Nel mio precedente post sulle statistiche incrementali, una nuova funzionalità di SQL Server 2014, ho dimostrato come possono aiutare a ridurre la durata delle attività di manutenzione. Questo perché le statistiche possono essere aggiornate a livello di partizione e le modifiche unite nell'istogramma principale per la tabella. Ho anche notato che Query Optimizer non utilizza quelle statistiche a livello di partizione durante la generazione di piani di query, il che potrebbe essere qualcosa che le persone si aspettavano. Non esiste documentazione per affermare che le statistiche incrementali verranno o meno utilizzate da Query Optimizer. Quindi come fai a saperlo? Devi provarlo. :-)
La configurazione
L'impostazione per questo test sarà simile a quella dell'ultimo post, ma con meno dati. Tieni presente che le dimensioni predefinite sono inferiori per i file di dati e lo script viene caricato solo in pochi milioni di righe di dati:
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', --everything in 2011 '20120101', --everything in 2012 '20130101', --everything in 2013 '20140101', --everything in 2014 '20150101' --everything in 2015 ); GO CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Quando creiamo l'indice cluster per dbo.Orders, lo creeremo senza STATISTICS_INCREMENTAL opzione abilitata, quindi inizieremo con una tabella partizionata tradizionale senza statistiche incrementali:
ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ([OrderDate], [PurchaseOrderID]) ON [OrderDateRangePScheme] ([OrderDate]);
Successivamente caricheremo circa 4 milioni di righe, il che richiede poco meno di un minuto sulla mia macchina:
SET NOCOUNT ON; DECLARE @Loops SMALLINT = 0; DECLARE @Increment INT = 3000; WHILE @Loops < 1000 BEGIN INSERT [dbo].[Orders] ([PurchaseOrderID] ,[EmployeeID] ,[VendorID] ,[TaxAmt] ,[Freight] ,[SubTotal] ,[Status] ,[RevisionNumber] ,[ModifiedDate] ,[ShipMethodID] ,[ShipDate] ,[OrderDate] ,[TotalDue] ) SELECT [PurchaseOrderID] + @Increment , [EmployeeID] , [VendorID] , [TaxAmt] , [Freight] , [SubTotal] , [Status] , [RevisionNumber] , [ModifiedDate] , [ShipMethodID] , DATEADD(DAY, 365, [ShipDate]) , DATEADD(DAY, 365, [OrderDate]) , [TotalDue] + 365 FROM [Purchasing].[PurchaseOrderHeader]; CHECKPOINT; SET @Loops = @Loops + 1; SET @Increment = @Increment + 5000; END
Dopo il caricamento dei dati, aggiorneremo le statistiche con un FULLSCAN (in modo da poter creare un istogramma il più possibile coerente per i test) e quindi verificare quali dati abbiamo in ciascuna partizione:
UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN; SELECT $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number] , MIN([o].[OrderDate]) AS [Min_Order_Date] , MAX([o].[OrderDate]) AS [Max_Order_Date] , COUNT(*) AS [Rows_In_Partition] FROM [dbo].[Orders] AS [o] GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) ORDER BY [Partition Number];
 Dati in ogni partizione dopo il caricamento dei dati
Dati in ogni partizione dopo il caricamento dei dati
La maggior parte dei dati si trova nella partizione 2015, ma ci sono anche dati per il 2012, 2013 e 2014. E se controlliamo l'output dal DMV non documentato sys.dm_db_stats_properties_internal , possiamo vedere che non esistono statistiche a livello di partizione:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 sys.dm_db_stats_properties_internal output che mostra solo una statistica per dbo.Orders
sys.dm_db_stats_properties_internal output che mostra solo una statistica per dbo.Orders
Il test
Il test richiede una semplice query che possiamo utilizzare per verificare che si verifichi l'eliminazione della partizione e controllare anche le stime basate su statistiche. La query non restituisce alcun dato, ma non importa, siamo interessati a ciò che l'ottimizzatore pensa ritornerebbe, in base alle statistiche:
SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
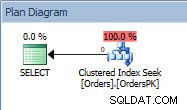 Piano di query per l'istruzione SELECT
Piano di query per l'istruzione SELECT
Il piano ha una ricerca dell'indice cluster e, se controlliamo le proprietà, vediamo che ha stimato 4000 righe e ha eseguito l'accesso alla partizione 5, che contiene i dati del 2014.
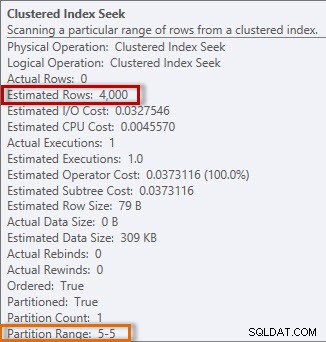 Informazioni stimate ed effettive dal Clustered Index Seek
Informazioni stimate ed effettive dal Clustered Index Seek
Se osserviamo l'istogramma per la tabella dbo.Orders, in particolare nell'area dei dati di aprile 2014, vediamo che non ci sono passaggi per 2014-04-01, quindi l'ottimizzatore stima il numero di righe per quella data utilizzando il passaggio per il 24-04-2014, dove AVG_RANGE_ROWS è 4000 (per qualsiasi valore compreso tra il 14-02-2014 e il 23-04-2014 inclusi, l'ottimizzatore stima che verranno restituite 4000 righe).
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
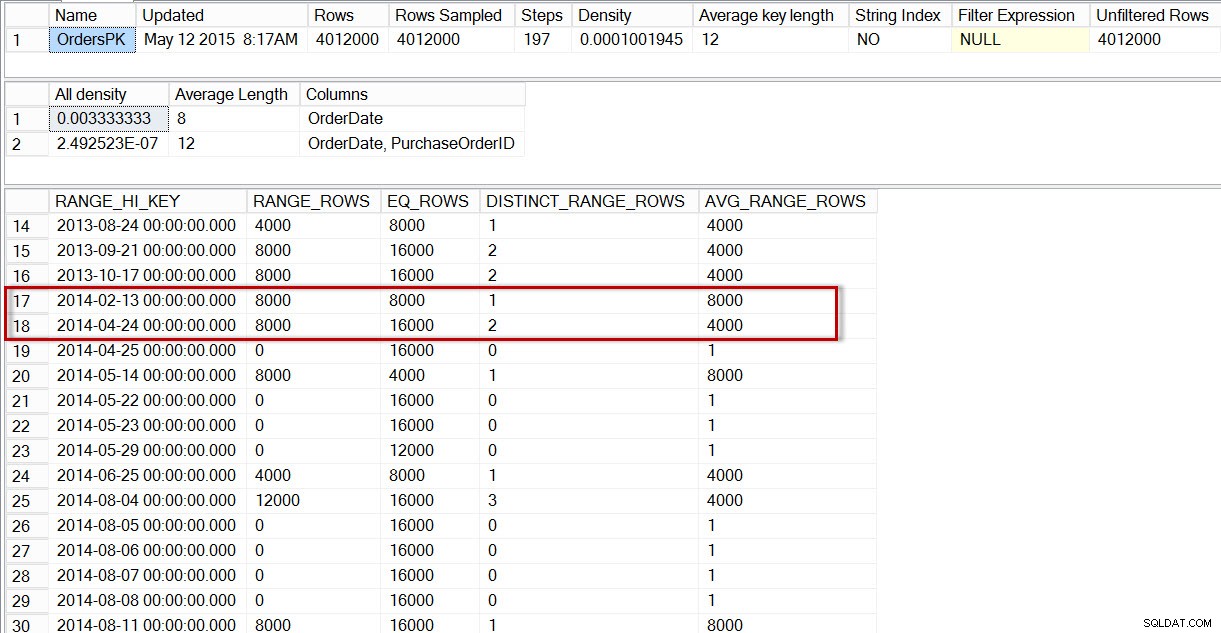 Distribuzione nell'istogramma dbo.Orders
Distribuzione nell'istogramma dbo.Orders
Il preventivo e il piano sono completamente attesi. Attiviamo le statistiche incrementali e vediamo cosa otteniamo.
ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON); GO UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN;
Se eseguiamo nuovamente la nostra query su sys.dm_db_stats_properties_internal , possiamo vedere le statistiche incrementali:
 sys.dm_db_stats_properties_internal mostra informazioni statistiche incrementali
sys.dm_db_stats_properties_internal mostra informazioni statistiche incrementali
Ora eseguiamo nuovamente la nostra query dbo.Orders ed eseguiremo DBCC FREEPROCCACHE prima di tutto per garantire che il piano non venga riutilizzato:
DBCC FREEPROCCACHE; GO SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
Otteniamo lo stesso piano e la stessa stima:
Piano di query per l'istruzione SELECT
Informazioni stimate ed effettive dal Clustered Index Seek
Se controlliamo l'istogramma principale per dbo.Orders, vediamo quasi lo stesso istogramma di prima:
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
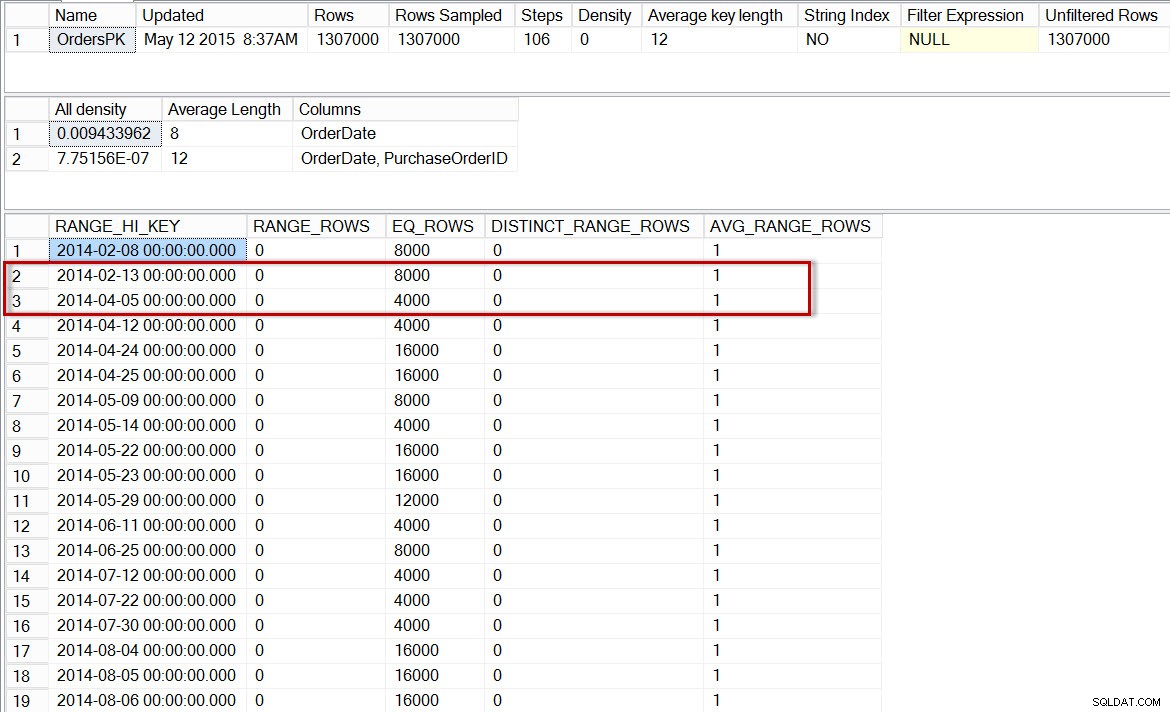 Istogramma per dbo.Orders, dopo aver abilitato le statistiche incrementali
Istogramma per dbo.Orders, dopo aver abilitato le statistiche incrementali
Ora, controlliamo l'istogramma per la partizione con i dati del 2014 (possiamo farlo usando il flag di traccia non documentato 2309, che consente di specificare un numero di partizione come argomento aggiuntivo per DBCC SHOW_STATISTICS ):
DBCC TRACEON(2309);
GO
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK', 6);
Istogramma per la partizione 2014 di dbo.Orders, dopo aver abilitato le statistiche incrementali
Qui vediamo che, ancora una volta, non ci sono passaggi per 2014-04-01, ma ce ne sono 0 RANGE_ROWS tra il 13-02-2014 e il 05-04-2014, con un AVG_RANGE_ROWS di 1. Se l'ottimizzatore stesse utilizzando l'istogramma per le statistiche a livello di partizione, la stima del numero di righe per il 01-04-2014 sarebbe 1.
Nota:la partizione identificata come utilizzata nel piano di query è 5, ma noterai che il DBCC SHOW_STATISTICS l'istruzione fa riferimento alla partizione 6. Il presupposto è un'incoerenza nei metadati delle statistiche (un errore comune di uno, probabilmente dovuto al conteggio basato su 0 rispetto a quello basato su 1), che potrebbe o meno essere corretto in futuro. Tieni presente che il flag di traccia non è attualmente documentato e che non è consigliabile utilizzarlo in un ambiente di produzione.
Riepilogo
L'aggiunta di statistiche incrementali nella versione di SQL Server 2014 è un passo nella giusta direzione per migliorare le stime della cardinalità per le tabelle partizionate. Tuttavia, come abbiamo dimostrato, il valore corrente delle statistiche incrementali è limitato a durate di manutenzione ridotte, poiché tali statistiche incrementali non sono ancora utilizzate da Query Optimizer.