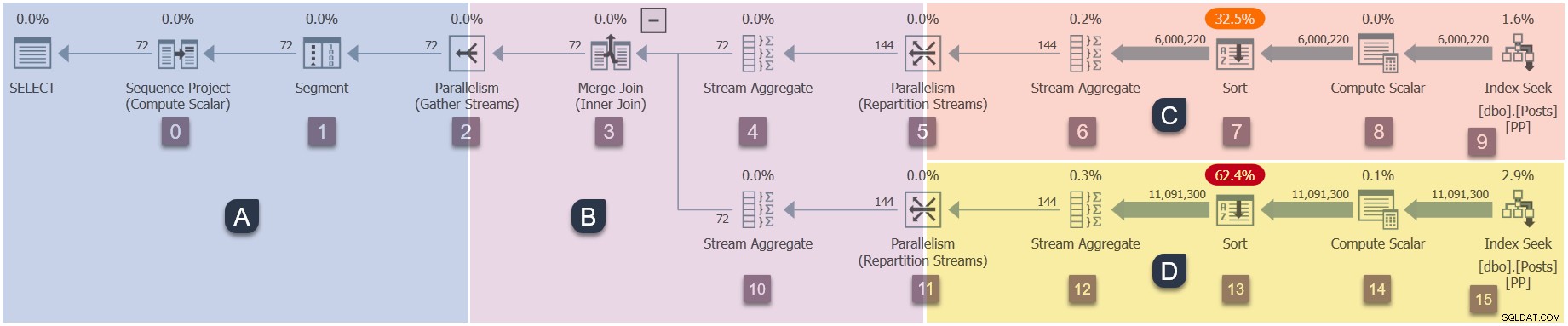
Il ramo A è associato all'attività padre, in esecuzione sul thread di lavoro fornito dalla sessione. Verranno avviati ulteriori lavoratori paralleli per eseguire le attività parallele aggiuntive contenuti nei rami B, C e D. Questi rami sono paralleli, quindi ci saranno compiti e lavoratori aggiuntivi DOP in ciascuno.
La nostra query di esempio viene eseguita su DOP 2, quindi il ramo B riceverà due attività aggiuntive. Lo stesso vale per il ramo C e il ramo D, per un totale di sei compiti aggiuntivi. Ogni attività verrà eseguita sul proprio thread di lavoro nel proprio contesto di esecuzione.
Due programmatori (S1 e S2 ) vengono assegnati a questa query per eseguire altri worker paralleli. Ogni lavoratore aggiuntivo verrà eseguito su uno di questi due scheduler. Il genitore può essere eseguito su uno scheduler diverso, quindi la nostra query DOP 2 può utilizzare un massimo di tre core del processore in qualsiasi momento.
Per riassumere, il nostro piano alla fine avrà:
- Ramo A (genitore)
- Attività principale.
- Filo di lavoro principale.
- Contesto di esecuzione zero.
- Qualsiasi utilità di pianificazione disponibile per la query.
- Ramo B (aggiuntivo)
- Due attività aggiuntive.
- Un thread di lavoro aggiuntivo legato a ogni nuova attività.
- Due nuovi contesti di esecuzione, uno per ogni nuova attività.
- Un thread di lavoro viene eseguito sullo scheduler S1 . L'altro viene eseguito sullo scheduler S2 .
- Ramo C (aggiuntivo)
- Due attività aggiuntive.
- Un thread di lavoro aggiuntivo legato a ogni nuova attività.
- Due nuovi contesti di esecuzione, uno per ogni nuova attività.
- Un thread di lavoro viene eseguito sullo scheduler S1 . L'altro viene eseguito sullo scheduler S2 .
- Ramo D (aggiuntivo)
- Due attività aggiuntive.
- Un thread di lavoro aggiuntivo legato a ogni nuova attività.
- Due nuovi contesti di esecuzione, uno per ogni nuova attività.
- Un thread di lavoro viene eseguito sullo scheduler S1 . L'altro viene eseguito sullo scheduler S2 .
La domanda è come vengono creati tutti questi compiti extra, lavoratori e contesti di esecuzione e quando iniziano a essere eseguiti.
Sequenza iniziale
La sequenza in cui attività aggiuntive inizia a eseguire per questo particolare piano è:
- Ramo A (attività principale).
- Ramo C (attività parallele aggiuntive).
- Ramo D (attività parallele aggiuntive).
- Ramo B (attività parallele aggiuntive).
Potrebbe non essere l'ordine di avvio che ti aspettavi.
Potrebbe esserci un ritardo significativo tra ciascuno di questi passaggi, per ragioni che esploreremo tra breve. Il punto chiave in questa fase è che le attività aggiuntive, i lavoratori e i contesti di esecuzione non tutti creati in una volta e non tutti iniziano a essere eseguiti contemporaneamente.
SQL Server potrebbe essere stato progettato per avviare tutti i bit paralleli aggiuntivi tutti in una volta. Potrebbe essere facile da comprendere, ma non sarebbe molto efficiente in generale. Massimizzerebbe il numero di thread aggiuntivi e altre risorse utilizzate dalla query e provocherebbe una grande quantità di inutili attese parallele.
Con la progettazione impiegata da SQL Server, i piani paralleli utilizzeranno spesso meno thread di lavoro totali rispetto a (DOP moltiplicato per il numero totale di rami). Ciò si ottiene riconoscendo che alcuni rami possono essere completati prima che sia necessario avviare un altro ramo. Ciò può consentire il riutilizzo dei thread all'interno della stessa query e generalmente riduce il consumo di risorse in generale.
Passiamo ora ai dettagli di come si avvia il nostro piano parallelo.
Apertura filiale A
La scansione della query viene avviata con l'attività principale che chiama Open() sull'iteratore alla radice dell'albero. Questo è l'inizio della sequenza di esecuzione:
- Ramo A (attività principale).
- Ramo C (attività parallele aggiuntive).
- Ramo D (attività parallele aggiuntive).
- Ramo B (attività parallele aggiuntive).
Stiamo eseguendo questa query con un piano "reale" richiesto, quindi l'iteratore radice non l'operatore del progetto di sequenza al nodo 0. Piuttosto, è l'iteratore di profilazione invisibile che registra le metriche di runtime nei piani in modalità riga.
L'illustrazione seguente mostra gli iteratori di scansione delle query nel ramo A del piano, con la posizione degli iteratori di profilazione invisibili rappresentata dalle icone degli "occhiali".
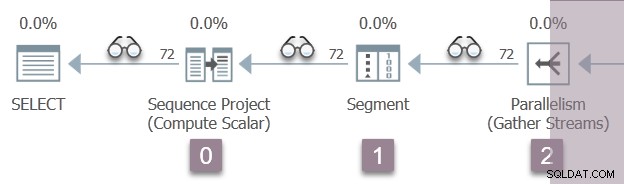
L'esecuzione inizia con una chiamata per aprire il primo profiler, CQScanProfileNew::Open . Questo imposta il orario di apertura per l'operatore del progetto della sequenza figlio tramite l'API Query Performance Counter del sistema operativo.
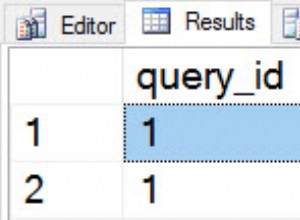
Possiamo vedere questo numero in sys.dm_exec_query_profiles :
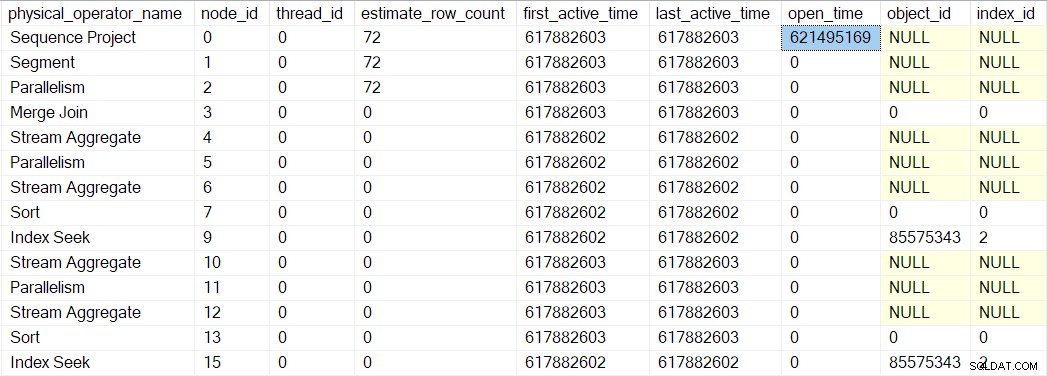
Le voci lì possono avere i nomi degli operatori elencati, ma i dati provengono dal profiler sopra l'operatore, non l'operatore stesso.
Guarda caso, un progetto di sequenza (CQScanSeqProjectNew ) non deve eseguire alcun lavoro quando aperto , quindi in realtà non ha un Open() metodo. Il profiler sopra il progetto della sequenza è chiamato, quindi un tempo aperto per il progetto della sequenza viene registrato nel DMV.
Open del profiler il metodo non chiama Open sul progetto della sequenza (poiché non ne ha uno). Invece chiama Open sul profiler per l'iteratore successivo in sequenza. Questo è il segmento iteratore al nodo 1. Ciò imposta il tempo di apertura per il segmento, proprio come faceva il profiler precedente per il progetto della sequenza:
Un iteratore di segmento lo fa avere cose da fare una volta aperto, quindi la prossima chiamata è a CQScanSegmentNew::Open . Una volta che il segmento ha fatto ciò che deve, chiama il profiler per l'iteratore successivo in sequenza:il consumatore lato dello scambio di flussi di raccolta al nodo 2:
La chiamata successiva all'albero di scansione delle query nel processo di apertura è CQScanExchangeNew::Open , ed è qui che le cose iniziano a farsi più interessanti.
Apertura dello scambio di flussi di raccolta
Chiedere al consumatore di aprire lo scambio:
- Apre una transazione locale (annidata in parallelo) (
CXTransLocal::Open). Ogni processo necessita di una transazione di contenimento e le attività parallele aggiuntive non fanno eccezione. Non possono condividere direttamente la transazione padre (di base), quindi vengono utilizzate le transazioni nidificate. Quando un'attività parallela deve accedere alla transazione di base, si sincronizza su un latch e potrebbe incontrareNESTING_TRANSACTION_READONLYoNESTING_TRANSACTION_FULLaspetta. - Registra il thread di lavoro corrente con la porta di scambio (
CXPort::Register). - Sincronizza con altri thread sul lato consumer dello scambio (
sqlmin!CXTransLocal::Synchronize). Non ci sono altri thread sul lato consumer di un flusso di raccolta, quindi questo è essenzialmente un no-op in questa occasione.
Elaborazione delle "fasi iniziali"
L'attività principale ha ora raggiunto il limite del ramo A. Il passaggio successivo è particolare ai piani paralleli in modalità riga:l'attività padre continua l'esecuzione chiamando CQScanExchangeNew::EarlyPhases sull'iteratore di scambio dei flussi di raccolta al nodo 2. Questo è un metodo iteratore aggiuntivo oltre al solito Open , GetRow e Close metodi che molti di voi conosceranno. EarlyPhases viene chiamato solo nei piani paralleli in modalità riga.
Voglio essere chiaro su una cosa a questo punto:il lato produttore dello scambio di flussi di raccolta sul nodo 2 non è stato ancora creato e no sono state create ulteriori attività parallele. Stiamo ancora eseguendo il codice per l'attività padre, utilizzando l'unico thread in esecuzione in questo momento.
Non tutti gli iteratori implementano EarlyPhases , perché non tutti hanno qualcosa di speciale da fare a questo punto nei piani paralleli in modalità riga. Questo è analogo al progetto della sequenza che non implementa Open metodo perché non ha nulla a che fare in quel momento. I principali iteratori con EarlyPhases i metodi sono:
CQScanConcatNew(concatenazione).CQScanMergeJoinNew(unisci unisciti).CQScanSwitchNew(cambia).CQScanExchangeNew(parallelismo).CQScanNew(accesso al set di righe, ad es. scansioni e ricerche).CQScanProfileNew(profilatori invisibili).CQScanLightProfileNew(profilatori leggeri invisibili).
Fasi iniziali del ramo B
L'attività principale continua chiamando EarlyPhases sugli operatori figlio oltre lo scambio di flussi di raccolta nel nodo 2. Un'attività che si sposta su un confine di ramo potrebbe sembrare insolita, ma ricorda che il contesto di esecuzione zero contiene l'intero piano seriale, con scambi inclusi. L'elaborazione della fase iniziale riguarda l'inizializzazione del parallelismo, quindi non conta come esecuzione di per sé .
Per aiutarti a tenere traccia, l'immagine seguente mostra gli iteratori nel ramo B del piano:
Ricorda, siamo ancora nel contesto di esecuzione zero, quindi mi riferisco a questo solo come Branch B per comodità. Non abbiamo iniziato qualsiasi esecuzione parallela ancora.
La sequenza delle chiamate del codice della fase iniziale nel ramo B è:
CQScanProfileNew::EarlyPhasesper il profiler sopra il nodo 3.CQScanMergeJoinNew::EarlyPhasesal nodo 3 unione join .CQScanProfileNew::EarlyPhasesper il profiler sopra il nodo 4. Il nodo 4 aggregato di flusso di per sé non ha un metodo delle fasi iniziali.CQScanProfileNew::EarlyPhasessul profiler sopra il nodo 5.CQScanExchangeNew::EarlyPhasesper i stream di ripartizione scambio al nodo 5.
Si noti che in questa fase stiamo elaborando solo l'input esterno (superiore) al join di unione. Questa è solo la normale sequenza iterativa di esecuzione in modalità riga. Non è particolare per i piani paralleli.
Fasi iniziali del ramo C
L'elaborazione della fase iniziale continua con gli iteratori nel ramo C:

La sequenza di chiamate qui è:
CQScanProfileNew::EarlyPhasesper il profiler sopra il nodo 6.CQScanProfileNew::EarlyPhasesper il profiler sopra il nodo 7.CQScanProfileNew::EarlyPhasessul profiler sopra il nodo 9.CQScanNew::EarlyPhasesper la ricerca dell'indice al nodo 9.
Non ci sono EarlyPhases metodo sull'aggregazione o ordinamento del flusso. Il lavoro svolto dal calcolo scalare al nodo 8 è differito (all'ordinamento), quindi non appare nell'albero di scansione della query e non ha un profiler associato.
Informazioni sui tempi del profiler
Attività principale elaborazione in fase iniziale iniziato allo scambio di flussi di raccolta al nodo 2. È disceso dall'albero di scansione della query, seguendo l'input esterno (superiore) al join di unione, fino all'indice di ricerca al nodo 9. Lungo il percorso, l'attività padre ha chiamato le EarlyPhases metodo su ogni iteratore che lo supporta.
Nessuna delle prime fasi dell'attività è stata finora aggiornata in qualsiasi momento nella profilazione DMV. In particolare, nessuno degli iteratori interessati dall'elaborazione delle prime fasi ha avuto il proprio "tempo aperto". Questo ha senso, perché l'elaborazione della fase iniziale sta solo impostando l'esecuzione parallela:questi operatori verranno aperti per l'esecuzione in seguito.
L'indice di ricerca al nodo 9 è un nodo foglia:non ha figli. L'attività principale ora inizia a tornare dalle EarlyPhases nidificate chiamate, crescente l'albero di scansione della query indietro verso lo scambio di flussi di raccolta.
Ciascuno dei profiler chiama il Contatore prestazioni query API all'ingresso nel loro EarlyPhases metodo, e lo chiamano di nuovo uscendo. La differenza tra i due numeri rappresenta il tempo trascorso per l'iteratore e tutti i suoi figli (poiché le chiamate al metodo sono nidificate).
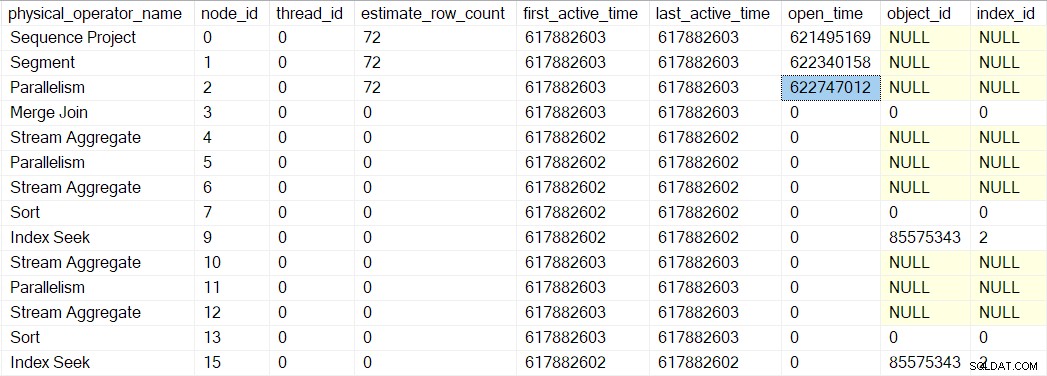
Dopo che il profiler per la ricerca dell'indice ritorna, il DMV del profiler mostra il tempo trascorso e della CPU per la ricerca dell'indice solo, nonché un ultimo attivo aggiornato tempo. Si noti inoltre che queste informazioni vengono registrate rispetto all'attività principale (l'unica opzione in questo momento):
Nessuno degli iteratori precedenti toccati dalle chiamate delle prime fasi ha tempi trascorsi o aggiornato gli ultimi tempi attivi. Questi numeri vengono aggiornati solo quando saliamo sull'albero.
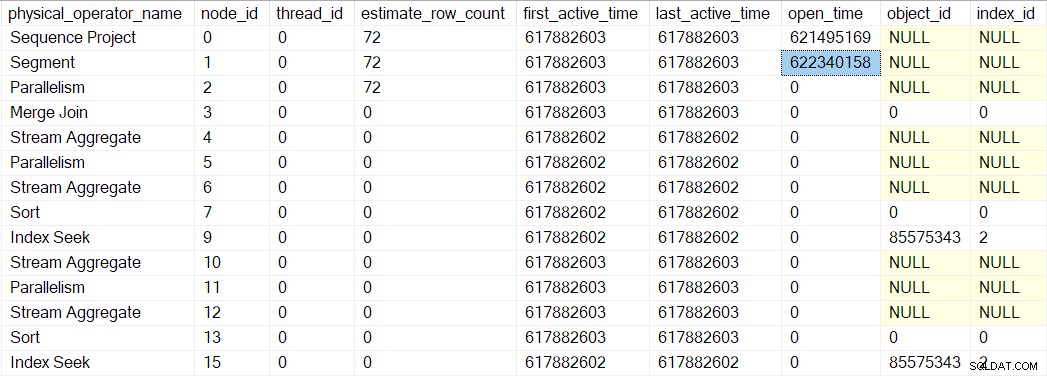
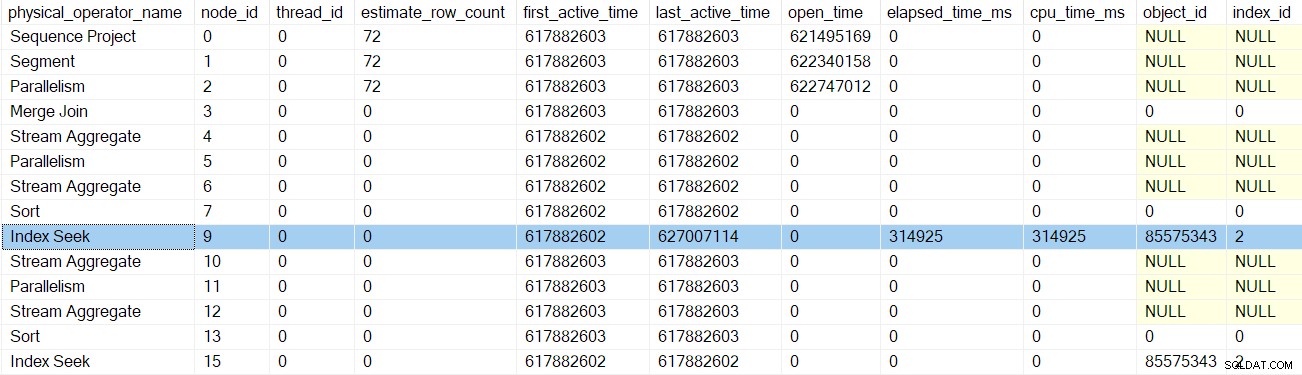
Dopo la successiva chiamata delle prime fasi del profiler, il ordinamento gli orari sono aggiornati:
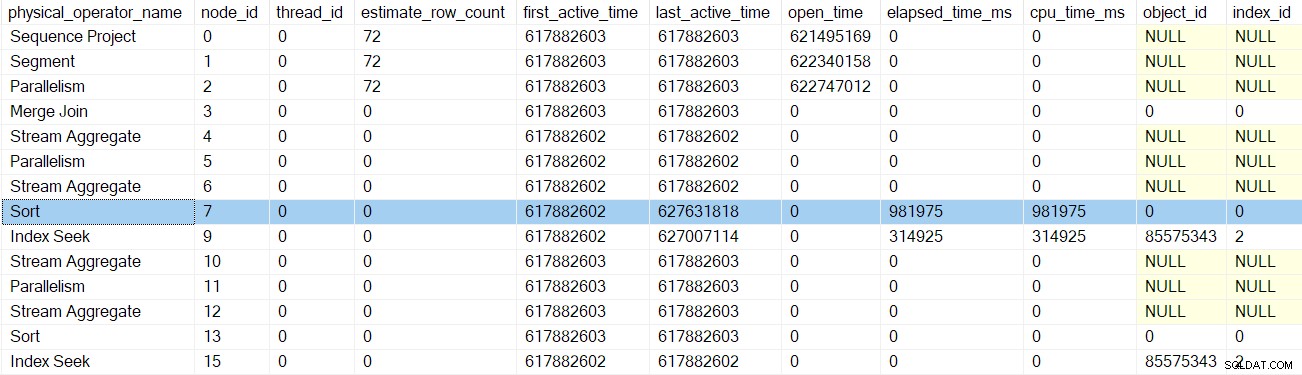
Il prossimo ritorno ci porta oltre il profiler per l'aggregato stream al nodo 6:
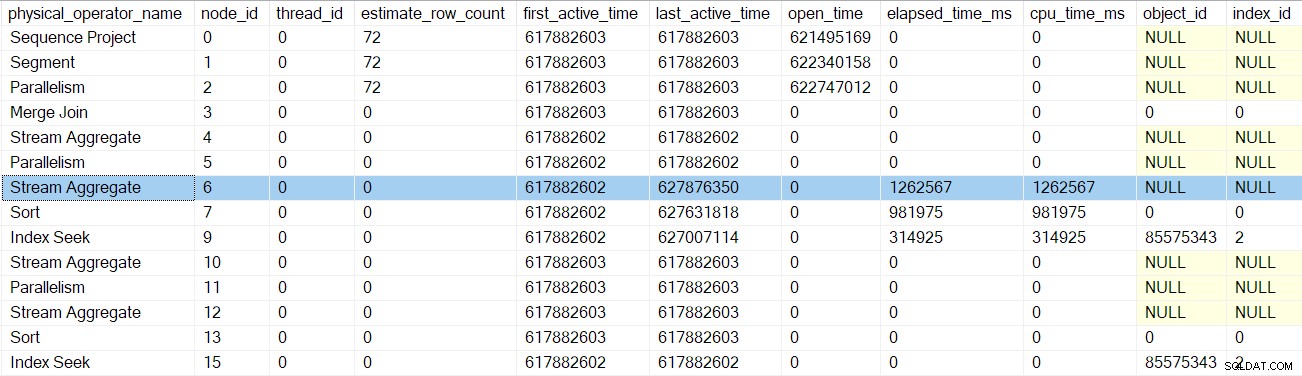
Il ritorno da questo profiler ci riporta alle EarlyPhases chiamata agli stream di ripartizione scambio al nodo 5 . Ricorda che non è qui che è iniziata la sequenza delle chiamate delle prime fasi:è stato lo scambio di flussi di raccolta al nodo 2.
Attività parallele del ramo C accodate
A parte l'aggiornamento dei dati di profilazione, le precedenti chiamate nelle prime fasi non sembravano fare molto. Che tutto cambia con i stream di ripartizione scambio al nodo 5.
Descriverò il ramo C in modo abbastanza dettagliato per introdurre una serie di concetti importanti, che si applicheranno anche agli altri rami paralleli. Coprire questo terreno una volta ora significa che la discussione successiva sul ramo può essere più concisa.
Dopo aver completato l'elaborazione della fase iniziale nidificata per il suo sottoalbero (fino alla ricerca dell'indice al nodo 9), lo scambio può iniziare il proprio lavoro di fase iniziale. Inizia allo stesso modo dell'apertura lo scambio di flussi di raccolta al nodo 2:
CXTransLocal::Open(apertura della sub-transazione parallela locale).CXPort::Register(registrandosi con il porto di scambio).
I passaggi successivi sono diversi perché il ramo C contiene un blocco completo iteratore (l'ordinamento al nodo 7). L'elaborazione della fase iniziale nei flussi di ripartizione del nodo 5 esegue le seguenti operazioni:
- Chiama
CQScanExchangeNew::StartAllProducers. Questa è la prima volta che incontriamo qualcosa che fa riferimento al lato produttore dello scambio. Il nodo 5 è il primo scambio in questo piano a creare il suo lato produttore. - Acquisisce un mutex quindi nessun altro thread può accodare attività contemporaneamente.
- Avvia transazioni nidificate parallele per le attività del produttore (
CXPort::StartNestedTransactionseReadOnlyXactImp::BeginParallelNestedXact). - Registra le sottotransazioni con l'oggetto di scansione della query principale (
CQueryScan::AddSubXact). - Crea descrittori produttore (
CQScanExchangeNew::PxproddescCreate). - Crea nuovi contesti di esecuzione del produttore (
CExecContext) derivato dal contesto di esecuzione zero. - Aggiorna la mappa collegata degli iteratori del piano.
- Imposta DOP per il nuovo contesto (
CQueryExecContext::SetDop) in modo che tutte le attività sappiano qual è l'impostazione DOP complessiva. - Inizializza la cache dei parametri (
CQueryExecContext::InitParamCache). - Collega le transazioni nidificate parallele alla transazione di base (
CExecContext::SetBaseXact). - Metti in coda i nuovi processi secondari per l'esecuzione (
SubprocessMgr::EnqueueMultipleSubprocesses). - Crea nuove attività parallele attività tramite
sqldk!SOS_Node::EnqueueMultipleTasksDirect.
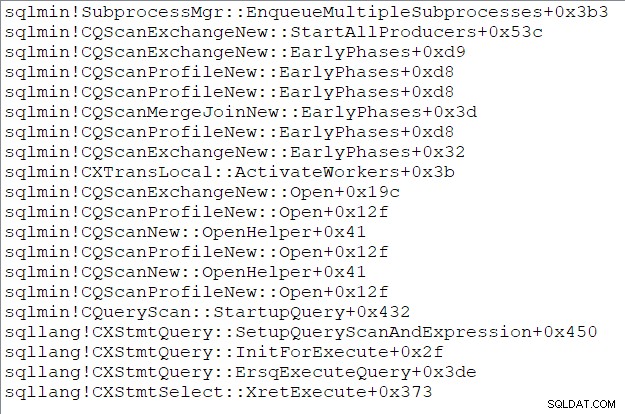
Lo stack di chiamate dell'attività principale (per quelli di voi che amano queste cose) in questo momento è:
Fine della terza parte
Ora abbiamo creato il lato produttore dello scambio di flussi di ripartizione al nodo 5, ha creato ulteriori attività parallele per eseguire il ramo C e ricollegare tutto a genitore strutture come richiesto. Il ramo C è il primo branch per avviare eventuali attività parallele. La parte finale di questa serie esaminerà in dettaglio l'apertura del ramo C e avvierà le restanti attività parallele.