Introduzione
La memorizzazione dei dati è una cosa; memorizzazione significativa, utile, corretta i dati sono tutt'altro. Sebbene il significato e l'utilità siano essi stessi qualità soggettive, la correttezza almeno può essere definita e imposta in modo logico. I tipi assicurano già che i numeri siano numeri e le date siano date, ma non possono garantire che il peso o la distanza siano numeri positivi o impedire la sovrapposizione degli intervalli di date. I vincoli di tupla, tabelle e database applicano regole ai dati archiviati e rifiutano valori o combinazioni di valori che non superano l'esame.
I vincoli non rendono in alcun modo inutili altre tecniche di convalida dell'input, anche quando verificano le stesse asserzioni. Il tempo speso a provare e a non riuscire a memorizzare dati non validi è tempo perso. Messaggi di violazione, come assert nei sistemi e nei linguaggi di programmazione delle applicazioni, rivela solo il primo problema con il primo record candidato in modo molto più dettagliato di quanto non necessiti chiunque non sia immediatamente coinvolto nel database. Ma per quanto riguarda la correttezza dei dati, i vincoli sono di legge, nel bene o nel male; tutto il resto è un consiglio.
Su tuple:Not Null, Default e Check
I vincoli non nulli sono la categoria più semplice. Una tupla deve avere un valore per l'attributo vincolato o, in altre parole, l'insieme di valori consentiti per la colonna non include più l'insieme vuoto. Nessun valore significa nessuna tupla:l'inserimento o l'aggiornamento è rifiutato.
Proteggersi dai valori null è facile come dichiarare column_name COLUMN_TYPE NOT NULL in CREATE TABLE o ADD COLUMN . I valori Null causano intere categorie di problemi tra il database e gli utenti finali, quindi è una buona abitudine definire riflessivamente vincoli non Null su qualsiasi colonna senza una buona ragione per consentire i Null.
La fornitura di un valore predefinito se non viene specificato nulla (per omissione o un esplicito NULL ) in un inserto o aggiornamento non è sempre considerato un vincolo, poiché i record candidati vengono modificati e archiviati anziché rifiutati. In molti DBMS, i valori predefiniti possono essere generati da una funzione, sebbene MySQL non consenta funzioni definite dall'utente per questo scopo.
Qualsiasi altra regola di validazione che dipenda solo dai valori all'interno di una singola tupla può essere implementata come CHECK vincolo. In un certo senso, NOT NULL di per sé è una scorciatoia per CHECK (column_name IS NOT NULL); il messaggio di errore ricevuto in violazione fa la maggior parte della differenza. CHECK , tuttavia, può applicare e imporre la verità di qualsiasi predicato booleano su una singola tupla. Ad esempio, una tabella che memorizza le posizioni geografiche dovrebbe CHECK (latitude >= -90 AND latitude < 90) e allo stesso modo per longitudine compresa tra -180 e 180 -- oppure, se disponibile, utilizzare e convalidare un GEOGRAPHY tipo di dati.
Sui tavoli:unico ed esclusione
I vincoli a livello di tabella testano le tuple l'una contro l'altra. In un vincolo univoco, solo un record può avere un determinato insieme di valori per le colonne vincolate. La nullità può causare problemi qui, poiché NULL non è mai uguale a nient'altro, fino a NULL incluso si. Un vincolo univoco su (batman, robin) consente quindi infinite copie di qualsiasi Robinless Batman.
I vincoli di esclusione sono supportati solo in PostgreSQL e DB2, ma riempiono una nicchia molto utile:possono prevenire sovrapposizioni. Specificare i campi vincolati e le operazioni in base alle quali ciascuno verrà valutato e un nuovo record verrà accettato solo se nessun record esistente viene confrontato correttamente con ciascun campo e operazione. Ad esempio, un schedules la tabella può essere configurata per rifiutare i conflitti:
-- text, int, etc. comparisons in exclusion constraints require this-- Postgres extensionCREATE EXTENSION btree_gist;CREATE TABLE schedules ( schedule_id SERIAL NOT NULL PRIMARY KEY, room_number TEXT NOT NULL, -- a range of TIMESTAMP WITH TIME ZONE provides both start and end duration TSTZRANGE, -- table-level constraints imply an index, since otherwise they'd -- have to search the entire table to validate a candidate record; -- GiST (generalized search tree) indexes are usually used in -- Postgres EXCLUDE USING GIST ( room_number WITH =, duration WITH && ));INSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- the same time in a different room: acceptedINSERT INTO schedules (room_number, duration)VALUES ('32B', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- a half-hour overlap for an already-scheduled room: rejectedINSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:30:00Z,2020-08-20T11:30:00Z)');
Operazioni avanzate come ON CONFLICT di PostgreSQL clausola o ON DUPLICATE KEY UPDATE di MySQL utilizzare un vincolo a livello di tabella per rilevare i conflitti. E come i vincoli non nulli possono essere espressi come CHECK vincoli, un vincolo unico può essere espresso come vincolo di esclusione sull'uguaglianza.
La chiave primaria
I vincoli univoci hanno un caso speciale particolarmente utile. Con un ulteriore vincolo non nullo sulla colonna o sulle colonne univoche, ogni record nella tabella può essere identificato singolarmente dai suoi valori per le colonne vincolate, che sono denominate collettivamente una chiave . Più chiavi candidate possono coesistere in una tabella, ad esempio users a volte hanno ancora email distinte, univoche e non nulle se username S; ma dichiarare una chiave primaria stabilisce un unico criterio in base al quale i record sono pubblicamente ed esclusivamente conosciuti. Alcuni RDBMS organizzano persino le righe sulle pagine in base alla chiave primaria, chiamata a questo scopo indice cluster , per rendere la ricerca in base ai valori della chiave primaria il più veloce possibile.
Esistono due tipi di chiave primaria. Una chiave naturale viene definita su una o più colonne "naturalmente" incluse nei dati della tabella, mentre una chiave surrogata o sintetica viene inventata al solo scopo di diventare la chiave. Le chiavi naturali richiedono attenzione:possono cambiare più cose di quanto spesso i progettisti di database attribuiscano, dai nomi agli schemi di numerazione. Una tabella di ricerca contenente nomi di paesi e regioni può utilizzare i rispettivi codici ISO 3166 come chiave primaria naturale sicura, ma un users tabella con una chiave naturale basata su valori mutevoli come nomi o indirizzi e-mail crea problemi. In caso di dubbio, crea una chiave surrogata.
Se una chiave naturale si estende su più colonne, dovrebbe sempre essere considerata almeno una chiave surrogata poiché le chiavi a più colonne richiedono uno sforzo maggiore per la gestione. Se la chiave naturale è adatta, tuttavia, le colonne dovrebbero essere ordinate con specificità crescente proprio come negli indici:codice paese allora codice regionale, anziché il contrario.
La chiave surrogata è stata storicamente una singola colonna intera, o BIGINT dove alla fine verranno assegnati miliardi. I database relazionali possono riempire automaticamente le chiavi surrogate con il numero intero successivo di una serie, una caratteristica solitamente chiamata SERIAL o IDENTITY .
Un contatore numerico autoincrementante non è privo di inconvenienti:l'aggiunta di record con chiavi pregenerate può causare conflitti e se i valori sequenziali vengono esposti agli utenti, è facile per loro indovinare quali potrebbero essere altre chiavi valide. Gli identificatori univoci universali, o UUID, evitano questi punti deboli e sono diventati una scelta comune per le chiavi surrogate, sebbene siano anche molto più grandi nella pagina rispetto a un semplice numero. I tipi UUID v1 (basato sull'indirizzo MAC) e v4 (pseudorandom) sono i più utilizzati.
Sul database:chiavi esterne
I database relazionali implementano solo una classe di vincolo multi-tabella, il
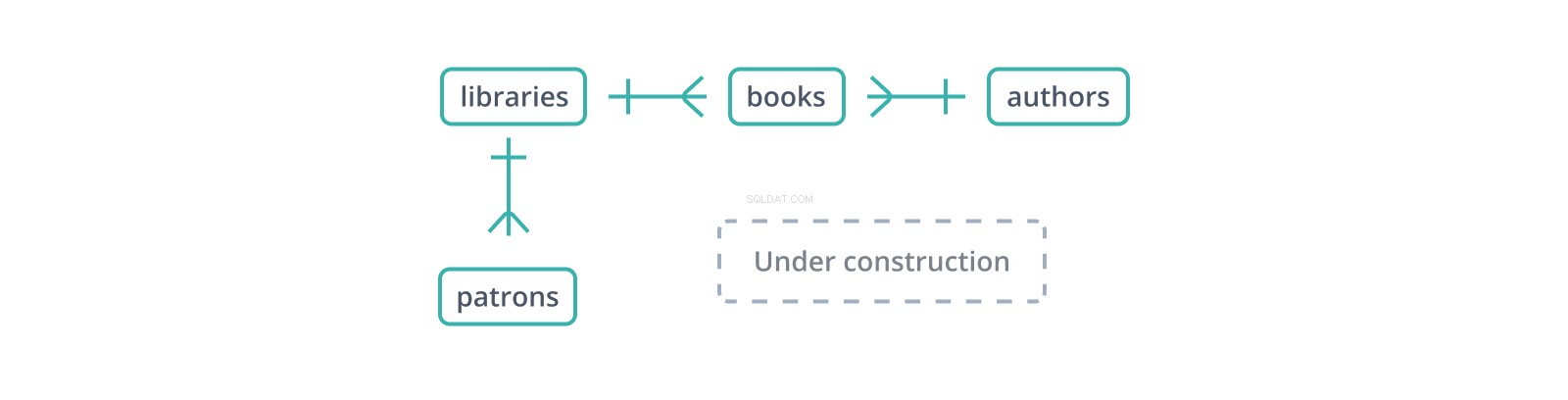
Questo "diagramma entità-relazione" informale o ERD mostra l'inizio di uno schema per un database di biblioteche e le loro collezioni e mecenati. Ogni bordo rappresenta una relazione tra le tabelle che collega. Il | il glifo indica un singolo record su un lato, mentre il glifo "zampa di gallina" rappresenta più:una biblioteca contiene molti libri e ha molti mecenati.
Una chiave esterna è una copia della chiave primaria di un'altra tabella, colonna per colonna (un punto a favore delle chiavi surrogate:solo una colonna da copiare e fare riferimento), con valori che collegano i record in questa tabella ai record "genitori" in quella. Nello schema sopra, i books table mantiene un library_id chiave esterna a libraries , che contengono libri e un author_id agli authors , chi li scrive. Ma cosa succede se un libro viene inserito con un author_id che non esiste in authors ?
Se la chiave esterna non è vincolata, ovvero è solo un'altra o più colonne, un libro può avere un autore che non esiste. Questo è un problema:se qualcuno cerca di seguire il collegamento tra books e authors , non finiscono da nessuna parte. Se authors.author_id è un numero intero seriale, c'è anche la possibilità che nessuno se ne accorga fino allo spurgo author_id alla fine viene assegnato e ti ritrovi con una copia particolare di Don Chisciotte attribuito prima a nessuno noto e poi a Pierre Menard, con Miguel Cervantes introvabile.
Vincolare la chiave esterna non può impedire l'attribuzione errata di un libro in caso di author_id erroneo punta a un record esistente in authors , quindi altri controlli e test rimangono importanti. Tuttavia, l'insieme dei valori di chiave esterna esistenti è quasi sempre un piccolo sottoinsieme del possibile valori di chiave esterna, quindi i vincoli di chiave esterna cattureranno e preverranno la maggior parte dei valori errati. Con un vincolo di chiave esterna, il Chisciotte con autore inesistente verrà rifiutato anziché registrato.
È da qui che viene il "relazionale" in "database relazionale"?
Le chiavi esterne creano relazioni tra tabelle, ma le tabelle come le conosciamo sono matematicamente relazioni tra gli insiemi di valori possibili per ciascun attributo. Una singola tupla mette in relazione un valore per la colonna A con un valore per la colonna B e successive. L'articolo originale di E.F. Codd usa "relazionale" in questo senso.
Ciò ha causato una confusione infinita e probabilmente continuerà a farlo in perpetuo.
Per determinati valori di corretto
Ci sono molti altri modi in cui i dati possono essere errati rispetto a quelli affrontati qui. I vincoli aiutano, ma anche loro sono solo così flessibili; molte specifiche comuni all'interno della tabella, come un limite di due o più sul numero di volte in cui un valore può apparire in una colonna, possono essere applicate solo con i trigger.
Ma ci sono anche modi in cui la struttura stessa di una tabella può portare a delle incongruenze. Per prevenirli, dovremo effettuare il marshalling di chiavi primarie ed esterne non solo per definire e convalidare, ma per normalizzare le relazioni tra le tabelle. Innanzitutto, però, abbiamo appena scalfito la superficie di come le relazioni tra le tabelle definiscono la struttura del database stesso.